


计数 DP 选刷
CF53E Dead Ends
好题。看到 \(n\leq 10\) 一眼状压或容斥。但是我可能并不会容斥于是考虑状压。
直接把暴力把题目限制作为状态,设 \(f_{S1,S2}\) 为与 \(1\) 连通的集合为 \(S1\),目前 \(deg=1\) 的节点为 \(S2\)(注意 \(S2\) 属于 \(S1\)),注意到 \(S2\) 有后效性但是 \(S1\) 没有后效性所以整体结构无后效性。
每次枚举一条边 \((u,v)\),钦定 \(u\) 在 \(S1\) 中,\(v\) 不在 \(S1\) 中。转移时,把 \(v\) 并入 \(S1\),且若 \(S2\) 中有 \(u\),就把 \(u\) 去除,同时将 \(v\) 并入 \(S2\)。
按理来说这样就做完了。但是其实我们显然会算重,样例一就会挂掉。因为先加 \(2\) 再加 \(3\) 其实和先加 \(3\) 再加 \(2\) 是本质相同的。
于是有一个大 Trick,先描述一下:就是若踢出 \(u\) 加入 \(v\) 之后 \(v\) 不是当前 \(S2\) 集合中编号最大的,就不更新,我不是很会证这个为啥能不重不漏,但是感性理解一下确实是这样的。
注意一下初始化,由于 \(deg_1=0\),所以初始化要初始化与 \(1\) 连边的点才行。
技巧 1:生成树问题状压可以从根开始往外拓展的加点。
技巧 2:可以让编号有序加入集合以保证不重不漏。
技巧 3:如若允许可以将限制暴力作为状态。
P3643 [APIO2016] 划艇
近似是自己推出来的吧。说一下思考的思路。
首先我们可以有一个初步的 dp,就是枚举你选啥,但这个东西显然和值域 \(V\) 是相关的,那完蛋了。
然后比如你随便考虑一下这个东西是区间选点,那么你把区间写出来讨论一下区间相对关系,你会发现不交非常好办,其他的好像不咋好办。但是你可以观察出一个东西,也是比较经典的。你将 \(l,r\) 离散化之后你会发现在一个离散后的区间内的点是基本等价的。
而且离散后的区间将我们的值域 \(V\) 缩减到了 \(1000\) 的量级。考虑把它计入状态。设 \(f_{i,j}\) 为前 \(i\) 个队伍,第 \(i\) 个队伍被派到了第 \(j\) 个离散区间的方案数。
若前面的与其不太同一个离散区间里,显然有转移 \(f_{i,j}=\sum_{k=1}^{j-1} f_{i-1,k}\),同段可能较为困难。
首先你要注意到他是可以不派出划艇的,这非常出生。但是我们先不管他,我们先看看由于你不知道同段的有多少个,这个东西非常棘手,你无法算答案,于是我们先枚举一个 \(t\) 代表你在这一段选了多少个学校。这样会让你的复杂度变为 \(O(n^4)\) 但是我们先不急。
我们的问题可以归约为:给定 \(n\) 个在 \([0,L]\) 中的数,非 \(0\) 数必须单调递增的方案数。
不好处理,我们先枚举一手,设我们选了 \(k\) 个 \(0\),于是其他的方案就是 \(\binom{L}{n-k}\),接下来我们把 \(0\) 的方案乘上去。也较为困难,实质上是把 \(k\) 个 \(0\) 插到 \(n-k+1\) 个空位的方案数,但是你注意到每插入一个都会多出一个空位,于是你就是 \((n-k+1)\times (n-k+2)...\times n\),由于 \(0\) 之间没有区别,于是除以 \(k!\) 即可。你会惊喜的发现这就是 \(\binom{n}{k}\)。
