
表达式展开程序设计 ——OO第一次作业总结
——OO第一次作业总结
一、设计理念——架构最重要
软件学院副院长张莉教授讲过,任何软件都有其生命周期,原因之一是客户不断变化的需求导致开发人员不断更改软件设计。随着更改次数增多,软件的架构越发凌乱,软件的维护成本也越发高昂。当维护成本达到一定程度时,这款软件便走到了生命的终点。
虽然绝大多数软件难逃一死,但是好的架构可以延缓软件的死亡进程。好的架构具有强大的可扩展性,这意味着面对需求的变化软件需要进行的改动较小,这样软件架构就不容易凌乱。由此可见,架构在软件工程中很重要。
这一设计理念可以直接应用到我们的OO课程中。这门课有四个单元,每个单元分为三次作业,除第一次作业外,每一次作业在前一次作业基础上增加需求。这意味着第一次的架构好坏直接决定了后两次作业开发难度的大小。因此,我在第一次作业中就考虑后两次作业可能出现的情况,设计出强可扩展性架构,以此换取后两次作业的轻松。
二、架构设计与复杂度分析
这一部分,我将介绍三次作业架构设计思路以及相应的复杂度分析。为凸显架构,部分优化不会在这一部分展开讲解。
2.1 第一次作业
2.1.1 架构思路
题目提供的表达式为中缀表达式,运算符+/-很自然地将表达式(Expression)分解为多个项,*将项(Term)分解为因子,**将因子(Factor)分解为底数(Base)与指数(power)。三种运算符的优先级依次递增,形成了表达式树状结构,如图1示。
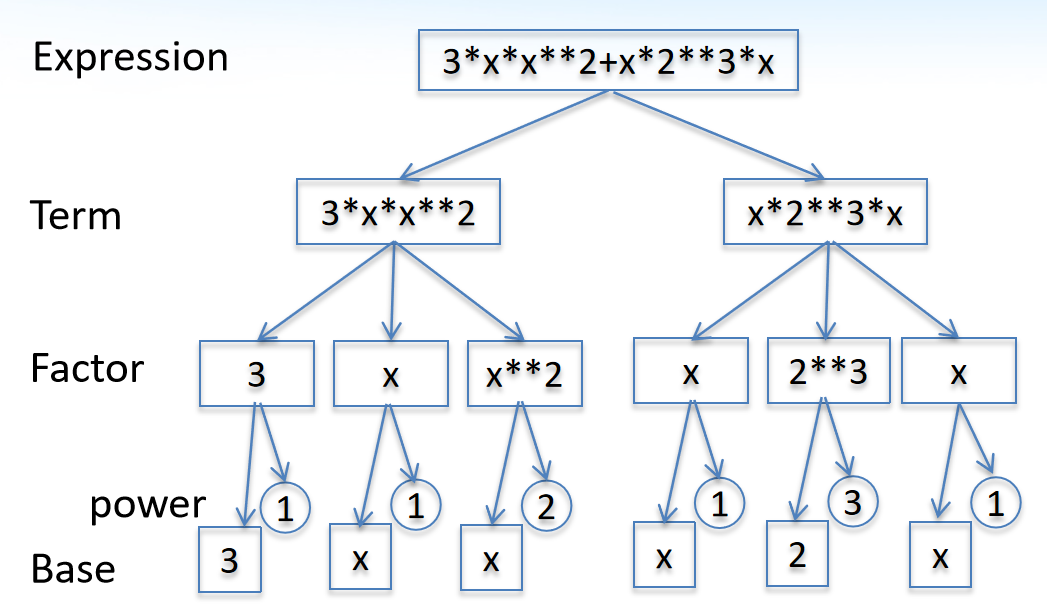
对于含有括号的表达式,我们将括号中的内容既视为Expression,又视为Base。之所以视为Expression,是因为括号中的内容可以为任意形式,Expression可以统一这些形式;之所以视为Base,是因为括号具有最高的运算优先级,高于乘方运算,在我们的结构中Base可以反映这一最高优先级。
因此,对于含有括号的表达式,括号这一Base结构还可以继续向下细分,如图2示。
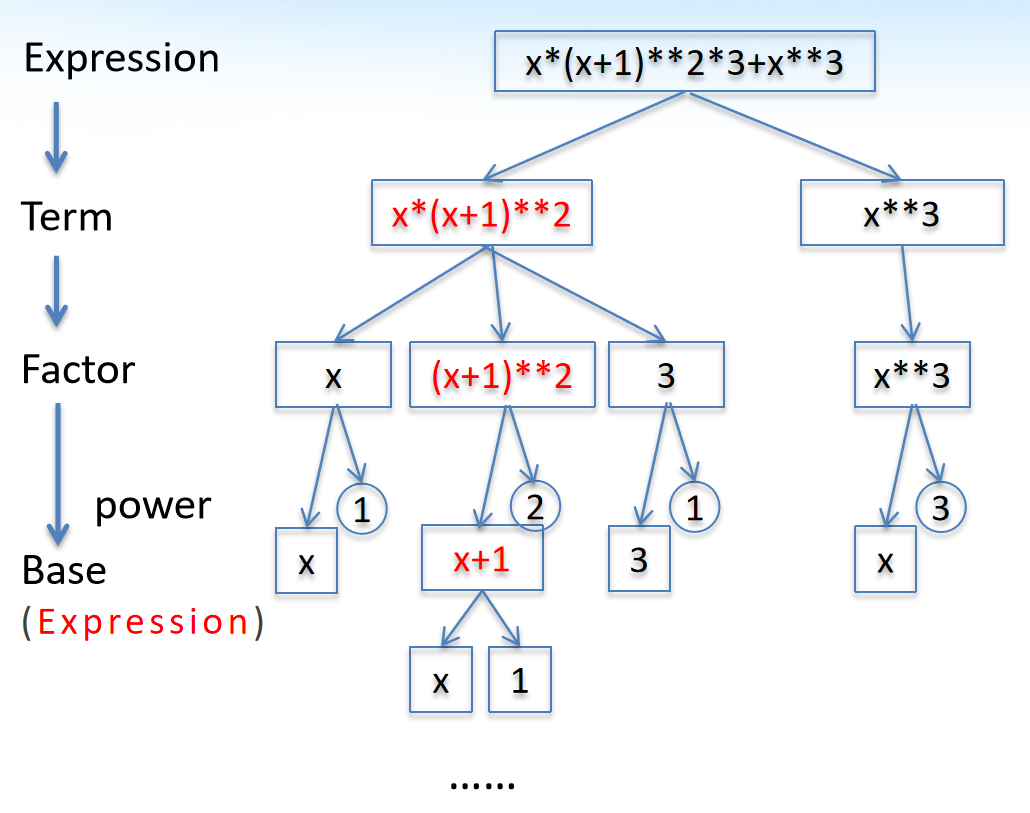
因此,解析表达式可以分为解析Expression,Term,Factor,Base与power四个层次,相应地有parseExpression,parseTerm(),parseFactor(),parserBase(),parsePower()五个方法。由于表达式可能含有括号,因此其Base既可能为Variable或Number,也可能为Expression,因此对于Variable与Number这类不可再向下细分的底数,用SimpleBase将其统一起来,再用Base将SimpleBase与Expression统一起来,这样parseBase()函数既可以返回SimpleBase,也可以返回Expression。
