BUAA OO-Course 2022 Unit1 Summary
BUAA OO-Course Unit1 Summary
综述
第一单元的三次作业主要是对给定输入表达式的解析、提取、存储以及化简输出,从第一次到第三次作业,需求不断增加,我们需要在需求变化的过程中对代码进行修改,扩展已有的类、增加必要的类、接口,甚至要在当前架构难以满足新任务的需求时进行重构。由于各种原因,我在这三次作业中都采用了预解析的输入方式,缺少了用递归下降的方法解析表达式的过程(具体见下面架构成型过程),因此三次作业主要集中在表达式存储和化简上。
代码结构分析
作业一
-
题目要求
输入一个表达式,表达式包括加、减、乘、乘方运算,其中乘方作用的对象为单个变量或表达式,且指数只能为0到8的整数。
-
代码分析
-
UML类图
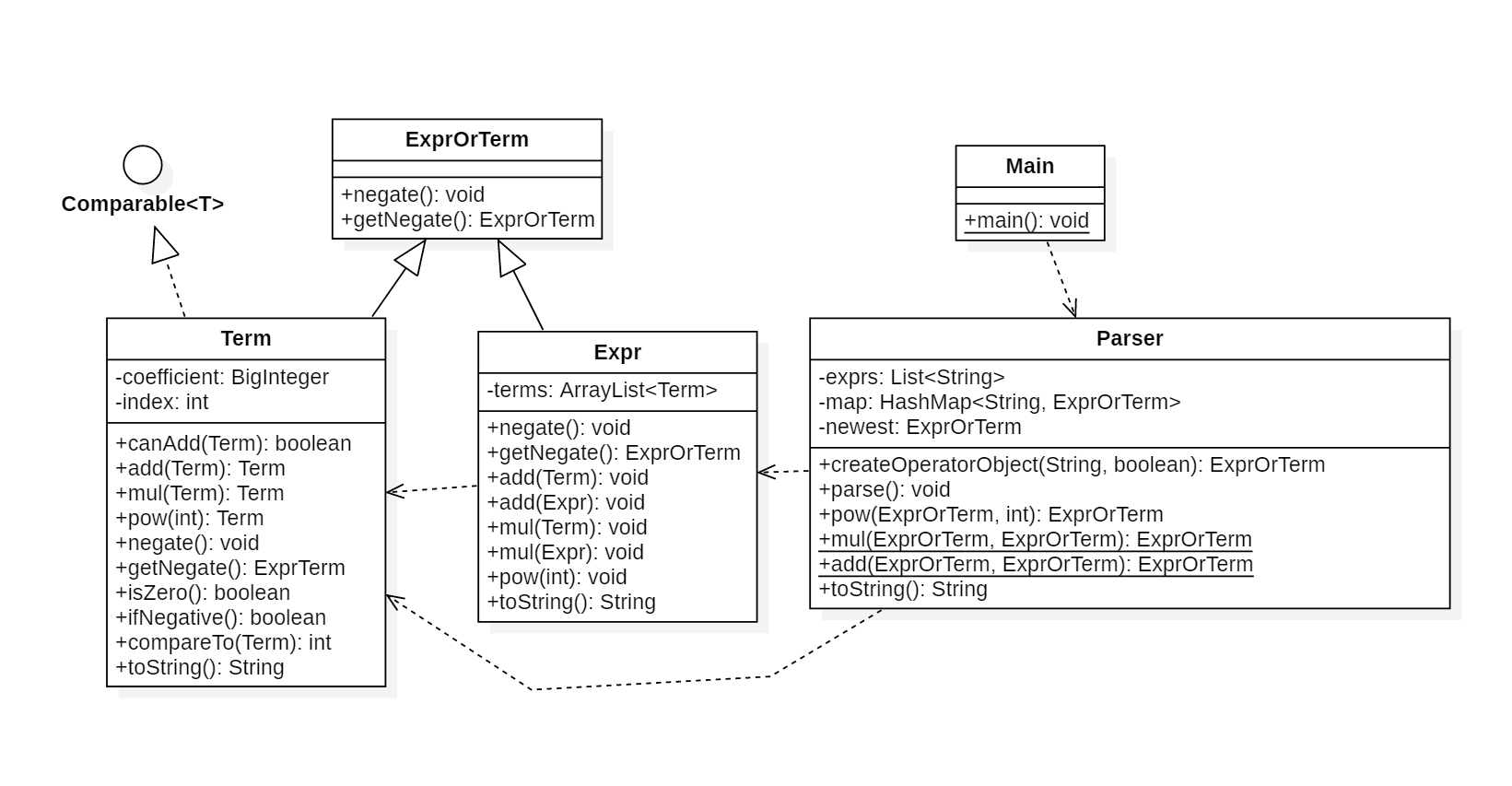
第一次作业的代码架构如上图所示(注:图中省略了每个类的所有构造方法和getter、setter方法 )。其中,每个类的含义如下:
|- Main: 主类 |- Parser: 表达式解析类 |- ExprOrTerm: expression or term (表达式或项,作为下面两个的父类) |- Expr: expression (表达式类) |- Term: (项类)如图所示,一个表达式对象由多个项组成,而项与项直接如果存在减法可以将其视作后一个项带着一个负号,这样就只需要在表达式类
Expr中设置属性ArrayList<Term>来存储每一个项,每一个项Term有系数coefficient和指数index(常数index = 0也是项),而由于项本身带有系数,项与项之间可以全看做加运算。在各类的方法中,尤其是存储类
Expr和Term包含了很多运算方法,但他们有重要区别。可以看到,Expr类中的add、mul、pow等方法返回值类型均为void;而Term类中的这三个方法返回一个Term对象,这是因为Term对象在进行这三个操作时不直接改变自身的属性,而是new一个新的对象存放结果并返回,而Expr对象则直接修改自身属性,不返回。(尽管如此,Term中仍含有许多改变属性的方法,如取相反数negate(),并不是不可变对象[1])由于第一次作业不涉及三角函数,并且我在Parser类中对输入的n个解析的操作逐一进行提取的时候,每一次操作都将其计算出结果(例如,前一次结果为一个不含括号的表达式
lastExpr,本次操作为将该表达式进行5次方的幂运算,那么在解析本次操作时就会将lastExpr运算完之后(即没有括号)的结果作为当前结果),这就保证了最新的结果中一定不含有括号,即不存在Term类的某个对象的属性中引用了Expr对象这种情况,实际的存储结构中没有递归的情况,这就大大降低了后面对表达式化简的复杂度。 -
复杂度分析
-
类复杂度分析(最终结果均保留两位或一位小数,下省略)
Class OCavg OCmax WMC ExprOrTerm 1.00 1.00 2.00 Term 1.92 11.0 25.00 Main 2.00 2.00 2.00 Expr 2.17 5.00 26.00 Parser 5.14 9.00 36.00 Total 91.00 从上表可以看出,
Parser类的圈复杂度最高,这是因为其采用了大量的条件分支对预解析输入提供的不同操作进行条件判断和处理,同时以循环的方式反复进行。总体来说复杂度算比较低。 -
方法圈复杂度分析 (圈复杂度[2])
