

2.去除坏波段(含水汽等影响)
2.1在HySime那一步的mian.py进行代码修改:
(1)修改位置preprocess_for_vca 函数,使打印常数波段索引
点击查看代码
import numpy as np
import scipy.io as sio
from sklearn import preprocessing
from skimage.segmentation import slic, mark_boundaries
import math
from operator import truediv
import matplotlib.pyplot as plt
from matplotlib import cm
import sys
import spectral.io.envi as envi
import os
from pathlib import Path
import warnings
# 忽略特定警告,保持输出清晰
warnings.filterwarnings('ignore', category=RuntimeWarning)
np.set_printoptions(precision=4, suppress=True)
# --- 辅助函数 (保持不变) ---
def SegmentsLabelProcess(labels):
'''
对labels做后处理,防止出现label不连续现象
'''
labels = np.array(labels, np.int64)
H, W = labels.shape
ls = list(set(np.reshape(labels, [-1]).tolist()))
dic = {}
for i in range(len(ls)):
dic[ls[i]] = i
new_labels = labels
for i in range(H):
for j in range(W):
new_labels[i, j] = dic[new_labels[i, j]]
return new_labels
# --- 改进的纯 NumPy 实现的 VCA ---
def vca_numpy(M, P):
"""
改进的纯 NumPy 实现的 Vertex Component Analysis (VCA)
增加了数值稳定性处理和错误恢复机制
参数:
M: 输入数据矩阵 (bands, pixels)
P: 要提取的端元数量
返回:
endmembers: 端元矩阵 (bands, P)
indices: 端元在原始数据中的索引 (P,)
"""
bands, pixels = M.shape
# 1. 数据预处理:处理NaN、Inf和常数波段
M = np.nan_to_num(M, nan=0.0, posinf=0.0, neginf=0.0)
# 检查并移除常数波段(标准差接近0)
std_bands = np.std(M, axis=1)
valid_band_mask = std_bands > 1e-8
if not np.all(valid_band_mask):
print(f"⚠️ 检测到 {np.sum(~valid_band_mask)} 个常数波段,已移除")
M = M[valid_band_mask, :]
original_bands = bands
bands = np.sum(valid_band_mask)
# 如果移除太多波段,使用原始数据尝试继续
if bands < max(3, P):
print(f"⚠️ 有效波段数量 ({bands}) 小于需要的端元数 ({P}),使用原始数据尝试")
M = M # 尝试使用原始数据
bands = original_bands
# 2. 数据中心化
mean_vec = np.mean(M, axis=1, keepdims=True)
M_centered = M - mean_vec
# 3. SVD 分解 - 添加尝试/恢复机制
try:
# 尝试标准 SVD
U, S, Vh = np.linalg.svd(M_centered, full_matrices=False)
V = Vh.T
except np.linalg.LinAlgError as e:
print(f"⚠️ 标准 SVD 失败: {e},尝试使用截断 SVD")
try:
# 使用随机化 SVD 作为后备
from sklearn.utils.extmath import randomized_svd
U, S, Vh = randomized_svd(M_centered, n_components=min(50, min(M_centered.shape)))
V = Vh.T
except ImportError:
print("⚠️ 无法导入 sklearn,尝试使用特征值分解")
# 使用特征值分解作为最后手段
cov_matrix = M_centered @ M_centered.T
eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)
# 按特征值大小排序
idx = np.argsort(eigenvalues)[::-1]
U = eigenvectors[:, idx]
S = np.sqrt(np.abs(eigenvalues[idx]))
U = U[:, :P] # 保留前 P 个奇异向量
# 4. 初始化
indices = np.zeros(P, dtype=int)
A = np.zeros((bands, P))
# 5. 第一个端元:最大投影
if U.shape[1] > 0: # 确保有足够的奇异向量
SNR = np.linalg.norm(U, axis=0)
max_idx = np.argmax(SNR)
indices[0] = max_idx
A[:, 0] = M[:, max_idx]
else:
# 如果 U 为空,随机选择一个点
max_idx = np.random.randint(0, pixels)
indices[0] = max_idx
A[:, 0] = M[:, max_idx]
# 6. 剩余端元
for i in range(1, min(P, bands)): # 确保不超过波段数
# 计算残差
U_i = U[:, :i]
proj = U_i @ (U_i.T @ M)
residual = M - proj
# 选择最大残差
norms = np.linalg.norm(residual, axis=0)
max_idx = np.argmax(norms)
indices[i] = max_idx
