
20192316 2020-2021-1 《数据结构与面向对象程序设计》实验七报告
20192316 2020-2021-1 《数据结构与面向对象程序设计》实验七报告
课程:《程序设计与数据结构》
班级: 1923
姓名: 贝世之
学号:20192316
实验教师:王志强
实验日期:2020年11月19日
必修/选修: 必修
1. 实验内容
1.定义一个Searching和Sorting类,并在类中实现linearSearch,SelectionSort方法,最后完成测试。
要求不少于10个测试用例,提交测试用例设计情况(正常,异常,边界,正序,逆序),用例数据中要包含自己学号的后四位
提交运行结果图。
2.重构你的代码
把Sorting.java Searching.java放入 cn.edu.besti.cs1823.(姓名首字母+四位学号) 包中(例如:cn.edu.besti.cs1823.G2301)
把测试代码放test包中
重新编译,运行代码,提交编译,运行的截图(IDEA,命令行两种)
3.参考http://www.cnblogs.com/maybe2030/p/4715035.html ,学习各种查找算法并在Searching中补充查找算法并测试
提交运行结果截图
4.补充实现课上讲过的排序方法:希尔排序,堆排序,二叉树排序等(至少3个)
测试实现的算法(正常,异常,边界)
提交运行结果截图(如果编写多个排序算法,即使其中三个排序程序有瑕疵,也可以酌情得满分)
5.编写Android程序对实现各种查找与排序算法进行测试
提交运行结果截图
推送代码到码云(选做,加分)
2. 实验过程及结果
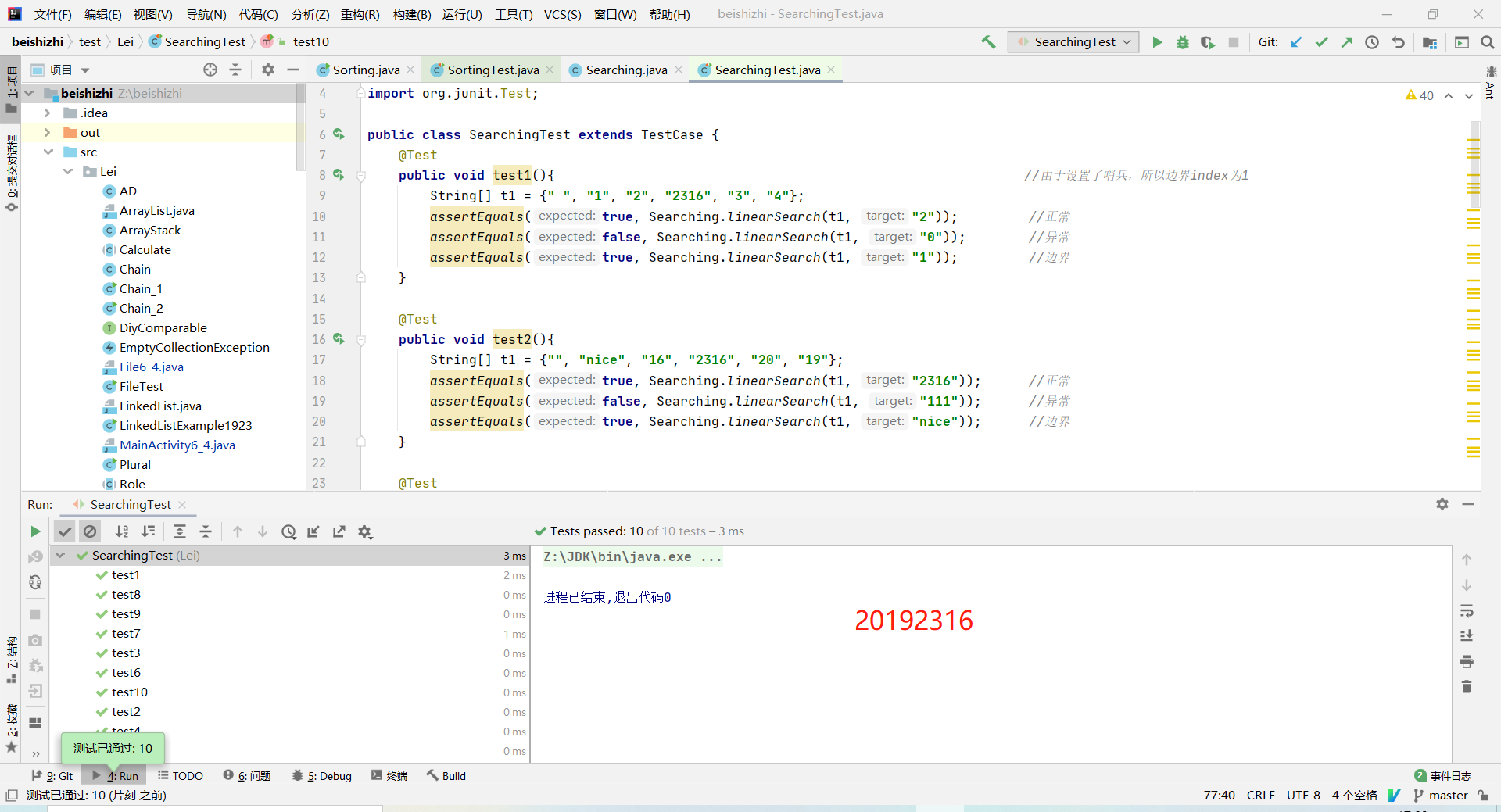
2.1 linearSearch和SelectionSort
-
设置哨兵,逆序寻找,快速实现Searching类的linearSearch方法
-
设置10个测试用例检测正常,异常,边界情况,由于设置了哨兵,所以边界index为1
-
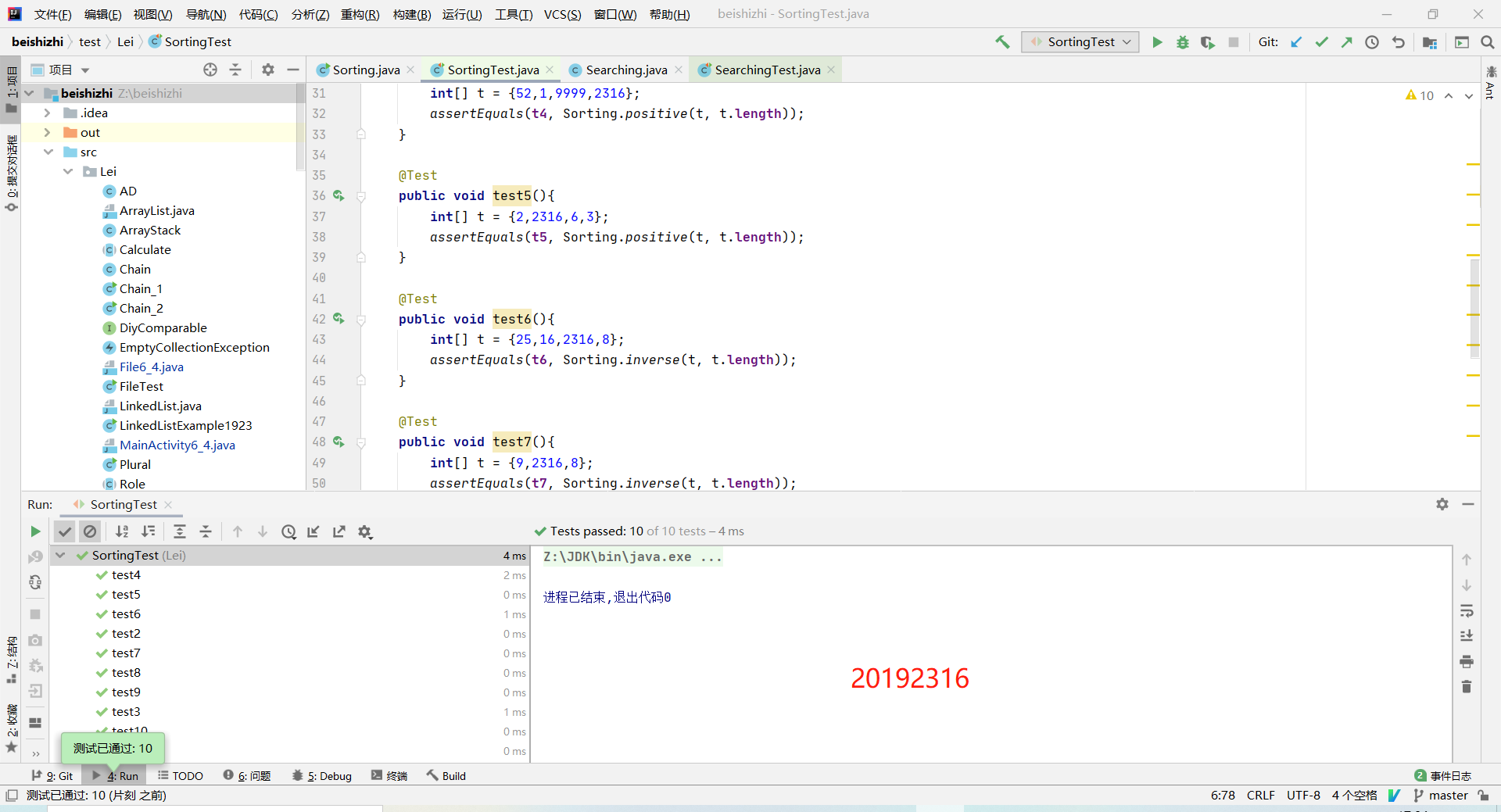
采用正序和逆序两种方法在Sorting类实现SelectionSort方法
-
设置10个测试用例检测正序,逆序情况,前5个检测正序,后5个检测逆序情况
2.2 重构代码,用IDEA和命令行运行
链接中代码在IDEA中运行,“/* */”代码在命令行中运行。