method CogC ev(G) iv(G) v(G) Expr.add(Expr) 1.0 1.0 2.0 2.0 Expr.add(Term) 4.0 3.0 4.0 4.0 Expr.Expr() 0.0 1.0 1.0 1.0 Expr.Expr(ArrayList) 0.0 1.0 1.0 1.0 Expr.Expr(Term) 0.0 1.0 1.0 1.0 Expr.getNegate() 1.0 1.0 2.0 2.0 Expr.getTerms() 0.0 1.0 1.0 1.0 Expr.mul(Expr) 3.0 1.0 3.0 3.0 Expr.mul(Term) 1.0 1.0 2.0 2.0 Expr.negate() 1.0 1.0 2.0 2.0 Expr.pow(int) 1.0 1.0 2.0 2.0 Expr.toString() 10.0 3.0 4.0 5.0 ExprOrTerm.getNegate() 0.0 1.0 1.0 1.0 ExprOrTerm.negate() 0.0 1.0 1.0 1.0 Main.main(String[]) 1.0 1.0 2.0 2.0 Parser.add(ExprOrTerm, ExprOrTerm) 14.0 5.0 5.0 12.0 Parser.createOperatorObject(String, boolean) 9.0 6.0 6.0 6.0 Parser.mul(ExprOrTerm, ExprOrTerm) 11.0 4.0 4.0 11.0 Parser.parse() 8.0 1.0 7.0 7.0 Parser.Parser(List) 0.0 1.0 1.0 1.0 Parser.pow(ExprOrTerm, int) 4.0 4.0 2.0 4.0 Parser.toString() 2.0 2.0 1.0 2.0 Term.add(Term) 0.0 1.0 1.0 1.0 Term.canAdd(Term) 0.0 1.0 1.0 1.0 Term.compareTo(Term) 2.0 2.0 2.0 2.0 Term.getCoefficient() 0.0 1.0 1.0 1.0 Term.getIndex() 0.0 1.0 1.0 1.0 Term.getNegate() 0.0 1.0 1.0 1.0 Term.ifNegative() 0.0 1.0 1.0 1.0 Term.isZero() 0.0 1.0 1.0 1.0 Term.mul(Term) 2.0 2.0 2.0 3.0 Term.negate() 0.0 1.0 1.0 1.0 Term.pow(int) 0.0 1.0 1.0 1.0 Term.Term(BigInteger, int) 0.0 1.0 1.0 1.0 Term.toString() 14.0 11.0 7.0 11.0 Total 89.0 67.0 76.0 99.0 Average 2.54 1.91 2.17 2.83 该表的结果基本上与上面类复杂度吻合。由于需要分支对不同的操作进行判断,我们可以看到提取解析类
Parser中的几个方法复杂度都较高。但是这里值得注意的是项类Term的toString()方法的圈复杂度也很高,其平均圈复杂度在所有方法中达到了最高,这是因为在该方法中不仅仅返回一个字符串,而且在返回前对其进行了尽可能的化简。这带来了一些调试过程中的阻碍。(toString()相关问题[3])
-
-
作业二
-
题目要求
在第一次作业的基础上,本次作业新增了三角函数、自定义函数和求和函数。由于预解析输入的特性,求和函数和自定义函数通过预解析能过转化为加、减、乘、乘方以及三角函数运算,因此本次作业的设计主要围绕三角函数带来的相关存储和化简问题进行。
-
代码分析
-
UML类图
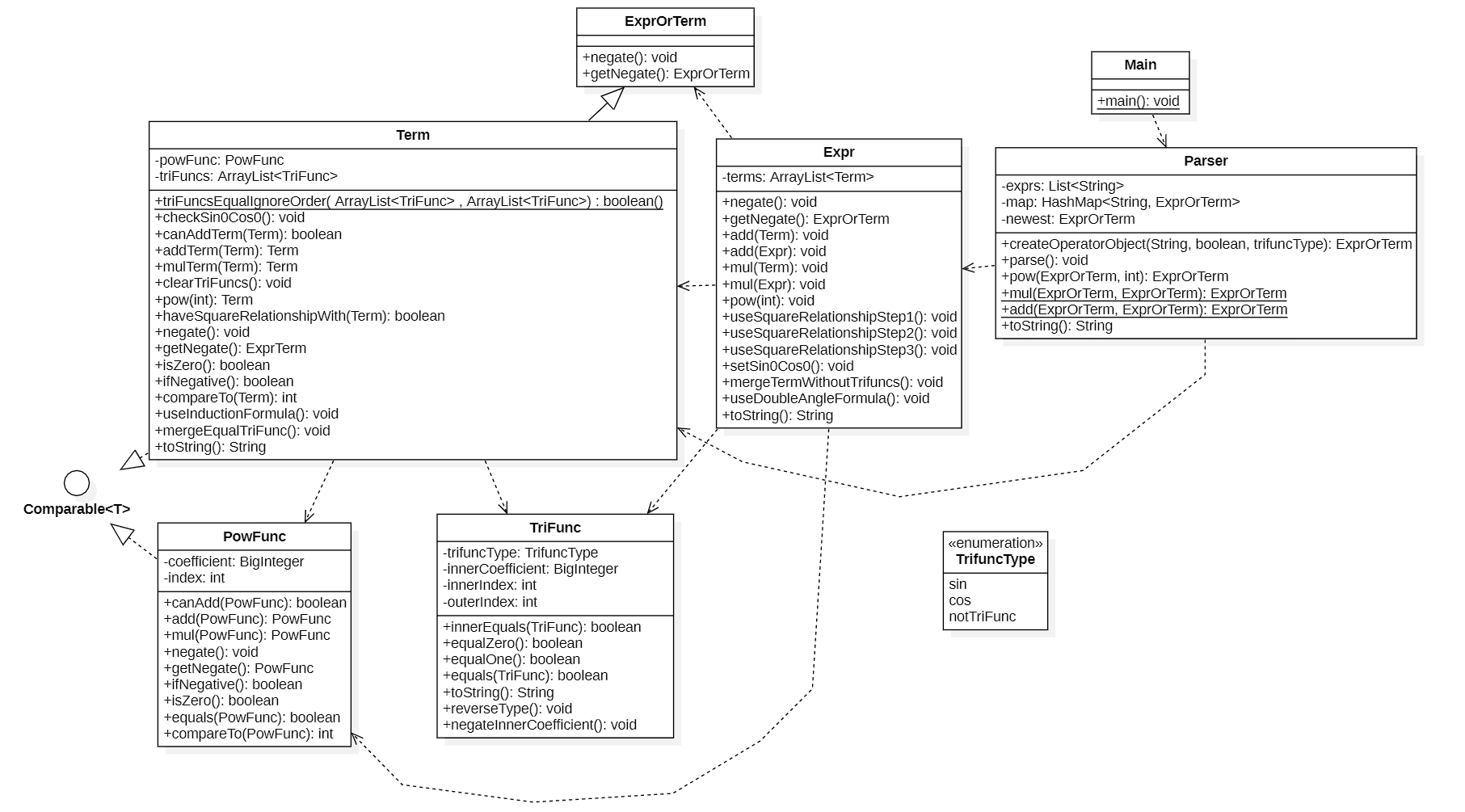
第二次作业的类图如上所示。可以看到,原来的