A[:, i] = M[:, max_idx]
# 更新子空间
try:
U = np.linalg.qr(np.column_stack((U_i, M[:, max_idx])), mode='reduced')[0]
except np.linalg.LinAlgError:
print(f"⚠️ QR 分解在第 {i} 次迭代失败,使用前一次的 U")
# 如果 QR 失败,使用前一次的 U
# 7. 如果 P 大于 bands,填充剩余端元
if P > bands:
print(f"⚠️ 要求的端元数量 P={P} 大于波段数 {bands},只提取了 {bands} 个有效端元")
# 复制最后一个端元填充
for i in range(bands, P):
A[:, i] = A[:, bands - 1]
indices[i] = indices[bands - 1]
return A, indices
# --- 改进的 HySime 实现 (纯 Python) ---
def hysime(Y, noise_sigma=None):
"""
改进的纯 Python HySime 实现
增加了数值稳定性处理和边界条件检查
参数:
Y: 输入数据 (pixels, bands)
noise_sigma: 噪声标准差 (可选)
返回:
p: 估计的端元数量
"""
pixels, bands = Y.shape
# 1. 数据预处理:处理NaN、Inf
Y = np.nan_to_num(Y, nan=0.0, posinf=0.0, neginf=0.0)
# 2. 检查并处理常数波段
std_bands = np.std(Y, axis=0)
mean_bands = np.mean(Y, axis=0)
# 创建波段掩码,移除标准差接近0的波段
valid_band_mask = std_bands > 1e-8
constant_bands = np.sum(~valid_band_mask)
if constant_bands > 0:
print(f"⚠️ 检测到 {constant_bands} 个常数波段")
# 保留有效波段
if np.sum(valid_band_mask) >= 3: # 至少保留3个波段
Y = Y[:, valid_band_mask]
bands = np.sum(valid_band_mask)
print(f" 使用 {bands} 个有效波段进行 HySime 估计")
else:
print(" 有效波段太少,使用所有波段尝试继续")
# 3. 安全的数据标准化
std_bands = np.std(Y, axis=0)
# 替换接近0的标准差,避免除以0
safe_std = np.where(std_bands < 1e-8, 1.0, std_bands)
Y_standardized = (Y - np.mean(Y, axis=0)) / safe_std
# 4. 计算协方差矩阵
R = np.cov(Y_standardized, rowvar=False)
# 5. 特征分解 - 添加错误处理
try:
eigenvalues, _ = np.linalg.eigh(R)
eigenvalues = np.flip(eigenvalues) # 从大到小排序
except np.linalg.LinAlgError:
print("⚠️ 特征分解失败,使用经验方法估计端元数量")
# 使用经验方法:取数据维度的10%作为估计
p = max(3, min(20, int(0.1 * min(pixels, bands))))
return p, None
# 6. 估计噪声方差
if noise_sigma is None:
# 更稳健的噪声估计:使用最小20%的特征值
noise_idx = max(3, int(0.2 * bands))
noise_eigenvalues = eigenvalues[-noise_idx:]
# 确保没有负值
noise_eigenvalues = np.abs(noise_eigenvalues)
noise_sigma = np.mean(noise_eigenvalues)
print(f" 估计的噪声方差: {noise_sigma:.4f}")
# 7. 计算信号子空间维数
signal_eigenvalues = eigenvalues[eigenvalues > noise_sigma]
p = len(signal_eigenvalues)
# 8. 设置合理的边界
min_p = 3 # 最小端元数量
max_p = min(30, bands - 1) # 最大端元数量
if p < min_p:
print(f"⚠️ 估计的端元数量 {p} 小于最小值 {min_p},使用 {min_p}")
p = min_p
elif p > max_p:
print(f"⚠️ 估计的端元数量 {p} 大于最大值 {max_p},使用 {max_p}")
p = max_p
print(f" 有效特征值: {len(signal_eigenvalues)} / {bands}")
print(f" 前10个特征值: {eigenvalues[:10]}")
print(f" 噪声阈值: {noise_sigma:.4f}")
return p, None
# --- 核心 SLIC 和特征提取类 (保持不变) ---
class SLIC_Processor(object):
"""
负责执行 SLIC 超像素分割、计算光谱均值 (X_super) 和构建邻接矩阵 (A)。
"""
def __init__(self, HSI, n_segments, compactness=20, max_iter=20, sigma=0, min_size_factor=0.3, max_size_factor=2):
self.n_segments = n_segments
self.compactness = compactness
self.sigma = sigma
self.min_size_factor = min_size_factor
self.max_size_factor = max_size_factor
# 数据standardization标准化
height, width, bands = HSI.shape
data = np.reshape(HSI, [height * width, bands])
minMax = preprocessing.StandardScaler()
data = minMax.fit_transform(data)
