【Redis】在Python的应用
目录
redis模块的应用
-
安装模块:
pip install redis连接本地示例,也可以连接远端
方式一:Redis实例化
from redis import Redis # 普通连接 conn = Redis( host="localhost", # 连接本地/远端 port=6379, # 端口 db=0, # 数据库 password=None, # 密码 ) conn.set('name','alan') print(conn.get('name')) # b'alan'方式二:使用连接池
# 连接池连接 # 第一步:创建池 POOL = redis.ConnectionPool(max_connections=10,host="localhost",port=6379, db=0) # 第二步,使用池,从池中拿一个连接 conn = redis.Redis(connection_pool=POOL) print(conn.get('name')) # b'alan' """ 这里需要注意,使用POOL必须是单例模式,也就是说POOL必须是单例的且全局只能有一个实例,无论程序怎么执行,POOL始终是同一个对象!所以建议把构造连接池的代码单独放入一个py文件中,因为导入py文件就是天然的单例模式,同一个py文件是一个对象(原理是导入的时候通过.pyc编译了) """ # POOL单例模式 '''redis_pool.py''' import redis POOL = redis.ConnectionPool(max_connections=10,host="localhost",port=6379, db=0) '''导入使用''' import redis from redis_pool import POOL # 第二步,使用池,从池中拿一个连接 conn = redis.Redis(connection_pool=POOL) print(conn.get('name')) # b'alan' # 多线程 from threading import Thread import redis import time from redis_pool import POOL def get_name(): conn=redis.Redis(connection_pool=POOL) print(conn.get('name')) for i in range(10): t=Thread(target=get_name) t.start() time.sleep(2) ''' 注意: py文件作为脚本文件的时候,不能使用相对导入,只能使用绝对导入,不然会报错,要从环境变量中开始导起 在pycharm中右键运行的脚本所在的目录,就会被加入到环境变量 '''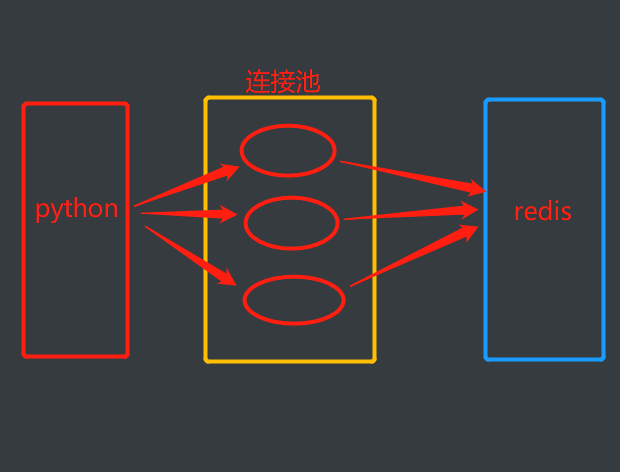
redis原生常见命令
| 序号 | 命令及描述 |
|---|---|
| 1 | DEL key 该命令用于在 key 存在时删除 key。 |
| 2 | DUMP key 序列化给定 key ,并返回被序列化的值。 |
| 3 | EXISTS key 检查给定 key 是否存在。 |
| 4 | EXPIRE key seconds 为给定 key 设置过期时间,以秒计。 |
| 5 | EXPIREAT key timestamp EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| 6 | PEXPIRE key milliseconds 设置 key 的过期时间以毫秒计。 |
| 7 | PEXPIREAT key milliseconds-timestamp 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern 查找所有符合给定模式( pattern)的 key 。 |
| 9 | MOVE key db 将当前数据库的 key 移动到给定的数据库 db 当中。 |
| 10 | PERSIST key 移除 key 的过期时间,key 将持久保持。 |
| 11 | PTTL key 以毫秒为单位返回 key 的剩余的过期时间。 |
| 12 | TTL key 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 |
| 13 | RANDOMKEY 从当前数据库中随机返回一个 key 。 |
| 14 | RENAME key newkey 修改 key 的名称 |
| 15 | RENAMENX key newkey 仅当 newkey 不存在时,将 key 改名为 newkey 。 |
| 16 | [SCAN cursor MATCH pattern] [COUNT count] 迭代数据库中的数据库键。 |
| 17 | TYPE key 返回 key 所储存的值的类型。 |
Python操作redis,使用redis字符串命令
一个键最大能存储 512MB
"""
1 set(name, value, ex=None, px=None, nx=False, xx=False)
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果
xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值
2 setnx(name, value)
2 setex(name, value, time)
3 psetex(name, time_ms, value)
4 mset(*args, **kwargs)
5 get(name)
5 mget(keys, *args)
6 getset(name, value)
