
机器学习—贷款能力的评估
一、选题背景
在社会经济的不断发展的催化下,“贷款”应由诞生。贷款解决了许多人暂时性的资金不足的问题,但同时也产生了许多无力偿还,造成违约的的案列 。本人对于验证人的偿还能力比较感兴趣所以选择了改课题研究方向。数据来源于UCI机器学习数据中的台湾违约案列,针对贷款能力的评估。
附上数据来源链接:UCI Machine Learning Repository
二、机器学习案列和设计方案
1.机器学习案列来源:UCI机器学习数据集,整体数据集分为训练与测试集。
2.框架描述:①读取数据并处理
②数据预处理(pca,标准化)
③svm,logtistic,随机森林,Kmeans四种模型训练
④模型评估
3.技术难点与解决思路:数据集比较难,特征多,不易得到好结果。
采用PCA降维处理,数据标准化。
模型简单描述:
PCA(Principal Component Analysis)
即主成分分析方法,是一种使用最广泛的数据降维算法(非监督的机器学习方法)。其最主要的用途在于“降维”,通过析取主成分显出的最大的个别差异,发现更便于人类理解的特征。也可以用来削减回归分析和聚类分析中变量的数目。
SVM(support vector machines)
支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。SVM 适合中小型数据样本、非线性、高维的分类问题。
逻辑回归(Logistic Regression)
Logistic Regression算法是一个分类算法,分类算法是一种监督学习算法,它是指根据样本的特征,将样本划分到指定的类别中。Logistic Regression是一个二分类的线性分类算法,说到线性分类算法就不得不说一下线性可分与线性不可分的概念了,如果一个分类问题可以使用线性判别函数正确分类,则称该问题为线性可分,否则称为线性不可分问题。
随机森林(RandomForest)
随机森林是一个元估计器,它适合数据集的各个子样本上的多个决策树分类器,并使用平均值来提高预测精度和控制过度拟合。 子样本大小始终与原始输入样本大小相同,但如果bootstrap = True(默认值),则会使用替换来绘制样本。
K-means聚类算法
kmeans算法又名k均值算法。其算法思想大致为:先从样本集中随机选取 kk 个样本作为簇中心,并计算所有样本与这 kk 个“簇中心”的距离,对于每一个样本,将其划分到与其距离最近的“簇中心”所在的簇中,对于新的簇计算各个簇的新的“簇中心”。实现kmeans算法的主要三点:(1)簇个数 kk 的选择(2)各个样本点到“簇中心”的距离(3)根据新划分的簇,更新“簇中心”。
附上学习转载链接:机器学习算法(一)SVM_yaoyz105-CSDN博客_svm
Python实现Logistic Regression(逻辑回归模型)算法_象在舞的技术专栏-CSDN博客_python实现逻辑回归模型
机器学习分类算法(六)-随机森林算法_猫敷雪-CSDN博客_机器学习 随机森林
K-means聚类算法原理及python实现_Flaneur-yz的博客-CSDN博客_k-means聚类算法python实现
kmeans算法理解及代码实现 - LLLiuye - 博客园 (cnblogs.com)
附上数据集小部分截图及其变量解释:

