
面向对象第三单元(地铁)总结
面向对象系列:
(1)多项式求导:https://www.cnblogs.com/ZhaoLX/p/OO_Derivative.html
(2)电梯(多线程):https://www.cnblogs.com/ZhaoLX/p/OO_Elevator.html
(3)地铁(JML):https://www.cnblogs.com/ZhaoLX/p/OO_Subway.html
(4)UML图:https://www.cnblogs.com/ZhaoLX/p/OO_UML.html
OO_JML
前言
这个单元的作业在形式上是根据JML规格完成代码,在内容上涉及数据结构与算法(特别是图论相关)的很多知识。
由JML规格给定需求,让同学们进行“契约式”设计,是一种很新颖的形式。和指导书中自然语言给出的需求相比,JML规格更加全面地规定了程序员必须要实现严格满足功能的哪些方法,相当于是将有二义性的自然语言进行了“整治”与封装,严格划分了“甲方乙方”的职责。虽然由于JML语言的特性,在一定程度上增加了双方的工作量,但这是一种非常规范且可靠性极高的工程化方法,其思想非常值得我们进行学习。
在内容上与数据结构、算法挂钩,其实并不意在考察我们这两方面的编程能力,而是如何在面向对象的编程思想中将数据结构与算法两者进行一定程度的封装。在编程过程中也发现,架构对于代码复用及功能扩充的重要性:差的架构牵一发而动全身,一不小心就改出bug;好的架构功能独立,将耦合降到最低,每个类或方法职责分明,修改起来也事半功倍。
一、JML语言的理论基础
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。近年来,JML持续受到关注,为严格的程序设计提供了一套行之有效的方法。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具以静态方式来检查代码实现对规格的满足情况。一般而言,JML有两种主要的用法:
- 开展规格化设计。需求方将逻辑严格的规格,而非可能带有内在模糊性的自然语言描述交给代码实现人员。
- 针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
方法规格是JML的重要内容。它的核心内容包括三个方面,前置条件、后置条件和副作用约定。
- 前置条件:对方法输入参数的限制,如果不满足前置条件,方法执行结果不可预测,或者说不保证方法执行结果的正确性。
- 后置条件:对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,否则执行错误。
- 副作用约定:方法在执行过程中对输入对象或this对象进行了修改(对其成员变量进行了赋值,或者调用其修改方法)。
从设计角度,软件需要适应用户的所有可能输入,因此也需要对不符合前置条件的输入情况进行处理,往往对应着异常处理。从规格的角度,JML区分这两种场景,分别对应正常行为规格(normal_behavior)和异常行为规格(expcetional_behavior)。
可用的工具:
- OpenJML:根据JML规格,对实现的代码JML进行静态检查。
- JMLUnitNG:针对JML规格语法的描述,自动生成相应的测试样例,测试样例会侧重于边界条件的检查(比如相加时溢出等)。
二、JMLUnitNG
首先,根据讨论区伦佬的帖子完成了JMLUnitNG的准备工作。Demo中只有一个compare方法,是比较两个int型数据的大小,我又添加了一些方法进行测试,代码及结果如下:
// demo/Demo.java package demo; public class Demo { /*@ public normal_behaviour @ ensures \result == lhs - rhs; */ public static int compare(int lhs, int rhs) { return lhs - rhs; } /*@ ensures \result == a + b; */ public static int add2(int a, int b) { return a + b; } /*@ ensures \result == a - b; */ public static int minus(int a, int b) { return a - b; } /*@ ensures \result == a * b; */ public static int mult(int a, int b) { return a * b; } /*@ ensures \result == a / b; */ public static int div(int a, int b) { return a / b; } /*@ ensures \result == a % b; */ public static int mod(int a, int b) { return a % b; } /*@ public normal_behaviour @ requires a > 0; @ ensures \result == a; @ public normal_behaviour @ requires a <= 0; @ ensures \result == -a; */ public static int abs(int a) { return (a > 0)? a : -a; } /*@ ensures \result == Math.pow(a, b); */ public static double pow(double a, int b) { double re = 1; for (int i = 0; i < b; i++) { re *= a; } return a; } public static void main(String[] args) { compare(114514,1919810); add2(1, 2); minus(1, 2); mult(1, 2); div(1, 2); abs(1); pow(3.1, 5); } }
[TestNG] Running: Command line suite Failed: racEnabled() Passed: constructor Demo() Failed: static abs(-2147483648) Passed: static abs(0) Passed: static abs(2147483647) Failed: static add(-2147483648, -2147483648) Passed: static add(0, -2147483648) Passed: static add(2147483647, -2147483648) Passed: static add(-2147483648, 0) Passed: static add(0, 0) Passed: static add(2147483647, 0) Passed: static add(-2147483648, 2147483647) Passed: static add(0, 2147483647) Failed: static add(2147483647, 2147483647) Passed: static compare(-2147483648, -2147483648) Failed: static compare(0, -2147483648) Failed: static compare(2147483647, -2147483648) Passed: static compare(-2147483648, 0) Passed: static compare(0, 0) Passed: static compare(2147483647, 0) Failed: static compare(-2147483648, 2147483647) Passed: static compare(0, 2147483647) Passed: static compare(2147483647, 2147483647) Passed: static div(-2147483648, -2147483648) Passed: static div(0, -2147483648) Passed: static div(2147483647, -2147483648) Failed: static div(-2147483648, 0) Failed: static div(0, 0) Failed: static div(2147483647, 0) Passed: static div(-2147483648, 2147483647) Passed: static div(0, 2147483647) Passed: static div(2147483647, 2147483647) Passed: static main(null) Passed: static main({}) Passed: static minus(-2147483648, -2147483648) Failed: static minus(0, -2147483648) Failed: static minus(2147483647, -2147483648) Passed: static minus(-2147483648, 0) Passed: static minus(0, 0) Passed: static minus(2147483647, 0) Passed: static minus(-2147483648, 2147483647) Passed: static minus(0, 2147483647) Passed: static minus(2147483647, 2147483647) Passed: static mod(-2147483648, -2147483648) Passed: static mod(0, -2147483648) Failed: static mod(2147483647, -2147483648) Failed: static mod(-2147483648, 0) Failed: static mod(0, 0) Failed: static mod(2147483647, 0) Passed: static mod(-2147483648, 2147483647) Passed: static mod(0, 2147483647) Passed: static mod(2147483647, 2147483647) Failed: static mult(-2147483648, -2147483648) Passed: static mult(0, -2147483648) Failed: static mult(2147483647, -2147483648) Passed: static mult(-2147483648, 0) Passed: static mult(0, 0) Passed: static mult(2147483647, 0) Failed: static mult(-2147483648, 2147483647) Passed: static mult(0, 2147483647) Failed: static mult(2147483647, 2147483647) Passed: static pow(-Infinity, -2147483648) Passed: static pow(0.0, -2147483648) Passed: static pow(Infinity, -2147483648) Passed: static pow(-Infinity, 0) Passed: static pow(0.0, 0) Passed: static pow(Infinity, 0) Passed: static pow(-Infinity, 2147483647) Passed: static pow(0.0, 2147483647) Passed: static pow(Infinity, 2147483647) =============================================== Command line suite Total tests run: 70, Failures: 20, Skips: 0 ===============================================