项Term这一类的两个属性系数coefficient和指数index变成了新建的被移到了新建的类PowFunc中,而现在的Term类的属性中一个引用刚才的PowFunc类的对象,另一个引用TriFunc类的对象。这是因为第一次作业中的Term类存的是一个不包含三角函数的幂函数(x的指数和系数);而现在,表达式中的一项除了包含幂函数以外,还可能有0个、1个或多个三角函数,这就需要一个三角函数类型(即上图中的类TriFunc的容器作为Term类的属性,该容器中存放着这一项中的所有三角函数的引用。具体的类定义如下所示:|- Main: 主类 |- Parser: 表达式解析类 |- ExprOrTerm: expression or term (表达式或项,作为下面两个的父类) |- Expr: expression (表达式类) |- Term: (项类) # change |- PowFunc: power function (幂函数类) |- TriFunc: trigonometric function (三角函数类) |- TrifuncType: types of trigonometric function (三角函数类型枚举常量)TriFunc类中的属性trifuncType为枚举类型,只能在sin、cos、notTriFunc(该对象非三角函数,该对象实际上不会输出,便于在比较Term的时候判断类型)取值。因此在输出的时候,现在Expr对象的toString()方法中对每个Term类调用toString(),而Term则分别调用PowFunc和TriFunc类的toString()方法进行输出。 -
复杂度分析
-
类复杂度分析
Class OCavg OCmax WMC TrifuncType 0.0 ExprOrTerm 1.0 1.0 2.0 TriFunc 1.63 8.0 26.0 PowFunc 1.86 11.0 26.0 Main 2.0 2.0 2.0 Term 2.43 9.0 56.0 Expr 4.06 10.0 73.0 Parser 6.0 9.0 42.0 Total 227.0 Average 2.80 7.14 28.38 如图所示,
Parser复杂度高的原因与第一次作业相同,不再赘述。这里可以发现Expr类的复杂度比上一次增加很多,这是因为其增加了很多化简方法。而所有化简方法都会被toString()方法调用(这不是好习惯,具体见toString()相关问题[3:1]),导致了其圈复杂度激增,下面通过方法圈复杂度更具体地分析。 -
方法圈复杂度分析 (圈复杂度[2:1])
由于篇幅限制,这里仅列出几个复杂度较高的方法:
method CogC ev(G) iv(G) v(G) ...... Parser.parse() 17.0 1.0 9.0 9.0 Term.haveSquareRelationshipWith(Term) 7.0 2.0 12.0 13.0 Parser.mul(ExprOrTerm, ExprOrTerm) 11.0 4.0 4.0 11.0 Parser.pow(ExprOrTerm, int) 4.0 4.0 2.0 4.0 Term.isZero() 7.0 4.0 5.0 5.0 Parser.add(ExprOrTerm, ExprOrTerm) 14.0 5.0 5.0 12.0 Expr.mergeTermWithoutTrifuncs() 16.0 7.0 4.0 8.0 Expr.useDoubleAngleFormula() 37.0 7.0 15.0 20.0 Expr.useSquareRelationshipStep2() 21.0 8.0 6.0 12.0 Expr.useSquareRelationshipStep3() 22.0 8.0 9.0 15.0 TriFunc.toString() 12.0 8.0 9.0 10.0 Parser.createOperatorObject(String, boolean, TrifuncType) 19.0 9.0 8.0 9.0 Term.triFuncsEqualIgnoreOrder(ArrayList, ArrayList) 16.0 9.0 5.0 9.0 PowFunc.toString() 14.0 11.0 7.0 11.0 ...... Total 309.0 168.0 220.0 280.0 Average 3.815 2.07 2.71 3.46 这里首先对一些方法的名字进行解释:
public boolean haveSquareRelationshipWith(Term another) { // in class Term // 判断两个项是否具有平方关系 // 如:4*x**4*sin(8)**2 和 4*x**4*cos(8)**2具有平方关系,返回true } public void useSquareRelationshipStep2() { // in class Expr // 使用上述平方关系,共有三步 } public void mergeTermWithoutTrifuncs() { // in class Expr // 将没有Trifunc,即不含三角函数的项尽可能的合并 } public void useDoubleAngleFormula() { // in class Expr // 使用如下二倍角公式(三角函数内部没有x) // 4*sin(6)*cos(6) = 2*sin(12) } private static boolean triFuncsEqualIgnoreOrder( ArrayList<TriFunc> t1s, ArrayList<TriFunc> t2s) { // in class Term // 内部处理使用的私有静态方法 // 判断两个Term是否含有相同的triFunc(每个都要相同,但不考虑存储顺序) }从上面名字可以看出,这些复杂度较高的方法都是化简三角函数的方法。这里的化简我考虑了简单的平方关系(必须sin和cos同时存在)和二倍角公式。值得注意的是,在第二次作业中三角函数内部的数有所限制,如下的化简时违法的:
2*sin(x)\*cos(x) = sin(2\*x)或2*sin(x)\*cos(x) = sin((2\*x)),故我只做了里面为常数的化简。这有一个静态方法triFuncsEqualIgnoreOrder,比较两个项中的属性ArrayList<TriFunc>是否相等。这种静态方法的使用不太符合面向对象程序设计的架构,而更偏向于面向过程的架构。因此,我认为应该改成如下更合理:public boolean triFuncsEqualIgnoreOrder(Term another) { ArrayList<TriFunc> thisTriFuncs = this.trifuncs; // 对应t1s ArrayList<TriFunc> anotherTriFuncs = another.trifuncs; // 对应t2s //.... }
-
-
作业三
-
题目要求
在第二次作业的基础上,三角函数内的东西不仅仅是系数为一的幂函数或常数,而扩展成因子,即里面可能是一个带括号的表达式,同时自定义函数的调用增加了嵌套的情况。由于本次作业采用的是预解析的方式,只需要考虑三角函数嵌套。
-
代码分析
-
UML类图

与第二次作业的类图相比,整体上看起来没什么变化。但实际上在细节上做了很多处理。类定义解释如下:
|- Main: 主类 |- Parser: 表达式解析类 |- ExprOrTerm: expression or term (表达式或项,作为下面两个的父类) |- Expr: expression (表达式类) |- Term: (项类) # change |- PowFunc: power function (幂函数类) |- TriFunc: trigonometric function (三角函数类) |- TrifuncType: types of trigonometric function (三角函数类型枚举常量) |- InnerType: types of the inner object in trigonometric function (三角函数内的的对象类型)InnerType为新增加的枚举类型,用于表示三角函数内部对象的类型。由于三角函数内部可能有所有因子,这就导致其产生了一个递归的引用结构。另一个重要变化是,ExprOrTerm、Term、Expr、PowFunc、TriFunc都实现了自己的equals()方法。其中ExprOrTerm、Term、Expr的equals()方法是对Object类方法的重写,这是为了保证在判断两个三角函数内部对象是否相等时能够合法的调用equals()方法。(若equals()方法中参数类型不是Object,则不能传入其他类型的参数) -
复杂度分析
-
类复杂度分析
Class OCavg OCmax WMC TrifuncType 0.0 TriFunc 3.57 20.0 75.0 Term 3.04 14.0 76.0 PowFunc 1.86 12.0 28.0 Parser 7.0 15.0 49.0 Main 2.0 2.0 2.0 InnerType 0.0 ExprOrTerm 1.33 2.0 4.0 Expr 4.3 11.0 86.0 Total 320.0 Average 3.47 10.85 35.55 与前两次作业相比,每个类的复杂度都多了很多,特别是
TriFunc三角函数类。第三次作业沿用了第二次作业中对三角函数的几个化简,但是由于三角函数可以嵌套任何对象,需要对三角函数内部使用多个条件语句进行内部的类型判断,从而分别对其进行处理。复杂度的激增可以从下面方法圈复杂度分析看出。 -
方法圈复杂度分析 (圈复杂度[2:2])
由于篇幅限制,这里仅列出几个复杂度较高的方法:
method CogC ev(G) iv(G) v(G) ...... Parser.parse() 21.0 1.0 9.0 10.0 Term.mergeEqualTriFunc() 20.0 1.0 10.0 10.0 Term.haveSquareRelationshipWith(Term) 7.0 2.0 11.0 12.0 Parser.mul(ExprOrTerm, ExprOrTerm) 11.0 4.0 4.0 11.0 Parser.pow(ExprOrTerm, int) 4.0 4.0 2.0 4.0 Term.isZero() 7.0 4.0 5.0 5.0 Expr.mergeTerm() 12.0 5.0 5.0 7.0 Parser.add(ExprOrTerm, ExprOrTerm) 14.0 5.0 5.0 12.0 Term.useInductionFormula() 28.0 6.0 13.0 16.0 Expr.useSquareRelationshipStep2() 21.0 8.0 6.0 12.0 Expr.useSquareRelationshipStep3() 22.0 8.0 8.0 14.0 TriFunc.innerUseInductionFormula() 16.0 8.0 7.0 8.0 Expr.useDoubleAngleFormula() 46.0 9.0 15.0 22.0 TriFunc.equalOne() 16.0 9.0 10.0 11.0 TriFunc.equalZero() 16.0 9.0 10.0 11.0 Expr.equals(Object) 18.0 11.0 5.0 11.0 