X1:给定信贷的金额(新台币):它包括个人消费者信贷和他/她的家庭(补充)信贷。
X2:性别(1 = 男性;2 = 女性)。
X3:教育(1 =研究生院;2=大学;3=高中;4=其他)。
X4:婚姻状况(1 =已婚;2=单身;3=其他人)。
X5:年龄(年)。
X6 - X11:过去付款的历史记录。我们跟踪了过去的每月付款记录(2005年4月到9月)
X12-X17:账单金额(新台币)。
X18-X23:之前付款金额(新台币)。
三、机器学习的实现步骤
导入相关的库
1 #导入相关的库 2 import numpy as np 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 from sklearn.linear_model import LogisticRegression 6 from sklearn.model_selection import GridSearchCV 7 from sklearn.model_selection import train_test_split 8 from sklearn.metrics import f1_score, auc, roc_curve 9 from sklearn.svm import LinearSVC 10 from sklearn.ensemble import RandomForestClassifier 11 from sklearn.cluster import KMeans 12 from sklearn.preprocessing import StandardScaler 13 from sklearn.metrics import mean_absolute_error 14 from sklearn.metrics import mean_squared_error 15 from sklearn.ensemble import RandomForestRegressor 16 import joblib 17 from tqdm import tqdm
读取文件以及数据分析
1 #读取文件以及数据分析 2 head = 1 3 index = "ID" 4 data = pd.read_excel("D:/default of credit card clients.xls", header=head, index_col=index) 5 #查看前五行数据 6 data.head(5)
结果截图:
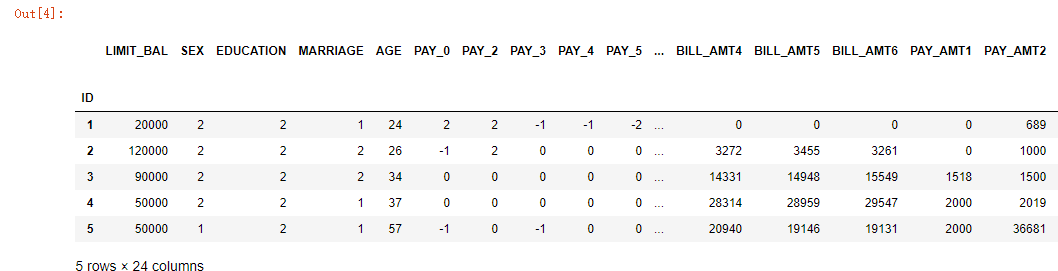
(可以看出数据特征较多,如果直接训练结果不会很好!)
1 #可见数据有20多个特征,特征值分为0,1 2 print(data.shape) 3 data = data.dropna() 4 print(data.shape) 5 data.describe()
结果截图:
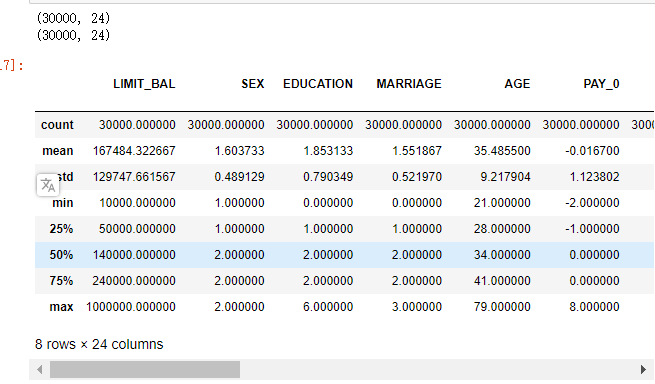
(可见没有缺失值)
数据预处理
1 #上面测试过,并未有缺失值,所有不做处理 2 #设置两个列表用于最终结果绘图 3 acc_all = [] 4 mse_all = [] 5 #标签值与特征分开 6 X = data.iloc[:, 0:23] 7 Y = data.iloc[:, 23] 8 #数据特征较多,所有进行降维处理,并且不断调参以后发现10会得到较好结果 9 #pca降维 10 from sklearn.decomposition import PCA 11 pca = PCA(n_components=10) 12 X0 = pca.fit_transform(X) 13 14 #数据标准化 15 S = StandardScaler() 16 S.fit(X0) 17 X = S.transform(X0)
因为数据特征多,所以使用pca降维算法,还用了数据标准化,因为数据比较分散。
PS:Pca降维能使得所有模型准确率提高5%左右,标准化能使得svm和逻辑回归模型准确率提高20%左右,但对于随机森林没有任何影响(因为随机森林对于数据零散没有影响),反而使得kmean准确率降低15%左右(因为kmeans自然是数据越分散越好)。
数据集分割
1 x_train, x_test, y_train, y_test = train_test_split(X, Y, 2 train_size=0.8, random_state=999) 3 print(x_train.shape, y_train.shape) 4 #对于kmeans不需要标准化的效果更好所所以给出一份数据用于kmeans 5 x_train0, x_test0, y_train0, y_test0 = train_test_split(X0, Y, 6 train_size=0.8, random_state=999)
结果截图:

(8:2分割,设置好随机种子,便于分析结果)
接下来进入模型训练环节
SVM模型测试以及评估
1 #训练未标准化的数据 2 svm = LinearSVC() 3 svm.fit(x_train, y_train) 4 #训练未标准化数据 5 svm0 = LinearSVC() 6 svm0.fit(x_train0, y_train0)
1 #测试集预测准确率 2 print("标准化svm的准确率", svm.score(x_test, y_test)) 3 y_pred = svm.predict(x_test) 4 5 print("未标准化svm的准确率", svm0.score(x_test0, y_test0)) 6 y_pred0 = svm0.predict(x_test0) 7 8 acc_all.append(svm.score(x_test, y_test)) 9 acc_all.append(svm0.score(x_test0, y_test0)) 10 #误差分析 11 print(mean_squared_error(y_test, y_pred)) 12 mse_all.append(mean_squared_error(y_test, y_pred)) 13 print(mean_squared_error(y_test, y_pred0)) 14 mse_all.append(mean_squared_error(y_test, y_pred0)) 15 #绘制ROC曲线 16 y_score = svm.fit(x_train, y_train).decision_function(x_test) 17 fp, tp, threshold = roc_curve(y_test, y_score) 18 roc_auc = auc(fp, tp) 19 20 plt.figure(figsize=(10,4)) 21 plt.plot(fp, tp, color='darkorange', 22 lw=2, label='ROC curve (area = %0.2f)' % roc_auc) 23 plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') 24 plt.xlim([0.0, 1.0]) 25 plt.ylim([0.0, 1.05]) 26 plt.xlabel('FP') 27 plt.ylabel('TP') 28 plt.title('ROC曲线') 29 plt.legend(loc="best") 30 plt.show()
结果截图:

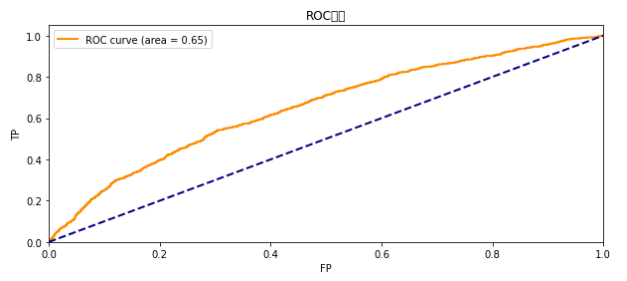
标准化SVM的准确率能达到0.773
未标准化SVM的准确率能达到0.5705
小总结:明显标准化对于svm的分类是正向作用,所有以后采用svm分类时尽量进行数据标准化,Svm参数可以调节的主要是核函数,但rbf运行会很慢所有不做展示。
逻辑回归训练以及ROC曲线绘制
1 clf = LogisticRegression(C=0.01) 2 g = GridSearchCV(clf, param_grid=[{'C':[0.01, 0.1, 1, 10]}], cv=4) 3 g.fit(x_train, y_train) 4 print("最好分数是:", g.best_score_) 5 print("最好参数是", g.best_params_)
结果截图:

1 #最好参数训练 2 clf.fit(x_train, y_train) 3 #预测 4 acc = clf.score(x_test, y_test) 5 print("准确率是:", acc) 6 #误差分析 7 y_pred = clf.predict(x_test) 8 mean_squared_error(y_test, y_pred) 9 acc_all.append(acc) 10 mse_all.append(mean_squared_error(y_test, y_pred))
结果截图:

模型测试以及评估
1 g.score(x_test, y_test) 2 y_score = clf.fit(x_train, y_train).decision_function(x_test) 3 fp, tp, threshold = roc_curve(y_test, y_score) 4 roc_auc = auc(fp, tp) 5 6 plt.figure(figsize=(10,4)) 7 plt.plot(fp, tp, color='darkorange', 8 lw=2, label='ROC curve (area = %0.2f)' % roc_auc) 9 plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') 10 plt.xlim([0.0, 1.0]) 11 plt.ylim([0.0, 1.05]) 12 plt.xlabel('FP') 13 plt.ylabel('TP') 14 plt.title('ROC曲线') 15 plt.legend(loc="best") 16 plt.show()
结果截图:

小总结:可见最好参数是0.01,对应的最好分数是0.78,略高于svm。ROC相比于SVM的也略好一些。
随机森林训练
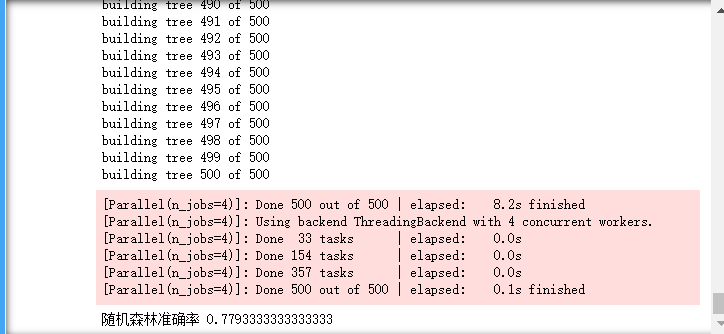
1 clf1 = RandomForestClassifier(n_estimators=500, oob_score=True,verbose=2,n_jobs=4) 2 # g1 = GridSearchCV(clf1, param_grid=[{'n_estimators':[400, 500, 600]}], cv=4) 3 # g1.fit(x_train, y_train) 4 clf1.fit(x_train, y_train) 5 #结果测试 6 acc = clf1.score(x_test, y_test) 7 print("随机森林准确率", acc) 8 # print("最好分数是:", g1.best_score_) 9 # print("最好参数是", g1.best_params_)
500棵树的准确率与运行结果:
绘制水平直方图评估模型好坏
1 z=zip(clf1.feature_importances_, y_test) 2 z=sorted(z,reverse=True)[:5] 3 x=[i[1] for i in z] 4 width=[i[0] for i in z] 5 6 plt.figure(figsize=(5, 2)) 7 plt.barh(x, width) 8 plt.show()
结果截图:

误差分析
1 #误差分析 2 y_pred = clf1.predict(x_test) 3 mean_squared_error(y_test, y_pred) 4 acc_all.append(acc) 5 mse_all.append(mean_squared_error(y_test, y_pred))
结果截图:

换用300棵树进行训练
1 #300棵树进行训练 2 clf1 = RandomForestClassifier(n_estimators=300, oob_score=True, verbose=2, n_jobs=4) 3 clf1.fit(x_train, y_train) 4 #结果测试, 5 acc = clf1.score(x_test, y_test) 6 print("随机森林准确率", acc)
结果截图:

(500参数稍微比300好一些,单影响也不是很大)
绘制水平直方图评估模型
1 z=zip(clf1.feature_importances_, y_test) 2 z=sorted(z,reverse=True)[:5] 3 x=[i[1] for i in z] 4 width=[i[0] for i in z] 5 6 plt.figure(figsize=(5, 2)) 7 plt.barh(x, width) 8 plt.show()
结果截图:

误差分析:
1 #误差分析 2 y_pred = clf1.predict(x_test) 3 mean_squared_error(y_test, y_pred)
结果截图:

小总结:对于随机森林,主要的参数是树木的多少,因为数据集比较大,交叉验证很花时间。所以,用两次来比较随机森林参数。显然500科树要略好于300颗。
Kmeans 训练以及准确率分析
Kmean聚类
1 k = KMeans(2) 2 k.fit(x_train0, y_train0) 3 #预测,计算准确率 4 y_pred0 = k.predict(x_test0) 5 acc0 = (y_pred0 == y_test0).sum() / len(y_pred0) 6 s = k.score(x_test0, y_test0) 7 print("k近邻分数:", s) 8 print("k近邻准确率:", acc0)
结果截图:

1 #误差分析 2 print(mean_squared_error(y_test, y_pred0)) 3 4 acc_all.append(acc0) 5 mse_all.append(mean_squared_error(y_test, y_pred0))
结果截图:

对其进行标准化
1 #标准化后 2 k = KMeans(2) 3 k.fit(x_train, y_train) 4 #预测,计算准确率 5 y_pred0 = k.predict(x_test) 6 acc0 = (y_pred0 == y_test).sum() / len(y_pred0) 7 s = k.score(x_test, y_test) 8 print("k近邻分数:", s) 9 print("k近邻准确率:", acc0)
结果截图:

1 #误差分析 2 print(mean_squared_error(y_test, y_pred0)) 3 4 acc_all.append(acc0) 5 mse_all.append(mean_squared_error(y_test, y_pred0))
结果截图:

小总结:x标准化后准确率明显降低。说明了标准化对kmeans的影响是负向的。因为kmeans点越近越近越不利于区分。
最后我们做一个小测试,如果能在二维把数据分开那分类效果自然很好
将数据降到二维观察分析
1 pca1 = PCA(n_components=2) 2 d = pca1.fit_transform(X) 3 4 plt.figure(figsize=(10,4)) 5 plt.scatter(d[:, 0], d[:, 1], c=data.iloc[:, 23]) 6 plt.show()
结果截图:

明显数据集聚集在一起难以分离,所有此方法不行。
最后:各个模型的结果比较
1 #绘制实际值 2 def autolable(rects): 3 for r in rects: 4 h = r.get_height() 5 plt.text(r.get_x()+r.get_width()/2., 0.98*h, '%s'% float(int(h*1000)/1000))
1 plt.figure(figsize=(8, 3)) 2 x = [ "Standard-SVM", "SVM", "Logistics", "RF-500", "RF-300", "Kmeans", "Standard-Kmeans"] 3 rects = plt.bar(x, acc_all) 4 plt.title("accuracy of model") 5 autolable(rects) 6 plt.show()
结果截图:

1 plt.figure(figsize=(8, 3)) 2 3 x = [ "Standard-SVM", "SVM", "Logistics", "RF-500", "RF-300", "Kmeans", "Standard-Kmeans"] 4 rects = plt.bar(x, mse_all) 5 plt.title("MSE of model") 6 autolable(rects) 7 plt.show()