7 getrange(key, start, end)
8 setrange(name, offset, value)
9 setbit(name, offset, value)
10 getbit(name, offset)
11 bitcount(key, start=None, end=None)
12 bitop(operation, dest, *keys)
13 strlen(name)
14 incr(self, name, amount=1)
15 incrbyfloat(self, name, amount=1.0)
16 decr(self, name, amount=1)
17 append(key, value)
"""
import redis
conn = redis.Redis(host="localhost",port=6379,db=0, )
# conn.set('name','Hans') # 存值
# conn.setex('age',5,18) # 设置过期时间5秒
# conn.psetex('age',5000,18) # 设置过期时间为5000毫秒
# print(conn.mget('name','age')) # 取值
# conn.setnx('text','python')
# conn.setnx('text','redis') # nx为true,text存在无法修改值,不存在可以修改
# conn.set('text','redis1',xx=True) # xx为true,text不存之无法修改,存在可以修改
# conn.mset({'text':'Linux','text1':'Python'}) # 批量设置
# conn.setrange('hobby',0,'ball') # 从0位置开始设置ball
# print(conn.get('text')) # b'Linux'
# print(conn.mget(['text','text1'])) # [b'Linux', b'Python']
# print(conn.mget('text','text1')) # [b'Linux', b'Python']
# print(conn.getset('name','monkey')) # 获取原来的name,并设置成新值,b'Hans'
# print(conn.get('name')) # b'monkey'
'''获取字节'''
# print(conn.getrange('name',0,1)) # b'mo'
# conn.set('name1','大帅逼')
# print(conn.getrange('name1',0,2).decode('utf8')) # 大
"""统计字符串长度"""
# 英文monkey
# print(conn.strlen('name')) # 6
# 汉字大帅逼
# print(conn.strlen('name1')) # 9
"""增值age+=1"""
# print(conn.incr('age'))
"""减值age-=1"""
# print(conn.decr('age'))
"""尾部追加"""
# print(conn.append('name','nb')) # monkeynb
Python操作redis,使用redis哈希命令
Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)
hset(name, key, value,mapping,items) # 设置值/多个值
hmset(name, mapping) # 批量设置多个值
hget(name,key) # 获取值
hmget(name, keys, *args) # 获取多个值
hgetall(name) # 获取所有值
hlen(name) # 获取长度(键值对个数)
hkeys(name) # 获取所有key
hvals(name) # 获取所有value值
hexists(name, key) # 判断key是否存在于哈希表中
hdel(name,*keys) # 删除一个值/多个值
hincrby(name, key, amount=1) # 累加,通过指定amount的值
hincrbyfloat(name, key, amount=1.0) # 累加浮点数
hscan(name, cursor=0, match=None, count=None) # 获取部分值
'''
cursor:游标,cursor=0,代表从位置0开始取
match:匹配规则
count:取多少条数据
注意:如果取100条,那么下次取会基于这次的游标位置继续往下取
'''
hscan_iter(name, match=None, count=None) # 取部分值,优化于hscan,可以一次取所有,也优化于hgetall设置count的值一般不会撑爆内存,内部使用的生成器yield
demo
import redis
conn = redis.Redis(host="localhost",port=6379,db=1)
