ANTLR笔记4 - AST构造,tree grammar,tree walker
目前为止使用的例子中,都是直接在语法文件中嵌入求值处理代码,这种方式ANTLR称为嵌入式动作(embeded action)。
复杂情况下,需要基于语法树遍历(walking the tree)生成目标代码。embeded action将处理代码跟语法描述混合起来,语法复杂时使语法文件臃肿。另外语法可能经常需要修改,但语法的主要表达式不会变动,将语法识别与转换、生成(目标代码)等处理分离是有好处的。
所以产生以下概念:
识别(recognize): 前面讲的由语法描述文件生成的词法分析器、语法分析器代码,就是语法识别器(recognizer)。它接受原始输入字符流(类似源代码),进行分析,得到抽象语法树AST。
转换(translate): 我们可以编写一个转换器(translator, tree walker),使用AST作为输入,进行计算处理,或生成目标代码等操作。这个步骤同样可以使用ANTLR来完成。
1. AST构造(AST construct)
1.1 说明
使用全局option设置output=AST,ANTLR生成的识别器中每个方法都返回一个AST节点或节点集合,起始规则返回的是所有匹配到的AST节点的集合。AST节点集合都是一个链表结构。为了使识别器返回AST树,需要在语法文件中使用AST构造,告诉ANTLR在语法识别时如何构造树结构。
基于堆栈的递归算法一般采用的一种文本表达方式:
3+4: (+ 3 4)
3+4*5: (+3 (* 4 5))
即把操作符(operator)放在最前面,后面按顺序出现操作数,图形表示为

ANTLR在语法规则表达式后面添加后缀实现这种表达方式
后缀^表示它前面的表达式为操作符
后缀!表示它前面的表达式不需要生成AST节点
->为AST构造规则,左边是规则表达式(产生式),右边是AST树的构造规则。例如
ID '=' expr NEWLINE -> ^('=' ID expr);
^(...)属于构造规则的一部分,括号里面第一个元素是操作符,将作为树的根节点,其它元素为操作数,作为树的子节点。如果->右边为空,表示不构造AST节点;右边只有一个表达式,表示只构造一个AST节点,而不是AST树,例如expr NEWLINE -> expr; 。
1.2 示例
1.2.1 语法文件ExprTree.g
1.2.2 简单说明:
ASTLabelType=CommonTree; 指示AST节点的类型
$stat.tree.ToStringTree(): output指定为AST时,使用$stat.tree属性访问识别过程中构造出来的AST节点,ToStringTree()方法将AST树序列化成字符串方式。
+, -, *这几个标记使用^后缀指明为操作符。
atom中的左右括号这两个符号是输入字符流中用于表达计算优先级关系的,语法识别之后,通过AST语法树上面已经体现了这个优先级,它们本身并不需要成为语法树上的节点。
1.2.3 测试代码:
1.2.4 生成识别器,运行测试
java org.antlr.Tool ExprTree.g生成识别器
建立C# Console工程,添加ANTLR Runtime的引用,把识别器文件和测试文件添加到工程中
在工程中添加一个input.txt,设置Copy to Output Directory为Copy always,文件内容为
a=3;
b=4;
(2+a)*b+5;
编译运行,可以看到结果为
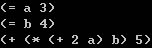
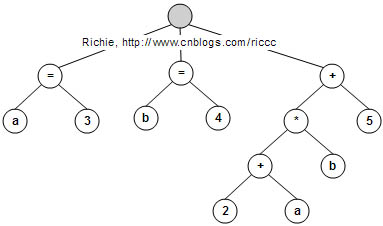
图形表示的AST语法树为
2. AST树语法(tree grammar),树的遍历(tree walking)
上面已经得到了AST树,例子中我们只需要简单求值,其它情况下可能要进行转换生成目标代码/输出。使用ANTLR的tree grammar来实现,遍历语法树,完成需要的运算。
2.1 建立一个tree grammar语法文件ExprEval.g
2.2 简单说明
1.2的示例中,使用ANTLR生成识别器的同时会产生一个符号表文件ExprTree.tokens,这里需要用到这个文件。一方面在tree grammar中不再需要定义符号,而通过符号表文件引用,另外生成的识别器在构造语法树时,每种匹配到的符号标记都将成为语法树的一个节点,符号表文件中记录了这些节点的类型(1,2,3这样的整数表示),tree grammar生成的tree walker代码在遍历AST过程中需要使用这些类型信息。
