

一、本章学习知识点归纳及学习心得
(一)图的定义:图G由V(顶点集合)和E(边集合)两个集合组成,可分为有向图(<x,y>尖括号且x是弧尾,y是弧头)和无向图((x,y)圆括号);
注意:E(G)可以为空集,则此时图G只有顶点而没有边;
(二)图的基本术语:
1、子图:一个图G的顶点集合和边集合分别是另一个图G'的顶点集合和边集合的子集,那么G是G'的子图;
2、有向完全图和无向完全图:无向完全图(具有n(n-1)/2条边);而有向完全图(有n(n-1)条边)
注意:如果该图是无向图,那么两个顶点之间只有一条边连接,所以要除以2,若是无向图,那么两个顶点之间可以有两条边;
3、稀疏图和稠密图:有很少条边或弧的图称为稀疏图,反之称为稠密图;
4、权和网:在实际应用中,每条边上可以标有具有某种意义的数值,该数值称为权;而带权的图称为网;
5、邻接点、度(入度+出度)、入度和出度;
6、路径和路径长度(路径长度是一条路径上经过的边或弧的数目)、回路和环、简单路径、简单回路或简单环;
注意:简单是指序列中顶点不重复出现
7、连通、连通图和连通分量:
连通分量:指的是无向图的极大连通子图;
注意:(1)一般来说,连通分量是相对于无向图的一个概念;(2)极大不等于最大,一个无向图中也不只有一个连通分量;
8、连通图的生成树:一个极小连通子图,它含有图中全部顶点,但只有足以构成一个树的n-1条边;
(三)图的存储结构:
1、邻接矩阵表示法:①将图的信息封装成一个结构体,数据成员包括用于存放顶点名字和编号关系的顶点表、邻接矩阵(用于表示两个顶点是否相邻)、顶点数和边数,具体实现代码如下:
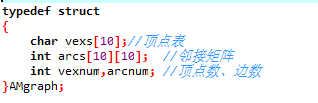
②用邻接矩阵表示法,创建无向图,具体代码如下:

注意:a)若是建立无向网,初始化邻接矩阵是将g.arcs[i][j]=MaxInt,同时可以输入边的权值;b)可以通过邻接矩阵中元素值(0或1)来判断两个顶点是否相邻;
2、邻接表表示法:相对于邻接矩阵来说,比较复杂一点,但在课堂上,老师一一利用画图来表示这些数据成员具体指哪些,帮助我们更好理解,画图如下:
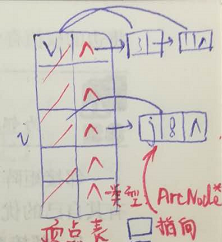
初始化的时候,顶点表中的指向边结点的指针初始化为零;同时在采用邻接表表示法创建无向图中,也使用了头插法建立一个顶点与其他相邻顶点所构成的一个个单链表;
(四)图的遍历:
1、深度优先搜索遍历,具体代码实现如下(基于作业题:输出连通子集):

注意:深度优先搜索类似于树的先序遍历,在理解由图通过深度优先搜索生成深度优先生成树时,可以通过树的先序遍历来帮助理解
2、广度优先搜索遍历,具体实现代码如下(基于作业题:输出连通子集):
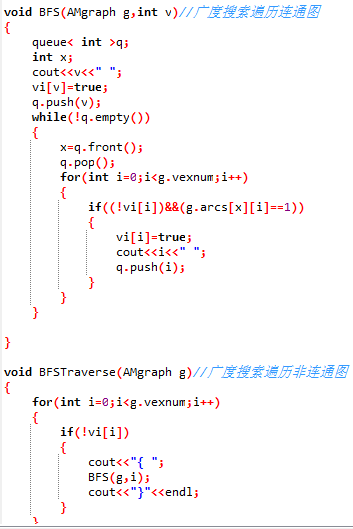
广度优先搜索类似于树的层次遍历,因此实现通过广度搜索来遍历图的代码时,也采用了像树的层次遍历中用到的队列,而采用广度搜索时,可以分为两种情况:①对于顶点v,可以先访问,在入队;也可以先入队,再访问。
注意:因为图可以采用基于邻接矩阵和邻接表的存储结构,所以深度搜索和广度搜索也分别有两种实现代码,此外,当同一个程序中使用到深度搜索和广度搜索时,我们会使用辅助数组,用来标记访问过得顶点,但需注意出现以下情况:

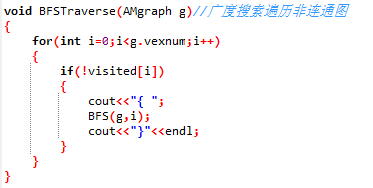
同一个程序中,深度搜索和广度搜索使用了同一个判断数组,但是在执行过程中,经过深度搜索的时候,判断数组中的元素值已经全部赋值为1,所以执行到广度搜索的语句的时候,一定不会满足if语句中的条件,所以运行后不会输出广度搜索的连通子集。
(五)图的应用:
1、最小生成树:普里姆算法(选顶点)、克鲁斯卡尔算法(选权值最小的边)
2、最短路径问题:迪杰斯特拉算法(依据最短路径的长度递增的次序求得各条路径)
二、目标完成情况及接下来的目标:
1、目标完成情况:对于二叉树的性质自己通过画图、做些相关练习,有促进自己对这些性质的理解,在整理解题思路的时候,发现自己思路不是很清晰,会回忆老师讲解时的具体思路,慢慢转变成自己能够理解的东西,也会请教同学帮助。
2、接下来的目标:更进一步去了解关于最小生成树和最短路径问题的相关算法,弄清算法在求解过程中个参量的变化,促进理解。