Term.triFuncsEqualIgnoreOrder(ArrayList, ArrayList) 19.0 11.0 6.0 12.0 PowFunc.toString() 17.0 12.0 7.0 12.0 Parser.createOperatorObject(String, boolean, TrifuncType) 36.0 15.0 14.0 15.0 TriFunc.toString() 48.0 20.0 22.0 25.0 ...... Total 492.0 242.0 298.0 382.0 上面所示方法圈复杂度的增加大部分都是由于
TriFunc内部存放其他类型变量这一原因导致的。具体的来说,TriFunc.toStirng()方法在返回字符串时需要判断其内部的类型,是否没有嵌套(innerNormal)、或者嵌套一个Term对象,或者嵌套三角函数自己?这就需要递归的进行判断分析。同时,即便是最简单的没有嵌套的情况innerType = innerNormal,出于性能分的考虑,为了缩短长度,需要对内部幂函数指数为0、指数为1、指数为2进行特殊处理。这就又增加了条件判断分支的个数,最终造成了可怕的复杂度。
-
-
bug分析
-
第一次作业
由于采用预解析的方法,只需要按需存储每一项;在输出时也只需要一层遍历,所以没什么bug
-
第二次作业
第二次作业在做
cos(0)化简的时候过于“鲁莽”,遇到cos(0)就直接返回1,导致了下面这种bug:// standard input: 0 cos(0)*sin(x) // my output: 1并成功地在强测和互测中都被测出。
-
第三次作业
本次作业的bug较难修改。先看测出bug的输入输出:
// standard input: 0 sin((-x))**2 // my output: -sin(x)**2乍一看是
Term在使用诱导公式化简时没有区分判断外面的指数,但是当我查看Term类的代码时发现并非如此。于是我用单步调试,却发现单步调试输出的结果不一样[^单步调试输出的结果不一样],它输出了正确答案sin(x)**2。在解决输出不一致的问题后,我才发现,原来是由于三角函数内部存在所有因子的可能,在该因子所在的类中没有过对调用它的三角函数类外面的指数有无进行判断导致出错,其他错误类似。当然了,第三次作业的bug较多的原因还有测试没做够这一因素,这再一次印证了面向评测机编程是行不通的。
Hack 策略
对于我自己来说,Hack主要采取一下几种方式(按照简单到复杂)
-
首先是用自己测试过程中测出自己程序bug的数据试一试,看看别人的程序是否也存在相同的问题。
-
其次是试一些边界数据,如下面这个hack成功的例子:
-
标准输入:
0 x + 99999999999999999999 -
标准输出:
Mode: Parsed -
标准异常:
Exception in thread "main" java.lang.NumberFormatException: For input string: "99999999999999999999" at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.lang.Long.parseLong(Long.java:592) at java.lang.Long.parseLong(Long.java:631) at MainClass.main(MainClass.java:79)
-
-
再次就是拿别人的程序和自己的对拍,这样既可能发现别人的bug,也可能发现自己的bug。
-
当然,最有用的还是认真阅读别人的代码,从别人的表达式预处理、解析、存储、运算、化简和输出逻辑中寻找是否有漏洞,从而进行hack。
其他知识上的收获
介绍
本部分内容也许和面向对象程序设计关系没那么大,但确实是我在搜集资料、完成作业过程中收获的一些知识,这里正好在此稍作总结。
