Python常用基础知识整理
一、Python转义字符
\a :响铃(BEL)
\b : 退格(BS) ,将当前位置移到前一列
\f :换页(FF),将当前位置移到下页开头
\n :换行(LF) ,将当前位置移到下一行开头
\r :回车(CR) ,将当前位置移到本行开头
\t :水平制表(HT) (跳到下一个TAB位置)
\v :垂直制表(VT)
\\ :代表一个反斜线字符\
\' :代表一个单引号(撇号)字符
\" :代表一个双引号字符
\? :代表一个问号
\0 :空字符(NULL)
\ddd :3位八进制数所代表的任意字符
\xhh :2位十六进制所代表的任意字符
二、Python字符串格式化符号
1、百分号%方式
%c:格式化字符及其ASCII码
%s:格式化字符串
%d:格式化整数
%u:格式化无符号整型
%o:格式化无符号八进制数
%x:格式化无符号十六进制数
%X:格式化无符号十六进制数(大写)
%f:格式化浮点数字,可指定小数点后的精度
%e:用科学计数法格式化浮点数
%E:作用同%e,用科学计数法格式化浮点数
%p:用十六进制数格式化变量的地址
例子:


%r 与 %s 区别:
%r 用来做 debug 比较好,因为它会显示变量的原始数据(raw data),而其它的符号则是用来向用户显示输出的。

格式化部分用单引号输出
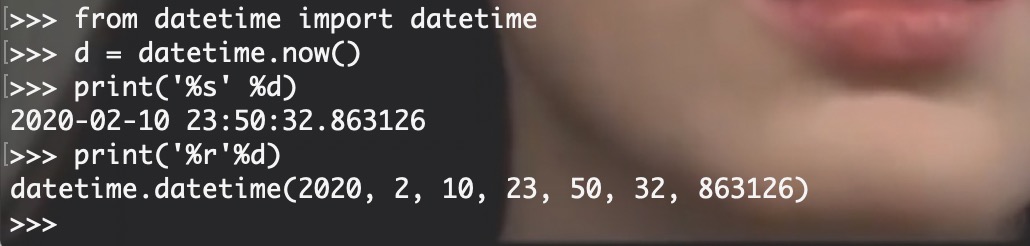
可以看见与上面输出存在明显的区别
2、format方式

三、Python正则表达式
1、正则匹配的基本语法
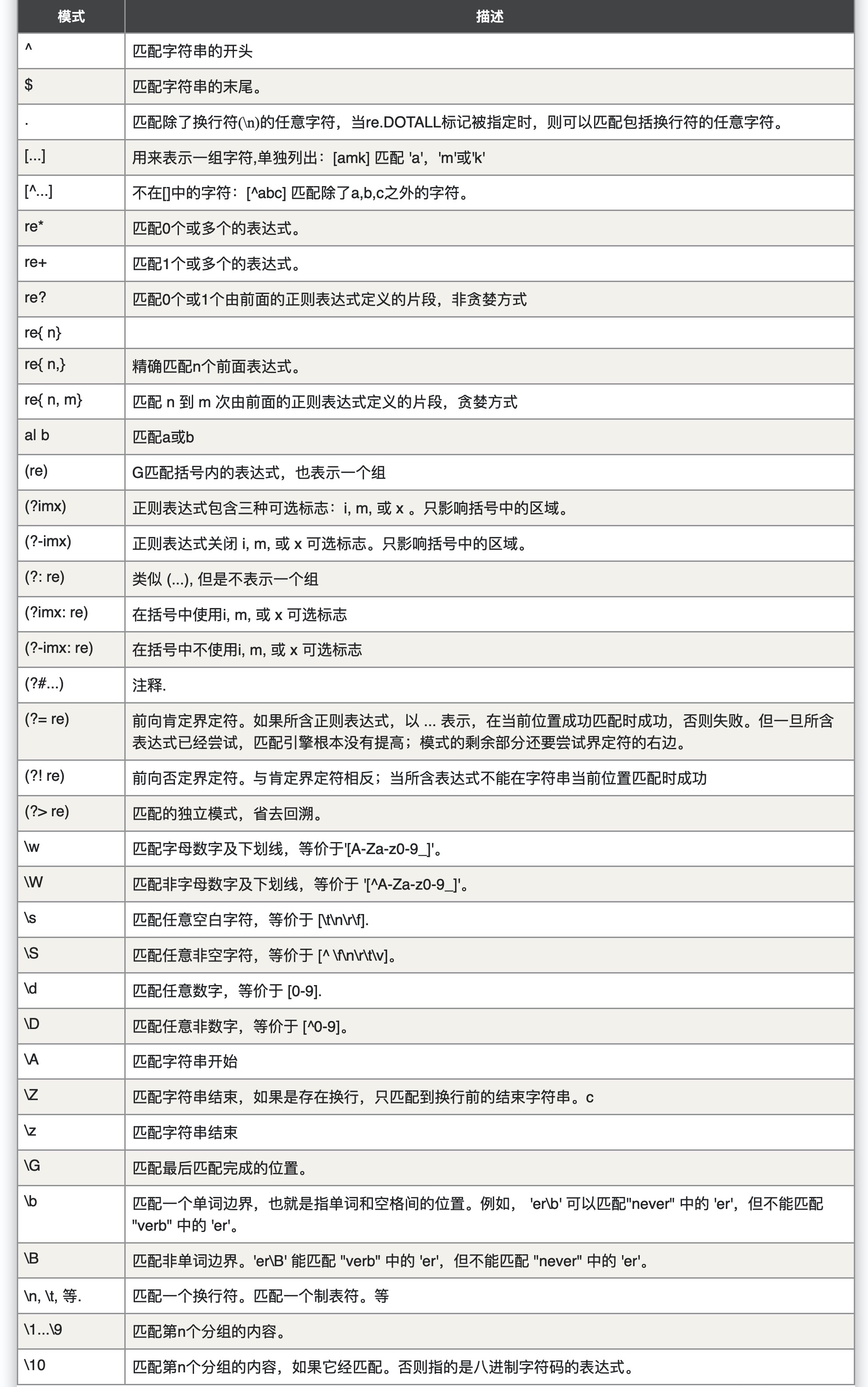
正则表达式的通配符表示含义:
模式字符串使用特殊的语法来表示一个正则表达式:
- 字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
- 多数字母和数字前加一个反斜杠时会拥有不同的含义。
- 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
- 反斜杠本身需要使用反斜杠转义。
- 由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 '\t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
2、re模块
Python中re模块使用正则表达式的两种方法
- 使用re.compile(r, f)方法生成正则表达式对象,然后调用正则表达式对象的相应方法。这种做法的好处是生成正则对象之后可以多次使用。
- re模块中对正则表达式对象的每个对象方法都有一个对应的模块方法,唯一不同的是传入的第一个参数是正则表达式字符串。此种方法适合于只使用一次的正则表达式。
以下是re模块常用的七个函数:
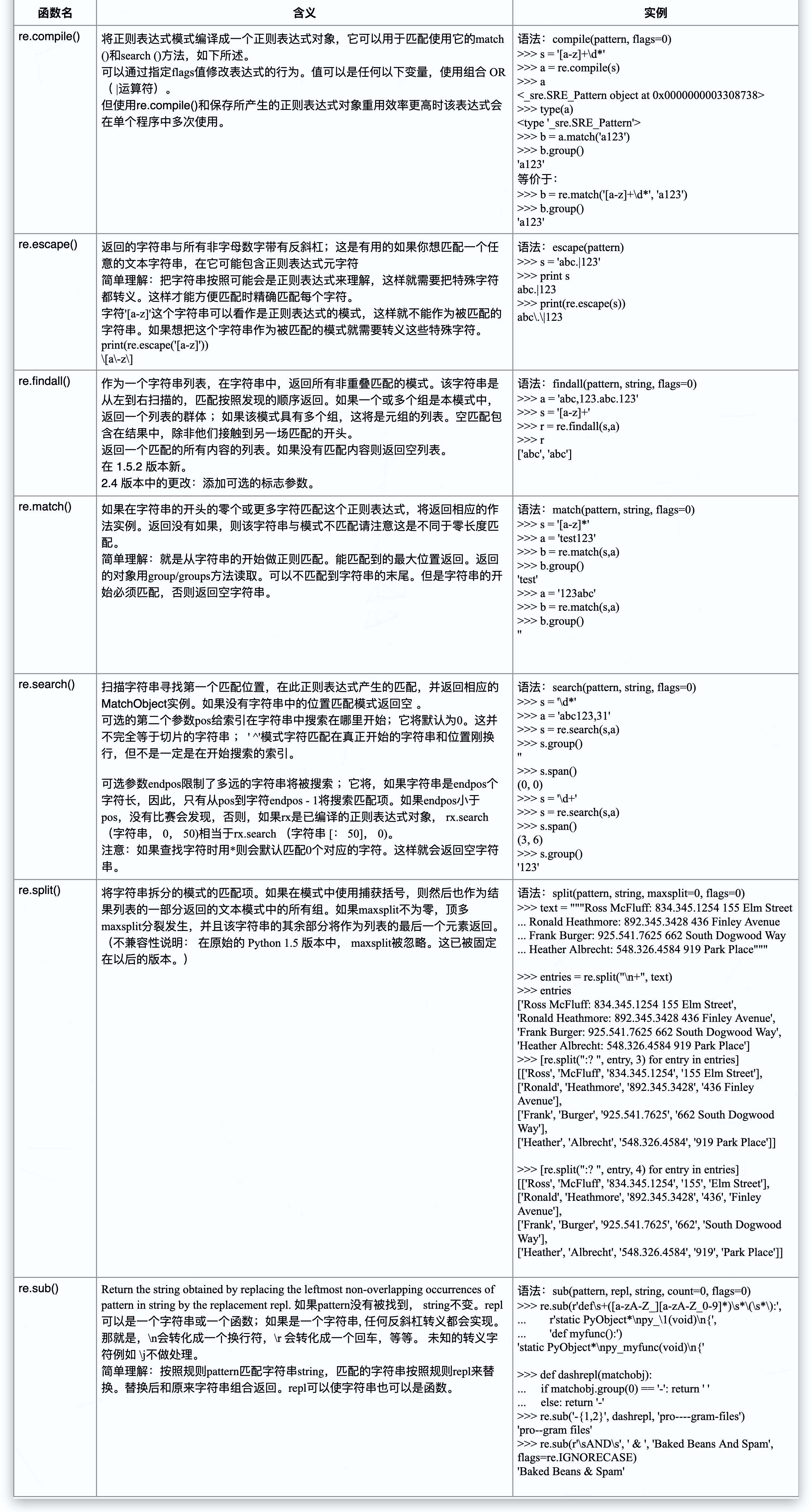
注意事项:match、fullmatch、findall、finditer、search区别
match:是根据传入的正则表达式匹配对应的字符串。并且是从开始字符匹配。匹配到字符不能匹配的位置然后返回匹配的对象。返回的对象是MatchObject或者空。
fullmatch和match的区别是fullmatch必须是目标字符串从开始到结束全部都匹配这个传入的正则表达式才可以返回匹配对象。否则返回空。返回的对象也是MatchObject对象。
findall:从字符串中从前向后依次查找匹配正则表达式的子串。最后把多个匹配的子串用列表形式返回。列表的每个元素是一个匹配的子串。
finditer和findall功能相同。但是finditer返回的是一个可迭代对象。可以用next()方法读取。然后再用group方法读取匹配的内容。
search:是从前向后依次扫描整个字符串。返回第一个匹配的子串。匹配位置不一定是开始字符。但是如果用*来表示0-n次重复时需要测试。有时候会返回空字符串。
search、match返回对象是MatchObject或者是None。findall返回对象是列表。列表每个元素都是一个可以匹配的一段子串。
3、总结
- 对于正则表达式的匹配功能,Python没有返回true和false的方法,但可以通过对match或者search方法的返回值是否是None来判断
- 对于正则表达式的搜索功能,如果只搜索一次可以使用search或者match方法返回的匹配对象得到,对于搜索多次可以使用finditer方法返回的可迭代对象来迭代访问
- 对于正则表达式的替换功能,可以使用正则表达式对象的sub或者subn方法来实现,也可以通过re模块方法sub或者subn来实现,区别在于模块的sub方法的替换文本可以使用一个函数来生成
- 对于正则表达式的分割功能,可以使用正则表达式对象的split方法,需要注意如果正则表达式对象有分组的话,分组捕获的内容也会放到返回的列表中
参考链接:
https://docs.python.org/zh-cn/3/howto/regex.html
https://docs.python.org/zh-cn/3/library/re.html
四、Python文件操作
文件方法
1、open() 方法
完整语法:
open(file,mode='r',buffering=-1,encoding=None,errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener:
文件打开模式mode参数如下:
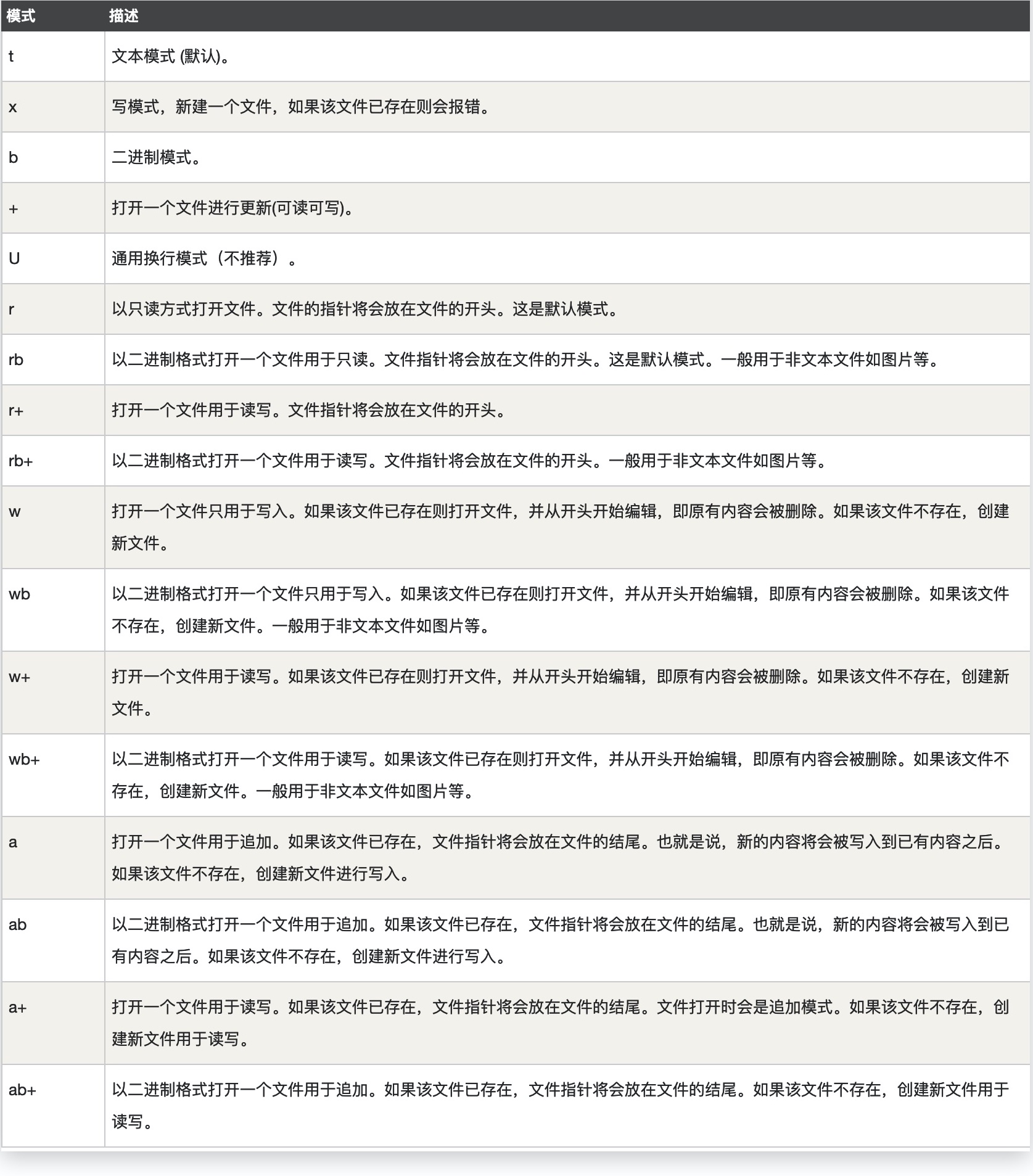
思考:r+、w+和a+都可以实现对文件的读写,那他们有什么区别呢?