这样,我们就得到了第一次作业的类图,如图3。
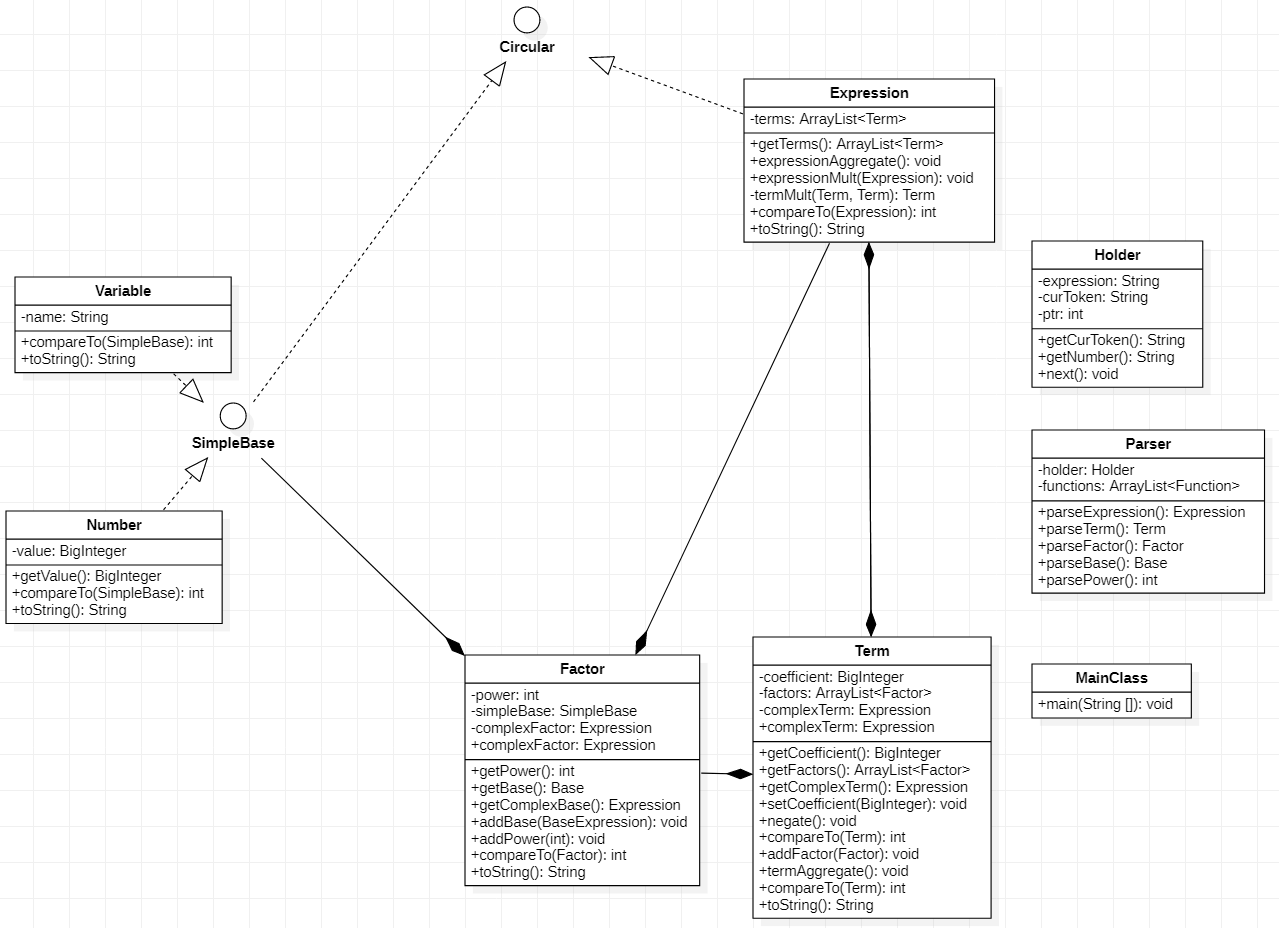
其中,Holder,Parser是工具类,Holder控制表达式字符串指针的移动,同时解析表达式的符号(例如x**200可以被解析为x,**,200三个符号)。一个表达式字符串与一个Holder对象一一对应。Parser利用输入表达式专属的Holder解析表达式。MainClass是Java程序的客户端,从控制台获取输入,将解析后的表达式字符串输出到控制台。Expression,Term,Factor,Number,Variable,SimpleBase,Base等类或接口是存储表达式的数据结构。
也许你会觉得直接由上述讲解导出这样一大堆的类以及其相应的方法太突然了。没关系!我在第一次研讨课上做过27分钟的架构设计分享,当时我详细地讲述了这一架构的实现原理。你可以在下面的链接中找到我的讲稿与PPT,其中的讲解足够明白。
https://pan.baidu.com/s/1lFhF6_fQ33Q6MZBSFFppYQ
提取码:qp9o
2.1.2 复杂度分析
我利用IDEA的MetricsReload插件对这一架构的复杂度进行分析,得到表1所示结果,仅展示复杂度较高(至少有一个指标大于等于6)的方法。
| Method | CogC | ev(G) | iv(G) | v(G) |
| Parser.parseExpression() | 11 | 1 | 7 | 9 |
| Expression.expressionAggregate() | 8 | 1 | 7 | 7 |
| Factor.addPower(int) | 8 | 1 | 4 | 4 |
| Term.addFactor(Factor) | 16 | 1 | 6 | 6 |
| Term.termAggregate() | 7 | 1 | 6 | 6 |
表2是对复杂度评价指标的解释。
| 指标 | 信息 |
| Cogc | 代码可读性,数值越大代码可读性越差 |
| ev(G) | 代码非结构化复杂度,数值越高代码的结构性越差 |
| iv(G) | 函数调用关系的复杂度,数值越高函数耦合就越紧密。 |
| v(G) | 圈复杂度,它由if,else,while,for,break,continue,switch等流程控制语句计算出,数值越大代表函数复杂度越大,可扩展性越差,维护成本越高。一般来说,各函数的圈复杂度应控制在10以内 |