tokenVocab=ExprTree;就是指定符号表文件为ExprTree.tokens。
@header和@members中,定义了一个Dictionary,遍历过程中遇到变量声明的表达式时,用<key, value>将变量名和值保存起来。
^(...),这个操作在前面示例的语法文件中已经用过,它表示AST树上某种类型的节点,这里的意义就是当匹配到这种类型的AST树节点时,运用后面{...}中的操作。
2.3 生成tree walker代码
跟生成识别器方法一样,不过注意目录中必须有ExprTree.tokens这个文件
生成的文件名为ExprEval.cs
2.4 测试代码
2.5 编译,运行测试
把ExprEval.cs添加到工程中,测试代码改成上面,还是使用上面的input.txt作为输入。编译运行结果如下

2.6 AST构造递归描述,backtrack
将ExprEval.g中的expr规则改成下面这样:
用修改后的tree grammar重新生成ExprEval.cs文件,编译运行,这一次只要input.txt文件中给出的输入被^('+' expr ^('*' expr expr))匹配,即x+y*z这样的表达式,结果都为99。
上面只是演示两个功能: 1. ^(.. ^(..))这样AST表述;2. backtrack功能。这样做不符合AST的设计原则,但个别特殊的情况下可以用来解决特定的问题。
跟embeded action的方式对比,我们把结合在一起的操作分成了2个步骤,中间结合点是抽象语法树AST。这样对语法的描述、识别,与语法树的遍历、运算形式上独立开来,对语法树的运算处理也变得更灵活。
复杂情况下,需要基于语法树遍历(walking the tree)生成目标代码。embeded action将处理代码跟语法描述混合起来,语法复杂时使语法文件臃肿。另外语法可能经常需要修改,但语法的主要表达式不会变动,将语法识别与转换、生成(目标代码)等处理分离是有好处的。
所以产生以下概念:
识别(recognize): 前面讲的由语法描述文件生成的词法分析器、语法分析器代码,就是语法识别器(recognizer)。它接受原始输入字符流(类似源代码),进行分析,得到抽象语法树AST。
转换(translate): 我们可以编写一个转换器(translator, tree walker),使用AST作为输入,进行计算处理,或生成目标代码等操作。这个步骤同样可以使用ANTLR来完成。
1. AST构造(AST construct)
1.1 说明
使用全局option设置output=AST,ANTLR生成的识别器中每个方法都返回一个AST节点或节点集合,起始规则返回的是所有匹配到的AST节点的集合。AST节点集合都是一个链表结构。为了使识别器返回AST树,需要在语法文件中使用AST构造,告诉ANTLR在语法识别时如何构造树结构。
基于堆栈的递归算法一般采用的一种文本表达方式:
3+4: (+ 3 4)
3+4*5: (+3 (* 4 5))
即把操作符(operator)放在最前面,后面按顺序出现操作数,图形表示为
ANTLR在语法规则表达式后面添加后缀实现这种表达方式
后缀^表示它前面的表达式为操作符
后缀!表示它前面的表达式不需要生成AST节点
->为AST构造规则,左边是规则表达式(产生式),右边是AST树的构造规则。例如
ID '=' expr NEWLINE -> ^('=' ID expr);
^(...)属于构造规则的一部分,括号里面第一个元素是操作符,将作为树的根节点,其它元素为操作数,作为树的子节点。如果->右边为空,表示不构造AST节点;右边只有一个表达式,表示只构造一个AST节点,而不是AST树,例如expr NEWLINE -> expr; 。
1.2 示例
1.2.1 语法文件ExprTree.g
grammar ExprTree;
options{
output=AST;
ASTLabelType=CommonTree;
language=CSharp;
}
prog: ( stat {Console.WriteLine($stat.tree.ToStringTree());} )+ ;
stat: expr NEWLINE -> expr
| ID '=' expr NEWLINE -> ^('=' ID expr)
| NEWLINE ->
;
expr: multExpr (('+' ^|'-' ^) multExpr)* ;
multExpr: atom ('*' ^ atom)* ;
atom: INT
| ID
| '(' ! expr ')' !