r+会覆盖当前文件指针所在位置的字符,如原来文件内容是"Hello,World",打开文件后写入"hi"则文件内容会变成"hillo, World"
w+与r+的不同是,w+在打开文件时就会先将文件内容清空,不知道它有什么用
a+与r+的不同是,a+只能写到文件末尾(无论当前文件指针在哪里)
最低内存消耗的文件读取操作:

发现上面的输出结果中行与行之间多了一个空行。这是因为文件每一行的默认都有换行符,而print()方法也会输出换行,因此就多了一个空行。去掉空行也比较简单:可以用line.strip()去除字符串右边的换行符,也可以通过print(line, end='')避免print方法造成的换行。
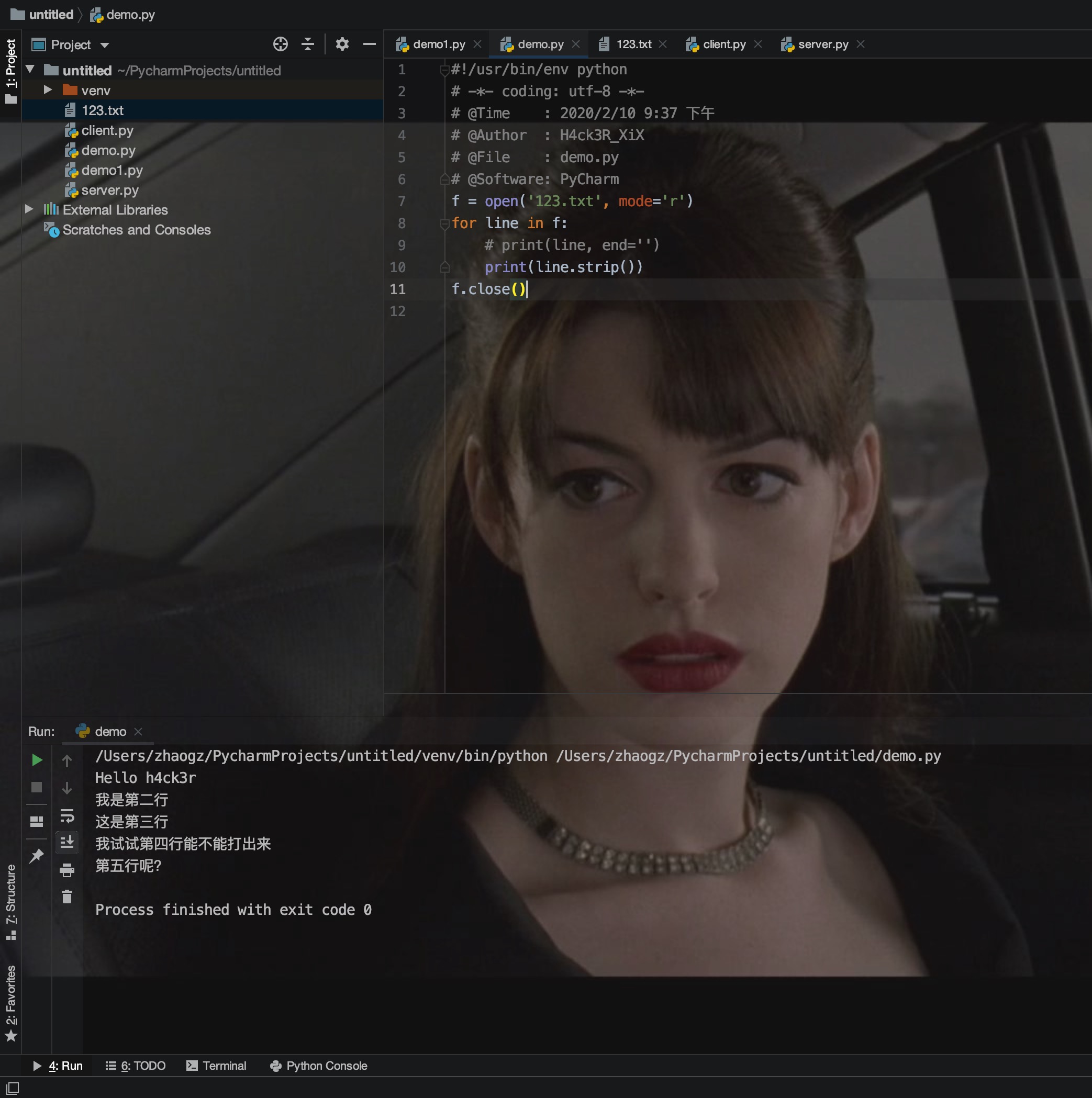
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
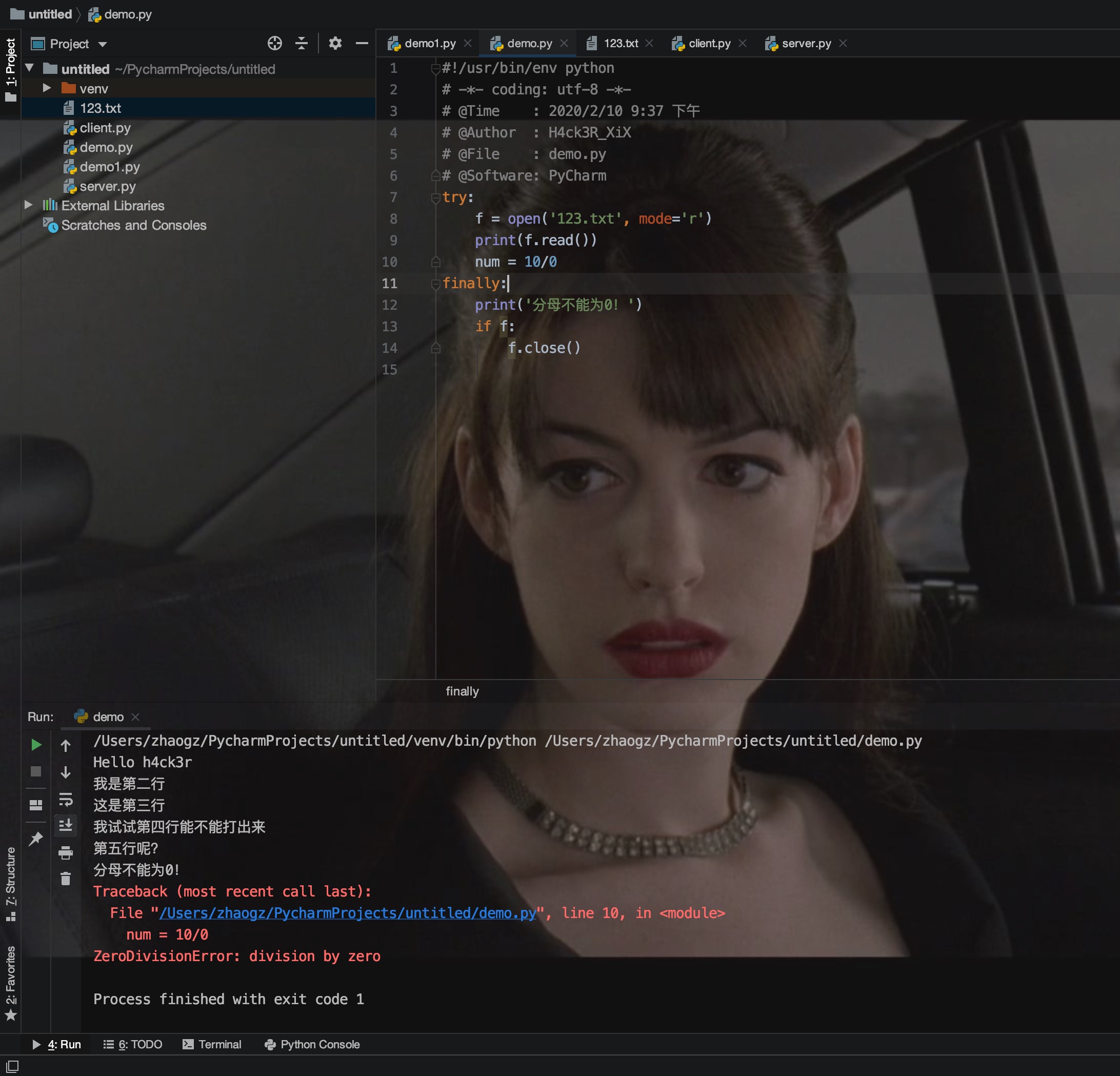