纵观v(G)一栏数据,可见所有函数的圈复杂度均在10以内,由此初步可以判定代码的复杂度较低,架构设计较好。
addFactor()函数的CogC数值较大,原因是这一函数需要考虑不同种类的Factor(简单还是复杂,对简单Factor,还要判断其为数字还是变量),具有较多的if-else分支嵌套。但由于每个分支下的代码并不多,且不同分支的代码重复度较低,因此在我的架构下,这一函数CogC数值较大的问题很难通过拆分函数解决。
与addFactor()函数类似,addPower()函数的CogC数值也较大。原因是这一函数需要考虑Factor种类(简单Factor,复杂Factor)以及power值(0,大于0)的情况,与addFactor()函数CogC数值较高的原因相同。
此外,expressionAggregate()函数CogC数值也较大,原因是这一函数承载了三个功能:合并同类型,去除0项,保证Expression的Term列表非空。这说明当函数承载的功能较多时,可能需要将这些功能再拆分成函数,否则代码难以理解。
还有,Parser类的parseExpression()函数圈复杂度较大,CogC数值也较大。我们专门来分析一下这个函数:
public Expression parseExpression() {
Expression expression = new Expression();
int firstSign = 1;
while (holder.getCurToken().equals("-") ||
holder.getCurToken().equals("+")) {
if (holder.getCurToken().equals("-")) {
firstSign = -firstSign;
}
holder.next();
}
Term firstTerm = parseTerm();
if (firstSign == -1) {
firstTerm.negate();
}
expression.addTerms(firstTerm);
while (holder.getCurToken().equals("+") ||
holder.getCurToken().equals("-")) {
int sign = 1;
if (holder.getCurToken().equals("-")) {
sign = -1;
}
holder.next();
Term term = parseTerm();
if (sign == -1) {
term.negate();
}
expression.addTerms(term);
}
return expression;
}
