
BlogEngine.Net架构与源代码分析系列part6:开放API——MetaWeblog与BlogImporter
2008-11-07 17:28 GUO Xingwang 阅读(5285) 评论(3) 编辑 收藏 举报 一款优秀的Blog系统少不了一些公开的API。BlogEngine.Net实现了标准的MetaWeblog API接口来允许用户通过客户端软件来发布自己的Blog,此外它还实现了将其它Blog系统中的文章(标准格式的BlogML或Rss)导入到BlogEngine.Net中来的BlogImporter接口,在这篇文章里我将对这些开放部分进行详细的介绍,对于涉及到的一些相关知识点也给出链接或做简单的描述。
一款优秀的Blog系统少不了一些公开的API。BlogEngine.Net实现了标准的MetaWeblog API接口来允许用户通过客户端软件来发布自己的Blog,此外它还实现了将其它Blog系统中的文章(标准格式的BlogML或Rss)导入到BlogEngine.Net中来的BlogImporter接口,在这篇文章里我将对这些开放部分进行详细的介绍,对于涉及到的一些相关知识点也给出链接或做简单的描述。
一款优秀的Blog系统少不了一些公开的API。BlogEngine.Net实现了标准的MetaWeblog API接口来允许用户通过客户端软件来发布自己的Blog,此外它还实现了将其它Blog系统中的文章(标准格式的BlogML或Rss)导入到BlogEngine.Net中来的BlogImporter接口,在这篇文章里我将对这些开放部分进行详细的介绍,对于涉及到的一些相关知识点也给出链接或做简单的描述。
MetaWeblog API使用标准的Http协议封装的XMLRPC实现(类似于WebService中的Soap协议)
1.首先让我们了解一下什么是MetaWeblog API
MetaWeblog API (MWA)是一套编程接口,允许外面的程序能取得和设置Blog文章的文本或属性。它是建立在XMLRPC接口之上,并且已经有了很多的实现。
2.MetaWeblog API有三个基本的函数规范:
metaWeblog.newPost (blogid, username, password, struct, publish) 返回一个字符串,可能是Blog的ID。
metaWeblog.editPost (postid, username, password, struct, publish) 返回一个Boolean值,代表是否修改成功。
metaWeblog.getPost (postid, username, password) 返回一个Struct。
其中blogid、username、password分别代表Blog的id(注释:如果你有两个Blog,blogid指定你需要编辑的blog)、用户名和密码。由于篇幅有限,关于MetaWeblog API的更多信息请参考文末的链接部分。
3.BlogEngine.Net中的MetaWeblog API的实现分析
BlogEngine.Net的XMLRPC调用主要是由BlogEngine.Core.API.MetaWeblog命名空间下的几个类型来完成的。
首先客户端软件通过Http协议向MetaWeblogHandler提交了一个标准的XML请求,MetaWeblogHandler是一个HttpHandler,之后MetaWeblogHandler执行ProcessRequest来处理这个请求,最后将处理结果再封装为XML返回给客户端软件。
下面让我对这部分涉及到的几个类型做一个简单的介绍:
MetaWeblogHandler:不用说了,处理的主逻辑部分,ProcessRequest是处理的入口点,将一些具体处理的部分委托给一些私有成员,例如:
internal string NewPost(string blogID, string userName, string password,
MWAPost sentPost, bool publish)
XMLRPCRequest:是对一个HttpRequest信息提取以后的封装,里面是一些解析XML提取信息的相关属性与方法,例如远程调用方法名,参数,文章信息等。
XMLRPCResponse:与XMLRPCRequest是对应的,它的Response方法会将执行结果生成XML并传递给HttpResponse之后返回给客户端。
