

Python第五章实验
实例1:
programmer_1 = '程序员甲: 搞IT太辛苦了,我想换行......怎么办?'
programmer_2 = '程序员乙: 敲一下回车键'
print(programmer_1 + '\n' + programmer_2)
str1 = '人生苦短,我用Python!'
length = len(str1)
print(length)
substr1 = str1[1]
substr2 = str1[5:] # 从第6个字符截取
substr3 = str1[:5] # 从左边开始截取5个字符
substr4 = str1[2:5] # 截取第3个到第5个字符
print(substr1 + '\n' + substr2 + '\n' + substr3 +
实例2:
programer_1 = '你知道我的生日吗?' # 程序员甲问程序员乙的台词
print('程序员甲说:', programer_1) # 输出程序员甲的台词
programer_2 = '输入你的身份证号码。' # 程序员乙的台词
print('程序员乙说:', programer_2) # 输出程序员乙的台词
idcard = '123456199006277890' # 定义保存身份证号码的字符串
print('程序员甲说:', idcard) #程序员甲说出身份证号码
birthday = idcard[6:10] + '年' + idcard[10:12] + '月' + idcard[12:14] + '日' # 截取生日
print('程序员乙说:', '你是' + birthday + '出生的,所以你的生日是' + birthday[5:])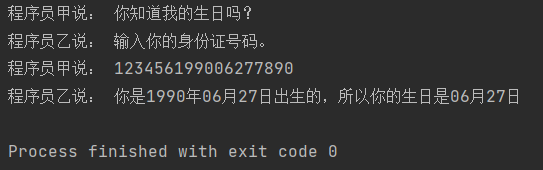
实例3:
str1 = '@明日科技 @扎克伯格 @俞敏洪'
list1 = str1.split(' ') # 用空格分割字符串
print('您@的好友有:')
for item in list1:
print(item[1:]) # 输出每个好友名时,去掉@符号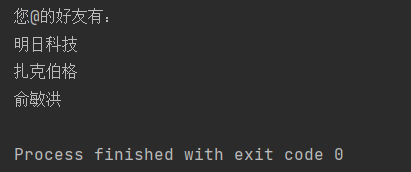
实例4:
list_friend = ['明日科技','扎克伯格','俞敏洪','马云','马化腾'] # 好友列表
str_friend = ' @'.join(list_friend) # 用空格+@符号进行链接
at = '@' + str_friend # 由于使用join()方法时,第一个元素前不加分隔符,所以需要在前面加上@符号
print('您要@的好友: ',at)
实例5:
str1 = '@明日科技 @扎克伯格 @俞敏洪'
print('字符串 “', str1, '“中包括', str1.count('@',1,6),'个@符号') # 从“明“开始检索,不到第一个”@“就结束
print(str1.find('@',2,3)) # 没有则返回-1
print(str1.find('@')) # 有则返回第一个符号的位置
print(str1.index('@')) # index中没有的字符会显示异常
print(str1.startswith('@')) # startswith判断是否以符号开头,是则返回True,不是则返回False
print(str1.startswith('!'))
print(str1.endswith('洪')) # endswith判断是否以符号结尾...
str2 = 'WWW.Mingrisoft.com'
print('原字符串:', str2)
print('新字符串:', str2.lower()) # lower()全部转换为小写
print('新字符串:', str2.upper()) # upper()全部转换为大写
print("实例5:")
# 假设已经注册的会员名称保存在一个字符串中,以“|”进行分隔
username_1 = '|MingRi|mr|mingsoft|WGH|MRSoft|'
# 将会员名称字符串全部转换为小写
username_2 = username_1.lower()
regname_1 = input('请输入要注册的会员名称:')
# 将要注册的会员名称全部转化为小写
regname_2 ='|' + regname_1.lower() + '|'
# 判断输入的会员名称是否存在
if regname_2 in username_2:
print('会员名' + regname_1 + '已存在')
else:
print('会员名' + regname_1 + '可以注册!')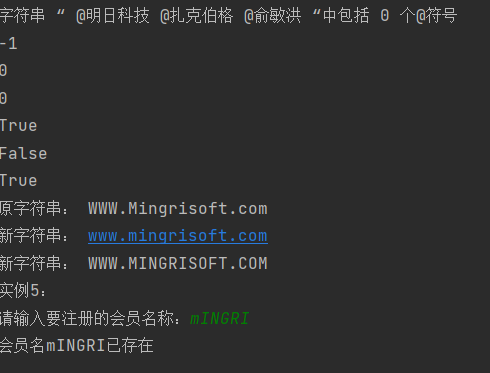
实例6:
import math
# 以货币形式显示
print('1251+3950的结果是(以货币方式显示):¥{:,.2f}元'.format(1251+3950))
print('{0:.1f}用科学计数法表示:{0:E}'.format(120000.1)) # 用科学计数法表示
print('π取5位小数:{:.5f}'.format(math.pi)) # 输出小数点后5位
print('{0:d}的16进制结果是:{0:#x}'.format(100)) # 输出十六进制
# 输出百分比,并且不带小数
print('天才是由{:.0%}的灵感,加上{:.0%}的汗水。'.format(0.01,0.99))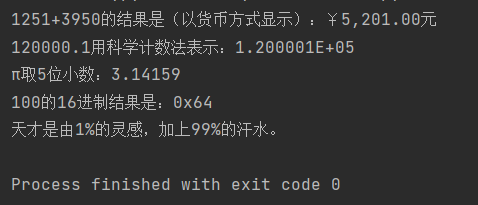
实例7:
import re # 导入Python的re模块
pattern = r'(13[4-9]\d{8})$|(15[01289]\d{8})$'
mobile = '13634222222'
match = re.match(pattern, mobile) # 进行模式匹配
if match == None: #判断是否为None,为真表示匹配失败
print(mobile,'不是有效的中国移动手机号码。')
else:
print(mobile,'是有效的中国移动手机号码。')
mobile = '13144222221'
match = re.match(pattern, mobile) # 进行模式匹配
if match == None: #判断是否为None,为真表示匹配失败
print(mobile,'不是有效的中国移动手机号码。')
else:
print(mobile,'是有效的中国移动手机号码。')
实例8:
import re # 导入Python的re模块
pattern = r'(黑客)|(抓包)|(监听)|(Trojan)' # 模式字符串
about = '我是一名程序员,我喜欢看黑客方面的图书,想研究一下Trojan'
match = re.search(pattern,about) # 进行模式匹配
if match == None: # 判断是否为None,为真表示匹配失败
print(about, '@ 安全!')