其中代码的前半部分负责解析表达式的第一项,后半部分在解析后续项。两部分解析项的数据结构只用了expression.addTerm(parseTerm());一行代码,但是对于项的正负号分析却用了一大片代码,并且大量用循环与条件判断(我们的作业支持多个正负号连在一起,客户需求比较恶心),这应该是函数复杂度较大的原因。但其实仔细观察可以看到,处理第一项符号的代码与处理后续项的代码其实非常相似,我们完全可以另外定义函数parseSign(),专门处理符号,这样应该可以减小函数圈复杂度。
以下是parseSign()函数的实现。
private int parseSign() {
int sign = 1;
while (holder.getCurToken().equals("+") || holder.getCurToken().equals("-")) {
if (holder.getCurToken().equals("-")) {
sign = -sign;
}
holder.next();
}
return sign;
}
此时parseExpression()函数可以简化为以下形式。
public Expression parseExpression() {
Expression expression = new Expression();
int firstSign = parseSign();
Term firstTerm = parseTerm();
if (firstSign == -1) {
firstTerm.negate();
}
expression.addTerms(firstTerm);
while (holder.getCurToken().equals("+") ||
holder.getCurToken().equals("-")) {
int sign = parseSign();
Term term = parseTerm();
if (sign == -1) {
term.negate();
}
expression.addTerms(term);
}
return expression;
}
我们再次循行MetricsReload插件,可见parseExpression()函数的圈复杂度降为了5。这体现了利用函数可以降低代码重复度,增加代码可读性。
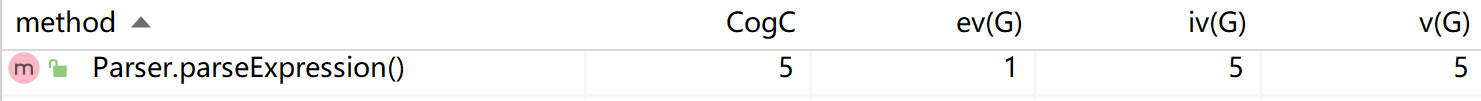
2.2 第二次作业
2.2.1 架构思路
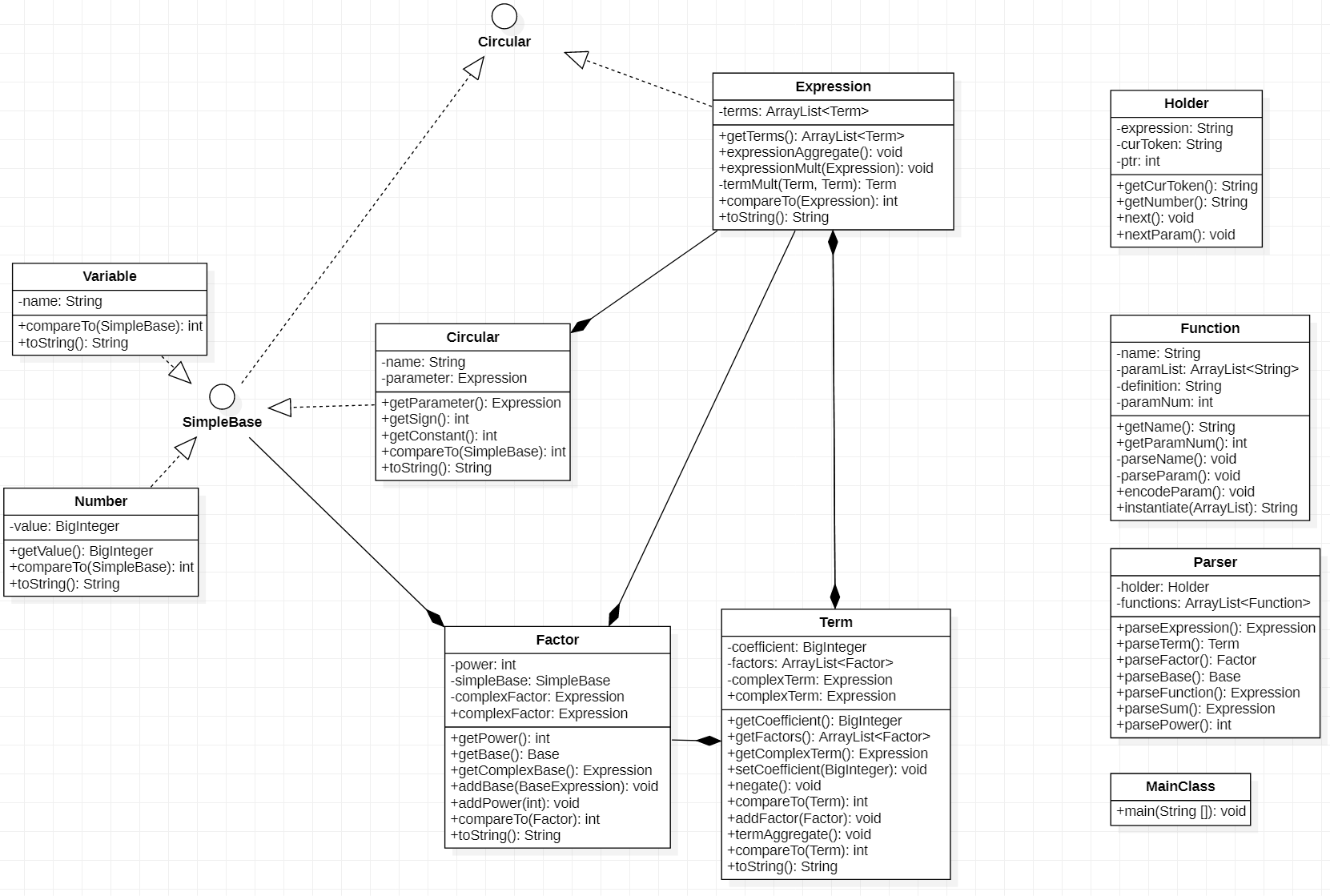