输出结果说明,尽管try代码块中出现了异常,但是”分母不能为0!“ 信息还是被打印了,说明finally代码块被执行,即文件关闭操作被执行。但是结果中错误信息还是被输出了,因此还是建议用一个完成的try...except...finally语句对异常信息进行捕获和处理。
每次都这么写实在太繁琐,所以,Python引入了with open as 语句来自动帮我们调用close()方法:
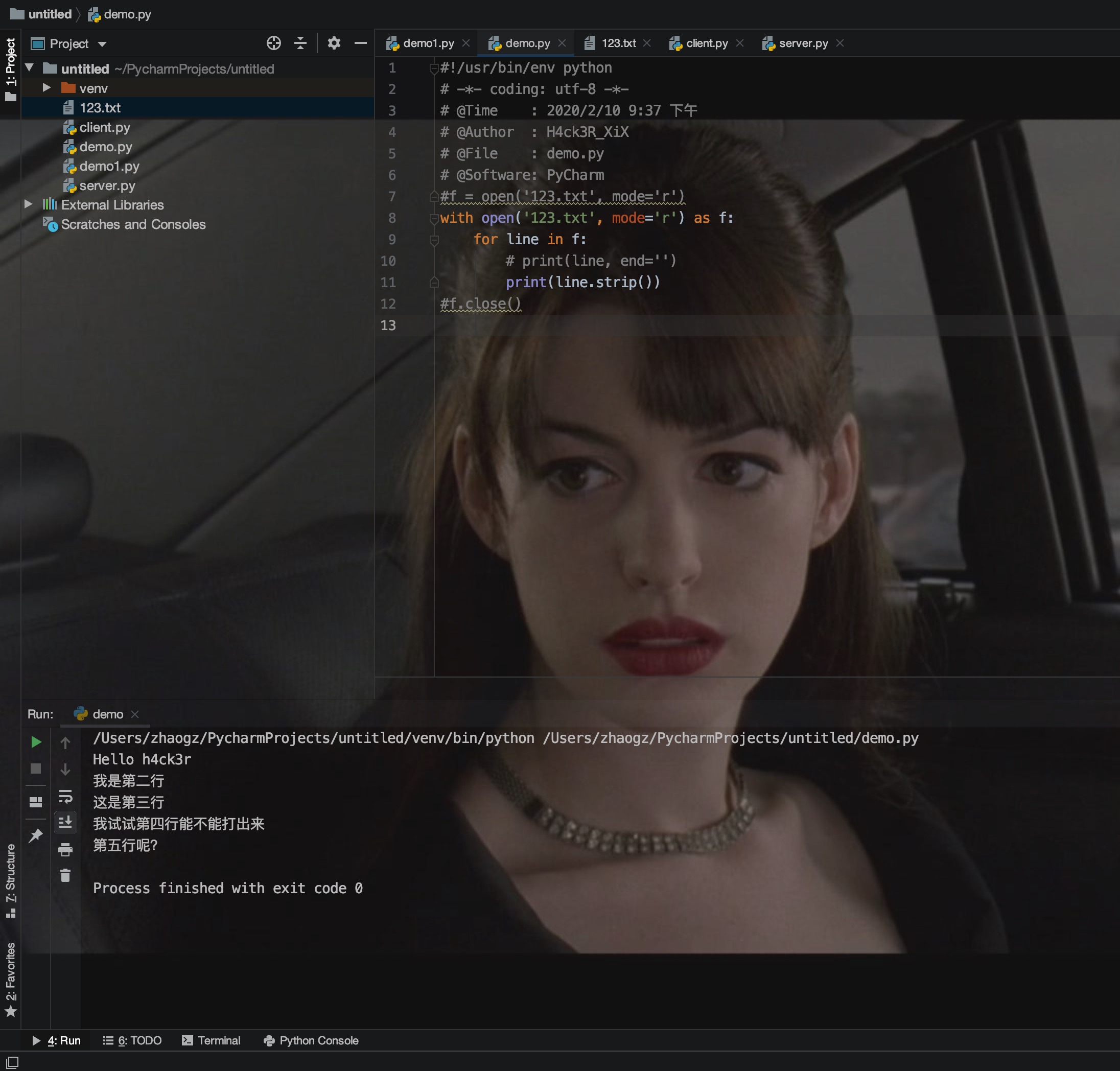
这和前面的try ... finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。
2、文件对象方法函数
文件对象使用 open()函数来创建,下表列出了 file 对象常用的函数:

五、Python异常处理
Python 有两种错误很容易辨认:语法错误和异常。
1、语法错误
Python 的语法错误或者称之为解析错,如下实例:
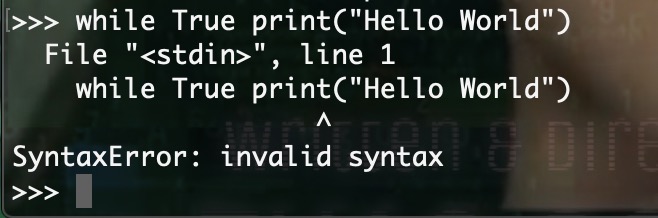
函数 print() 被检查到有错误,是它前面缺少了一个冒号 “:”
语法解析器指出了出错的一行,并且在最先找到的错误的位置标记了一个小小的箭头。