可以发现,JMLUnitNG主要是对边界情况进行测试,对于int型的输入,就会测试Integer.MAX_VALUE, 0, Integer.MIN_VALUE这三种情况;如果一个方法输入n个int,那么就会测试这三类数据的n-排列。这在简单情况下是比较有用的找Bug方式,但是一旦程序逻辑复杂起来,可能这三个数值不足以代表极端情况,debug的准确度就有所下降。此外,我还尝试了输入为String的方法,JMLUnitNG则会着重测试空串""和空指针NULL。
Failed: static contains(null, null) Failed: static contains(, null) Failed: static contains(null, ) Passed: static contains(, )
三、三次作业架构设计
这三次作业如果只考虑正确性的话,实现起来都是比较容易的,不太需要动脑子用基础的数据结构+算法就可以写完。但由于限制了CPU时间,所以需要进行一些优化。可以看得出来,课程组设置CPU时间的限制并不是鼓励我们像前两个单元一样进行疯狂优化(因为并没有性能分),而只是通过这个的设置迫使我们必须要考虑如何使复杂度能有“质”的下降,而不是纠结于常数上“量”的优化。由于图结构变更指令的极少量和查询指令的极大量,一个需要秉持的思路就是将查询的复杂度均摊到图结构变更中,让查询的复杂度接近O(1)。
1、第一次作业
第一次作业整体来讲比较简单,任务明确,规格易懂。
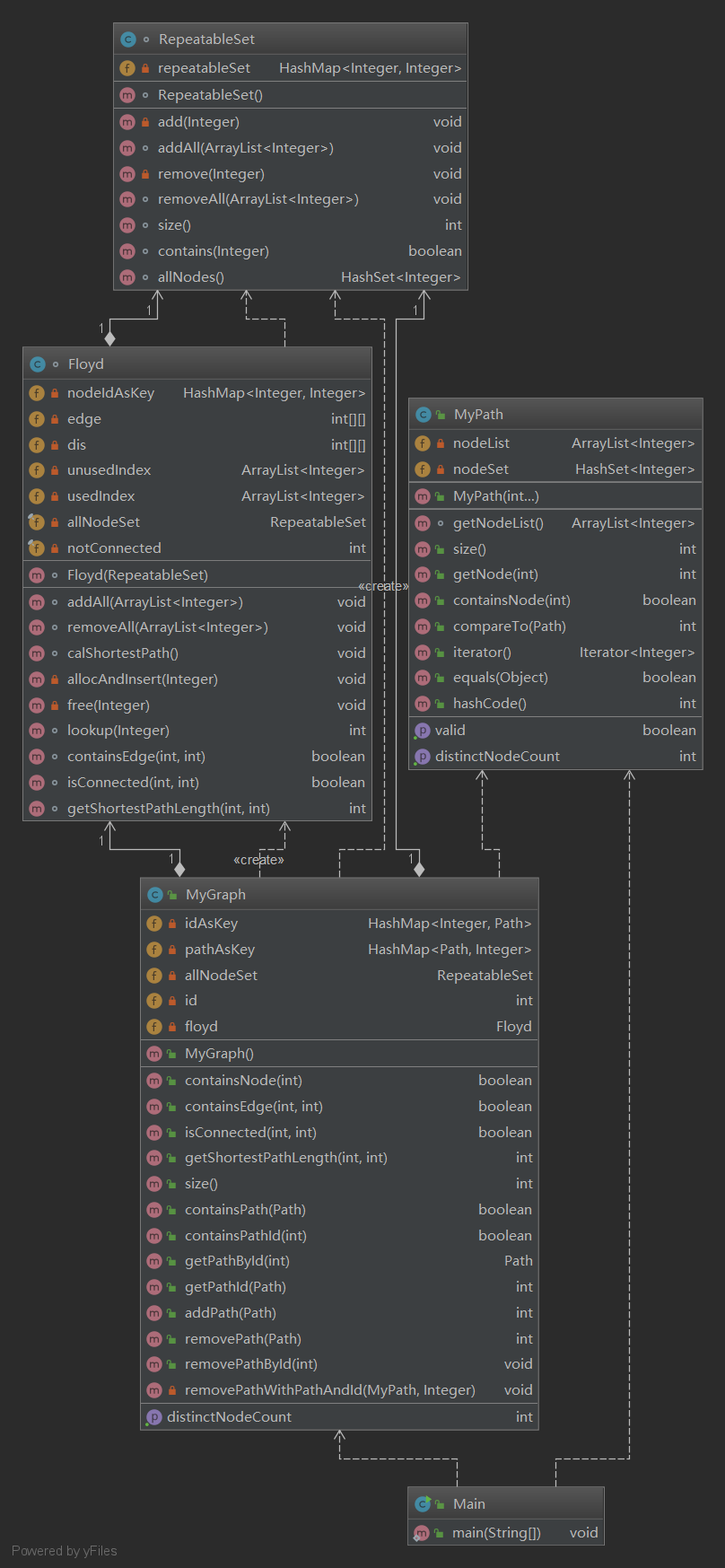
MyPath类中,我的成员变量是:
private ArrayList<Integer> nodeList; private HashSet<Integer> nodeSet;
其中ArrayList用于存储路径。HashSet用于在O(1)复杂度上实现getDistinctNode方法。
MyPathContainer类中,我的成员变量是:
private HashMap<Integer, Path> idAsKey; private HashMap<Path, Integer> pathAsKey; private RepeatableSet allNodeSet;
其中两个HashMap用于Path和PathId的双向查找。RepeatableSet为我自己实现的另外一个类,它是一个可重集合,内部实现是通过 HashMap<Integer, Integer> ,key值是元素,value值是该元素对应的重数,当value值为0时,将key-value键值对移出HashMap。RepeatableSet类内部模仿HashSet类实现了void add(Integer node), void addAll(ArrayList<Integer> nodes), void remove(Integer node), void removeAll(ArrayList<Integer> nodes)四个方法,作为接口供MyPathContainer中的方法调用。
下边是我这次作业的类图:
2、第二次作业
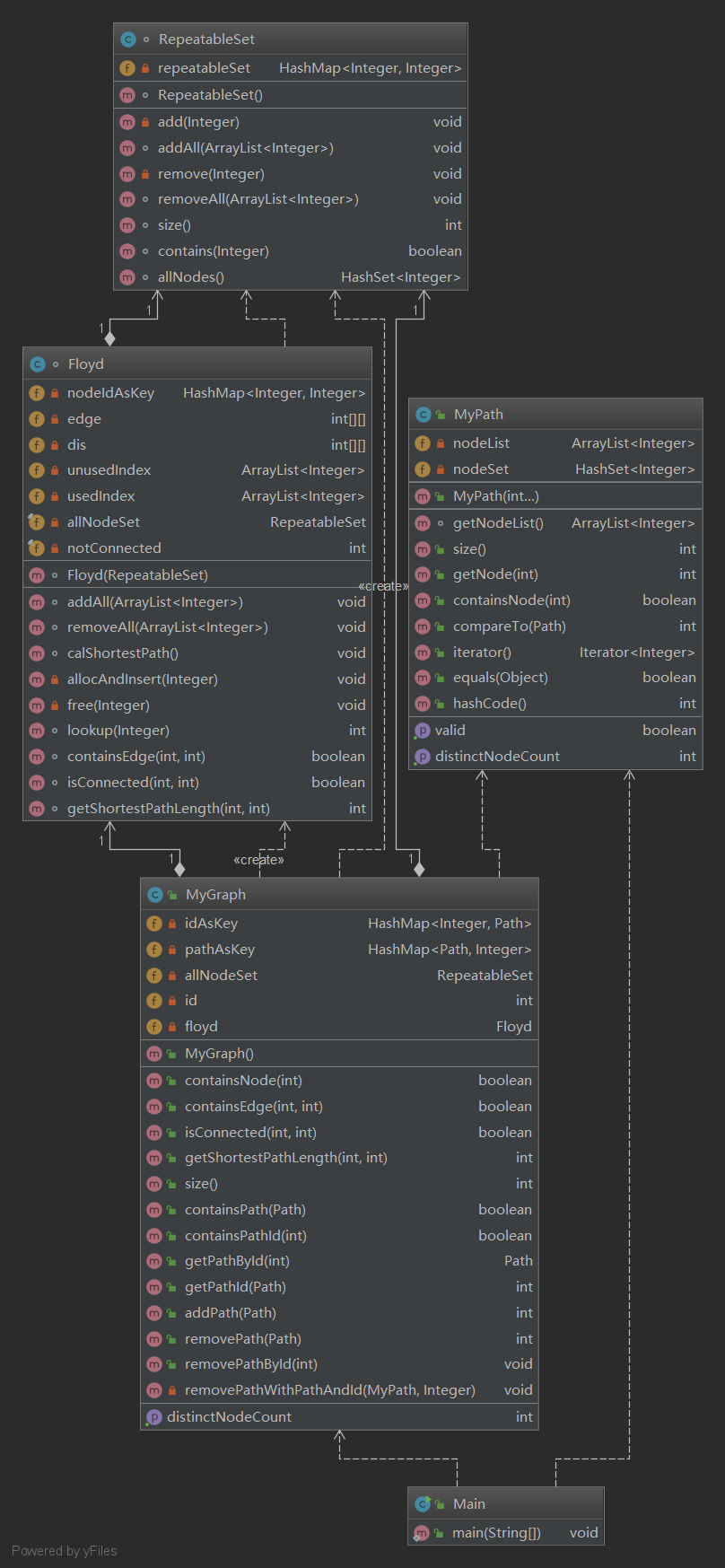
在第一次作业的基础上,第二次作业需要在PathContainer的基础上,抽象出一个图结构。在这个图结构下,需要完成以下几个方法:查询结点是否存在containsNode,查询边是否存在containsEdge,两个结点是否可达isConnected,两个结点之间的最短路径getShortestPathLength。其中containsNode可以直接在PathContainer中利用RepeatableSet实现;isConnected和getShortestPathLength实则是同一个问题,即求最短路径;存储边及其个数的数据结构是求最短路径的基础,所以containsEdge与求最短路径息息相关。考虑到这次的数据规模(最多同时存在250个不同的点)和前边提到的大量查询vs极少量图变更,所以采用了Floyd算法进行最短路径的计算。
我这次直接将和图有关的数据结构和算法都封装到了另一个类中,并命名为Floyd。现在看来,这种做法其实是非常不可取的,其缺点体现在以下两个方面:
- 有一些数据结构,如上文提到的“存储边及其个数”,和查询最短路径虽然有着很大的关系,但它实则是图Graph的一个属性,应当直接放在MyGraph类中,而非Floyd类中。
- 将这个类取名为Floyd也是不合适的,Floyd只是一个算法,而为了求最短路径需要的数据结构,如邻接矩阵、距离矩阵,都是与算法无关的,不论采用什么算法几乎都需要这两个数据结构,所以可以将他们直接放在MyGraph中,或者封装到一个求最短路径的类,例如名为ShortestPath的类中;再将Floyd算法单独封装,或将其内嵌在ShortestPath类中(ShortestPath类自然也可以内嵌别的求最短路径的算法)。
虽然设计上存在一些失误,但我还是按照我当时写代码的逻辑进行讲解。Floyd类中的成员变量如下:
private HashMap<Integer, Integer> nodeIdAsKey; //int->250 private int[][] edge; // 存储边的个数 private int[][] dis; private ArrayList<Integer> unusedIndex; private ArrayList<Integer> usedIndex;
其中edge和dis两个静态数组比较容易理解,是边的个数矩阵(不是邻接矩阵,因为这次作业中边的长度都为1,所以不需要邻接矩阵来存储边的长度),来表示一条边在图中出现的次数(即为0时就是不存在这条边,不为0时就是存在这条边)。dis就是距离矩阵。
这次作业中比较值得说道的一点是:NodeId的范围是int,如果开个int*int的数组,那毫无疑问内存会爆炸。但是这次作业保证图中在任意时刻都不会存在超过250个的不同的点,也就是说,理论上讲,一个250*250的静态数组就可以完美表达这个图中各个结点的邻接关系,前提是做好从int到[0, 249]的映射。这个映射的过程和OS中内存管理分配页面的过程非常类似,主要就是以下两个步骤:
- 分配(alloc)并建立映射(insert):分配[0, 249]中的一个数字作为一个NodeId的index(index是我自己取的名字,现在看起来这个名字并不好,但是就将错就错地用了两次作业)。分配过程即从unusedIndex中取出一个未被使用过的index作为该nodeId的index,并添加到usedIndex中。建立映射即将<NodeId, index>这个键值对put到nodeIdAsKey中。
- 取消映射(free):将已经建立的映射移除,即从nodeIdAsKey中移除<NodeId, index>这个键值对,将index从usedIndex移除并加入到unusedIndex中。
拥有了映射关系,可以在250*250的空间内操作后,我们就可以利用正常的Floyd算法进行求解了。一次O(n^3)的计算,可以满足接下来在图没有变更情况下的所有查询。Floyd算法的简洁还是令人印象深刻的,所以想把它特别贴在下边:
1 void calShortestPath() { 2 for (int i : usedIndex) { 3 for (int j : usedIndex) { 4 if (i == j) { continue; } 5 if (edge[i][j] > 0) { // dis数组的初始化 6 dis[i][j] = 1; 7 } else { 8 dis[i][j] = notConnected; 9 } 10 11 } 12 } 13 for (int k : usedIndex) { // 只需要对usedIndex中的元素进行遍历 14 for (int i : usedIndex) { 15 for (int j : usedIndex) { 16 if (dis[i][k] != notConnected && dis[k][j] != notConnected 17 && dis[i][k] + dis[k][j] < dis[i][j]) { 18 dis[i][j] = dis[i][k] + dis[k][j]; 19 } 20 } 21 } 22 } 23 }
下边是我这次作业的类图:
3、第三次作业