第二次作业客户需求进一步恶心,增加了三角函数,自定义函数与求和函数。不过,兵来将挡水来土掩,在第一次作业的架构良好的架构上,我们只需要做加法以及极少量的修改。 具体来说,我新建了以下类:
(1)Function,此类的一个对象代表一个自定义函数,它保存了该自定义函数的参数列表,定义表达式字符串,并提供方法利用字符串替换将传入的参数转化为函数展开后的表达式字符串。
(2)Circular,此类代表三角函数,主要成员变量为String类型的name,代表三角函数类型,以及Expression类型的parameter,代表作为三角函数参数的表达式(另外的constant以及sign属性完全是为了卷作业性能分,对于架构的分析没有意义)。
对于第一次作业已经定义的Parser类,我新增了以下方法:
(1)parseFunction(),此方法将自定义函数解析为Expression类型,在parseBase()方法中被调用。
(2)parseSum(),此方法将sum函数解析为Expression类型,在parseBase()方法中被调用。 对于已经定义的Holder类,我新增了nextParam()方法,此方法与next()类似,不同之处在于nextParam()方法每一次调用将获得自定义函数或者sum函数的一个参数字符串。我还修改Holder类的next()方法,支持识别新增的sin,cos字符串。
对于Parser类的parseBase()方法,我通过增加if-else分支实现了解析自定义函数,sum函数,三角函数的功能。
除此之外,我为Expression,Term,Factor,Variable,Number类均定义了compareTo()方法,这样对它们进行排序,方便合并同类项。
图4是作业二的架构。
2.2.2 复杂度分析
我对这一架构进行圈复杂度分析,得到表3所示结果,仅展示复杂度较高(至少有一个指标大于等于6)且第二次作业新增或修改的方法。
| Method | CogC | ev(G) | iv(G) | v(G) |
| Holder.next() | 12 | 2 | 5 | 9 |
| Holder.nextParam() | 19 | 1 | 8 | 12 |
| Parser.parseBase() | 7 | 6 | 7 | 7 |
| Circular.Circular(String, Expression) | 7 | 1 | 6 | 7 |
| Circular.compareTo(SimpleBase) | 7 | 6 | 3 | 6 |
| Expression.compareTo(Expression) | 9 | 7 | 4 | 8 |