还有一些类似于MWABlogInfo,例如MWAMediaObject,MWAPost等的结构是对于业务对象类型数据提取信息的封装,主要是为了交换信息而定义的。
从BlogEngine.Net的实现上看,它支持很多标准的协议,这些协议很多都是基于XML进行通信的,而BlogEngine.Net一般都是通过HttpHandler来处理这些标准的。
BlogEngine.Net的导入和导出Blog文章的实现分析
BlogEngine.Net的导入支持Rss和BlogML两种格式,导出支持BlogML格式(也具有Rss的请求链接,后续文章将讲解)。登录以后进入Settings我们发现在页面的最底部提供了导入和导出功能的两个按钮,查看codebefore的代码我们看到这两个按钮的请求地址为:
<input type="button" value="<%=Resources.labels.import %>"
onclick="location.href='http://dotnetblogengine.net/clickonce/blogimporter/
blog.importer.application?url=<%=Utils.AbsoluteWebRoot %>&username=<%=Page.User.Identity.Name %>'" />
<input type="button" value="<%=Resources.labels.export %>"
onclick="location.href='blogml.axd'" />
原来在导入时会向http://dotnetblogengine.net/clickonce/blogimporter/blog.importer.application发一个请求,后面跟上相关参数信息,这是一个使用clickonce部署的客户端应用程序,打开以后可以看到:
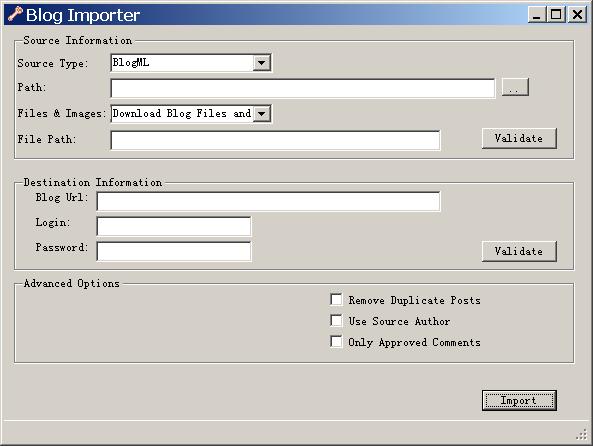
使用它我们可以完成将其它Blog系统中的Blog文章导入到BlogEngine.Net中来,同样,这些文件的格式都是标准的XML文件。
在BlogEngine.Net的Web站点中我们可以看到一个api的目录,那里面有一些Blog导入所使用的WebService接口,这个客户端导入工具同样也是调用站点中的这些接口函数来完成导入的,注意
http://dotnetblogengine.net/clickonce/blogimporter/blog.importer.application
后面的参数url就是告诉导入工具WebService的所在站点地址,username就是导入的目标用户名。这个导入的WebService应该属于BlogEngine.Net自己定义的接口,并不是标准的接口,但是可以被标准调用(Soap),例如我们也可以自己写一个导入的程序调用这个接口来完成导入功能。
对于这个WebService的实现比较简单,我不想多说了,但是希望大家注意两点比较有特色的地方:
1.在部分接口中使用了SoapHeader来完成用户信息的验证。例如:







 }
} }
}2.对于一些被导入的Blog中的图片和文件等的存储和处理。例如下载文件和链接的加入:
此外在api中还有一个TagMiniView.aspx,它的作用我想就是允许在其它站点中引用本站点的云标签信息。对于Blog的导出功能通过请求的URL可以看出,又是通过HttpHandler来处理生成BlogML文档的。
总结
1.一个开放的系统需要支持很多标准,包括通信标准,标准文档等,BlogEngine.Net在这方面做得很到位。
2.对于使用clickonce部署的客户端来导入Blog文章感觉很值得借鉴。
参考文章
一边写文章,一边阅读源代码,有些东西让我恍然大悟.
上一篇:BlogEngine.Net架构与源代码分析系列part5:对象搜索——IPublishable与Search
下一篇:BlogEngine.Net架构与源代码分析系列part7:Web2.0特性——Pingback&Trackback
【来源】:http://thriving-country.cnblogs.com/
本文版权归作者和博客园共同所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。