在第二次作业的基础上,第三次作业从Graph结构中又建立出了一个RailwaySystem。除了最短路径ShortestPath问题,又多了LeastTicketPirce, LeastTransferCount, LeastUnpleasantValue这三个问题。和最短路径问题相比,这三个问题的难点在于,它们都涉及到了换乘这一概念,而且换乘在这个三个问题中都是有其“惩罚”的,比如换乘一次,在LeastTicketPirce中要多付两元钱,在LeastTransferCount中只有换乘是需要记录的,在LeastUnpleasantValue会增加一个固定的unpleasant值。为了应对这个问题,大体上OO玩家们分成了两派:拆点和连边。我选择了拆点的方法,因为大佬室友可以carry我 这种方法比较直观。所以当我在理解了连边派的核心思想后,不禁为它的简洁与优美所折服。当我得知这种方法还贼快的时候,我不禁泪流满面。可见数学真的是非常重要的,创意的想法与优美的算法真的是胜过吭哧吭哧写+调半天代码。
“拆点”思想
回到正题,拆点法。拆点法的核心思想就是,将不同路径上的相同结点拆成不同结点,给连接着两个不同结点的边赋予权值,将其转化为普通的求最短路径问题。拆点法的重中之重就是“如何拆点”,因为极端情况下,同一个结点可能处于50条路径上,这样80个不同的结点就可以拆成4000个拥有不同Index的点,要求NodeId为A的结点到NodeId为B的结点的最短路径,可能需要考虑50*50种情况,这个查询的代价显然稍微大了一些。所以,我采用了我聪明伶俐机灵可爱的是有的“汇点”的做法。
对于每一个点,都要设置它的“起点”与“终点”,不同路径上的相同结点共享这对起点终点。点与起点终点三个点中间形成一个单向三角形,即存在三条单向边:点→终点(权值恒为0)、终点→起点(权值为“换乘惩罚”),起点→点(权值恒为0)。这样做的目的及其正确性在于,起点的作用是统一管理处于不同路径上的结点,意味着从一个起点出发可以以0的代价到达换乘点中的任意一个,相当于是从这些换乘点中的一个出发;同理,终点的作用也是如此。这样一来,就不需要对50*50种情况进行组合及排列,只需要对一个起点→一个终点这一种情况进行计算。
当然这样做也不是没有代价的。在不添加起点及终点的情况下,一个地铁系统中最多有4000个Index,添加了之后会导致index的增多。但增加的个数可以控制在200以内,相比于4000个index还是非常可以接受的。
最短路径算法
完成拆点之后,这四个问题其实就变成了一个问题:求解最短路径。由于n的增大(第二次作业中n为250,本次作业中n为4000+),Floyd不再适用,所以我采用了spfa+cache的机制进行单源最短路的计算。
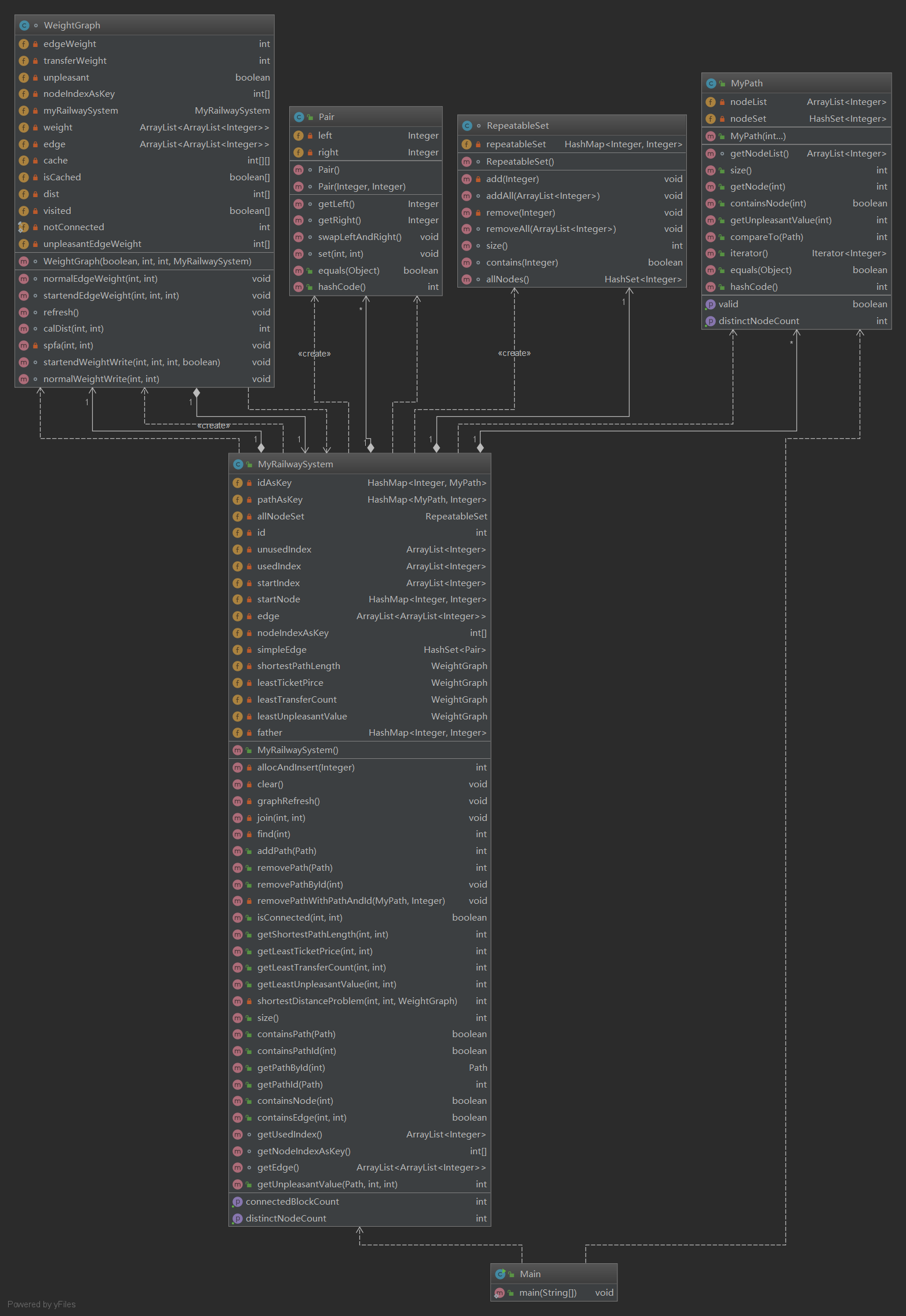
在架构上,MyRailwaySystem复用了上一次作业的MyGraph,将上一次Floyd类(是的就是那个非常失败的设计)的部分成员变量及方法整合进来,此外还添加了四个成员变量:带权图。带权图WeightGraph是我新实现的一个类,其内部包含计算最短路径时需要的数据结构及方法。它的成员变量如下:
private int edgeWeight; //普通边权重 private int transferWeight; //换乘边权重 private boolean unpleasant; //是否是unpleasant问题 private int[] nodeIndexAsKey; private MyRailwaySystem myRailwaySystem; private ArrayList<ArrayList<Integer>> weight; private ArrayList<ArrayList<Integer>> edge; private int[][] cache; private boolean[] isCached; private int[] dist;
其中需要特别解释一些成员变量:
- unpleasant:LeastUnpleasantValue问题和其它三个问题的区别在于,这个问题的edgeWeight并非固定,而是和两个结点的NodeId有关,所以需要特别标注某个对象是否是LeastUnpleasantValue问题的实例。