这一次,很不幸,Holder的next()方法与nextParam()方法圈复杂度均处于较高水平,分别为9和12。这是因为表达式的符号(数字,运算符,sin,cos,括号)增多,表达式指针可能的状态增多(类比识别字符串的有限状态机),复杂度便提升了。
此外,parseBase()方法的复杂度也增大了,这是因为parseBase()方法新增了解析三角函数,求和函数,自定义函数的功能。不过总体来说,parseBase()方法各个复杂度数值均在10以内,总的来看可以接受。
至于Circular的构造器Circular()复杂度榜上有名,就要归咎于优化了。为实现sin(0)=0,cos(0)=1的优化,我在Circular的构造器中单独判定了内部Expression是否为0,如果是0则根据Circular的种类将Circular的constant属性置为0或1,以提醒上层Factor将其作为相应的数字底数而非三角函数底数。这一优化让CIrcular()构造器有4个分支,复杂度略微较大。
最后是Circular以及Expression的比较函数复杂度较大。对Circular,这是因为比较时需要根据另一个SimpleBase的种类选用不同的比较策略,条件分支较多(如果后续增加SimpleBase种类条件分支会更多);对Expression,这是因为首先需要依次比较两个Expression的Term列表中每个Term的Factor列表,如果这一标准不能确定两个Expression的先后顺序则比较两个Expression的Term列表大小,如果仍不能确定先后顺序则依次比较两个Expression的、每个Term常数项。这样的比较过程增加了复杂度,不过这一复杂度可以接受。
2.3 第三次作业
2.3.1 架构思路
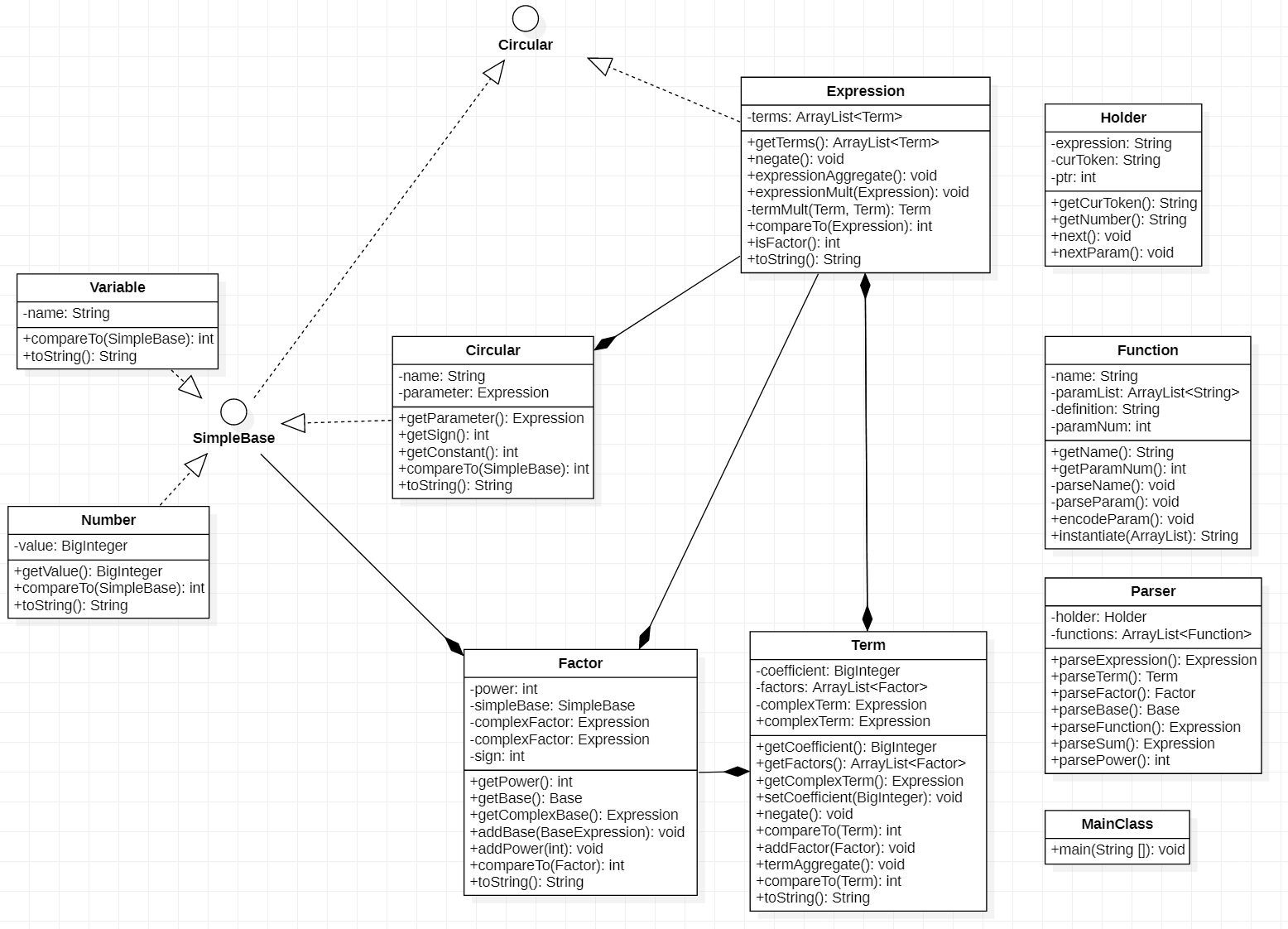
在第二次作业中,我已经实现了第三次作业几乎所有功能,包括自定义函数嵌套自定义函数,三角函数中出现表达式。因此,第三次作业我几乎不用增量开发。
不过在第三次作业中,客户多了一个恶心人的需求——当三角函数内部为表达式因子时,该表达式因子要加上括号。我的实现不支持这一点,因此我为Expression类定义了isFactor()方法,在三角函数的toString()方法中调用Expression类的isFactor()方法判定了内部表达式是否为表达式因子,从而决定是否输出括号。
图6是第三次作业架构。
2.3.2 复杂度分析
进行复杂度分析得到表4结果,仅展示复杂度较高(至少有一个指标大于等于6)且第三次作业新增或修改的方法。
| Method | CogC | ev(G) | iv(G) | v(G) |
| Expression.isFactor() | 12 | 7 | 5 | 10 |