于是接下来我们要算的就是 \(\sum_{k=0}^n \binom{L}{n-k}\times \binom{n}{k}\),注意到这是范德蒙德卷积,等于 \(\binom{L+n}{n}\),推完这个我们就做完了。
剩下的就是常规的前缀和优化 dp 了。
CF1485F Copy or Prefix Sum
艹这个题感觉。比划艇那个题难好多啊,感觉挺难想清楚的。*2400 其实评的差不多。
首先我都会的东西:注意到这个东西很前缀和。记目前我们假想一个 \(a\) 的前缀和为 \(Sum\),那么现在 \(a_i\) 要么是 \(b_i\) 要么是 \(b_i-Sum\)。并且你稍微注意一下答案为什么不是 \(2^n\),观察一下两个转移的形式,若 \(Sum=0\) 你可就完蛋了。
然后 \(f_i\) 代表前 \(i\) 个数,且 \(i\) 位置 \(a_i=b_i\) 的个数,\(g_i\) 表示 \(i\) 位置 \(a_i\neq b_i\) 的 \(a_i=b_i-Sum\) 的个数。
然后是我想不到的,我确实想完状态就不会转移了。我根本不知道 \(Sum\) 是啥东西。
然后有一个非常重要的观察:\(a\) 的前缀和等价于 \(b\) 的一段区间和,这不难理解,因为 \(b\) 要么是 \(a\) 的单点,要么是 \(a\) 的前缀和。
于是我们有 \(f_i=f_{i-1}+g_{i-1}\),因为我钦定 \(a_i=b_i\) 和前面选啥没关系。有 \(g_i=\sum_{j=1}^{i-1} [Sumb_{i-1}\neq Sumb_{j-1}]g_j\)。
关于 \(g\) 的转移有如下两点问题:
- 首先 \(b\) 的区间和一定和 \(a\) 的前缀和构成双射吗?我一度有这个疑问,但是其实题解可能并不是这个意思。他貌似是钦定了中间一段选 \(a_i=b_i\),最前面那个选的是前缀。
- 其次为什么 \(g\) 不能从 \(f\) 转移。还是刚才那个解释,我们钦定了 \(j\) 位置选的是前缀。于是肯定没有 \(f\) 什么事儿了。
然后 map 维护一下转移就行了。时间复杂度 \(O(n\log n)\)
[ABC134F] Permutation Oddness
哇这个题质量有点儿太高了。还能这么拆贡献。。。学到了学到了。。。
首先如果你不往区间 dp 想的话,如果从线性 dp 的角度考虑,应当能设计出正确的状态,就像我最开始考虑的一样。设 \(f_{i,j,k}\) 为考虑了前 \(i\) 个数,有 \(j\) 个未配对,怪异值为 \(k\) 的排列总数。这个状态固然是对的,但是我最开始貌似考虑枚举前面没配对的点了,然后你就无法保证一个点只会被匹配一次,然后你就完蛋了。
比较混乱,其实如果你不混乱根据你自己设计的状态也应该知道这是个匹配问题的。我们应该稍微画个图。
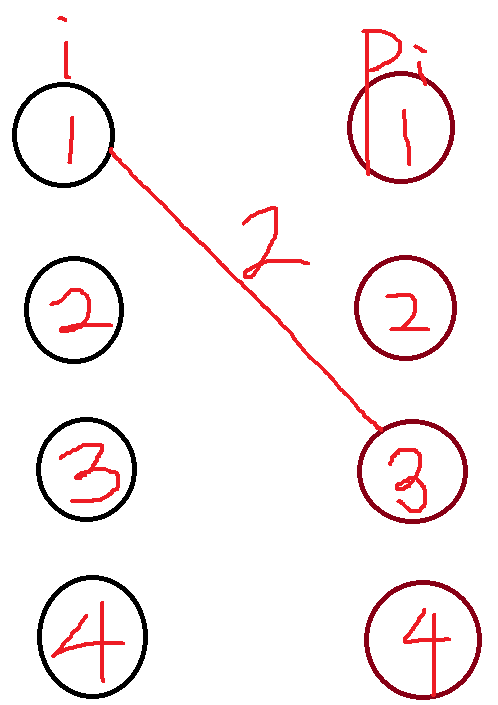
可以发现,其实这个绝对值挺难搞的,不是很能做。我们可以考虑拆一下贡献。即把 \(\sum_{i=1}^n |p_i-i|\) 改成 \(\sum_{j=1}^{n-1}\sum_{i=1}^n [i\leq j][p_i>j]\)(求和换序)。考虑这样的组合意义,其实就是你把贡献拆成这样:
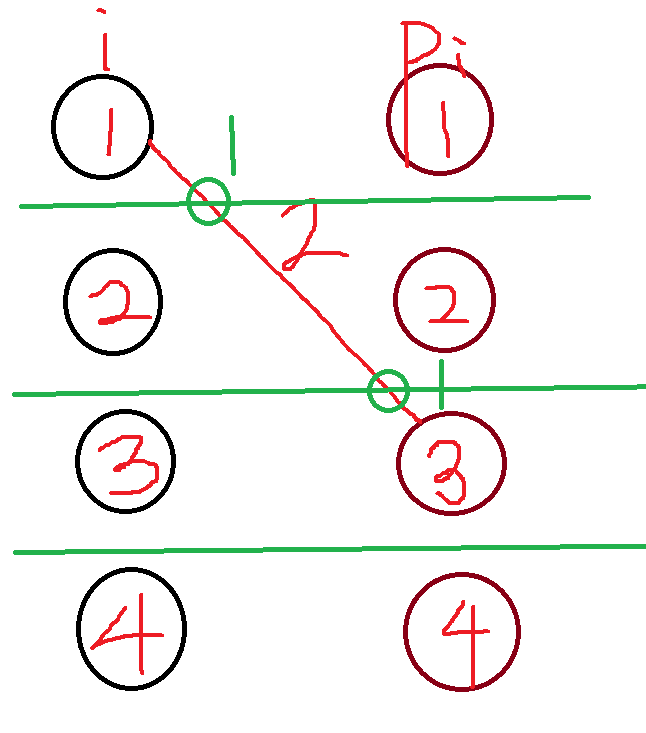
每个交点就是一个贡献。唉这样就比较舒服看起来。我们把每条线的贡献加起来就是答案。