self.data = np.reshape(data, [height, width, bands])
self.segments = None
self.superpixel_count = 0
self.S = None # 超像素光谱均值矩阵 (X_super)
self.Q = None # 分配矩阵
def get_Xsuper_Q_Segments(self):
"""
执行 SLIC 分割,并计算每个超像素块内的光谱平均值(S,即 X_super),
以及像素到超像素的分配矩阵 Q。
"""
img = self.data
(h, w, d) = img.shape
# --- 1. 执行 SLIC 分割 ---
segments = slic(img, n_segments=self.n_segments, compactness=self.compactness,
convert2lab=False, sigma=self.sigma,
enforce_connectivity=True, min_size_factor=self.min_size_factor,
max_size_factor=self.max_size_factor, slic_zero=False)
# 确保超像素 label 连续
if segments.max() + 1 != len(set(np.reshape(segments, [-1]).tolist())):
segments = SegmentsLabelProcess(segments)
self.segments = segments
superpixel_count = segments.max() + 1
self.superpixel_count = superpixel_count
print(f"--- SLIC 分割完成 ---")
print(f"目标超像素数量: {self.n_segments}, 实际超像素数量: {superpixel_count}")
# --- 2. 计算光谱均值 (S = X_super) 和 分配矩阵 (Q) ---
segments_flat = np.reshape(segments, [-1])
S = np.zeros([superpixel_count, d], dtype=np.float32)
Q = np.zeros([w * h, superpixel_count], dtype=np.float32)
x_flat = np.reshape(img, [-1, d])
for i in range(superpixel_count):
idx = np.where(segments_flat == i)[0]
count = len(idx)
pixels = x_flat[idx]
superpixel = np.sum(pixels, axis=0) / count
S[i] = superpixel
Q[idx, i] = 1
self.S = S
self.Q = Q
return Q, S, self.segments
def get_A(self, sigma: float = 10.0):
"""
根据超像素分割图 Segments 和光谱均值 S (X_super) 构建邻接矩阵 A。
"""
if self.segments is None or self.S is None:
raise ValueError("必须先调用 get_Xsuper_Q_Segments() 方法完成分割和特征提取。")
A = np.zeros([self.superpixel_count, self.superpixel_count], dtype=np.float32)
(h, w) = self.segments.shape
for i in range(h - 1):
for j in range(w - 1):
sub = self.segments[i:i + 2, j:j + 2]
sub_unique = np.unique(sub)
if len(sub_unique) > 1:
idx1 = sub_unique[0]
idx2 = sub_unique[1]
if A[idx1, idx2] == 0:
pix1 = self.S[idx1]
pix2 = self.S[idx2]
diss = np.exp(-np.sum(np.square(pix1 - pix2)) / sigma ** 2)
A[idx1, idx2] = A[idx2, idx1] = diss
return A
# --- 主执行函数(包含测试数据)---
def run_superpixel_processing(hsi_data, target_n_segments=10000, sigma_weight=10.0):
"""
执行完整的超像素分割、特征提取和图结构构建流程。
"""
print(f"输入数据形状 (H, W, B): {hsi_data.shape}")
slic_processor = SLIC_Processor(
HSI=hsi_data,
n_segments=target_n_segments,
compactness=1,
sigma=1,
min_size_factor=0.1,
max_size_factor=2
)
Q, X_super, Segments = slic_processor.get_Xsuper_Q_Segments()
A = slic_processor.get_A(sigma=sigma_weight)
print("\n--- 结果形状摘要 ---")
print(f"最终超像素数量 (N): {X_super.shape[0]}")
print(f"X_super 形状 (N, B): {X_super.shape}")
print(f"Q 形状 (H*W, N): {Q.shape}")
print(f"A 形状 (N, N): {A.shape}")
print(f"Segments 形状 (H, W): {Segments.shape}")
return Q, X_super, A, Segments
# --- VCA 导入函数 (改进版) ---
def import_vca():
"""尝试导入 VCA 实现,优先使用 spectral,其次使用纯 NumPy 实现"""
# 1. 尝试从 spectral 导入
try:
from spectral.algorithms.vca import vca
print("✅ 使用 spectral 库的 VCA 实现")
return vca