;
ID : ('a'..'z'|'A'..'Z')+ ;
INT : '0'..'9'+ ;
NEWLINE: (('"r'? '"n')|';')+ ;
WS : (' '|'"t')+ { $channel = HIDDEN; } ;
options{
output=AST;
ASTLabelType=CommonTree;
language=CSharp;
}
prog: ( stat {Console.WriteLine($stat.tree.ToStringTree());} )+ ;
stat: expr NEWLINE -> expr
| ID '=' expr NEWLINE -> ^('=' ID expr)
| NEWLINE ->
;
expr: multExpr (('+' ^|'-' ^) multExpr)* ;
multExpr: atom ('*' ^ atom)* ;
atom: INT
| ID
| '(' ! expr ')' !
;
ID : ('a'..'z'|'A'..'Z')+ ;
INT : '0'..'9'+ ;
NEWLINE: (('"r'? '"n')|';')+ ;
WS : (' '|'"t')+ { $channel = HIDDEN; } ;
1.2.2 简单说明:
ASTLabelType=CommonTree; 指示AST节点的类型
$stat.tree.ToStringTree(): output指定为AST时,使用$stat.tree属性访问识别过程中构造出来的AST节点,ToStringTree()方法将AST树序列化成字符串方式。
+, -, *这几个标记使用^后缀指明为操作符。
atom中的左右括号这两个符号是输入字符流中用于表达计算优先级关系的,语法识别之后,通过AST语法树上面已经体现了这个优先级,它们本身并不需要成为语法树上的节点。
1.2.3 测试代码:
static void Main(string[] args)
{
ExprTreeLexer lex = new ExprTreeLexer(new ANTLRFileStream(@"input.txt"));
CommonTokenStream tokens = new CommonTokenStream(lex);
ExprTreeParser parser = new ExprTreeParser(tokens);
try
{
parser.prog();
}
catch (RecognitionException e)
{
Console.Error.WriteLine(e.StackTrace);
}
Console.ReadLine();
}
需要引用命名空间: Antlr.Runtime{
ExprTreeLexer lex = new ExprTreeLexer(new ANTLRFileStream(@"input.txt"));
CommonTokenStream tokens = new CommonTokenStream(lex);
ExprTreeParser parser = new ExprTreeParser(tokens);
try
{
parser.prog();
}
catch (RecognitionException e)
{
Console.Error.WriteLine(e.StackTrace);
}
Console.ReadLine();
}
1.2.4 生成识别器,运行测试
java org.antlr.Tool ExprTree.g生成识别器
建立C# Console工程,添加ANTLR Runtime的引用,把识别器文件和测试文件添加到工程中
在工程中添加一个input.txt,设置Copy to Output Directory为Copy always,文件内容为
a=3;
b=4;
(2+a)*b+5;
编译运行,可以看到结果为
图形表示的AST语法树为
2. AST树语法(tree grammar),树的遍历(tree walking)
上面已经得到了AST树,例子中我们只需要简单求值,其它情况下可能要进行转换生成目标代码/输出。使用ANTLR的tree grammar来实现,遍历语法树,完成需要的运算。
2.1 建立一个tree grammar语法文件ExprEval.g
tree grammar ExprEval;
options {
tokenVocab=ExprTree;
ASTLabelType=CommonTree;
language=CSharp;
}
@header {using System.Collections.Generic;}
@members { IDictionary<string, int> _variables = new Dictionary<string, int>(); }
prog: stat+ ;
stat: expr {Console.WriteLine($expr.value);}
| ^('=' ID expr) {_variables.Add($ID.text, $expr.value);}
;
expr returns [int value]
: ^('+' a=expr b=expr) {$value = a+b;}
| ^('-' a=expr b=expr) {$value = a-b;}
| ^('*' a=expr b=expr) {$value = a*b;}
| ID
{
$value = 0;
_variables.TryGetValue($ID.text, out $value);
}
| INT {$value = int.Parse($INT.text);}
;
options {
tokenVocab=ExprTree;
ASTLabelType=CommonTree;
language=CSharp;
}
@header {using System.Collections.Generic;}
@members { IDictionary<string, int> _variables = new Dictionary<string, int>(); }
prog: stat+ ;
stat: expr {Console.WriteLine($expr.value);}
| ^('=' ID expr) {_variables.Add($ID.text, $expr.value);}
;
expr returns [int value]
: ^('+' a=expr b=expr) {$value = a+b;}