else:
print(about, '@ 出现了危险词汇!')
about = '我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。'
match = re.search(pattern,about) # 进行模式匹配
if match == None: # 判断是否为None,为真表示匹配失败
print(about, '@ 安全!')
else:
print(about, '@ 出现了危险词汇!')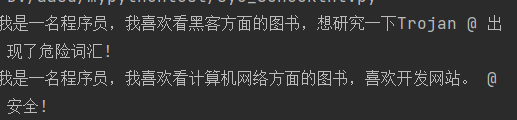
实例9:
import re
pattern = r'(黑客)|(抓包)|(监听)|(Trojan)'
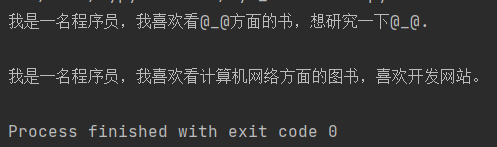
about = '我是一名程序员,我喜欢看黑客方面的书,想研究一下Trojan.\n'
sub = re.sub(pattern,'@_@',about)
print(sub)
about = '我是一名程序员,我喜欢看计算机网络方面的图书,喜欢开发网站。'
sub = re.sub(pattern,'@_@',about)
print(sub)
实例10:
import re
str1 = '@明日科技 @扎克伯格 @俞敏洪'
pattern = r'\s*@'
list1 = re.split(pattern,str1)
print('您@的好友有:')
for item in list1:
if item != "":
print(item)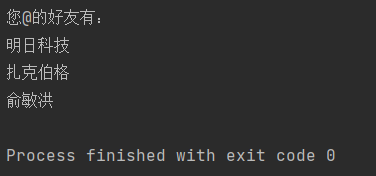
实战1:
str1 = '马走日,'
str2 = '象走田,'
str3 = '车走直路炮翻山,'
str4 = '士走斜线护将边,'
str5 = '小卒一去不回还。'
print("象棋口诀:" )
print(str1 + '\n' + str2 + '\n' + str3 + '\n' + str4 + '\n' + str5
实战2:
str1 = '津A·12345 沪A·23456 京A·34567'
list1 = str1.split(' ')
for item in list1:
if item[0:1] == '津':
print("第1张车牌号码:" + '\n' + item)
print("这张号牌的归属地:天津")
elif item[0:1] == '沪':
print("第2张车牌号码:" + '\n' + item)
print("这张号牌的归属地:上海")
elif item[0:1] == '京':
print("第3张车牌号码:" + '\n' + item)
print("这张号牌的归属地:北京")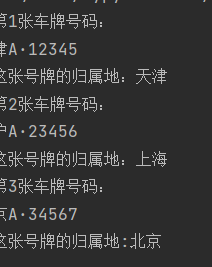
实战3:
import random
a = input("请输入要装入红包的总金额(元):")
b = input("请输入红包的个数(个):")
i = 1
for number in range(int(b)):
print("第", end='')
print(i, end='')
print("个红包:", end='')
c = random.uniform(0,int(a))
print(round(c,2), end='')
print("元")
i += 1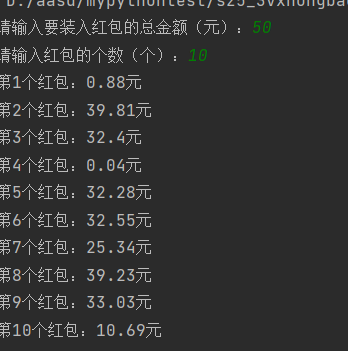
实战4:
weather='2018年4月17日 \t 天气预报:{:s} \t 20C~7°℃ \t 微风转西风3~4级\n \
08:00 \t 天气预报:{:s} \t 13℃ \t 微风\n\
12:00 \t 天气预报:{:s} \t 19℃ \t 微风\n\
16:00 \t 天气预报:{:s} \t 18℃ \t 西风3~4级\n\
20:00 \t 天气预报:{:s} \t 15℃ \t 西风3~4级\n\
00:00 \t 天气预报:{:s} \t 12℃ \t 微风\n\
04:00 \t 天气预报:{:s} \t 9℃ \t 微风'
a = weather.format('晴', '晴', '晴', '晴', '晴', '晴', '晴')
print(a)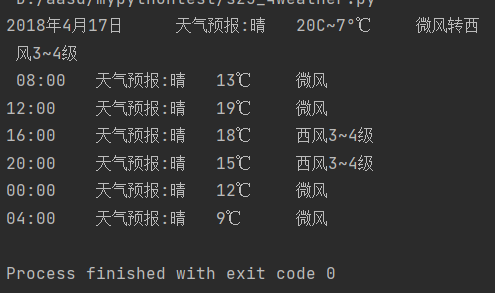

 浙公网安备 33010602011771号
浙公网安备 33010602011771号