2、异常
即便 Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
大多数的异常都不会被程序处理,都以错误信息的形式展现在这里:

异常以不同的类型出现,这些类型都作为信息的一部分打印出来: 例子中的类型有 ZeroDivisionError,NameError 和 TypeError。
错误信息的前面部分显示了异常发生的上下文,并以调用栈的形式显示具体信息。
1.异常处理
** try/except**
异常捕捉可以使用 try/except语句。
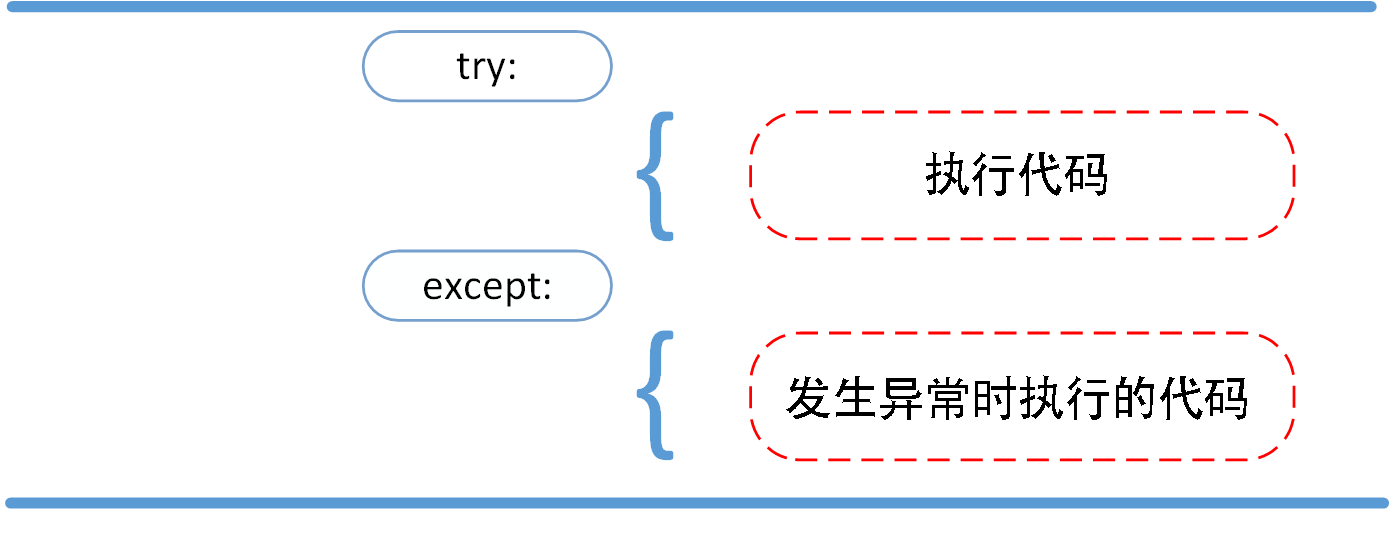
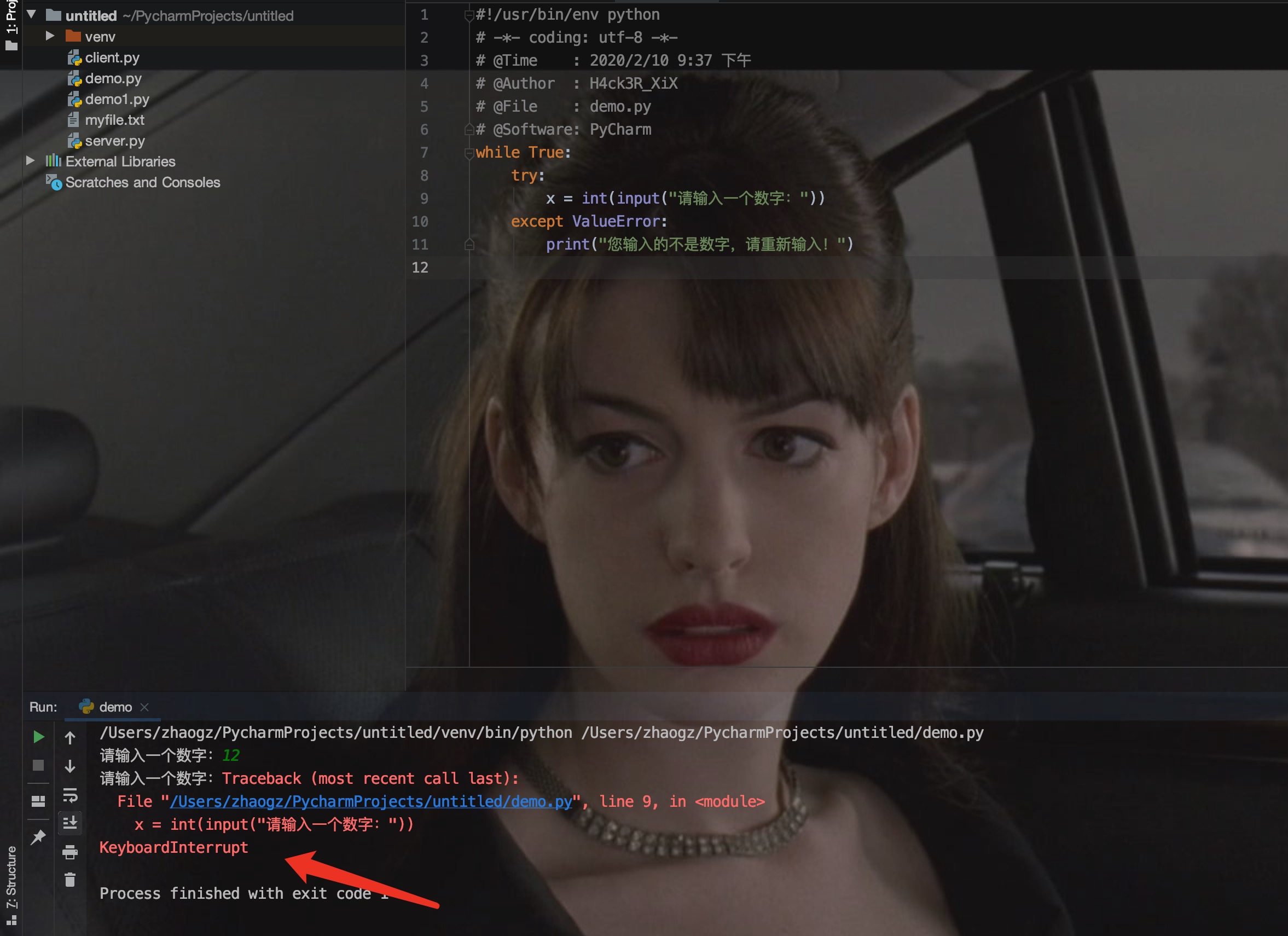
以下例子中,让用户输入一个合法的整数,但是允许用户中断这个程序(使用 Control-C 或者操作系统提供的方法)。用户中断的信息会引发一个 KeyboardInterrupt 异常。
try 语句按照如下方式工作;
首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