# conn.hset('test','name','alan') # 设置一个值
# conn.hset('test',mapping={'age':19,'hobby':'ball'}) # 设置多个值
# print(conn.hget('test', 'name')) # 获取值---->b'alan'
# print(conn.hmget('test',['name','age'])) # [b'alan', b'19']
# print(conn.hgetall('test')) # 获取所有值---》{b'name': b'alan', b'age': b'19', b'hobby': b'ball'}
# print(conn.hlen('test')) # 获取键值对个数---->3
# print(conn.hkeys('test')) # 获取所有key--->[b'name', b'age', b'hobby']
# print(conn.hvals('test')) # 获取所有value---->[b'alan', b'19', b'ball']
# print(conn.hexists('test','name')) # 判断该哈希表中是否有该key---->True
# print(conn.hdel('test','name')) # 删除值
# print(conn.hincrby('test','age',amount=2)) # 累加,每次加2岁 --->21
# print(conn.hincrbyfloat('test','age',amount=2.2)) # 累加浮点数 --->23.2
# hscan获取部分值
# 写入值
# for i in range(1000):
# conn.hset('test1',f"key-->{i}",i)
# hscan获取值
# res=conn.hscan('test1', cursor=0, count=10)
# print(res)
# print(len(res[1])) # 100
# hscan_iter: #全取出所有值,分批取,不是一次性全取回来,减小内存占用
# res =conn.hscan_iter('test1',count=10)
# print(res) # <generator object ScanCommands.hscan_iter at 0x0000015B14BD2D58>
# for i in res:
# print(i)
Python操作redis,使用redis列表命令
一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
PS:图形界面看到的 上面是左,下面是右
lpush(name,values) # 从列表左边插入
lpushx(name,value) # 从列表左边插入,如果存在,才能操作
llen(name) # 求长度
linsert(name, where, refvalue, value) # 指定位置插入值
r.lset(name, index, value) # 对name对应的list中的某一个索引位置重新赋值
r.lrem(name, count,value) # 删除
'''
name:list名
value:要删除的值
num=0:要删除所有指定的值
num=1:删除一个
num=2:删除两个
num=-2:从后往前删2个
'''
lpop(name) # 从左侧弹出
rpop(name) # 从右侧弹出
lindex(name, index) # 获取索引位置为index的值lindex('list',0)
lrange(name, start, end) # 范围取,全闭区间
ltrim(name, start, end) # 保留start-end范围内的值,移除其他值
rpoplpush(src, dst) # 从一个列表取出最右边的元素,同时将其添加到另外一个列表的最左边
blpop(keys, timeout) # 从左边弹出值,如果没有timeout秒后返回nil(生产者消费者模型,消息队列)
brpoplpush(src, dst, timeout=0)
demo
import redis
conn = redis.Redis(host="localhost",port=6379,db=2)
# conn.lpush('mylist','alan1','alan2')
# conn.rpush('mylist','alan3')
# conn.lpushx('mylist','alan4') # 存在name,从左边插入成功
# print(conn.llen('mylist')) # 4
# conn.linsert('mylist','before','alan4','alan5') # 在谁前插入
# conn.linsert('mylist','after','alan5','alan6') # 在谁后插入
# conn.lset('mylist',0,'位置0重新赋值')
# conn.lrem('mylist',1,'位置0重新赋值') # 从左侧删除第一个值
# conn.lrem('mylist',-1,'alan3') # 从右侧删除第一个值
# conn.lrem('mylist','0','alan') # 从0开始,后面alan全删
# res = conn.lpop('mylist') # 从左往外弹出
# print(res) # b'alan5'
# print(conn.lindex('mylist',1)) # 获取索引为1的值---> b'alan2'
# print(conn.lrange('mylist',0,1)) # 获取范围内的值,[b'alan4', b'alan2']
# conn.ltrim('mylist',0,1) # 除了范围内的,都删除
# conn.blpop('mylist',timeout=2) # 阻塞式弹出,如果没有值,会一直阻塞
# 作用,可以实现分布式的系统---》分布式爬虫
# 爬网页,解析数据,存入数据库一条龙,一个程序做
# 写一个程序,专门爬网页---》中间通过redis的列表做中转
# 再写一个程序专门解析网页存入数据库
Python内使用Redis公共操作
公共操作与类型无关
delete(*names) # 删除单个name或者多个name
exists(name) # 判断是否存在name
keys(pattern='*') # 获取匹配的key,不写默认获取所有,支持模糊匹配
'''
模糊查询:
?代表匹配单个
*代表匹配任意长度