except ImportError:
pass
# 2. 尝试从 spectral 主模块导入
try:
from spectral import vca
print("✅ 使用 spectral 库的 VCA 实现 (备用路径)")
return vca
except ImportError:
pass
# 3. 使用纯 NumPy 实现
print("🔧 使用改进的纯 NumPy 实现的 VCA (后备方案)")
return vca_numpy
# # --- 数据预处理函数 ---
# def preprocess_for_vca(X_super):
# """
# 为 VCA 准备数据,处理常见问题
# """
# # 1. 处理 NaN 和 Inf
# X_super = np.nan_to_num(X_super, nan=0.0, posinf=0.0, neginf=0.0)
#
# # 2. 检查数据范围
# min_val = np.min(X_super)
# max_val = np.max(X_super)
# mean_val = np.mean(X_super)
# std_val = np.std(X_super)
#
# print(f" 数据统计: min={min_val:.4f}, max={max_val:.4f}, mean={mean_val:.4f}, std={std_val:.4f}")
#
# # 3. 检查常数波段
# std_bands = np.std(X_super, axis=0)
# constant_bands = np.sum(std_bands < 1e-8)
# if constant_bands > 0:
# print(f"⚠️ 检测到 {constant_bands} 个常数波段")
#
# # 4. 数据标准化 (可选)
# # X_super = preprocessing.StandardScaler().fit_transform(X_super)
#
# return X_super
# --- 数据预处理函数 (已修改) ---
def preprocess_for_vca(X_super):
"""
为 VCA 准备数据,处理常见问题,并打印常数波段索引。
"""
# 1. 处理 NaN 和 Inf
X_super = np.nan_to_num(X_super, nan=0.0, posinf=0.0, neginf=0.0)
# 2. 检查数据范围
min_val = np.min(X_super)
max_val = np.max(X_super)
mean_val = np.mean(X_super)
std_val = np.std(X_super)
print(f" 数据统计: min={min_val:.4f}, max={max_val:.4f}, mean={mean_val:.4f}, std={std_val:.4f}")
# 3. 检查常数波段 (关键修改处)
std_bands = np.std(X_super, axis=0)
# 找出方差接近于零的波段索引
constant_band_indices_py = np.where(std_bands < 1e-8)[0]
constant_bands_count = len(constant_band_indices_py)
if constant_bands_count > 0:
print(f"⚠️ 检测到 {constant_bands_count} 个常数波段")
# 打印 Python 0-based 索引
print(f" Python 索引 (从 0 开始): {constant_band_indices_py.tolist()}")
# 打印 ENVI 1-based 索引 (您在 ENVI 中需要删除的波段号)
constant_band_indices_envi = constant_band_indices_py + 1
print(f" **ENVI 波段号 (从 1 开始): {constant_band_indices_envi.tolist()}**")
# 4. 数据标准化 (可选)
# X_super = preprocessing.StandardScaler().fit_transform(X_super)
return X_super
# --- 主程序 ---
if __name__ == '__main__':
# 1. 确定目标超像素数量和路径
TARGET_N_SUPERPIXELS = 10000
IMAGE_HDR_PATH = r"D:\RS_DYL\s3_RPC\ZY1E_AHSI_E89.52_N39.27_20231119_021937_L1A0000680549_H1B_f_rpcortho.hdr"
OUTPUT_DIR = Path(r"D:\RS_DYL\Output_GCN_Features")
OUTPUT_DIR.mkdir(exist_ok=True)
# 预期的保存文件路径
XSUPER_NPY_PATH = OUTPUT_DIR / 'Xsuper_features.npy'
A_NPY_PATH = OUTPUT_DIR / 'A_adjacency_matrix.npy'
# =========================================================
# --- 阶段 1: 数据加载或特征加载 ---
# =========================================================
if XSUPER_NPY_PATH.exists() and A_NPY_PATH.exists():
print(f"✅ 检测到已保存的特征。从 {OUTPUT_DIR} 加载 X_super 和 A 矩阵。")
Xsuper_out = np.load(XSUPER_NPY_PATH)
A_out = np.load(A_NPY_PATH)
# 仅为后续 HySime 步骤设置尺寸
H, W, B = (0, 0, Xsuper_out.shape[1]) # H, W 不重要,但 B 必须设置
N_super = Xsuper_out.shape[0]
print(f"加载完成。X_super 形状: {Xsuper_out.shape}")
else:
print("❌ 未检测到已保存的超像素特征。开始执行 SLIC 分割和特征提取。")
# --- 数据加载 ---
try:
img = envi.open(IMAGE_HDR_PATH, IMAGE_HDR_PATH.replace('.hdr', '.dat'))