- 两个ArrayList<ArrayList<Integer>>:两个配合起来看就是邻接矩阵。用嵌套的ArrayList存储是这个这个方法中防止TLE的重点,这一点在Bug分析中会有更加深入的讨论。其中edge存储的是一个index结点和哪些结点相连,weight存储的是相对应的这两个结点之间的权值,这就是二者必须配合才能当作权值矩阵的原因。
然后就是利用spfa算法求出单源最短路径,并将其存在cache中,更新cache和isCached两个变量。spfa算法并非OO的重点,所以在此就不赘述了。
下面是这次作业的类图:
四、bug分析
我的bug
这三次作业中,我的第二次作业出现了严重的超时,第三次改进前的版本也有严重的超时问题。对这两个代码进行分析,我有以下一些收获与想法。
在第二次作业中,我写了两个版本的代码:一个是上文提到的静态数组法,另一个是受同学启发写的HashMap法。二者的主要区别在于,静态数组法通过以静态数组int[][]的方式存储邻接矩阵(更准确的其实是,存储一条边在图中出现的次数),而HashMap法将<Pair<Integer, Integer>, Integer>作为这一数据结构的容器(其中Pair代表连接两个结点的边,value的Integer记录一条边的出现次数)。在第三次作业中,我也尝试了利用HashMap存储邻接矩阵的写法。最终结果就是,这两个写法都会超时。HashMap法超时的原因在于:
- 用了HashMap这个容器。我们常认为HashMap是一种非常高效的容器,但是其实在一些情况下它的速度会很慢,比如要计算key的HashCode,比如HashMap的一些操作只是近似O(1)但并不是真正的O(1)....
- 用了javafx中的Pair。本来想手写一个Pair类,结果被同学提醒有这么一个现成的类,没多想就直接用了,后来发现这就是个HashMap啊...只不过不严格区分key和value了...在Floyd中,由于需要知道一条边是否存在,所以需要反复new一个Pair类型的对象,并在HashMap中查询是否包含该key值,这部分的时间开销其实是非常恐怖的。
所以在第三次作业中,我采用了上述提到的嵌套ArrayList的容器来存储邻接矩阵。它的好处在于:
- 和静态数组相比更加稠密。映射后的n为4200的静态数组已经稠密了很多,但相对于嵌套ArrayList来说,还是过于稀疏了。尤其是在初始化邻接矩阵的时候,需要初始化4200^2个int,还是有一点费时的。
- 和HashMap相比操作更快。两个嵌套ArrayList,一个edge用于记录一个结点和哪些结点相连,一个weight用于记录这个两个结点之间的权值。所以edge用于遍历,weight用于取值计算。遍历的方法即get方法,相对于HashMap来说,都是更加直接且快捷的操作,不会有额外的计算时间。
找到bug的方法
不论是在自测阶段,还是互测阶段,如何快速发现并定位bug是OO这门课每一次作业的一个重点工作。而找到bug的方法大概可以分为以下三种:
- 对拍:对拍是老朋友了,这次的三部曲(构造样例、输入样例、评测输出)中,输入样例照常用重定向完成,评测输出直接fc比较即可,困难的地方就在于构造测试样例。 这个单元的测试样例需要在两个方面做努力:一是对于边界情况的覆盖性(正确性),二是在极端情况下程序的运行时间(性能)。
- JUnit:JUnit这个工具是在指导书的强烈建议(和OO课上测试的要求)下进入大家视野的一个debug工具。和对拍器不同,它不是一个黑盒测试,而是针对某个方法所进行的测试。由于“覆盖率”这一概念的引入,我认为JUnit非常适合对那些逻辑复杂、分支众多的方法进行测试,首先保证覆盖率达到100%,再利用一些边界数据进行测试,就可以较好地确定一个方法的正确性。
- JML相关:这个就是上文提过的JML工具链,其中包括OpenJML, JMLUnitNG等。其中OpenJML实际使用起来体验比较一般,主要在于它对JML的语法要求非常严格,比如JML规定了静态数组,那么代码中就必须用静态数组实现。课程组对于这次博客中体验工具的要求放宽了,我就尝试了一个非常简单的场景,两个int型数据相加(代码见下),JML工具帮助我检查出了int型溢出的错误(信息见下)