命令行中因junit.framework.TestCase程序包找不到而导致错误,因此我更改命令行代码为输出测试



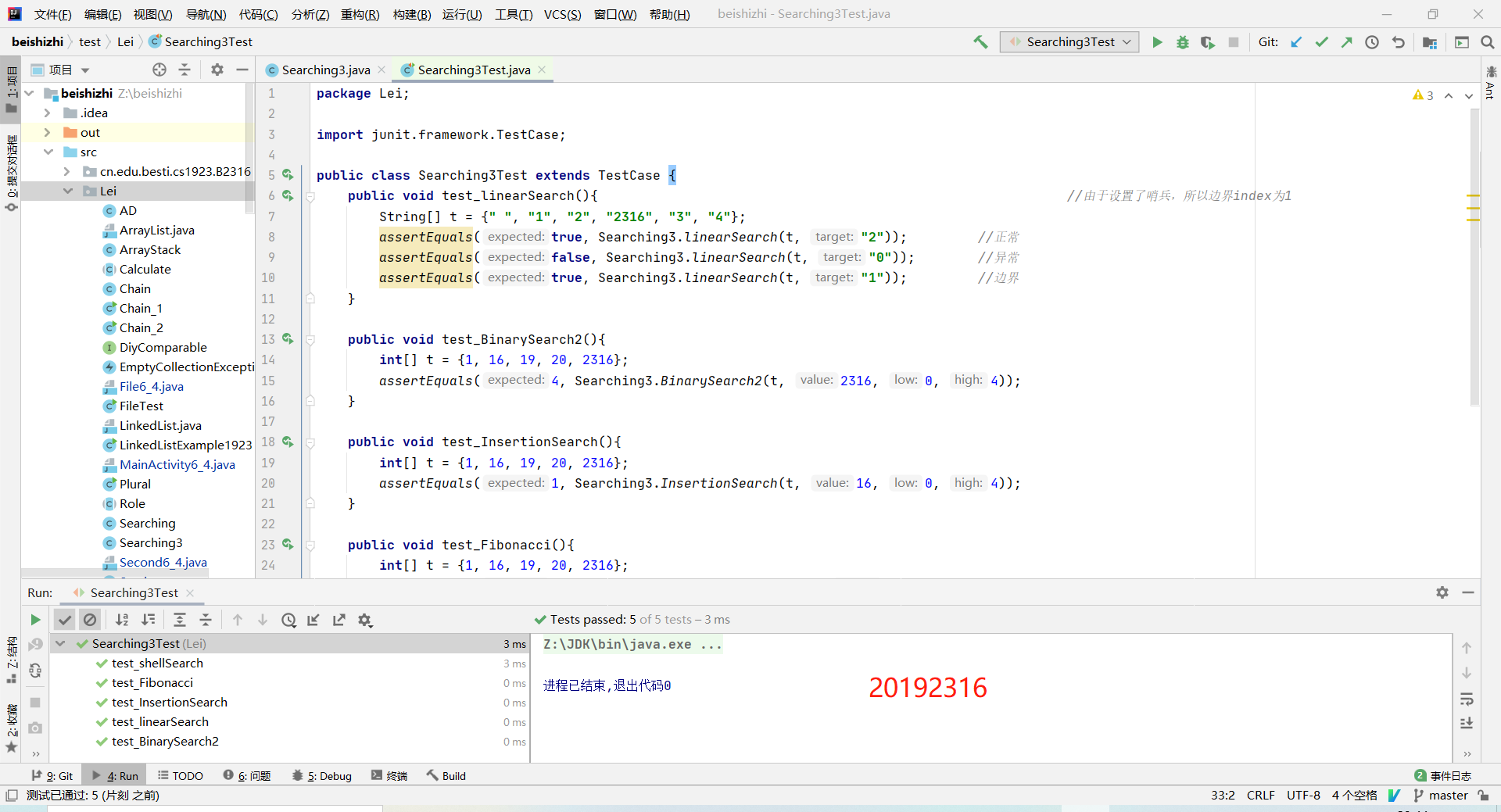
2.3 顺序查找、二分查找、插值查找、斐波那契查找、分块查找、哈希查找
参考[Data Structure & Algorithm] 七大查找算法添加了顺序查找、二分查找、插值查找、斐波那契查找、分块查找、哈希查找算法并测试
顺序查找
- 基本思想:顺序查找也称为线形查找,属于无序查找算法。从数据结构线形表的一端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则表示查找成功;若扫描结束仍没有找到关键字等于k的结点,表示查找失败。
- 复杂度分析:查找成功时的平均查找长度为:(假设每个数据元素的概率相等) ASL = 1/n(1+2+3+…+n) = (n+1)/2 ;当查找不成功时,需要n+1次比较,时间复杂度为O(n);所以,顺序查找的时间复杂度为O(n)。
二分查找
-
基本思想:也称为是折半查找,属于有序查找算法。用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