hsi_data = img.open_memmap(writable=False).copy()
print(f"成功加载影像。尺寸: {hsi_data.shape}")
except FileNotFoundError as e:
print(f"错误:无法找到文件 {IMAGE_HDR_PATH} 或其对应的 DAT 文件。")
print(f"请检查文件路径是否正确。详细错误: {e}")
sys.exit(1)
H, W, B = hsi_data.shape
if B != 166:
print(f"⚠️ 警告:影像波段数 B={B},与预期 166 不同。")
# --- 执行超像素处理流程 ---
Q_out, Xsuper_out, A_out, Segments_out = run_superpixel_processing(
hsi_data,
target_n_segments=TARGET_N_SUPERPIXELS
)
print("\n--- 超像素处理完成!---")
# --- 结果保存 ---
sio.savemat(OUTPUT_DIR / 'Xsuper_features.mat', {'Xsuper': Xsuper_out})
sio.savemat(OUTPUT_DIR / 'A_adjacency_matrix.mat', {'A_matrix': A_out})
np.save(XSUPER_NPY_PATH, Xsuper_out)
np.save(A_NPY_PATH, A_out)
print(f"超像素特征和邻接矩阵已保存到目录: {OUTPUT_DIR}")
N_super = Xsuper_out.shape[0]
# =========================================================
# --- 阶段 2 & 3: HySime 估计端元数量 (P) 和 VCA 提取 ---
# =========================================================
X_super = Xsuper_out
# 添加数据预处理
print("\n--- 数据预处理 ---")
X_super_processed = preprocess_for_vca(X_super)
# 如果预处理后数据有变化,使用处理后的数据
X_super = X_super_processed
B = X_super.shape[1] # 更新波段数
# --- HySime 估计 P (使用改进的实现) ---
print(f"\n--- 3.1. HySime 估计端元数量 ---")
try:
# 使用改进的 HySime 实现
P_est, _ = hysime(X_super)
P_est = int(P_est)
print(f"✅ HySime 估计的端元数量 P: {P_est}")
except Exception as e:
print(f"⚠️ HySime 估计失败: {e}")
# 使用基于数据维度的经验估计
N_super = X_super.shape[0]
B = X_super.shape[1]
P_est = min(20, max(5, int(0.05 * min(N_super, B))))
print(f"🔧 使用经验端元数量 P = {P_est} (基于数据维度)")
# --- VCA 提取端元 ---
print(f"\n--- 3.2. VCA 提取初始端元 ---")
# 确保 P_est 在合理范围内
min_p = 3
max_p = min(30, B - 1)
if P_est < min_p:
print(f"⚠️ 估计的端元数量 {P_est} 小于最小值 {min_p},调整为 {min_p}")
P_est = min_p
elif P_est > max_p:
print(f"⚠️ 估计的端元数量 {P_est} 大于最大值 {max_p},调整为 {max_p}")
P_est = max_p
# 导入 VCA 函数
vca_func = import_vca()
try:
# 准备数据:VCA 期望输入是 (bands, pixels)
data_for_vca = X_super.T # 转置为 (bands, pixels)
print(f" VCA 输入数据形状: {data_for_vca.shape}")
# 调用 VCA
if vca_func == vca_numpy:
endmembers_vca, indices = vca_numpy(data_for_vca, P_est)
else:
# 尝试使用 spectral 的 VCA
endmembers_vca, indices = vca_func(data_for_vca, P_est)
# 确保端元矩阵形状正确
if endmembers_vca.shape[0] != B:
if endmembers_vca.shape[1] == B:
endmembers_vca = endmembers_vca.T
else:
# 尝试恢复
actual_bands = endmembers_vca.shape[0]
print(f"⚠️ 端元矩阵形状不匹配: 期望 {B} 波段,得到 {actual_bands} 波段")
if actual_bands < B:
# 用零填充缺失波段
temp = np.zeros((B, P_est))
temp[:actual_bands, :] = endmembers_vca
endmembers_vca = temp
else:
# 截断多余波段
endmembers_vca = endmembers_vca[:B, :]
print(f"✅ VCA 成功提取 {P_est} 个初始端元。形状: {endmembers_vca.shape}")
# --- 4. 保存 VCA 提取的端元 ---
OUTPUT_FILE = OUTPUT_DIR / 'VCA_Endmembers.mat'
sio.savemat(
OUTPUT_FILE,
{'Endmembers': endmembers_vca, 'P_est': P_est, 'Indices': indices}
)
print(f"VCA 端元和 P 值已保存到: {OUTPUT_FILE}")
except Exception as e:
print(f"❌ VCA 算法调用失败。错误: {e}")
print("尝试使用改进的纯 NumPy 实现作为后备方案...")