如果没有异常发生,忽略 except 子句,try 子句执行后结束。
如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
如果一个异常没有与任何的 excep 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except (RuntimeError, TypeError, NameError):
pass
最后一个except子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
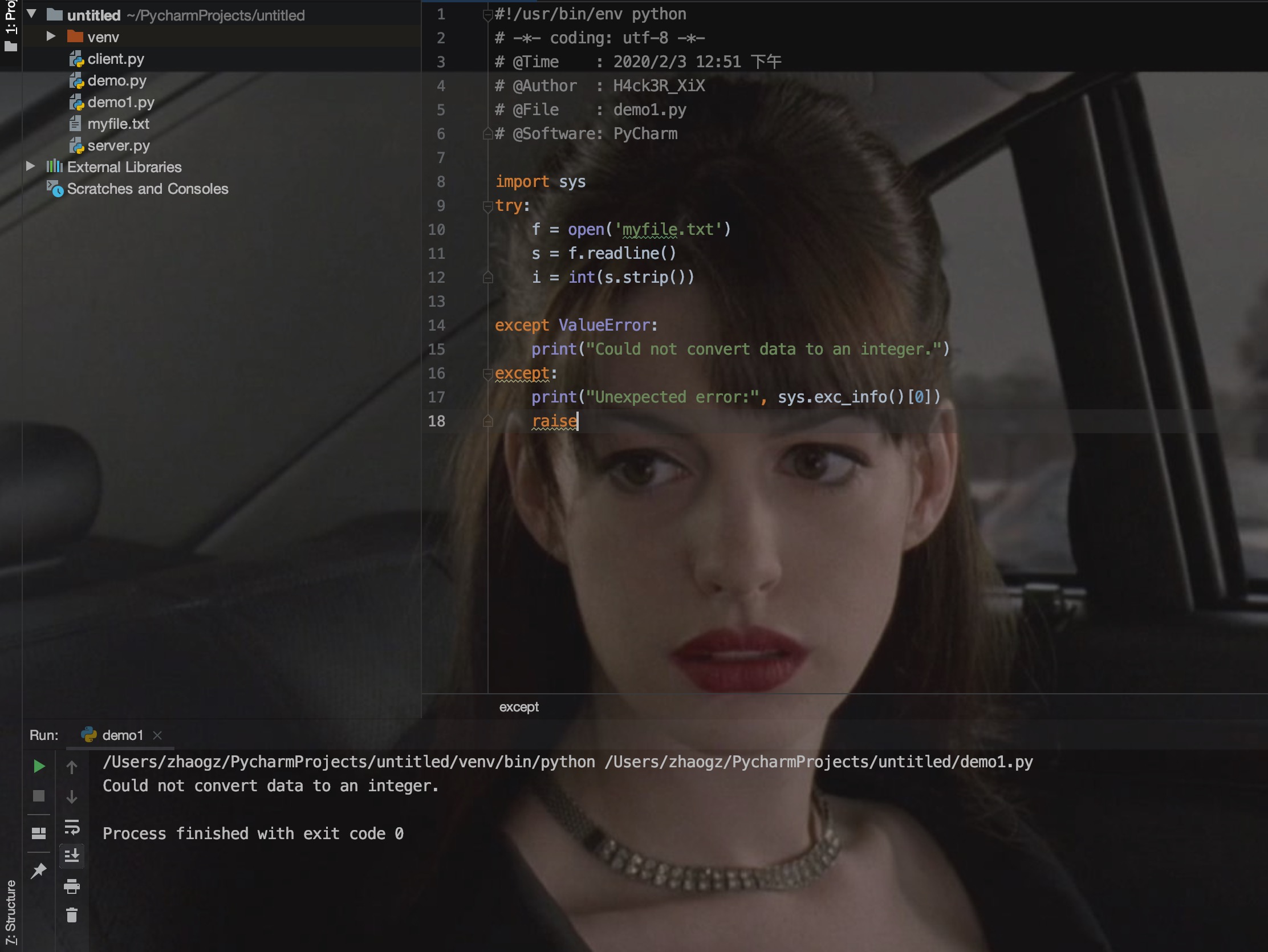
try/except...else
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。
else 子句将在 try 子句没有发生任何异常的时候执行。

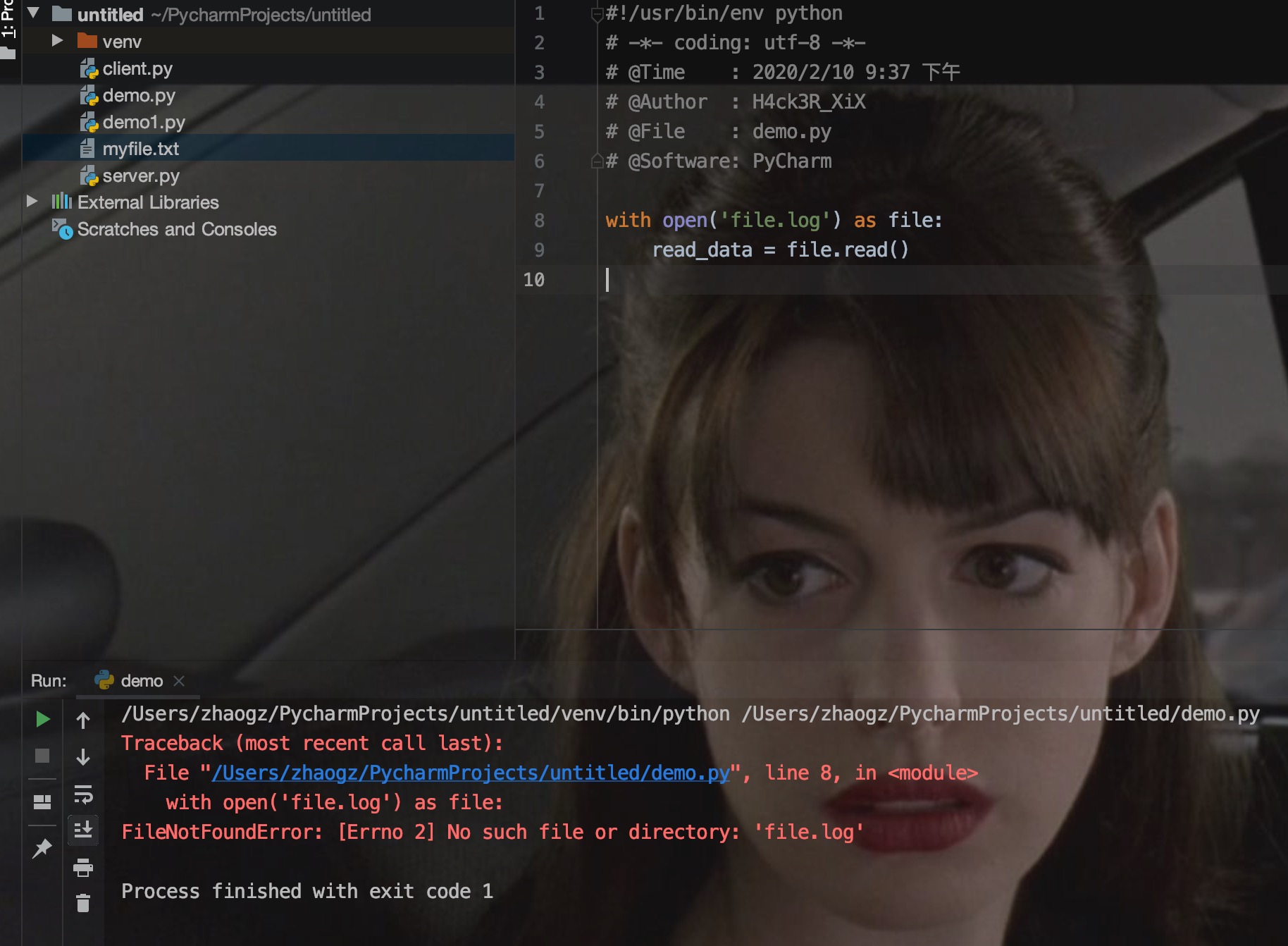
