
Python爬取全网热点榜单数据
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取全网热点榜单数据
2.主题式网络爬虫爬取的内容与数据特征分析:
1)热门榜单;
2)数据有日期、标题、链接地址等
3.主题式网络爬虫设计方案概述:
1)HTML页面分析得到HTML代码结构;
2)程序实现:
a. 定义代码字典;
b. 用requests抓取网页信息;
c. 用BeautifulSoup库解析网页;
d. 用pandas库保存数据为xls;
e. 定义主函数main();
f. 定义功能函数,解耦;
二、主题页面的结构特征分析
1.主题页面的结构与特征分析(网页地址:https://tophub.today/):
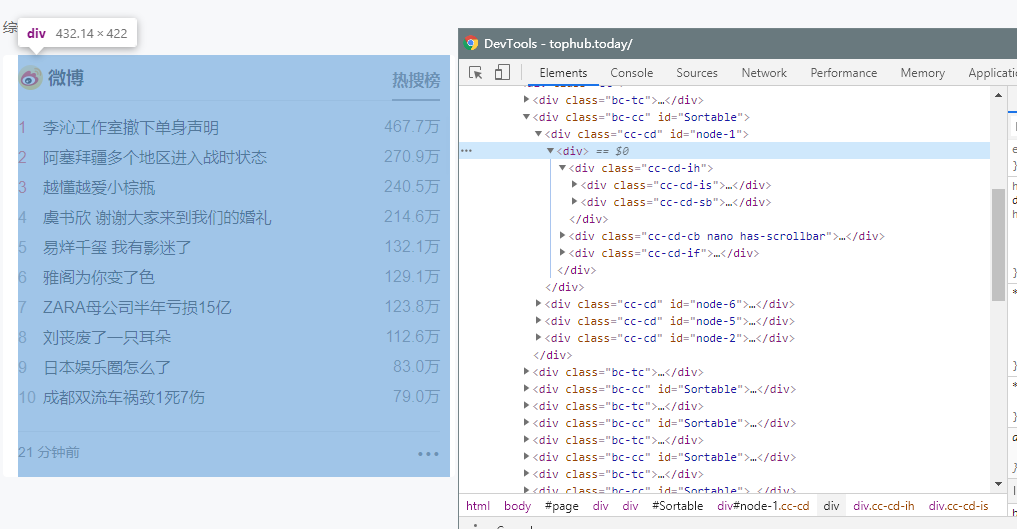
2.Html页面解析
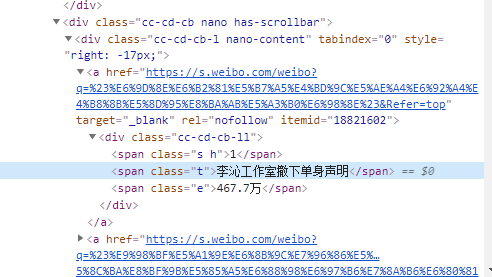
3.节点(标签)查找方法与遍历方法:使用 find_all() 和 find() 方法寻找关键class获取数据
三、网络爬虫程序设计
1.数据爬取与采集
用requests抓取网页信息,设置UA(User-Agent),访问获取网页数据;
部分代码:
import requests
def getHtml(url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/538.55 (KHTML, like Gecko) Chrome/81.0.3345.132 Safari/538.55'}
resp = requests.get(url, headers=headers)
return resp.text
部分运行截图:
2.对数据进行清洗和处理
用BeautifulSoup库解析网页,find_all()方法寻找需要的数据,然后find()方法通过class标签寻找关键数据;
部分代码:
from bs4 import BeautifulSoup
def get_data(html):
soup = BeautifulSoup(html, 'html.parser')
nodes = soup.find_all('div', class_='cc-cd')
return nodes
def get_node_data(df, nodes):
now = int(time.time())
for node in nodes:
source = node.find('div', class_='cc-cd-lb').text.strip()
messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
for message in messages:
content = message.find('span', class_='t').text.strip()
if source == '微信':
reg = '「.+?」(.+)'
content = re.findall(reg, content)[0]
if df.empty or df[df.content == content].empty:
data = {
'content': [content],
'url': [message['href']],
'source': [source],
'start_time': [now],
'end_time': [now]
}
item = pandas.DataFrame(data)
df = pandas.concat([df, item], ignore_index=True)
else:
index = df[df.content == content].index[0]
df.at[index, 'end_time'] = now
return df
部分运行截图:
3.数据持久化
用pandas库保存数据为xls;
部分代码:
import pandas
res = pandas.read_excel('tophub.xlsx')
res = get_node_data(res, data)
res.to_excel('tophub.xlsx')
部分运行截图:

4.将以上各部分的代码汇总,完整代码:
import requests
from bs4 import BeautifulSoup
import time
import pandas
import re
def getHtml(url):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/538.55 (KHTML, like Gecko) Chrome/81.0.3345.132 Safari/538.55'}
resp = requests.get(url, headers=headers)
return resp.text
def get_data(html):
soup = BeautifulSoup(html, 'html.parser')
nodes = soup.find_all('div', class_='cc-cd')
return nodes
def get_node_data(df, nodes):
now = int(time.time())
for node in nodes:
source = node.find('div', class_='cc-cd-lb').text.strip()
messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
for message in messages:
content = message.find('span', class_='t').text.strip()
if source == '微信':
reg = '「.+?」(.+)'
content = re.findall(reg, content)[0]
if df.empty or df[df.content == content].empty:
data = {
'content': [content],
'url': [message['href']],
'source': [source],
'start_time': [now],
'end_time': [now]
}
item = pandas.DataFrame(data)
df = pandas.concat([df, item], ignore_index=True)
else:
index = df[df.content == content].index[0]
df.at[index, 'end_time'] = now
return df
url = 'https://tophub.today'
html = getHtml(url)
data = get_data(html)
res = pandas.read_excel('tophub.xlsx')
res = get_node_data(res, data)
res.to_excel('tophub.xlsx')
四、结论
本次程序设计任务补考,我选择的课题是爬取全网热门榜单聚合数据,并不是每个网站的榜单数据,平时也经常使用这个网站关注全国的热点资讯。对于这个网站的爬取相对简单也比较熟悉,首先它是一个静态网页,其次节点也相当好找,通过class标签就可以轻松找到,而且爬虫部分也不需要特别的伪装,设置好UA信息,伪装成正常访客就可以了。
小结:
1.编码很重要,一开始爬取的数据解析后中文都乱码了,主要是GBK和UTF-8编码转换的问题;
2.养成写代码解耦分部并且检查的习惯,一开始代码一路写下来,全部是一坨,出问题非常难定位到哪里错了。修改分函数后,每个部分每个功能独立出来,不仅代码看起来直观了,出现问题也变少;
3.基础不够,还是需要继续努力;
最后,通过这次的补考,让我对python的应用有了更进一步的提升,受益良多。