try:
# 强制使用改进的纯 NumPy 实现
endmembers_vca, indices = vca_numpy(X_super.T, P_est)
# 确保形状正确
if endmembers_vca.shape[0] != B:
if endmembers_vca.shape[1] == B:
endmembers_vca = endmembers_vca.T
# 保存结果
OUTPUT_FILE = OUTPUT_DIR / 'VCA_Endmembers_backup.mat'
sio.savemat(
OUTPUT_FILE,
{'Endmembers': endmembers_vca, 'P_est': P_est, 'Indices': indices}
)
print(f"✅ 使用改进的纯 NumPy 实现成功!结果已保存到: {OUTPUT_FILE}")
except Exception as e2:
print(f"❌ 改进的纯 NumPy 实现也失败: {e2}")
print("📊 尝试提供数据诊断信息:")
# 数据诊断
print(f" X_super 形状: {X_super.shape}")
print(f" X_super 数据类型: {X_super.dtype}")
print(f" X_super 的 min/max: {np.min(X_super):.4f}/{np.max(X_super):.4f}")
print(f" X_super 的 NaN 计数: {np.sum(np.isnan(X_super))}")
print(f" X_super 的 Inf 计数: {np.sum(np.isinf(X_super))}")
# 波段标准差
std_bands = np.std(X_super, axis=0)
zero_std_count = np.sum(std_bands < 1e-8)
print(f" 零标准差波段数量: {zero_std_count}")
if zero_std_count > 0:
print("💡 建议: 尝试移除零方差波段或使用数据预处理")
# 尝试提取最小数量的端元
min_p = min(3, B - 1)
print(f"🔧 尝试使用最小端元数量 P={min_p} 重新运行...")
try:
endmembers_vca, indices = vca_numpy(X_super.T, min_p)
OUTPUT_FILE = OUTPUT_DIR / 'VCA_Endmembers_emergency.mat'
sio.savemat(
OUTPUT_FILE,
{'Endmembers': endmembers_vca, 'P_est': min_p, 'Indices': indices}
)
print(f"✅ 紧急模式成功!结果已保存到: {OUTPUT_FILE}")
except Exception as e3:
print(f"❌ 紧急模式也失败: {e3}")
print("无法提取端元。请检查输入数据质量和预处理步骤。")
sys.exit(1)
(2)运行结果如下:
点击查看代码
C:\Users\Administrator\.conda\envs\hyspipeline\python.exe D:\RS_DYL\python\HySime\main.py
✅ 检测到已保存的特征。从 D:\RS_DYL\Output_GCN_Features 加载 X_super 和 A 矩阵。
加载完成。X_super 形状: (9870, 166)
--- 数据预处理 ---
数据统计: min=-2.5395, max=3.1195, mean=0.0100, std=0.9647
⚠️ 检测到 7 个常数波段
Python 索引 (从 0 开始): [98, 99, 126, 127, 128, 129, 130]
**ENVI 波段号 (从 1 开始): [99, 100, 127, 128, 129, 130, 131]**
--- 3.1. HySime 估计端元数量 ---
⚠️ 检测到 7 个常数波段
使用 159 个有效波段进行 HySime 估计