[ab]匹配ab:hel[ab]lo
'''
expire(name ,time) # 设置过期时间
rename(src, dst) # name重命名,src原来的,dst新的
move(name, db) # 把指定的name移动到指定db下
randomkey() # 随机返回key值
type(name) # 查看value类型
demo
import redis
conn = redis.Redis(host="localhost",port=6379,db=0)
# conn.delete('age','test') # 删除age和test
# print(conn.exists('age')) # 0
# print(conn.exists('name','name1')) # 返回存在的个数--->2
# conn.expire('name',3) # 设置3秒后,name过期
# conn.rename('hobby','myhobby') # 重命名
# conn.move('text',db=1) # 移动text到db1下
# print(conn.randomkey()) # 随机返回key
# print(conn.type('text1')) # b'string'
Redis 管道(支持事务)
import redis
pool = redis.ConnectionPool() # 创建池
conn = redis.Redis(connection_pool=pool) # 实例化
pipe = conn.pipeline(transaction=True)
pipe.multi() # 管道等待放入多条命令
# 以后用pipe代替conn操作
pipe.set('name', 'alan')
pipe.set('role', 'nb')
# 到此是往管道中放了命令,还没执行,直到下面的命令
pipe.execute() # 一次性执行管道中的所有命令
"""
如果是集群环境,不支持管道,数据过于分散,"锁不住"
"""
rediscluster模块运行redis集群
-
redis以集群的方式启动
如果不以集群方式启动,会出现
rediscluster.exceptions.RedisClusterException: ERROR sending 'cluster slots'-
最小化配置
至少搞六台redis服务器
-
修改配置文件文件
port 7001 # 客户端连接端口 bind 127.0.0.1 #实例绑定的IP地址 dir /opt/redis/cluster/7001/data # redis实例数据配置存储位置,不写默认跟配置文件一个地 daemonize yes # 是否以后台进程的方式启动redis实例 pidfile pidfile /var/run/redis_7001.pid # 指定该进程pidfile logfile 7001 # 日志文件,如果实例启动失败可以查看redis的log寻找原因 dbfilename dump7001.rdb cluster-enabled yes # 开启集群模式,这个是启动集群的关键参数接下来按照同样的方式创建7002,7003,7004,7005,7006的文件夹,修改配置文件
-
依次启动redis实例
redis-server /opt/redis/cluster/7001/redis.conf redis-server /opt/redis/cluster/7002/redis.conf redis-server /opt/redis/cluster/7003/redis.conf redis-server /opt/redis/cluster/7004/redis.conf redis-server /opt/redis/cluster/7005/redis.conf redis-server /opt/redis/cluster/7006/redis.conf -
查看启动结果:ps -ef | grep redis
-
创建一个集群
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005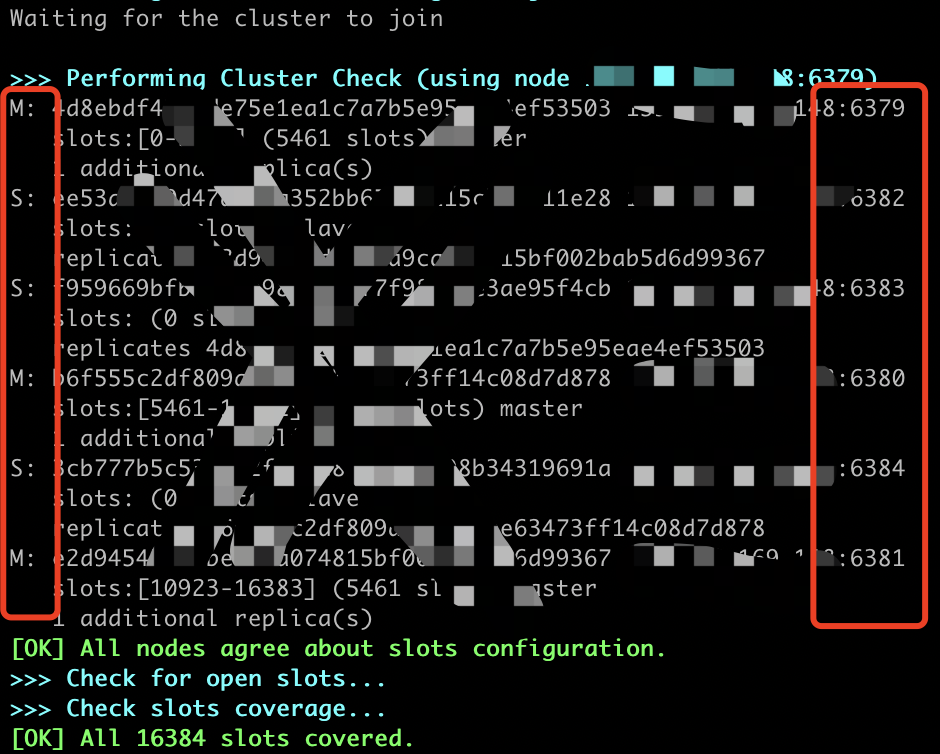
-
-
rediscluster模块的调用
-
rediscluster的安装
- redis-py-cluster: 最近还在维护
- rediscluster: 似乎很久没有更新了
pip install redis-py-cluster==2.1.3 or pip install rediscluster
-
代码实现
from rediscluster import RedisCluster # redis cluster 集群最少三主三从 startup_nodes = [ {"host":"192.168.3.25", "port":6379}, # 主 {"host":"192.168.3.25", "port":7001}, # 6379的从数据库 {"host":"192.168.3.25", "port":6380}, # 主 {"host":"192.168.3.25", "port":7002}, # 6380的从数据库 {"host":"192.168.3.25", "port":6381}, # 主 {"host":"192.168.3.25", "port":7003} # 6381的从数据库 ] # 连接集群 redis_server = RedisCluster(startup_nodes=startup_nodes, decode_responses=True,password='aaa') redis_server.set('name', 'lowman') redis_server.get('name')
-