-
复杂度分析:最坏情况下,关键词比较次数为log2(n+1),且期望时间复杂度为O(log2n);
-
注:折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,折半查找能得到不错的效率。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,那就不建议使用。——《大话数据结构》
插值查找
- 基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,插值查找也属于有序查找。
- 复杂度分析:查找成功或者失败的时间复杂度均为O(log2(log2n))。
- 注:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
斐波那契查找
- 基本思想:也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。一般将待比较的key值与第mid=(low+high)/2位置的元素比较,比较结果分三种情况。
- 相等,mid位置的元素即为所求;
- 大于,low=mid+1;
- 小于,high=mid-1。
要求开始表中记录的个数为某个斐波那契数小1,及n=F(k)-1;
开始将k值与第F(k-1)位置的记录进行比较(及mid=low+F(k-1)-1),比较结果也分为三种
- 相等,mid位置的元素即为所求
- 大于,low=mid+1,k-=2;
- 小于,high=mid-1,k-=1。
- 复杂度分析:最坏情况下,时间复杂度为O(log2n),且其期望复杂度也为O(log2n)。
分块查找
- 算法思想:将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,……
哈希查找
- 算法思想:哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。
- 复杂度分析:
单纯论查找复杂度:对于无冲突的Hash表而言,查找复杂度为O(1)。
代码与运行截图
2.4 希尔排序
根据要求,本次只验证希尔排序(包括正序逆序)

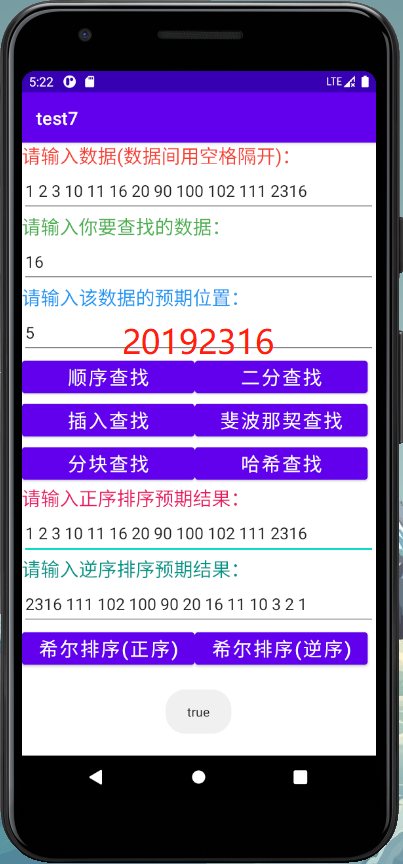
2.5 在Android Studio上实现上述程序