2.4 架构设计小结
功能上,三次作业的迭代基本都是在前一次作业的基础上增加代码,几乎没有改变代码,符合开闭原则(这一点从类图上可以看出)。架构搭得好,头发掉得少,我很高兴第一次作业的冥思苦想带来了我第二次,第三次作业的轻松自在。
复杂度上,三次作业架构复杂度均较小,绝大多数复杂度较大的方法是功能刚需,不能通过拆分结构简化。
三、Bug总结
在这一部分,我将分析自己三次作业中的bug,错误原因以及解决方案。
3.1 第一次作业
第一次作业成功通过所有强测测试点,但是在互测中被揪出了一个bug。具体测试点如下:
13+-+3
我的程序在执行的过程中发生了异常。原因是对于连续正负号,我程序的预处理用一大堆字符串替换将连续的+/-号替换为单个+/-号,解析时程序默认不会出现连续的+/-号。而这个测试点出现了三个连续的+/-号,经过我的预处理还剩两个连续的+/-号,这导致了程序的异常。 本着开闭原则,我的修复方法是在预处理时添加了一次连续+/-号的字符串替换,并没有改动架构,相当于打补丁。
3.2 第二次作业
第二次作业我成功通过所有强测测试点,并且在互测中也没有被揪出bug。但其实程序有bug,只是互测的限制让这一bug没能被揪出。
3.3 第三次作业
第三次作业我寄了一个强测样例,在互测中被hack了16次。经检查,我的程序总共有3个bug,各自的代表测试样例如下。
0
0+++0
同第一次作业的bug,又是连续的+/-号问题,对此我的bug修复措施仍然是在预处理时打补丁,方法同第一次作业。
0
sum(i,2147483648,2147483648,0)
我的程序在运行时出错,原因是我用int型变量处理sum函数的加法循环,而2147483648超过了int范围。解决办法是用BigInteger存放循环变量。
0
sum(i,1,0,1)
我的程序错误地输出了1,答案是0。我忽略了sum函数求和下界大于求和上界的情况。想当然将求和表达式初始化为求和下界对应的表达式。解决方案是将求和表达式初始化为0。
3.4 bug小结
三次作业的bug都是浅层次bug,与架构思想以及架构复杂度无关。其中连续+/-号的bug是预处理问题,这说明我的测试覆盖情况不够;求和函数对应的两个bug是没有读清楚题目造成的,这通过测试也没办法解决。
四、自动化测试
自动化测试分为两步:生成测试数据,输出检查。
4.1 生成测试数据
这一步其实是构造表达式,如果你亲自去实现了就会发现它比解析表达式简单。因此我只给出代码框架(以第三次作业为例)。
void define_function();
void get_expression();
void get_term();
void get_factor();