课题总结:
本人的几个观点:
1.一般模型内部参数对结果影响比较小,一般在0.01%的影响。
2.svm和logistics在标准化后能优化结果,kmeans标准化后结果反而不好。以上三种都受标准化影响。反观随机森林通过对每一个点进行分类无论标准化与否,影响都不是很大。3.PCA降维能使得高维数据降低,提升训练速度,并且得到较好的结果。
本人的收获:
1.学习了几个新的机器学习模型,丰富了知识面。在动手查阅资料的时候,也了解了几个学习的网站。
2.针对本次的课题研究:数据预处理对模型的影响非常大,所有以后数据特征处理一定要多加研究,以及处理对某个模型的影响是好是坏,都是很重要的。其次调参,因为调参影响不会太大变化,但也能稍微提高效果。
改进的建议:
在即将上交课题研究的时候,发现本人在编写的时候存在许多格式的不规范,对于数据的处理也是马马虎虎,导致后面的模型训练遇到很多问题。
附上完整代码
1 #导入相关的库 2 import numpy as np 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 from sklearn.linear_model import LogisticRegression 6 from sklearn.model_selection import GridSearchCV 7 from sklearn.model_selection import train_test_split 8 from sklearn.metrics import f1_score, auc, roc_curve 9 from sklearn.svm import LinearSVC 10 from sklearn.ensemble import RandomForestClassifier 11 from sklearn.cluster import KMeans 12 from sklearn.preprocessing import StandardScaler 13 from sklearn.metrics import mean_absolute_error 14 from sklearn.metrics import mean_squared_error 15 from sklearn.ensemble import RandomForestRegressor 16 import joblib 17 from tqdm import tqdm 18 19 20 #读取文件以及数据分析 21 22 head = 1 23 index = "ID" 24 data = pd.read_excel("D:/default of credit card clients.xls", header=head, index_col=index) 25 #查看前两行数据 26 data.head(5) 27 #可见数据有20多个特征,特征值分为0,1 28 print(data.shape) 29 data = data.dropna() 30 print(data.shape) 31 data.describe() 32 #可见没有缺失值 33 34 35 #数据预处理 36 37 #上面测试过,并未有缺失值,所有不做处理 38 #设置两个列表用于最终结果绘图 39 acc_all = [] 40 mse_all = [] 41 #标签值与特征分开 42 X = data.iloc[:, 0:23] 43 Y = data.iloc[:, 23] 44 #数据特征较多,所有进行降维处理,并且不断调参以后发现10会得到较好结果 45 #pca降维 46 from sklearn.decomposition import PCA 47 pca = PCA(n_components=10) 48 X0 = pca.fit_transform(X) 49 50 #数据标准化 51 S = StandardScaler() 52 S.fit(X0) 53 X = S.transform(X0) 54 55 56 #数据集分割 57 58 x_train, x_test, y_train, y_test = train_test_split(X, Y, 59 train_size=0.8, random_state=999) 60 print(x_train.shape, y_train.shape) 61 #对于kmeans不需要标准化的效果更好所所以给出一份数据用于kmeans 62 x_train0, x_test0, y_train0, y_test0 = train_test_split(X0, Y, 63 train_size=0.8, random_state=999) 64 65 66 #SVM模型训练 67 68 svm = LinearSVC() 69 svm.fit(x_train, y_train) 70 #训练未标准化数据 71 svm0 = LinearSVC() 72 svm0.fit(x_train0, y_train0) 73 74 75 #模型测试以及评估 76 77 #测试集预测准确率 78 print("标准化svm的准确率", svm.score(x_test, y_test)) 79 y_pred = svm.predict(x_test) 80 81 print("未标准化svm的准确率", svm0.score(x_test0, y_test0)) 82 y_pred0 = svm0.predict(x_test0) 83 84 acc_all.append(svm.score(x_test, y_test)) 85 acc_all.append(svm0.score(x_test0, y_test0)) 86 #误差分析 87 print(mean_squared_error(y_test, y_pred)) 88 mse_all.append(mean_squared_error(y_test, y_pred)) 89 print(mean_squared_error(y_test, y_pred0)) 90 mse_all.append(mean_squared_error(y_test, y_pred0)) 91 #绘制ROC曲线 92 y_score = svm.fit(x_train, y_train).decision_function(x_test) 93 fp, tp, threshold = roc_curve(y_test, y_score) 94 roc_auc = auc(fp, tp) 95 96 plt.figure(figsize=(10,4)) 97 plt.plot(fp, tp, color='darkorange', 98 lw=2, label='ROC curve (area = %0.2f)' % roc_auc) 99 plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') 100 plt.xlim([0.0, 1.0]) 101 plt.ylim([0.0, 1.05]) 102 plt.xlabel('FP') 103 plt.ylabel('TP') 104 plt.title('ROC曲线') 105 plt.legend(loc="best") 106 plt.show() 107 108 109 #逻辑回归 110 111 clf = LogisticRegression(C=0.01) 112 g = GridSearchCV(clf, param_grid=[{'C':[0.01, 0.1, 1, 10]}], cv=4) 113 g.fit(x_train, y_train) 114 print("最好分数是:", g.best_score_) 115 print("最好参数是", g.best_params_) 116 117 #用最好参数训练 118 clf.fit(x_train, y_train) 119 #预测 120 acc = clf.score(x_test, y_test) 121 print("准确率是:", acc) 122 #误差分析 123 y_pred = clf.predict(x_test) 124 mean_squared_error(y_test, y_pred) 125 