| ^('-' a=expr b=expr) {$value = a-b;}
| ^('*' a=expr b=expr) {$value = a*b;}
| ID
{
$value = 0;
_variables.TryGetValue($ID.text, out $value);
}
| INT {$value = int.Parse($INT.text);}
;
2.2 简单说明
1.2的示例中,使用ANTLR生成识别器的同时会产生一个符号表文件ExprTree.tokens,这里需要用到这个文件。一方面在tree grammar中不再需要定义符号,而通过符号表文件引用,另外生成的识别器在构造语法树时,每种匹配到的符号标记都将成为语法树的一个节点,符号表文件中记录了这些节点的类型(1,2,3这样的整数表示),tree grammar生成的tree walker代码在遍历AST过程中需要使用这些类型信息。
tokenVocab=ExprTree;就是指定符号表文件为ExprTree.tokens。
@header和@members中,定义了一个Dictionary,遍历过程中遇到变量声明的表达式时,用<key, value>将变量名和值保存起来。
^(...),这个操作在前面示例的语法文件中已经用过,它表示AST树上某种类型的节点,这里的意义就是当匹配到这种类型的AST树节点时,运用后面{...}中的操作。
2.3 生成tree walker代码
跟生成识别器方法一样,不过注意目录中必须有ExprTree.tokens这个文件
生成的文件名为ExprEval.cs
2.4 测试代码
static void Main(string[] args)
{
ExprTreeLexer lex = new ExprTreeLexer(new ANTLRFileStream(@"input.txt"));
CommonTokenStream tokens = new CommonTokenStream(lex);
ExprTreeParser parser = new ExprTreeParser(tokens);
ExprTreeParser.prog_return r = parser.prog();
CommonTree tree = r.tree;
CommonTreeNodeStream treeStream = new CommonTreeNodeStream(tree);
ExprEval walker = new ExprEval(treeStream);
try
{
walker.prog();
}
catch (RecognitionException e)
{
Console.Error.WriteLine(e.StackTrace);
}
Console.ReadLine();
}
需要引用命名空间: Antlr.Runtime, Antlr.Runtime.Tree{
ExprTreeLexer lex = new ExprTreeLexer(new ANTLRFileStream(@"input.txt"));
CommonTokenStream tokens = new CommonTokenStream(lex);
ExprTreeParser parser = new ExprTreeParser(tokens);
ExprTreeParser.prog_return r = parser.prog();
CommonTree tree = r.tree;
CommonTreeNodeStream treeStream = new CommonTreeNodeStream(tree);
ExprEval walker = new ExprEval(treeStream);
try
{
walker.prog();
}
catch (RecognitionException e)
{
Console.Error.WriteLine(e.StackTrace);
}
Console.ReadLine();
}
2.5 编译,运行测试
把ExprEval.cs添加到工程中,测试代码改成上面,还是使用上面的input.txt作为输入。编译运行结果如下
2.6 AST构造递归描述,backtrack
将ExprEval.g中的expr规则改成下面这样:
expr returns [int value]
: ^('+' expr ^('*' expr expr)) {$value = 99;}
| ^('+' a=expr b=expr) {$value = a+b;}
| ^('-' a=expr b=expr) {$value = a-b;}
| ^('*' a=expr b=expr) {$value = a*b;}
| ID
{
$value = 0;
_variables.TryGetValue($ID.text, out $value);
}
| INT {$value = int.Parse($INT.text);}
;
这个语法不再属于LL(*)范畴,为了避免ANTLR报错,必须打开backtrack(options {backtrack=true;} )选项,让ANTLR能够完成^('+' expr ^('*' expr expr))的匹配。: ^('+' expr ^('*' expr expr)) {$value = 99;}
| ^('+' a=expr b=expr) {$value = a+b;}
| ^('-' a=expr b=expr) {$value = a-b;}
| ^('*' a=expr b=expr) {$value = a*b;}
| ID
{
$value = 0;
_variables.TryGetValue($ID.text, out $value);
}
| INT {$value = int.Parse($INT.text);}
;
用修改后的tree grammar重新生成ExprEval.cs文件,编译运行,这一次只要input.txt文件中给出的输入被^('+' expr ^('*' expr expr))匹配,即x+y*z这样的表达式,结果都为99。
上面只是演示两个功能: 1. ^(.. ^(..))这样AST表述;2. backtrack功能。这样做不符合AST的设计原则,但个别特殊的情况下可以用来解决特定的问题。
跟embeded action的方式对比,我们把结合在一起的操作分成了2个步骤,中间结合点是抽象语法树AST。这样对语法的描述、识别,与语法树的遍历、运算形式上独立开来,对语法树的运算处理也变得更灵活。