以下实例在 try 语句中判断文件是否可以打开,如果打开文件时正常的没有发生异常则执行 else 部分的语句,读取文件内容:
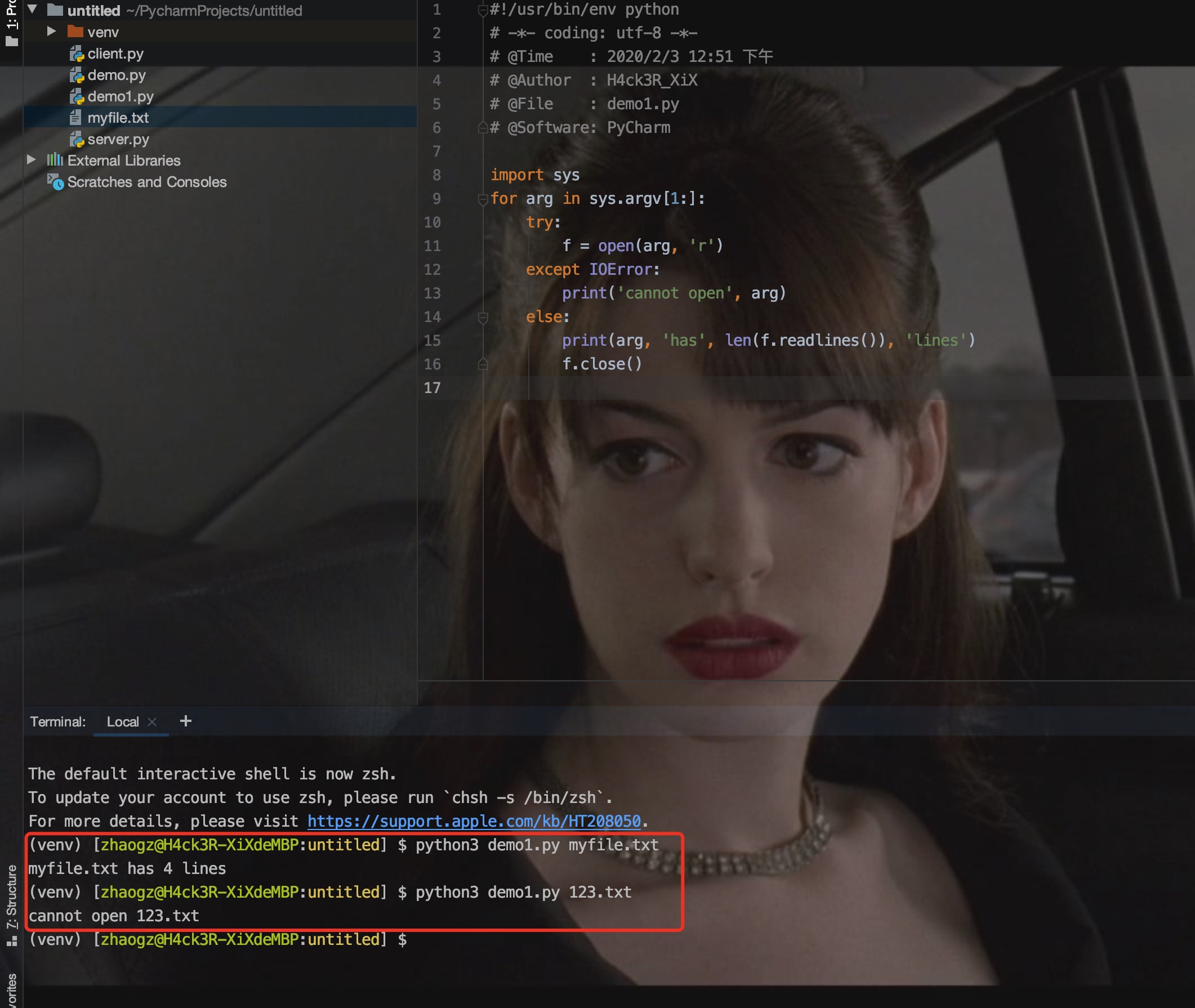
使用 else 子句比把所有的语句都放在 try 子句里面要好,这样可以避免一些意想不到,而 except 又无法捕获的异常。
异常处理并不仅仅处理那些直接发生在 try 子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。例如:

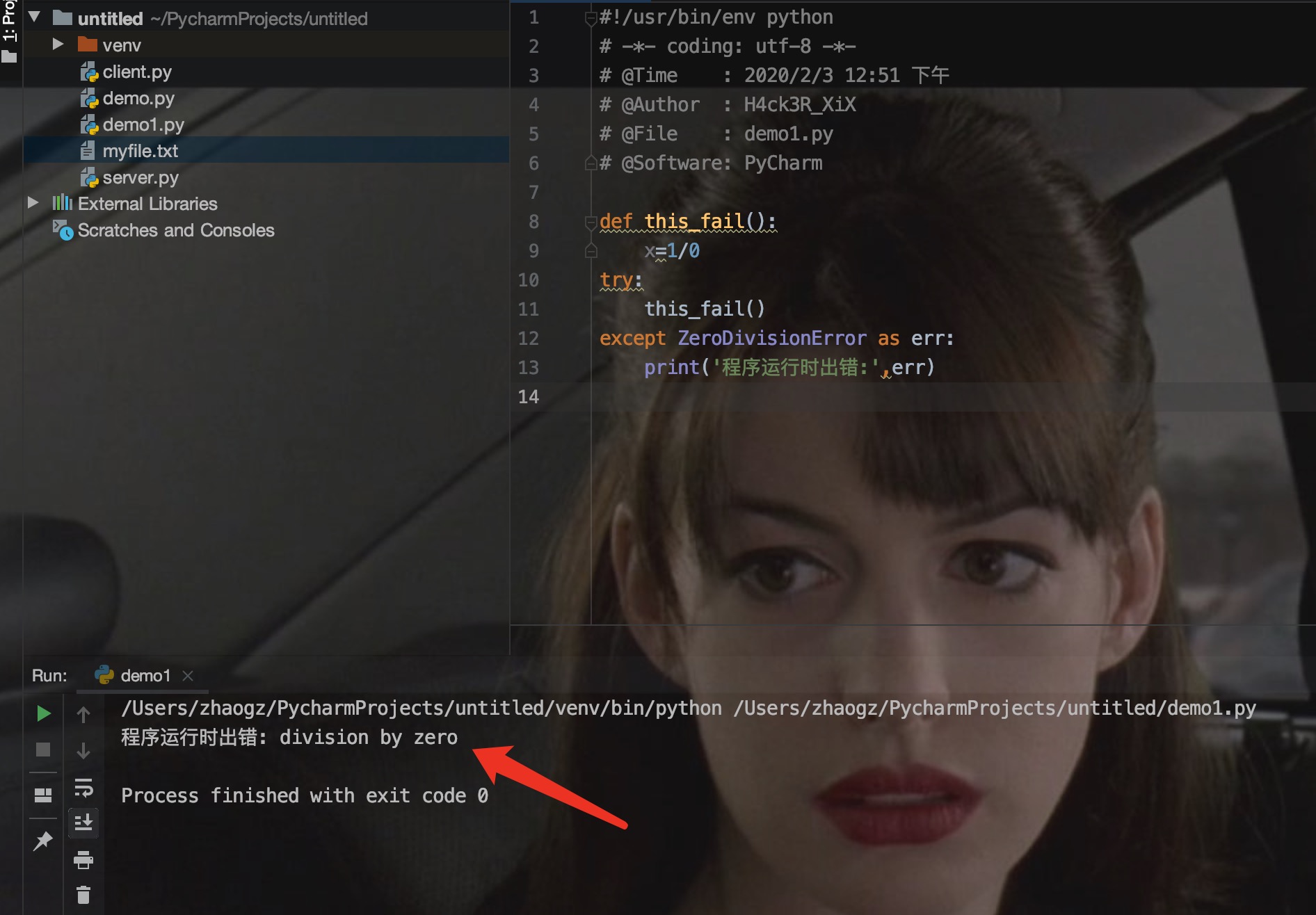
** try-finally 语句**
try-finally 语句无论是否发生异常都将执行最后的代码。

以下实例中 finally 语句无论异常是否发生都会执行:
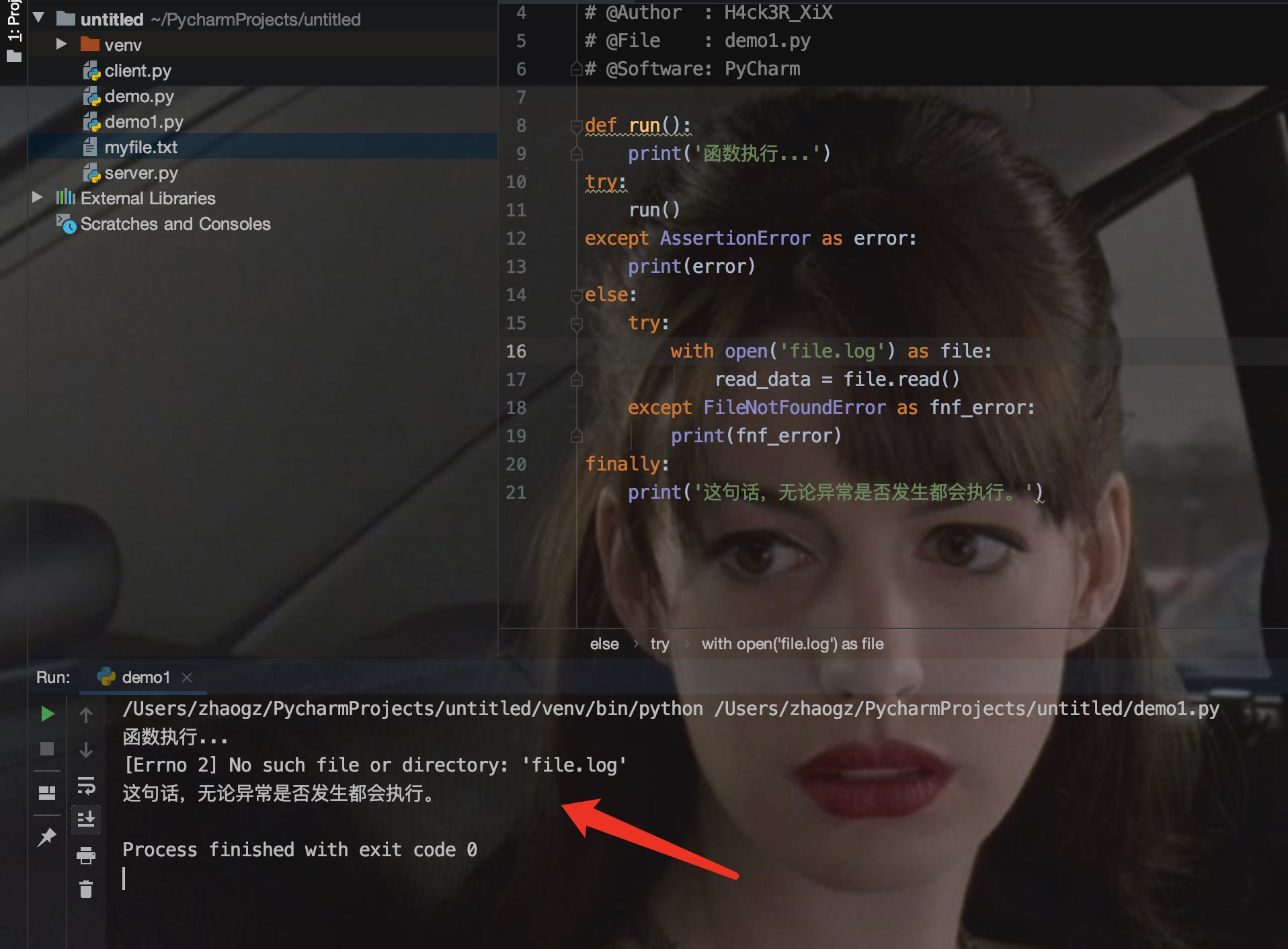
2.抛出异常
Python 使用 raise 语句抛出一个指定的异常,raise语法格式如下:
raise [Exception [, args [, traceback]]]