估计的噪声方差: 0.0000
⚠️ 估计的端元数量 141 大于最大值 30,使用 30
有效特征值: 141 / 159
前10个特征值: [156.365 1.2957 0.8364 0.2354 0.2163 0.0292 0.0144 0.0084
0.0055 0.0041]
噪声阈值: 0.0000
✅ HySime 估计的端元数量 P: 30
--- 3.2. VCA 提取初始端元 ---
🔧 使用改进的纯 NumPy 实现的 VCA (后备方案)
VCA 输入数据形状: (166, 9870)
⚠️ 检测到 7 个常数波段,已移除
⚠️ 端元矩阵形状不匹配: 期望 166 波段,得到 159 波段
✅ VCA 成功提取 30 个初始端元。形状: (166, 30)
VCA 端元和 P 值已保存到: D:\RS_DYL\Output_GCN_Features\VCA_Endmembers.mat
进程已结束,退出代码为 0
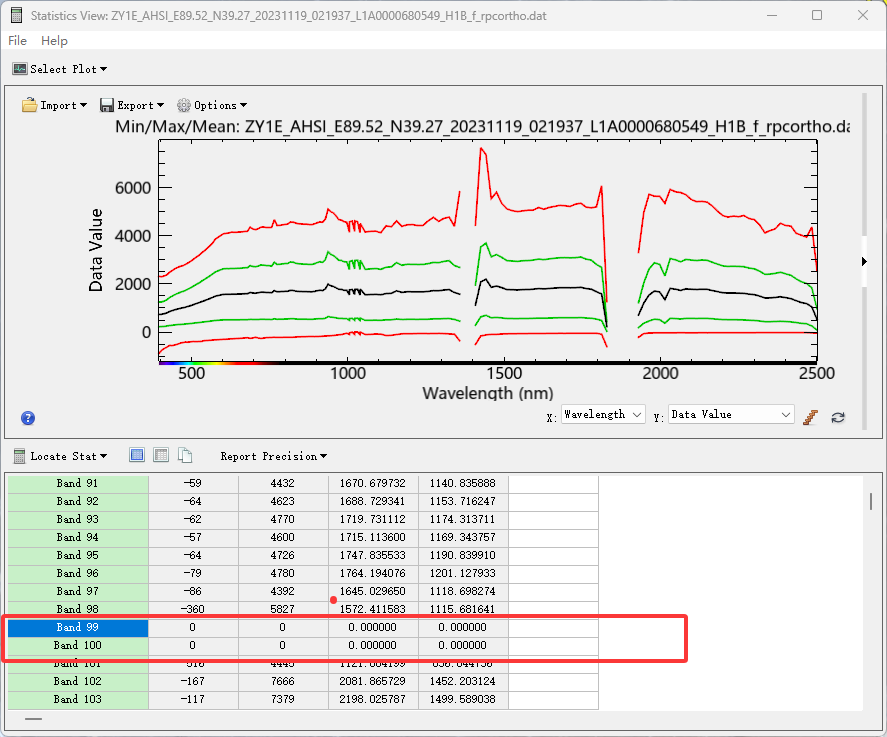
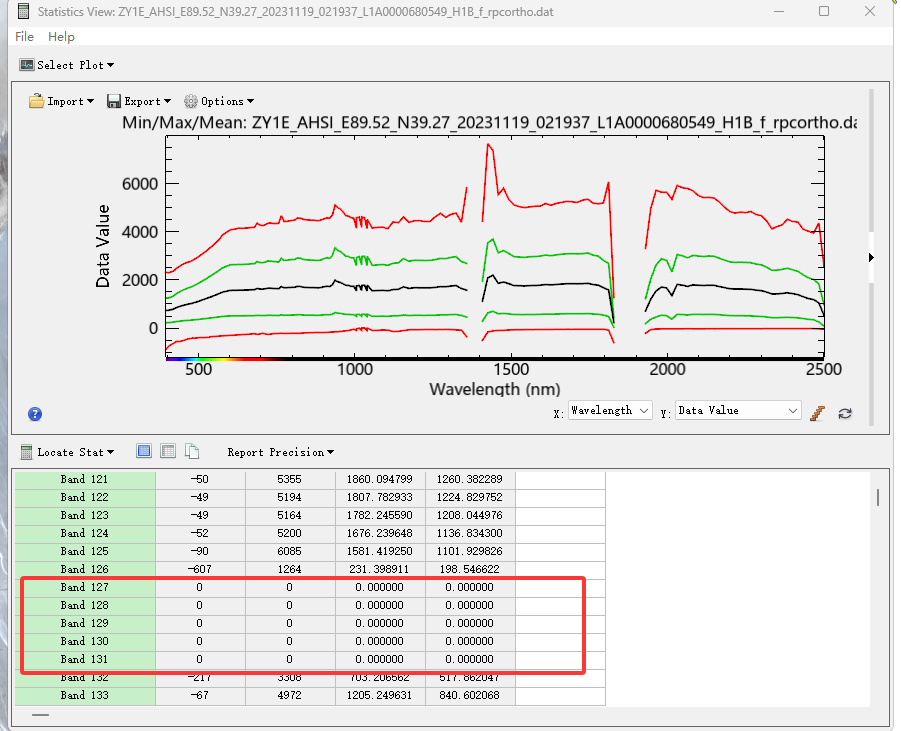
(3)要删除的波段为:
和ENVI快速统计的结果一致:ENVI 波段号 (从 1 开始): [99, 100, 127, 128, 129, 130, 131]
打开ENVI的Resize Data:
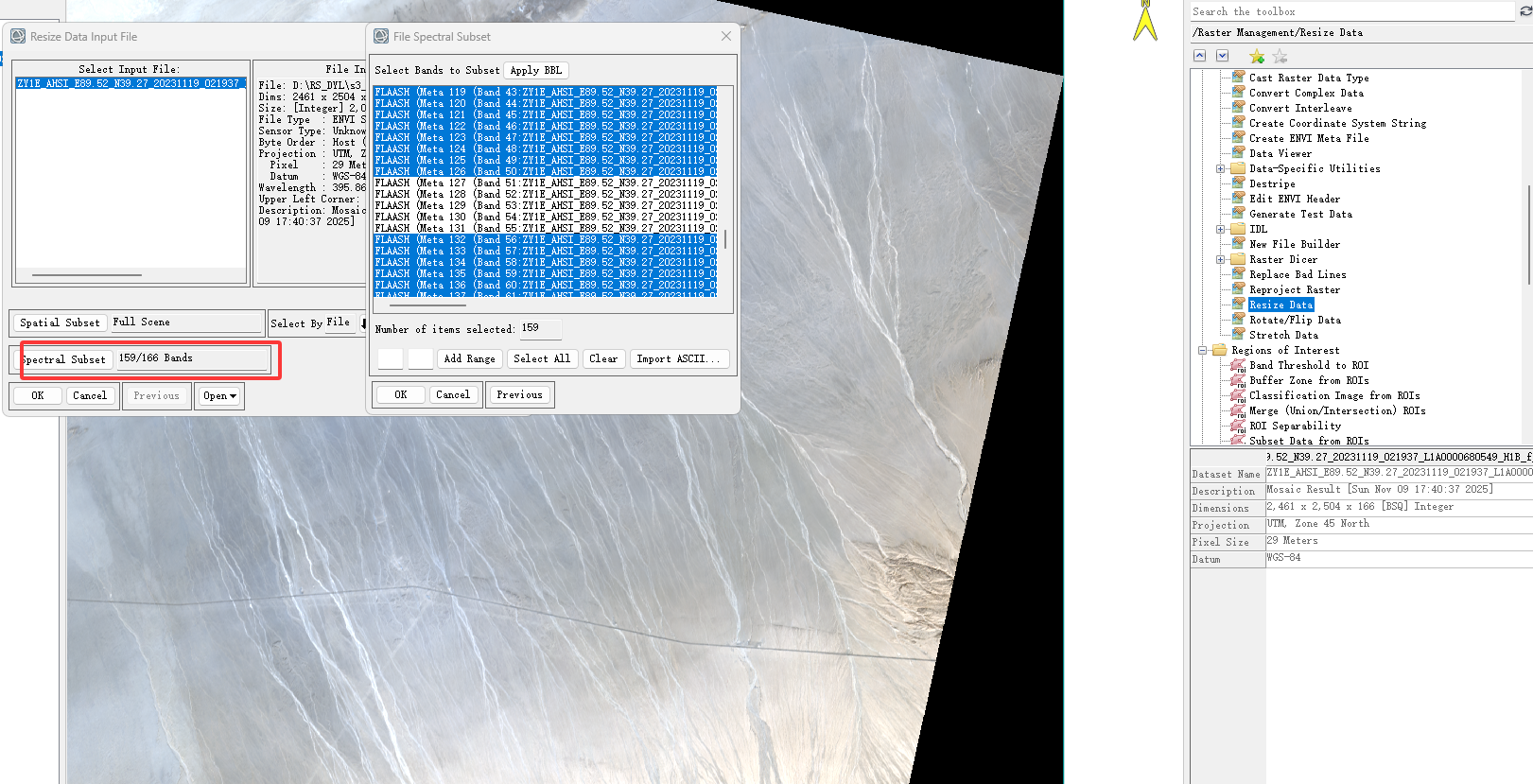
然后再File-Saveas为:20231119_021937_L1A0000680549.dat【D:\RS_DYL\s3_RPC_Remove\20231119_021937_L1A0000680549.dat】
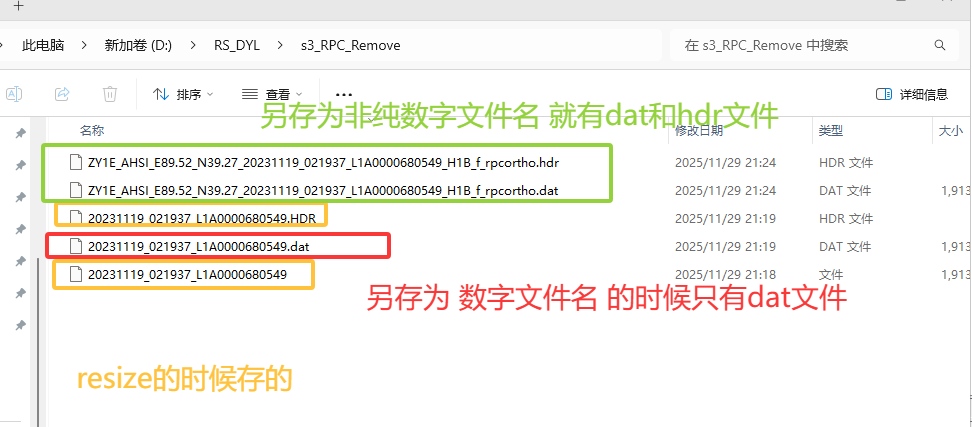
(4)另存为要注意文件名的设置:
不能保存为纯数字的文件名,否则没法自动保存后缀名为hdr文件:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号