内容
-
并发修改异常的报错
我们知道,java提供了
foreach循环的格式,截取我代码的一部分如下:for (Term term : terms) { // foreach if (term.getTriFuncs().size() != 0) { for (int j = 0; j < term.getTriFuncs().size(); j++) { TriFunc triFunc = term.getTriFuncs().get(j); if (triFunc.equalOne()) { // cos(0) term.getTriFuncs().remove(triFunc); // change!!! // ...... } } } }在双层for循环中,内部有可能会修改外层循环对象所对应的值,而外层的循环变量用的是迭代器,每次内部通过
next()方法调用,按理来说IDEA应该会产生一个ConcurrentModificationException并发修改异常。但是我在测试的时候发现IDEA有时候报错,有时候不报错。查找关于并发修改异常报错[4]的资料后才发现,如果遍历到最后一个元素后才修改迭代器对应迭代对象的属性,循环在throwConcurrentModificationException之前就退出了,故不会产生报错。 -
java switch-case、enum相关
-
首先我有如下枚举常量定义:
public enum InnerType { // 三角函数括号里内容的类型 innerExpr, innerTerm, innerTrifunc, innerNormal }在
switch-case中如下写会产生错误:switch (innerType) { case InnerType.innerExpr: //aaaa //bbbb break; case //... //... }错误信息:
java: an enum switch case label must be the unqualified name of an enumeration constant需将代码改成如下形式:
switch (innerType) { case innerExpr: //aaaa //bbbb break; case //... //... }报错的原因是Java会自动推断case后面元素的类型,因此标签必须是不受保护和限制的(unqualified)。在一般的switch case语句使用中,如果switch后面跟着一个int类型变量,我们也不会在case特地强调类型,而是简单的使用
case 1,这里枚举常量的使用其实本质上是一样的。 -
进一步地,根据IDEA的化简提示,可以将
switch-case语句进一步优化,如下所示:public enum Month { JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC; } public static int getNumberOfDays(Month month, boolean isLeapYear) { return switch(month) { case APR, JUN, SEP, NOV -> 30; case FEB -> (isLeapYear)? 29: 28; case JAN, MAR, MAY, JUL, AUG, OCT, DEC -> 31; }; }可以省略break的使用而不影响结果。
-
更多信息详见java14 switch-case用法[5]。
-
-
toString()相关问题
从前面代码结构分析中可以看出,我在