例:如果 x 大于 5 就触发异常:
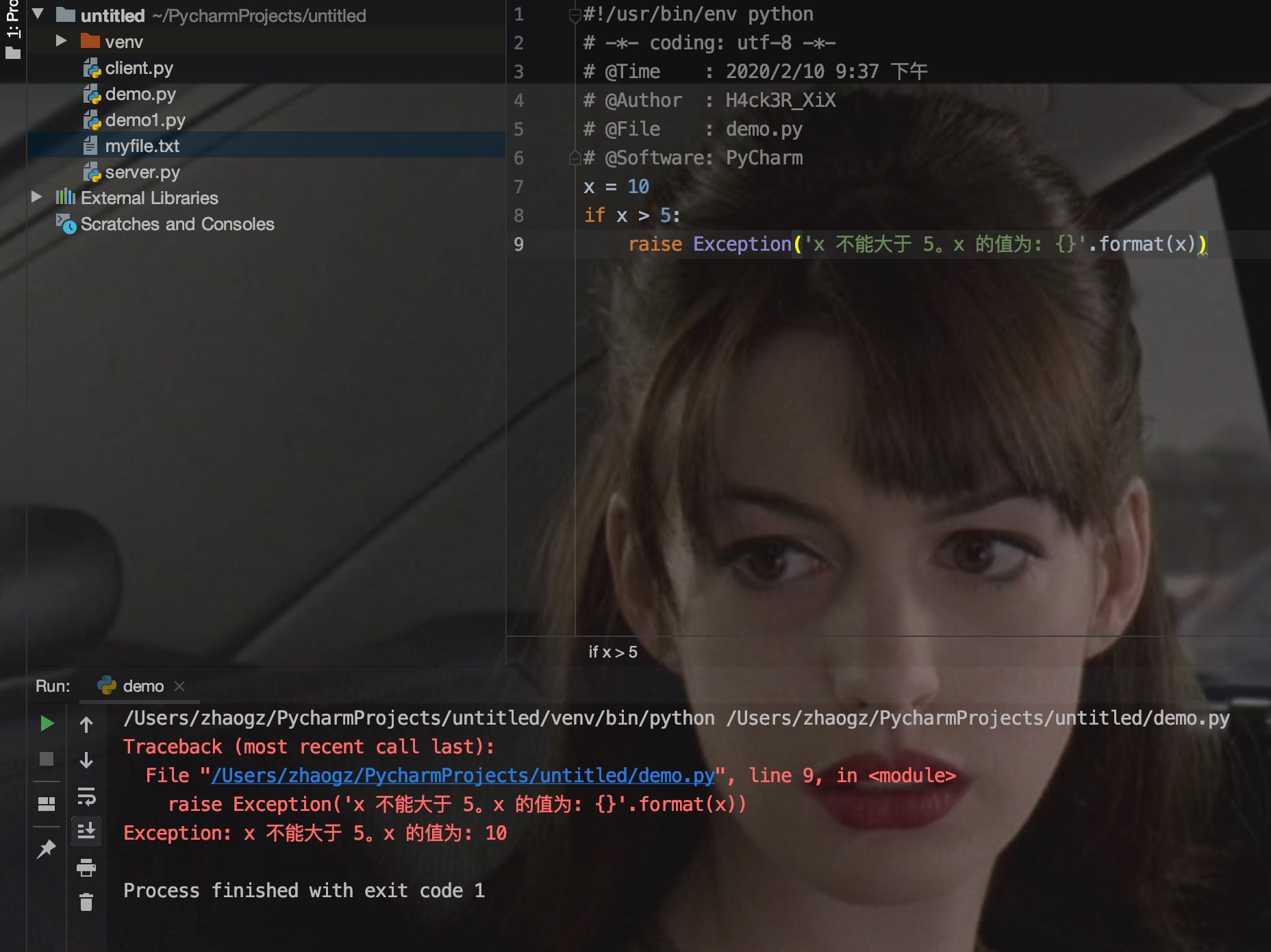
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
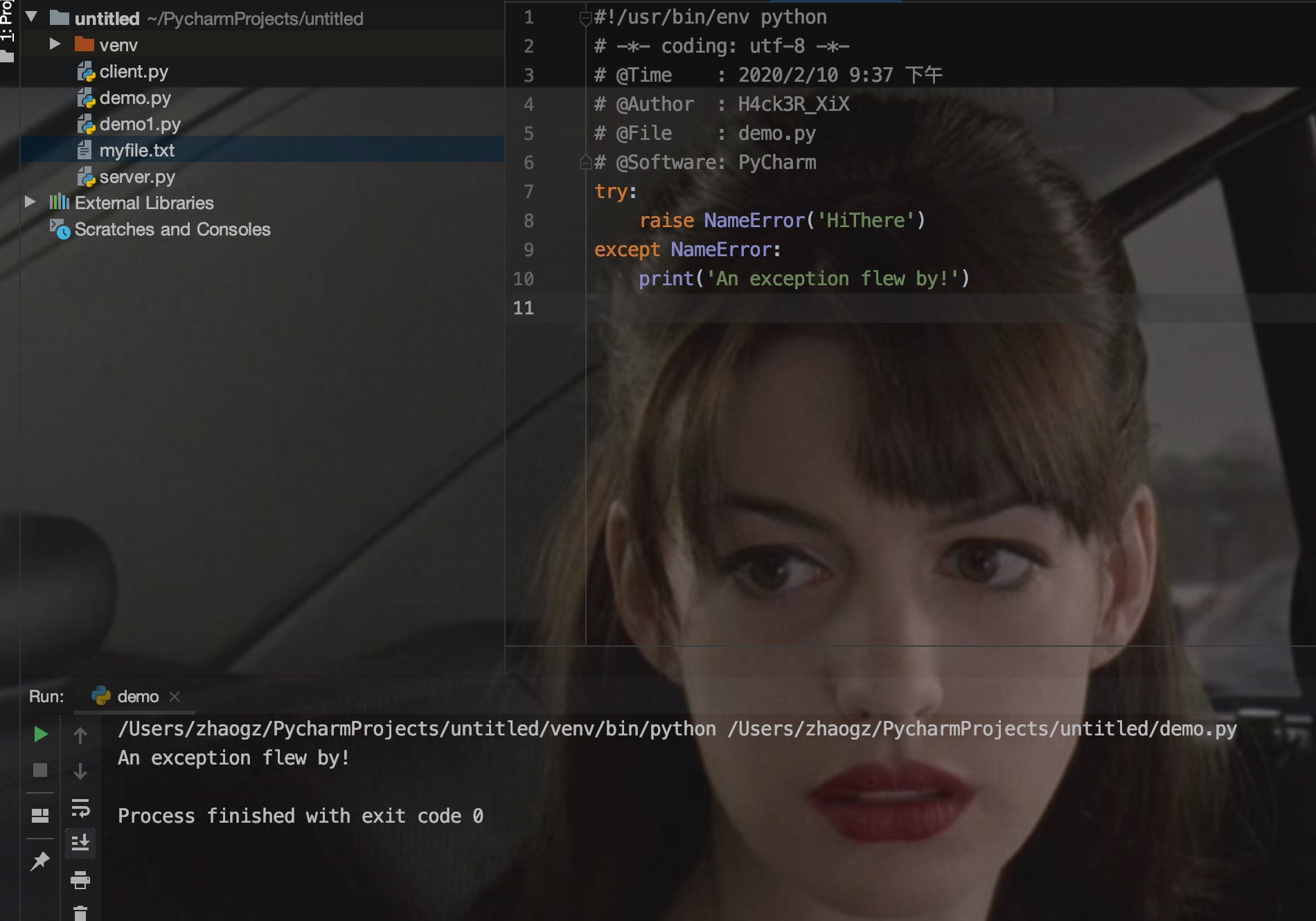
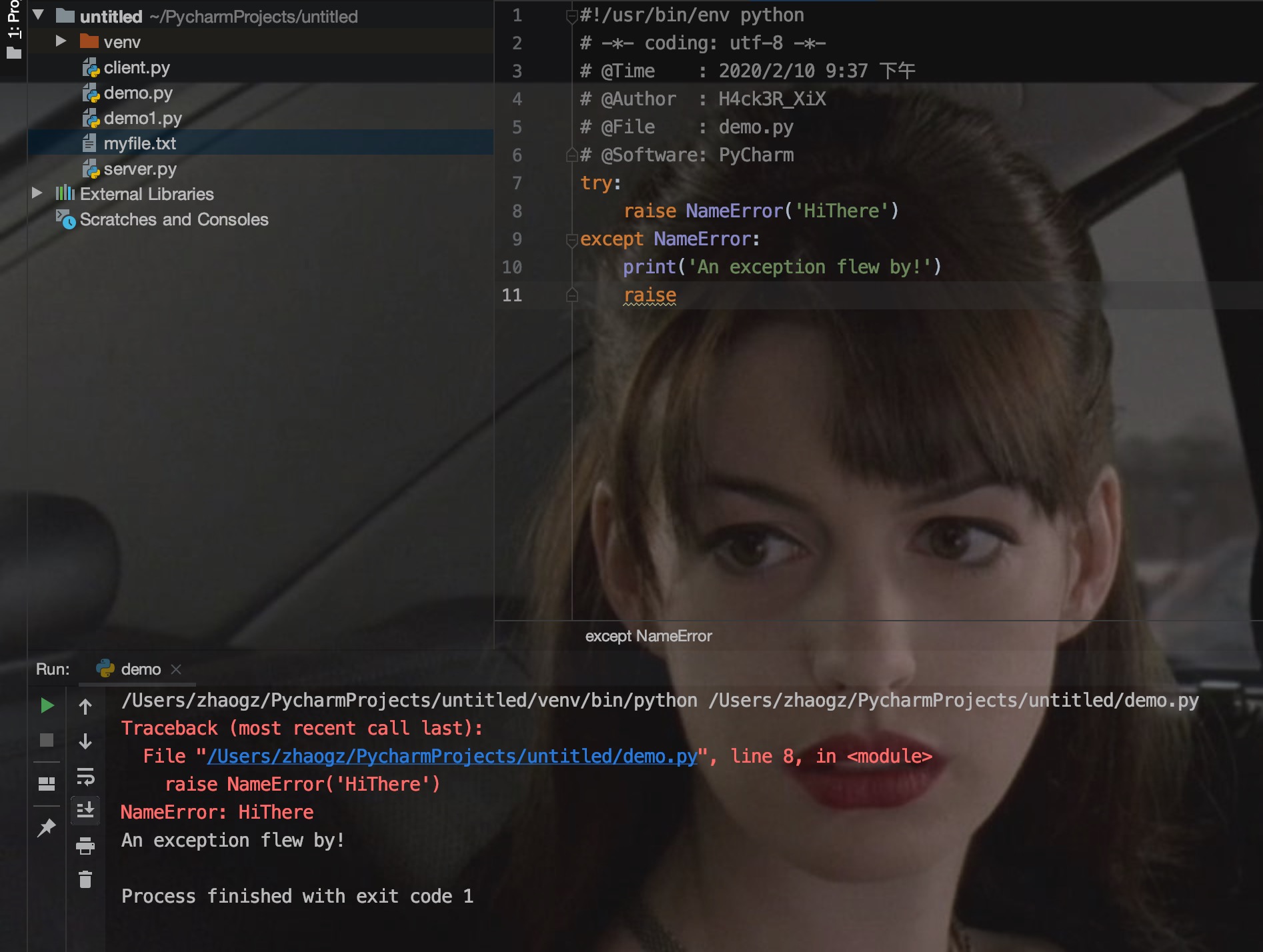
3.用户自定义异常
可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承,例如:
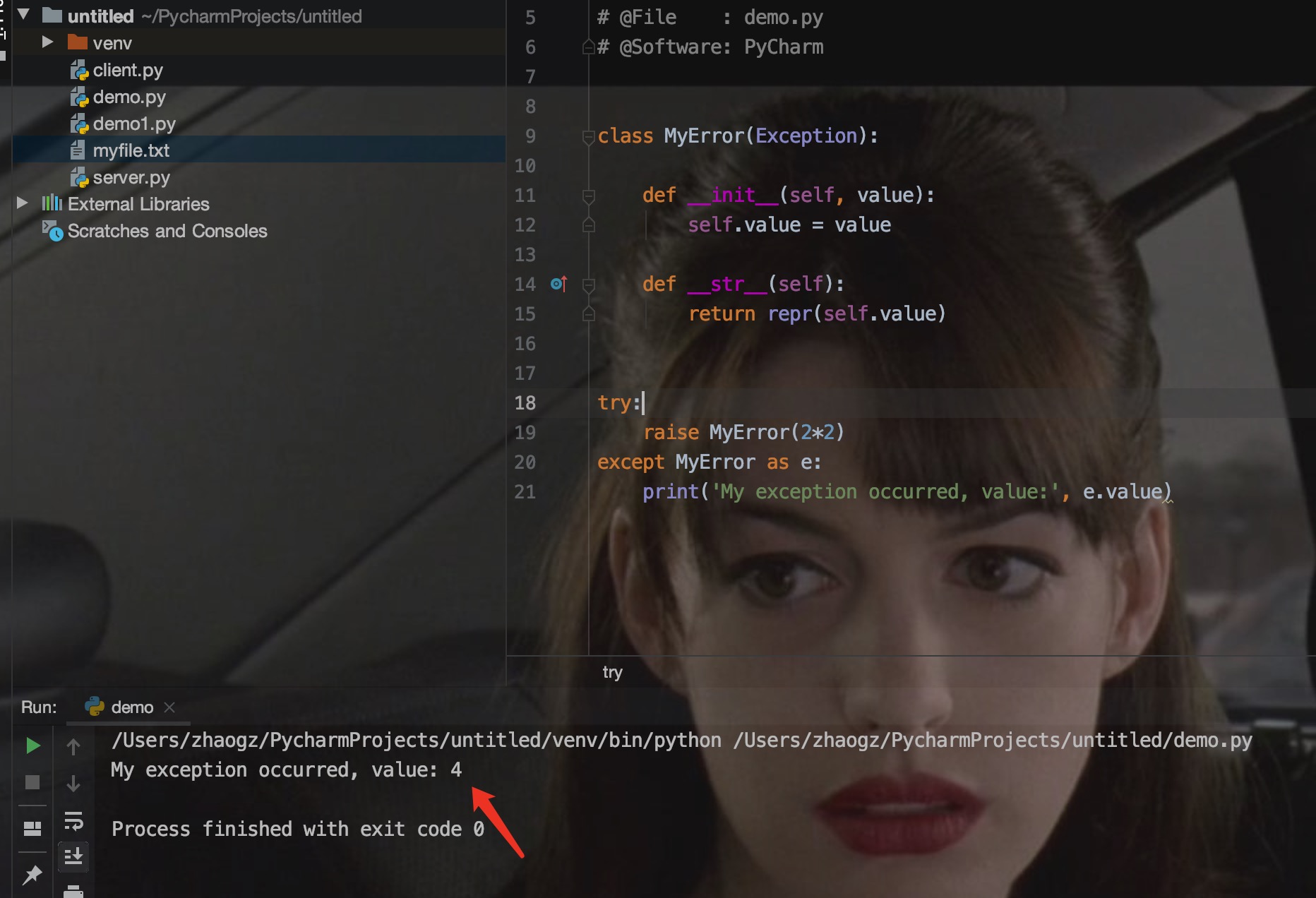
在这个例子中,类 Exception 默认的 init() 被覆盖。
当创建一个模块有可能抛出多种不同的异常时,通常为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
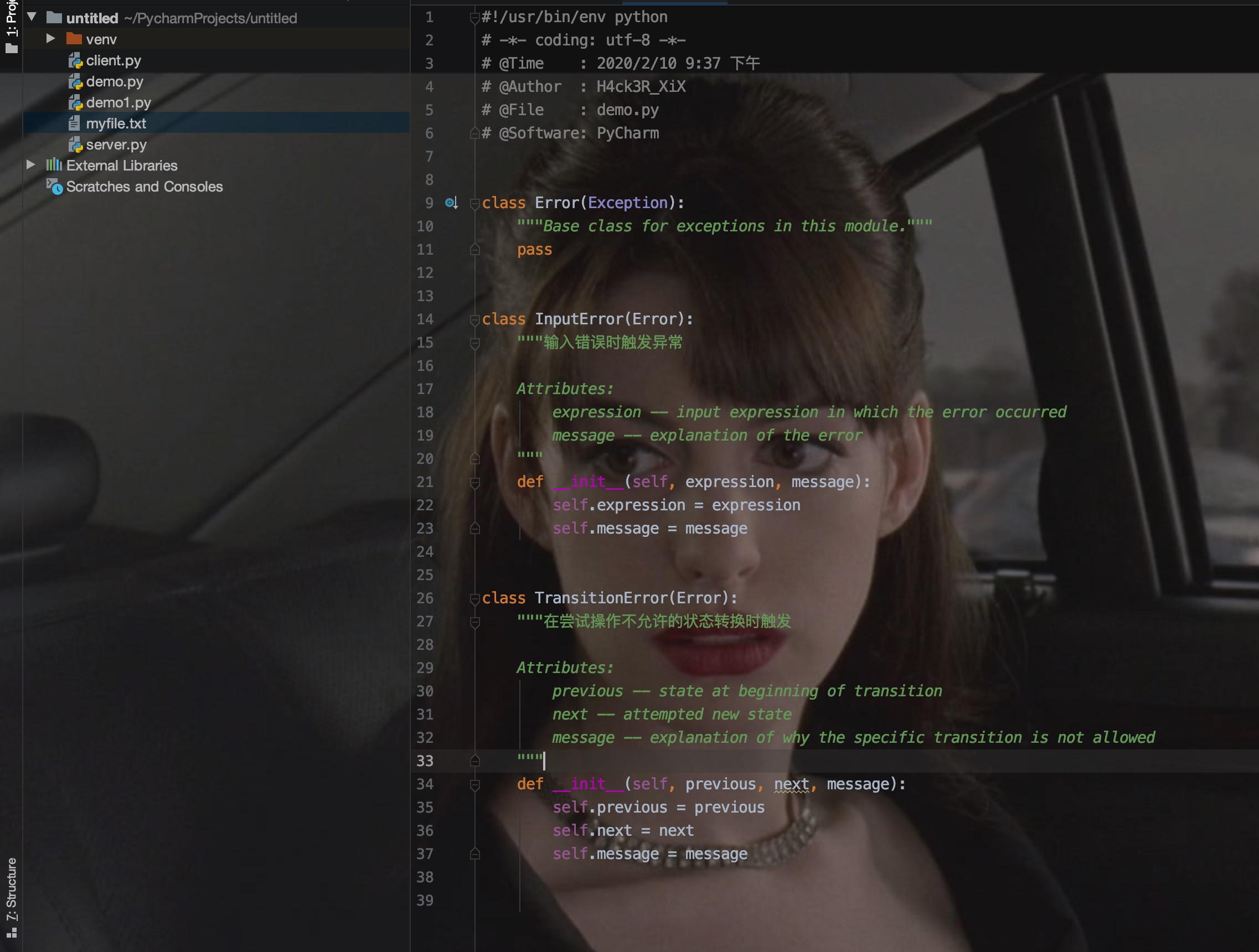
大多数的异常的名字都以"Error"结尾,与标准的异常命名一样。