在Android Studio上实现顺序查找、二分查找、插入查找、斐波那契查找、分块查找、哈希查找与希尔排序算法并进行测试。

3. 实验过程中遇到的问题和解决过程
-
问题1:不知道如何输出数组便于测试
-
问题1解决方案:参考java中数组输出的方式使用Java标准库提供的Arrays.toString()完成测试
-
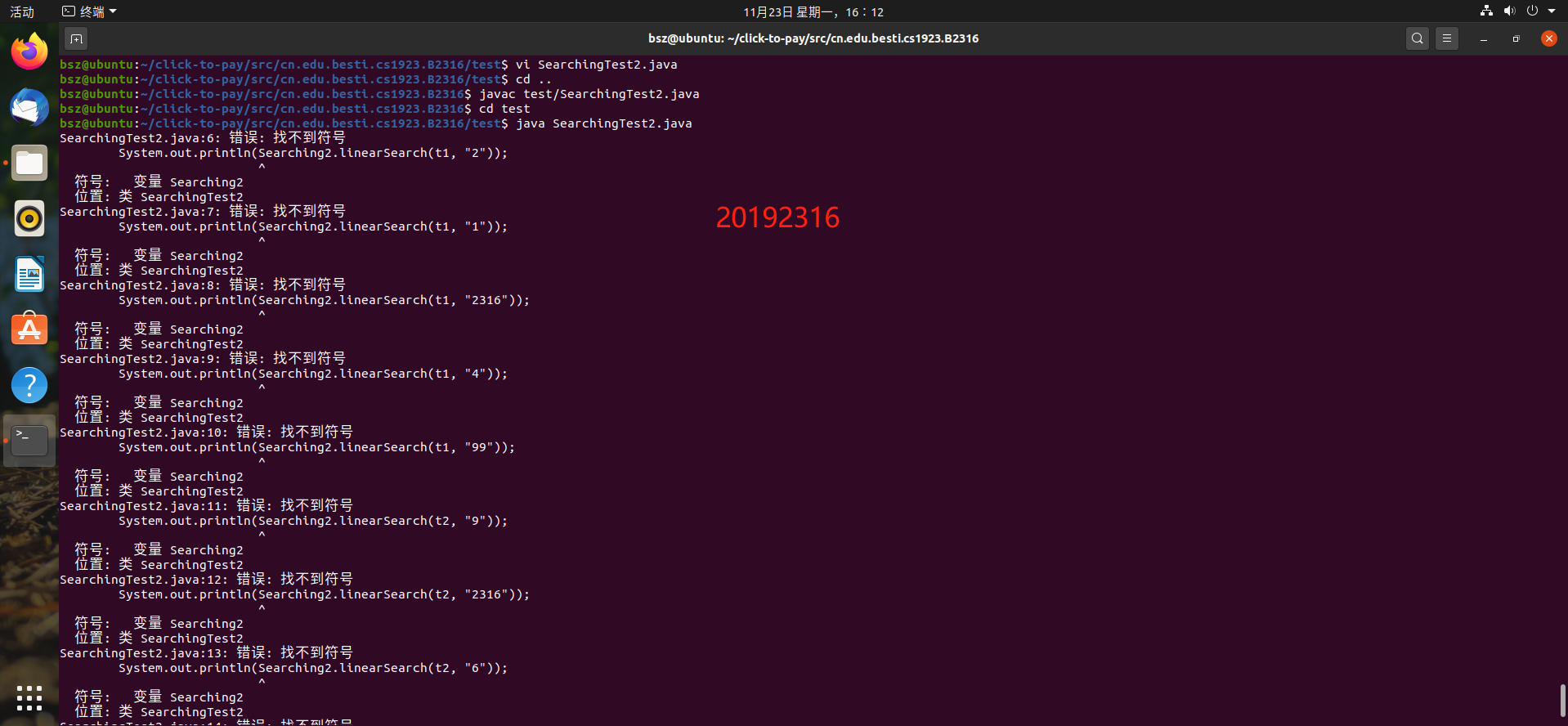
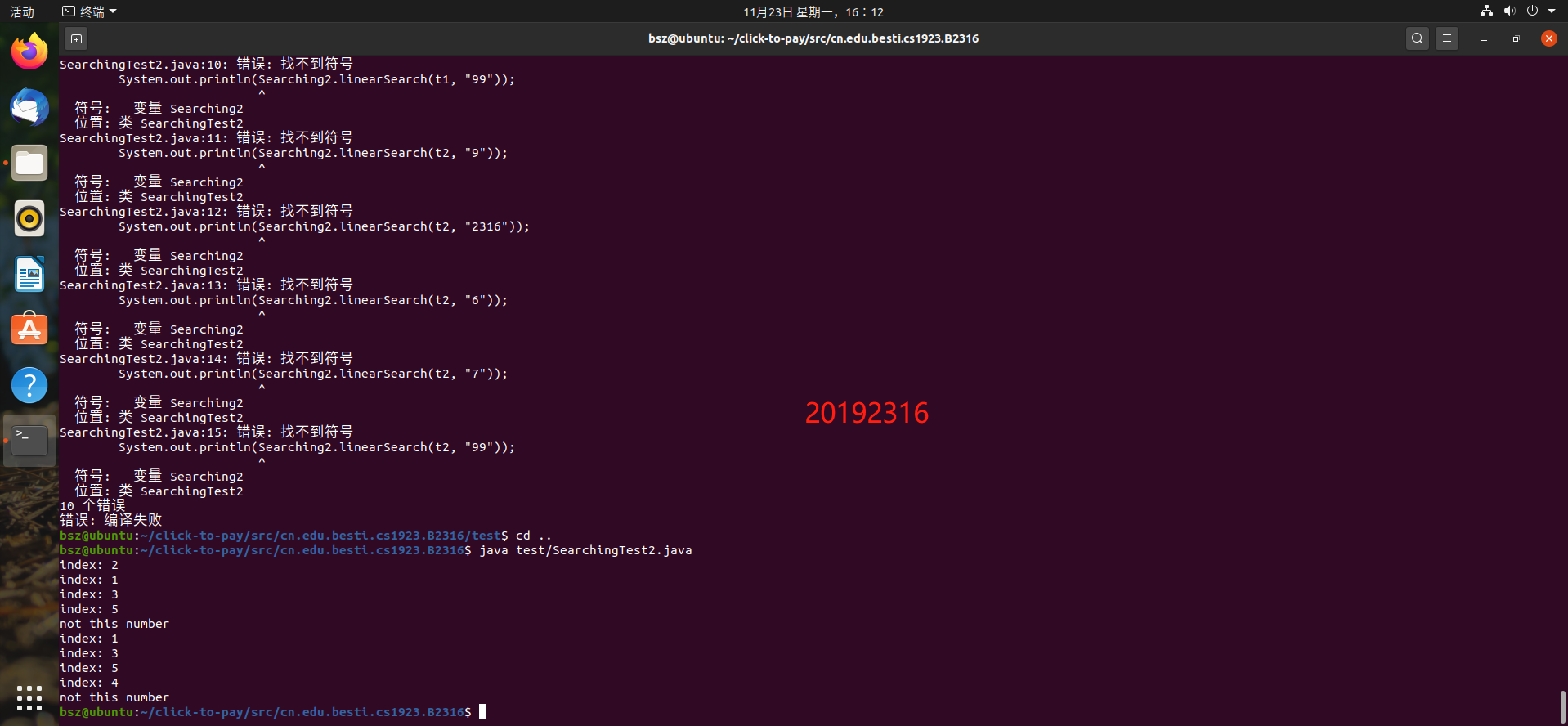
问题2:在命令行中运行程序时报错找不到程序包
-
问题2解决方案:参考cmd运行java程序包名不存在问题解决并经过大量测试后发现,整个包的位置需要在javac编译位置下,编译时不会往父文件夹找,只会往子文件夹找,所以两个类所在的包一定要在javac当前文件夹之下。并且不能import父类。
-
问题3:无法理解斐波那契查找的原理
-
问题3解决方案:参考斐波那契查找原理详解与实现和斐波那契查找原理深入完成代码编写。
其他(感悟、思考等)
这次实验涉及多种查找和排序的方法,越简单、越好理解的方法,效率一般不怎么高(但我喜欢用),接下来需要抽空学习时间复杂度计算,掌握较为复杂但是能够提高程序性能的算法。