acc_all.append(acc) 126 mse_all.append(mean_squared_error(y_test, y_pred)) 127 128 #模型测试以及评估 129 g.score(x_test, y_test) 130 y_score = clf.fit(x_train, y_train).decision_function(x_test) 131 fp, tp, threshold = roc_curve(y_test, y_score) 132 roc_auc = auc(fp, tp) 133 134 plt.figure(figsize=(10,4)) 135 plt.plot(fp, tp, color='darkorange', 136 lw=2, label='ROC curve (area = %0.2f)' % roc_auc) 137 plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') 138 plt.xlim([0.0, 1.0]) 139 plt.ylim([0.0, 1.05]) 140 plt.xlabel('FP') 141 plt.ylabel('TP') 142 plt.title('ROC曲线') 143 plt.legend(loc="best") 144 plt.show() 145 146 147 #随机森林 148 149 clf1 = RandomForestClassifier(n_estimators=500, oob_score=True,verbose=2,n_jobs=4) 150 # g1 = GridSearchCV(clf1, param_grid=[{'n_estimators':[400, 500, 600]}], cv=4) 151 # g1.fit(x_train, y_train) 152 clf1.fit(x_train, y_train) 153 #结果测试 154 acc = clf1.score(x_test, y_test) 155 print("随机森林准确率", acc) 156 # print("最好分数是:", g1.best_score_) 157 # print("最好参数是", g1.best_params_) 158 159 z=zip(clf1.feature_importances_, y_test) 160 z=sorted(z,reverse=True)[:5] 161 x=[i[1] for i in z] 162 width=[i[0] for i in z] 163 164 plt.figure(figsize=(5, 2)) 165 plt.barh(x, width) 166 plt.show() 167 168 #误差分析 169 y_pred = clf1.predict(x_test) 170 mean_squared_error(y_test, y_pred) 171 acc_all.append(acc) 172 mse_all.append(mean_squared_error(y_test, y_pred)) 173 174 175 #300棵树在进行训练 176 clf1 = RandomForestClassifier(n_estimators=300, oob_score=True, verbose=2, n_jobs=4) 177 clf1.fit(x_train, y_train) 178 #结果测试, 179 acc = clf1.score(x_test, y_test) 180 print("随机森林准确率", acc) 181 #500参数稍微比300好一些,单影响也不是很大 182 183 z=zip(clf1.feature_importances_, y_test) 184 z=sorted(z,reverse=True)[:5] 185 x=[i[1] for i in z] 186 width=[i[0] for i in z] 187 188 plt.figure(figsize=(5, 2)) 189 plt.barh(x, width) 190 plt.show() 191 192 #误差分析 193 y_pred = clf1.predict(x_test) 194 mean_squared_error(y_test, y_pred) 195 acc_all.append(acc) 196 mse_all.append(mean_squared_error(y_test, y_pred)) 197 198 199 #Kmean聚类模型 200 201 k = KMeans(2) 202 k.fit(x_train0, y_train0) 203 #预测,计算准确率 204 y_pred0 = k.predict(x_test0) 205 acc0 = (y_pred0 == y_test0).sum() / len(y_pred0) 206 s = k.score(x_test0, y_test0) 207 print("k近邻分数:", s) 208 print("k近邻准确率:", acc0) 209 210 #误差分析 211 print(mean_squared_error(y_test, y_pred0)) 212 213 acc_all.append(acc0) 214 mse_all.append(mean_squared_error(y_test, y_pred0)) 215 216 #标准化后 217 k = KMeans(2) 218 k.fit(x_train, y_train) 219 #预测,计算准确率 220 y_pred0 = k.predict(x_test) 221 acc0 = (y_pred0 == y_test).sum() / len(y_pred0) 222 s = k.score(x_test, y_test) 223 print("k近邻分数:", s) 224 print("k近邻准确率:", acc0) 225 226 #误差分析 227 print(mean_squared_error(y_test, y_pred0)) 228 #标准化后误差更大了 229 230 acc_all.append(acc0) 231 mse_all.append(mean_squared_error(y_test, y_pred0)) 232 233 234 #将数据降到二维观察分析 235 236 pca1 = PCA(n_components=2) 237 d = pca1.fit_transform(X) 238 239 plt.figure(figsize=(10,4)) 240 plt.scatter(d[:, 0], d[:, 1], c=data.iloc[:, 23]) 241 plt.show() 242 243 #绘制实际值 244 def autolable(rects): 245 for r in rects: 246 h = r.get_height() 247 plt.text(r.get_x()+r.get_width()/2., 0.98*h, '%s'% float(int(h*1000)/1000)) 248 249 plt.figure(figsize=(8, 3)) 250 x = [ "Standard-SVM", "SVM", "Logistics", "RF-500", "RF-300", "Kmeans", "Standard-Kmeans"] 251 rects = plt.bar(x, acc_all) 252 plt.title("accuracy of model") 253 autolable(rects) 254 plt.show() 255 256 plt.figure(figsize=(8, 3)) 257 258 x = [ "Standard-SVM", "SVM", "Logistics", "RF-500", "RF-300", "Kmeans", "Standard-Kmeans"] 259 rects = plt.bar(x, mse_all) 260 plt.title("MSE of model") 261 autolable(rects) 262 plt.show()