考虑这个东西他为什么好,你有没有发现,这个是按照线转移的,即按照行转移的,这与我们 dp 的方式不谋而合!那么我们可以大概知道,若前面的点未匹配的有 \(j\) 个,那么穿过这条线的就有 \(2\times j\) 的贡献,因为未匹配的 \(i\) 与未匹配的 \(p_i\) 个数一定是相等的。
我们考虑转移:对于每一行,我们可以匹配 \(0/1/2\) 个。
- 匹配 \(0\) 个
非常显然的,你先多了一组未匹配点,那么你就从 \(f_{i-1,j-1,k-2\times j}\) 转移。
- 匹配 \(1\) 个
也很显然了,你匹配了一组,我们先假设是 \(i\) 对 \(p\) 区进行匹配,那么由于没匹配的有 \(j\) 个,就有 \(j\) 种匹配方案,反之同理,一共 \(2\times j\) 种匹配方案。匹配数加一减一不变。
于是贡献是 \(f_{i-1,j,k-2\times j}\times 2\times j\)
- 匹配 \(2\) 个
也很显然,匹配两组,那么减少了一组未匹配。因为从 \(f_{i-1,j+1,k-2\times j}\) 转移,所以左边 \(j+1\) 种选择,右边 \(j+1\) 种选择。
于是贡献是 \(f_{i-1,j+1,k-2\times j}\times (j+1)^2\)
那么我们做完了!
技巧 1:遇事不决拆贡献,它给我们的启示是:你把贡献拆的和你目前所设计 dp 相吻合基本就对了。
技巧 2:和 Medals 一样,看到两类物品两两之间有关系啥的,你可以想到二分图匹配类似的东西看能不能处理。
第一篇题解 & xxw 后一部分的做法
这个比较像人类,就是你也不拆贡献了,你考虑提前计算贡献,考虑如果此行失配就是 \(-i\) 的贡献,如果两个都不匹配就是 \(-2i\) 的贡献,两个匹配就是 \(2i\) 的贡献,否则贡献为 \(0\),其余和上面转移一样。
这个东西也是失配模型的一种理解方式。
CF1726E Almost Perfect
手摸一下很容易注意到一个性质,就是原图要么是自环要么是任意二元环,要么是对角线差为 \(1\) 的四元环。
对这个计数即可。然后你发现一下其实只有对角线差为 \(1\) 的四元环的限制比较紧,前面那两个都太松了。于是我们可以枚举四元环个数 \(t\),其他的我们预处理出来带编号的匹配方案数即可。
设 \(f_i\) 为 \(i\) 个点带编号用自环和二元环凑出的方案数。这个是好计数的,我都会。首先 \(i\) 可以单独自环,即从 \(f_{i-1}\) 转移过来。要么就是与什么东西构成二元环,即 \(f_i=f_{i-2}\times (i-1)\),即选一个组成二元环其他 \(i-2\) 个带编号配凑,我们也不太关心编号是啥。
剩下就是式子,首先在 \(n\) 个中选 \(2t\) 个相邻二元组,这个东西相当于 \(x_1+x_2+...+x_{2t}=n\) 且对于 \(\forall i\) \(x_i\geq 2\) 的单线性方程解的个数,下界可以插板法。即 \(\binom{n-2t}{2t}\),组合意义理解一下就是先把 \(2t\) 个减掉,插板后再强制每个组插一个球,就完了。然后你对 \(2k\) 个数对任意排列,是 \((2k)!\),\(k\) 个四元环之间没有顺序,除以 \(k!\)。