void get_number();
void get_variable();
void get_circular();
void get_function();
void get_sum();
void get_pow();
void get_sign();
void get_blank();
为了控制测试数据复杂度,我们需要定义限制条件。
#define max_depth 3
#define max_term 2
#define max_factor 2
#define max_pow 5
#define max_number_length 3
#define min_number_length 3
生成表达式的工具我采用C语言实现,原因是C语言的性能显著强于python。
4.2 输出检查
我采用python的sympy库函数expand(),它能将表达式展开,并且展开后的表达式项与项,项的因子与因子之间具有唯一的顺序。因此它能用于判定输出表达式与原始表达式是否相等。 值得注意的是,如果你实现了三角函数的平方和优化,那么就不能用这一函数对拍了,原因是expand()并不会实现sin(x)**2+cos(x)**2=1的优化。此时需要用simplify()函数实现对拍。但是simplify()函数内部采用了启发式算法简化表达式,这将带来大量时间开销。
对于自定义函数,我的方式是固定自定义函数的形式,例如固定f(x,y,z)=x**2+cos(y)+sin(1+z),这样可以直接在python定义好f(x,y,z)函数。但这样的不方便之处在于自定义函数失去了灵活性,只能为一个样子。后来我参考了姜姐姐在讨论区的发言,意识到可以利用sympify()函数先将自定义函数的字符串转化为表达式,然后用subs()函数将自定义函数表达式中的x,y,z替换为传入的表达式参数,这样就能支持可变的自定义函数。
4.3 自动化测试小结
自动化评测机的搭建需要我们递归地构造表达式,并且熟悉python函数的用法。总体来看难度较低。
五、总结
OO第一单元到此完美谢幕。我的收获主要有以下几点:
- 架构设计能力提高。我凭借良好的架构在后两次作业中省了很多麻烦。
- Java语法掌握程度提高。在帮同学debug的过程中,我解开了HashMap的神秘面纱。
- python语法掌握程度提高。我学会了使用lambda表达式,sympy库。
- 命令行操作进一步熟练。我学会了javac,java等命令,提高了自动测试的速度。
- 我在第一次研讨课上进行了27分钟的展示,刷新了我展示时长的记录,锻炼了PPT制作能力。
- 复习了html语法,将《走进软件》学习到的技能捡回了一部分

