
KMeans算法演示程序
2009-02-02 11:36 Yin.P 阅读(9304) 评论(30) 编辑 收藏 举报这几天又把《数据挖掘概念与技术》这本书翻出来看了看,随便做了个演示程序实现了书中的K-Means算法。也算是一种复习和积累吧。最先这个算法完全是用C#来做的,数据样本点是用的类作为其数据结构,后来在测试中发现运行速度不太理想。就改为用C++实现算法本身,然后通过C#调用(P\Invoke)C++导出的函数来完成。最终的效果如下面的图所示,图中小十字叉是聚类中心:

图一:K=5
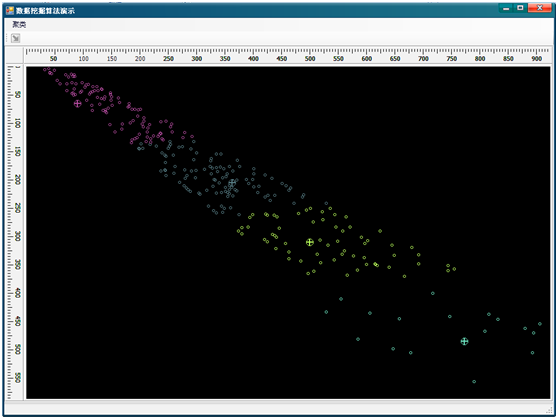
图二:K=4

图三:K=3
K-Means算法是聚类算法的一种,它通过计算样本数据点之间的逻辑距离来判断某个样本数据点属于哪一个簇,算法最终的目的是要把用于算法的样本数据点分配到K个簇中,使簇内的点有较大的相似度,而簇间的点有较小的相似度。K-Means中的K表示聚类中心的个数,在算法运行过程中,要反复扫描所有样本数据点,要计算每个非中心数据点与某个聚类中心点的距离,并将这个数据点归为与其距离最小的那个聚类中心对应的簇之中。每扫描一次就要重新计算每个聚类中心点的位置。当聚类中心点的位置变化在一定的阈值之内的时候停止处理,最后就可以得到K个簇,并且簇中每个样本数据点到本簇的中心的距离都小于到其它簇中心的距离。
现在来看看代码,解决方案中包括两个主要的项目,如图,其中SimpleKMeans.Core项目是算法的实现,是用C++ STL完成的,它用于处理二维的数据,另一个主要用于数据获取和结果显示,通过PInvoke调用算法函数并将结果图形化地显示出来:
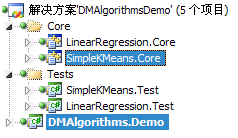
图四:选中的两个就是KMeans使用到的项目
在SimpleKMeans.Core中有一个导出的函数DataMining_KMeans。这个函数要接收C#传过来的原始数据、K值及其它参数,同时还要将处理的结果赋值给引用参数以便在C#中可以接收到处理结果。DataMining_KMeans函数的原型如下:
/*
* @Author:YinPSoft
* @param:
* raw: 原始数据
* count: 数据点个数
* K: 聚类中心个数
* means: 初始聚类中心
* minOffset: 聚类中心的最小偏移量,用于控制聚类处理的精度。
* times: 最大迭代次数
* c:每个聚类的数据点索引值
* sizes:每个聚类的容量
* finalMeans:最终的聚类中心位置
*/
void DataMining_KMeans(double* data,
int count,
int K,
int* means,
double minOffset,
int times,
int* c,
int* sizes,
double* finalMeans);
在这个原型声明中可以看到初始聚类中心点要从外部输入,而之前的版本是直接通过随机产生的。从外部输入这种方式有更大的灵活性,当有特定的初始聚类中心生成策略的时候可能通过这个策略来生成中心点,而没有策略的时候也可以通过随机来生成。初始聚类中心的值可以很大程度地影响到整个算法的效率,适当的选择聚类中心点可以减少算法的迭代次数。
接下来继续分析DataMining_KMeans函数中的代码,首先是初始化,如下面的代码:
for (i = 0; i < K; i++)
{
vector<int> cluster;
clusters.push_back(cluster);
meanIndex.push_back(*(means + i));
dots.at(*(means+i)).isMean = true;
dots.at(*(means+i)).isVirtual = false;
}
上面的代码有两个目的:一是初始化vector<int>数组用于存放K个簇的样本点索引;二是将外部传进来的K个聚类中心点添加到dots对象之中,dots对象是vector<Dot2D>类型的。在DataMining_KMeans最开始就要通过PreProcessor函数将外部传进来的数据点封装成vector<Dot2D>的对象,在这里是dots。Dot2D的定义如下,isMean和isVirtual是数据点的两个标志,前者用于标识这个数据点是否是聚类中心,后者用于表示这个点是不是虚拟数据点,虚拟数据点在这里意为这个点的位置是通过计算得到,而不是原始数据中的数据点。实际上,在这个算法中,虚拟数据点都是在处理过程中得到的聚类中心点,因为每一轮计算完成后要重新计算聚类中心位置,而这个计算出来的位置很可能不同于原始数据中的任何一个点,所以要把这些点保存下来用于下一轮的计算:
typedef struct Dot
{
double x;
double y;
bool isMean;
bool isVirtual;
} Dot2D, *Ptr_Dot2D;
接下来就是一个while循环,反复地扫描样本数据点并将其分配K个簇中。在这个while循环中包括两大部分,首先就是计算并比较数据点与聚类中心的距离并进行分配;其次就是重新计算聚类中心。代码如下:
for (i = 0; i < count; i++)
{
if (!dots.at(i).isMean && !dots.at(i).isVirtual)
{
dist = INFINITE_DISTANCE;
for (j = 0; j < K; j++)
{
term = Distance(dots[i], dots[meanIndex[j]]);
if (term < dist)
{
dist = term;
//存放与聚类中心有最小距离的那个数据点的索引值
c = j;
}
}
//将第i个数据点放入第j个聚类
clusters.at(c).push_back(i);
}
}
对所有数据点的扫描计算的前提是这些数据点不是聚类中心并且也不是虚拟数据点。然后将中间距离变量设置一个初值,接下来的for循环就要计算当前这个数据点与每个聚类中心的距离,如果当前点到第K个聚类中心的距离是最小的,那么就把它的索引值存放到clusters的第K个vector<int>对象中。当所有的样本数据点都被分配到K个簇中以后就要重新计算中心点的位置,代码如下:
for (i = 0; i < K; i++)
{
maxminvalues = FindMaxMinValues(dots, clusters.at(i));
newMean.x = (maxminvalues.at(0) + maxminvalues.at(2)) / 2.0;
newMean.y = (maxminvalues.at(1) + maxminvalues.at(3)) / 2.0;
newMean.isMean = true;
newMean.isVirtual = true;
term = Distance(newMean, dots[meanIndex[i]]);
flag = (term > minOffset) ? true : flag;
dots.at(meanIndex.at(i)).isMean = false;
dots.push_back(newMean);
*(finalMeans+i) = newMean.x;
*(finalMeans+i+K) = newMean.y;
meanIndex.at(i) = dots.size() - 1;
}
上面的代码用于计算新的聚类中心点的位置,并覆盖之前的聚类中心位置。在这个算法中通过计算簇所占有的矩形区域的中心点来作为新的聚类中心点的位置。在这个for循环中还有一件事情就是要计算新的聚类中心点与前一轮的聚类中心点的距离或者称为聚类中心点的位移,在函数原型中我们设置了这个位移的最小值,当K个位移都小于这个值的时候就要结束算法处理。另外每次进入while循环的时候要清空clusters对象,否则clusters中会有多余的数据,并且会随原始数据量而膨胀。
以上就是K-Means算法实现C++部分的主要代码,也是这个演示程序的核心部分。除了算法实现部分之外就是算法结果的展示了。另一个项目DMAlgorithms.Demo用于向算法传送原始数据以及接收算法的输出并可视化结果。在DMAlgorithms.Demo项目中要调用C++函数,方法是通过.NET的P/Invoke调用,其代码如下:
/// <summary>
/// K-Means聚类分析
/// </summary>
/// <param name="rawdata">KMeans原始数据</param>
/// <param name="rows">数据点个数</param>
/// <param name="K">聚类个数</param>
/// <param name="means">初始聚类中心</param>
/// <param name="minOffset">聚类中心的最小位移量</param>
/// <param name="times">最大迭代次数,-1为不控制</param>
/// <param name="result">聚类划分结果</param>
/// <param name="size">返回的每个聚类的大小</param>
/// <param name="finalMeans">返回的最终聚类中心</param>
/// <param name="size">表示第一个参数的长度</param>
/// <param name="finalMeans_size">表示第九个参数的长度</param>
[DllImport("SimpleKMeans.Core.dll", EntryPoint = "DataMining_KMeans",CharSet = CharSet.Auto)]
public static extern void DataMining_KMeans(
[MarshalAs(UnmanagedType.LPArray, SizeParamIndex = 9)]
double[] rawdata,
int rows, int K,
[MarshalAs(UnmanagedType.LPArray, SizeParamIndex = 2)]
int[] means,
double minOffset, int times,
[MarshalAs(UnmanagedType.LPArray, SizeParamIndex = 1)]
int[] result,
[MarshalAs(UnmanagedType.LPArray, SizeParamIndex = 2)]
int[] sizes,
[MarshalAs(UnmanagedType.LPArray, SizeParamIndex = 10)]
double[] finalMeans,
int size, int finalMeans_size
);
因为这部分不是本文的重点,而且这部分的C#代码都比较简单,所以不作过多介绍。更多细节可以参考附件中的代码。我会将所有代码和可执行程序以及样本数据打包放到附件,大家如有需要可以通过下面的链接下载附件。大家可以使用自己的数据库或数据文件。但注意使用自己的样本数据的时候要修改一下配置文件。配置方法很简单,在SimpleKMeans.Demo.exe.config文件中有两个ConnectionString的配置,其中名为KMeansSampleData的是数据库连接字符串;名为RetrieveData的是获取数据的SQL字符串(为了利用.NET的API直接取得数据所以直接使用连接字符串配置了),因为这个演示程序现在只能处理二维数据,所以SQL字符串只能有两个数值列,并且分别命其别名为X_Dim和Y_Dim,这样在程序中才能正确地取得数据。
当然,我这个程序也还存在一些需要要改进的地方,在这个程序中初始聚类中心的选择使用的是随机方式,这种方式对算法的影响是不稳定的,有的时候好有的时候坏。最好的处理方式应该是通过分析原始数据来生成K个聚类中心,而不是随机指定。第二,距离的计算方法被指定为欧氏距离,并且不能灵活更换。更好的处理方式应该是可以灵活选择距离计算方法的,并提供合理的接口以便扩展距离计算方法。第三就是每轮新的聚类中心点是通过簇区域的中心点来计算的,以这种方式计算聚类中心会影响最终聚类中心点的精度。最后就是DataMining_KMeans函数的参数过多,应该将其封装为结构体,使结构更清晰。