//@ ensures \result == a + b; public static int add(int a,int b) { return (a + b); }
Completed proof of Test.add(int, int) with prover cvc4 - with warnings [2.39 secs] Completed proving methods in Test [18.70 secs] Summary: Valid: 0 Invalid: 1 Infeasible: 0 Timeout: 0 Error: 0 Skipped: 0 TOTAL METHODS: 1 Classes: 0 proved of 1 Model Classes: 0 Model methods: 0 proved of 0 DURATION: 10.2 secs [13.24] Completed
五、规格撰写及理解的心得体会
JML规格带给我们最重要的意义是什么呢?我觉得是这种“契约式”设计的思想。契约之中,甲方和乙方的责任被明确区分:提供JML规格的一方不关心实现细节,只将一个方法当成一个模块,对于模块的输入和输出做出严格的限制;实现者要做的则是满足JML规格中的全部要求,因为只要满足了JML规格,那么就一定能保证代码的正确性,此外在力所能及或者实际情况需要的的情况下尽量提升性能。
但JML规格并不是没有缺点的,其最大的缺点就在于,写起来实在是太难了。以最短路径问题为例,如果用自然语言描述“最短路径”四个字其实足以让有一定数据结构+算法基础的程序员了解需求,再辅以说明问题具体情境的设计文档或Javadoc,其实是可以做到无二义性地像程序员传递需求的。但是在JML规格语法中,要表达这个需求所需要的代码量是非常大的,还需要封装一些方法来保证最短路径方法的简洁性和易懂性;此外JML语法太容易出错了,课程组的老师助教们哪个不是经验丰富的程序员?但这也并不能保证写出来且经过反复检查的JML规格就是没有bug的,这从指导书发布后仍需回炉修订可见一斑。
JML规格有利有弊,但不论如何,从其发源思想及实际撰写中,我们是可以学到很多东西的:
- 把方法当功能模块的思想。这个思想和JUnit的思想其实是一致的,JUnit就是将一个方法当做一个模块,针对这个模块进行白盒测试,我想着也是为什么在这一单元中,指导书向我们强烈安利JUnit这一个单元测试工具。JUnit在编写测试代码时可以针对JML规格中的正常行为规格(normal_behavior)和异常行为规格(expcetional_behavior)分别编写正例和反例,构造符合前置条件的样例,调用方法后对后置条件是否满足进行判断。
- 运用类型规格。类型规格是针对Java程序中定义的数据类型所设计的限制规则,它对Java代码中的数据进行了静态和动态的限制,保证数据不会出现一些异常情况,而一直在可控制的范围之内。JML中的类型规格非常多,我们常用的是不变式限制(invariant)和约束限制(constraints),运行类型规格,可以化简我们规格中的后置条件,使得我们不用在每一个方法的后置条件中都对数据的状态进行限制。
- 分层抽象JML规格。这个体现在第三次作业的规格中,在上文也提到了。对于换乘情景下的最短路径问题,如为了撰写getLeastTicketPrice这一个方法的规格,又自定义了isConnectedInPathSequence方法和getTicketPrice方法两个方法,将“定位换乘”与“计算路径长度”定位为低层次的功能,由计算最低票价方法调用这两个功能。这使得逻辑在一定程度上更加清晰,在每一个方法中可以聚焦于一个特定的功能,这也是一直以来都被强调的分层抽象的思想。
写在最后
总体来说,在这一个单元中我还是收获了很多的,既有契约式编程思想的训练,又补了数据结构和算法的课,对Java中一些容器也有了更加深入的了解。若说这一单元对自己不太满意的地方,倒也不是第二次作业由于超时而强测爆炸,而是自己没有好好看一遍课程组下发的输入输出接口包的具体实现。面对AppRunner,几百行的代码和陌生的语法让我望而生畏,连看一遍都没能做到。虽然这不是这个单元要求的内容,但依然觉得自己在单元之中错失了一个学习优秀代码的机会,希望自己有时间的时候还是可以仔细研究一下输入输出接口。
还剩最后一个单元的OO了,加油!