答案就是 \(\sum_{i=0}^{[\frac{n}{4}]} f_{n-4i}\times \frac{(2k)!}{k!}\times \binom{n-2i}{2i}\)。
然后就做完了。
[AGC013E] Placing Squares
超级无敌好题。
平方的一种组合意义:\(l^2\) 等价于在长度为 \(l\) 的区间上放置黑白两个球的方案数
有了这个后面就不难了,设 \(f_{i,0/1/2}\) 为现在考虑的是 \([i-1,i]\) 这个区间,从 \(i\) 位置到前面放隔板的位置放了多少个球。我们要讨论 \(i-1\) 这个位置放不放置隔板。
首先考虑不带禁止的情况,带禁止的肯定就是这东西排除掉点儿东西对吧。
首先 \(f_{i,0}=f_{i-1,0}+f_{i-1,2}\),\(f_{i-1,0}\) 不禁,\(f_{i-1,2}\) 禁且 \([i-1,i]\) 不放球。
其次 \(f_{i,1}=2\times f_{i-1,0}+f_{i-1,1}+2\times f_{i-1,2}\),\(2\times f_{i-1,0}+f_{i-1,1}\) 是不禁,\(2\times f_{i-1,2}\) 是禁,注意讨论系数 \(2\),因为黑白球是不同的。
最后是 \(f_{i,2}=f_{i-1,0}+f_{i-1,1}+f_{i-1,2}+f_{i-1,2}\),\(f_{i-1,0}+f_{i-1,1}+f_{i-1,2}\) 是不阻隔,后面的 \(f_{i-1,2}\) 是阻隔,这都是简单的。
带禁止的自己推吧,把我上面说的阻隔的减去即可。
维护分段矩阵乘法,简单的,比某美食家好多了(还得处理倍增矩阵真唐),然后就做完了。
CF1327F AND Segments
我可能想到了大概 60%,确实后面的比较好的思想了。也是我接触的第一道双指针结构优化的 DP。但其实你会发现这种手法可能也并不算是一种方法,在你想到合法区间时这是非常自然的。就像我在某场模拟赛也想到了合法区间这件事一样。
前面很套路,注意到每一位贡献孤立,所以我们对每一位分别计算,然后把答案乘起来即可,这非常好理解。发现有两种限制:
-
与值为 \(1\) 限制了全部为 \(1\),这是一个非常死的限制,把它判掉即可。
-
与值为 \(0\) 限制了一个存在性问题,即至少在 \([l,r]\) 中存在一个 \(0\)。这个可能就不太好限制。
注意到对于每个点 \(i\),其能够贡献的区间是固定的,设为 \([g_i,i]\)。\(g_i\) 是非常好求出的。
接下来设计一个较为显然的状态,设 \(f_{i,j}\) 为考虑了前 \(i\) 位,前面一个 \(0\) 填在了 \(j\) 位置的答案。
那么我们分类讨论其转移。
若 \(j<g_i\),则 \(f_{i,j}=0\)
若 \(g_i\leq j<i\),则 \(f_{i,j}=f_{i-1,j}\)
若 \(j=i\),则 \(f_{i,j}=\sum_{k=g_i}^{i-1} f_{i-1,k}\)
注意到这可以滚动数组,但其实我们连滚动数组都不需要,注意到我们大概率就是把上一层的直接复制过来。由于 \(g_i\) 单调不降,我们可以使用双指针维护左端点,到一个点直接进行删除和加入,你可以认为是一个类似单调队列的东西,只不过我们在计数所以改成了双指针。同时维护一下当前 \(sum\) 即可。
那我们做完了。
CF1580B Mathematics Curriculum
很好我是。。。我为什么会想到要限制子树左右端点的啊?