toString()方法中调用了所有化简的方法。如:Expr类的toString()方法如下:@Override public String toString() { setSin0Cos0(); mergeTerm(); useDoubleAngleFormula(); Collections.sort(terms); useSquareRelationshipStep1(); useSquareRelationshipStep2(); useSquareRelationshipStep3(); mergeTerm(); Collections.sort(terms); useSquareRelationshipStep1(); useSquareRelationshipStep2(); StringBuilder res = new StringBuilder(); for (int i = 0; i < terms.size(); i++) { //... } return res.toString(); }复杂度复杂本身不可怕,但是如果在这之中对对象的属性进行了修改,则可能会产生一些奇怪的结果。前面也讲了,正是因为在
toString()中调用了会改变对象属性的方法,我在调试中遇到了很多玄学问题。具体来说,就是使用IDEA直接输出的结果和单步调试输出的结果不同。经过数次重复和查找资料我才发现,原理是因为IDEA在单步调试的时候默认勾选了Enable 'toString()' object view,这意味着每走一步IDEA都会自动调用相关局部变量的toString()方法,而如果toString()方法中修改了对象的属性则很可能导致结果不同。为了解决toString()问题[6],可以临时在IDEA的settings中的Build, Execution, Deployment-Debugger-Data Views-Java中取消勾选Enable 'toString()' object view,可以暂时地解决问题。当然,最好的办法是不要再toString()方法中修改参数。 -
不可变对象与深克隆问题
关于不可变对象与深克隆问题[7],在讨论区中有非常多的讨论,
虽然我提出的利用反射的方法实现深克隆被禁止了。总的来说,如果要实现深拷贝,要么对每个类重写equals()方法,要么对每个类重写clone()方法,要么将相关对象设置为不可变类型,直接避开深克隆浅克隆问题。另外有同学提出的反序列化我没太了解,在此不做说明。其实最“粗鲁”的方法是每次返回对象的时候都“递归地”new一个新的对象。具体描述见文后链接。
架构成型过程与心得体会
最开始在第一次作业时,由于畏难情绪以及本身对递归下降理解不透而放弃了一般输入模式,结果使得第二、三次作业都不得不在第一次作业的基础上进行。说实话,三次作业都采用预解析对我而言还是蛮遗憾的。除了分数上的减少,更重要的是缺少了对递归下降解析表达式这一过程的理解和训练。
就预解析这三次作业来说,第一次作业构造的类与关系基本上保留到了第三次(第二次、第三次的PowFunc类实际上是第一次作业的Term类,都表示幂函数)。后面的作业在前面的基础上逐渐添加不同的属性,在一个类中添加不同重载的构造方法,不断增加新的化简过程。就数据上三次作业复杂度的攀升来说,其实可以把化简相关的逻辑专门放到一个类中,可以更好地降低类与类之间的耦合度(表达式类中不得不进行很多项类的操作等)。同时也可以尝试使用讨论区中其他同学提到的用HashMap等数据结构保存表达式方便合并的思想等等。
希望下次作业能够尝试类似于本单元“一般输入”的做法,同时在类的设计时多多分析复杂度和如何实现层次化的结构,而不是一股脑地把很多操作放在一个方法中。
相关引用和资料
不可变对象由于其在构造后属性不变,在共享、引用、拷贝的时候的
浅克隆可以视为深克隆,有关第三次作业中的相关处理见博客中其他知识上的收获部分 ↩︎java14 switch-case用法课程网站博客,stackoverflow相关问题,oracle官方文档说明 ↩︎