启示:不该记的就别瞎记,能快速算出来的东西就可以不记。
排列最大值显然可以考虑到笛卡尔树头上。设 \(f_{i,j,k}\) 为 \(i\) 个点组成的笛卡尔树,深度为 \(j\) 的点有 \(k\) 个的笛卡尔树个数,显然的,你每次就是要插入一个最大值,这谁都能想到。
那你就枚举最大值点插哪呗。其实你就是限制了现在最大值点为根,限制了左子树大小,那么同时右子树大小你也知道了。
然后你就需要枚举一下左子树符合条件的点有多少就行了,然后此时右子树的合法点也被限制了。
最后选一下左子树有哪些点就好了。这样右子树的点也确定了。
于是 \(f_{i,j,k}=f_{l,j-1,t}\times f_{i-l,j-1,k-t}\times \binom{i-1}{l}\)
然后就做完了。
莫比乌斯反演公式证明(混进来个奇怪的东西)
\(\sum_{d|n} \mu(d) = [n=1]\)
其实可能挺好整的。首先由于 \(\mu(n)\) 限制了若 \(n\) 有平方因子就是 \(0\),那么我们设 \(n=\prod_{i=1}^{m} p_i^{q_i}\),其中 \(\forall q_i\leq 1\) 才有贡献。
那么由二项式定理 \(\sum_{i=1}^{m} \binom{m}{i}\times x^i=(x+1)^m\)。那么 \(\sum_{d|n}\mu(d)=\sum_{i=1}^{m} \binom{m}{i}\times (-1)^i=((-1)+1)^m=[m=0]\),然后就整完了。
CF1559E Mocha and Stars
首先你把第三个限制去了好像就是一个前缀和优化背包,也没啥可说的。第三个条件应该也并非很难限制。有两种较为显然的做法。
约数容斥
枚举一个 \(d\),强制钦定选 \(d\) 的倍数的物品,即让 \(g_d\) 为 \(d|\gcd(a_1,a_2...,a_n)\) 的答案。令 \(f_d\) 为 \(d=\gcd(a_1,a_2...,a_n)\) 的答案。
倒着跑,这样 \(g_d\) 会在跑完 \(d\) 之后变为 \(f_d\) 这样你容斥的就是对的了。
莫比乌斯反演(用 \(\mu(d)\) 作为容斥系数)
变成 \(\sum_{a_1=l_1}^{r_1}...\sum_{a_n=l_n}^{r_n}[\gcd(a_1,a_2...,a_n)=1][\sum_{p=1}^{n}a_p\leq m]\)
稍微变一下变成 \(\sum_{a_1=l_1}^{r_1}...\sum_{a_n=l_n}^{r_n}\sum_{d|\gcd(a_1,a_2...,a_n)}\mu(d) [\sum_{p=1}^{n}a_p\leq m]\)
再变成 \(\sum_{d=1}^n\mu(d)\sum_{a_1=\frac{l_1}{d}}^{\frac{r_1}{d}}...\sum_{a_n=\frac{l_n}{d}}^{\frac{r_n}{d}}[\sum_{p=1}^{n}a_p\leq \frac{m}{d}]\)
跑背包就完了。复杂度依然是调和级数。常熟略大,由于 \(\mu(d)=0\) 时贡献为 \(0\),所以不需要跑这种。
CF1174E Ehab and the Expected GCD Problem
这种东西,你可能确实也不会特别往数的构造上想,但是我还是想了一下,想了一个类似最后一篇题解的做法,但是我好像是双 \(\log\) 的,于是还是学习了一下最后一篇题解。
技巧:有时可以对答案的形式进行考虑。
首先你发现就是最优答案应当是 \(\log_2(n)\) 吧好像是,然后我就没细想了。然后我想了一个东西,就是你注意到你可以枚举那些分界点,然后刷表,好像感觉这种带约数的填表就是 \(\sqrt{n}\) 的,刷表就是 \(\ln(n)\) 的一般。
然后你会注意到就是答案的可行性是单调的,就是若 \(j\) 是 \(i\) 的倍数且我们满足了 \(j\) 那么必定会满足 \(i\),所以我们填完分界点后其余的我们就可以随意丢在后面了。
看一下分界点是什么情况:
- 是 \(i\) 的倍数
- 不是 \(j\) 的倍数
那么显然这样的数有 \([\frac{n}{i}]-[\frac{n}{j}]\)。
技巧:强制选位置填数。这个东西以前有一道 arc 还是 agc 我忘了也用到过就是强制填到最左边
我们将分界点强制填到目前方案最左边的空,这样我们可以严格保证答案的正确性。所以先从 \([\frac{n}{i}]-[\frac{n}{j}]\) 里选一个,然后就随便排了,即 \(A_{n-[\frac{n}{j}] - 1}^{[\frac{n}{i}]-[\frac{n}{j}] - 1}\)。
这样我们中途记 \(f_{i}\) 表示目前填到 \(\gcd=i\) 的最优答案。\(g_i\) 表示最优答案方案数。类似最短路计数进行转移即可。
技巧:既要最优化又要最优化计数的可以考虑使用这种转移方式,这两个东西本身是兼容的。但是某些东西同时记两个就不行,因为你无法同时保证两维的最优性,属于线性规划问题,详见 甲虫 一题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号