基于人工智能的苹果成熟度检测
一、选题的背景
苹果在采摘期被采摘后,需要工人进行手工对苹果的成熟度进行分类,这耗费了大量的人力与物力,而且相近成熟度难以区分,存在分类颗粒度过粗,分类过程存在较为强烈的主观因素等问题。
在这里,我们提出了基于深度学习的苹果成熟度识别方案,这是一种用于帮助农民和采摘工人判断苹果成熟度的人工智能系统。它能够从图像中快速、准确地判断苹果的成熟度,判断苹果是否已经成熟,从而为农民和采摘工人提供帮助。
二、数据集的来源
数据一共有A -F一共六种不同成熟度的苹果,一共包括6161张照片。
AppleD文件夹: 网上搜索苹果成熟前5个月,此时苹果还很青涩
AppleF文件夹: 网上搜索苹果成熟前4个月
AppleE文件夹: 网上搜索苹果前成熟3个月
AppleC文件夹: 网上搜索苹果成熟前2个月
AppleA文件夹: 网上搜索苹果成熟前1个月
AppleB文件夹: 网上搜索苹果成熟时,此时苹果成熟
三、采用的机器学习框架描述
采用keras框架搭建分类模型,完成模型训练、预测和分类任务。
采用tensorflow.image API与tensorflow.data API完成图片的增强与数据集的制作。
采用sklearn,完成训练集和测试集的划分,并且固定随机数种子,防止信息泄露。
四、涉及到的技术难点与解决思路
tf.data可以把python写的代码编译到C++后端高效执行,因此也存在较大的限制。对模型张量存在要求,使用上也有限制。
数据集并不算十分充裕,因此引入预训练模型就十分必要了。这里采用的是ResNet50在imageNet上预训练的模型,有很强的泛化能力。
五、数据的预处理
为了利用在ResNet在ImageNet上预训练的权重,因此我们要使用与预训练相同的数据预处理方式,使数据保证在同一份分布上。
网络输入尺寸设置为224 * 224 * 3的RGB全彩图像,为了迎合各种尺寸的实际图像,需要把数据集中的图像按比例缩放,保证图像不会走形,影响模型的性能。将图片进行居中对齐,然后对每个维度缺失部分填0补充,反映到图像上,及为图像增加黑边。
在这里我们采用图片放大然后随机裁剪的方式对数据集进行扩充。
在实际中,我们缩放后的图片并非为实际网络输入尺寸,而是输入尺寸的1.4倍,然后再随机裁剪出需要尺寸。
最后对图片进行随机镜像,随机旋转进行数据增强,提高模型性能。
六、模型选择:
模型采用ResNet50,并加载imageNet数据集上训练的权重,降低训练压力,提高训练效果。
七、训练参数:
优化器: 采用Adam优化器学习率设置为2*1e-4,并训练10个epoch
损失函数: 采用SparseCategoryEntropy,及交叉熵作为分类损失。
衡量指标: 采用正确率和计算损失作为衡量指标

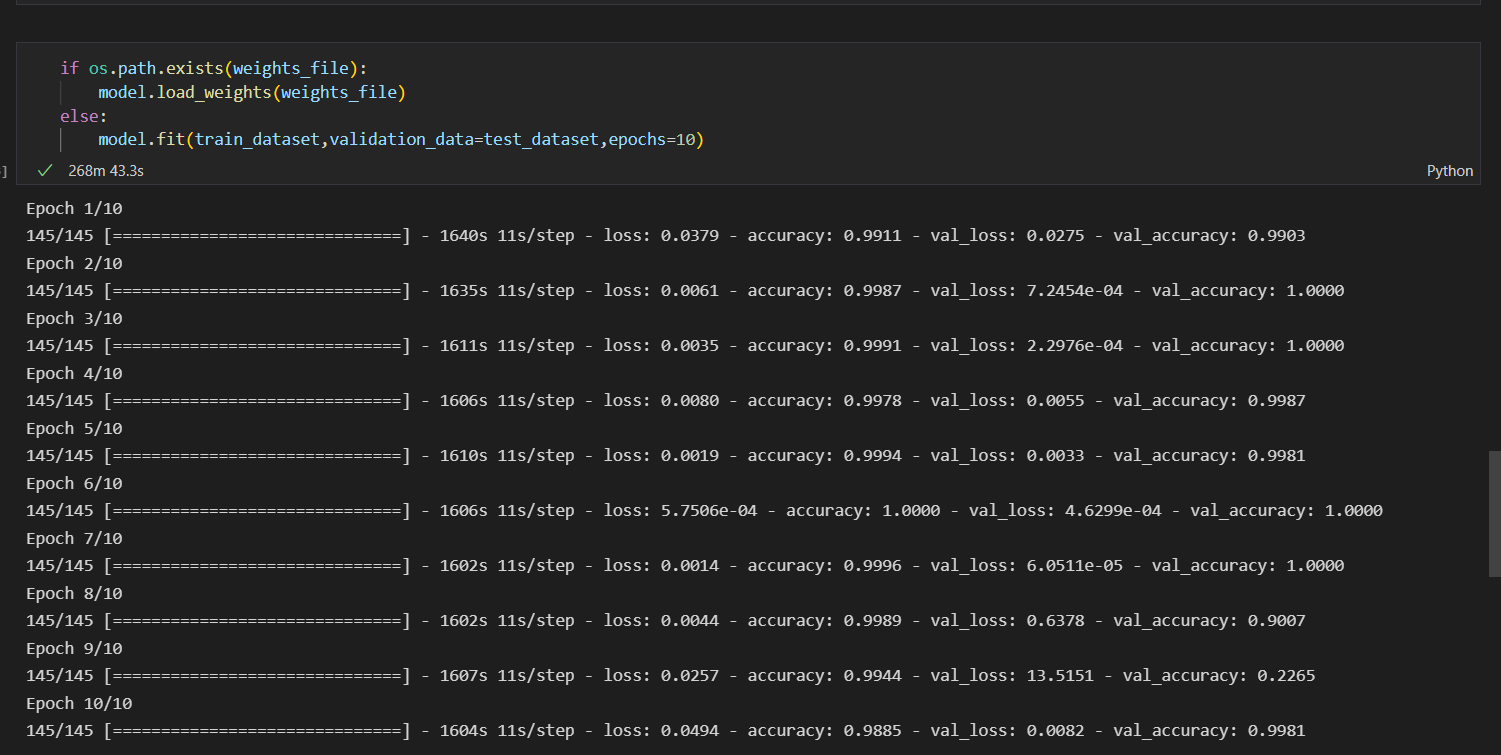
八、开始训练:
这里我训练了6个epoch,但是由图可知只有前3个epoch是有效训练。
训练集和测试集按照6:4比例划分,分类模型在测试集上实现了99.4%的分类精度。
九、模型测试:
我们加载一张图片对苹果进行分类演示:
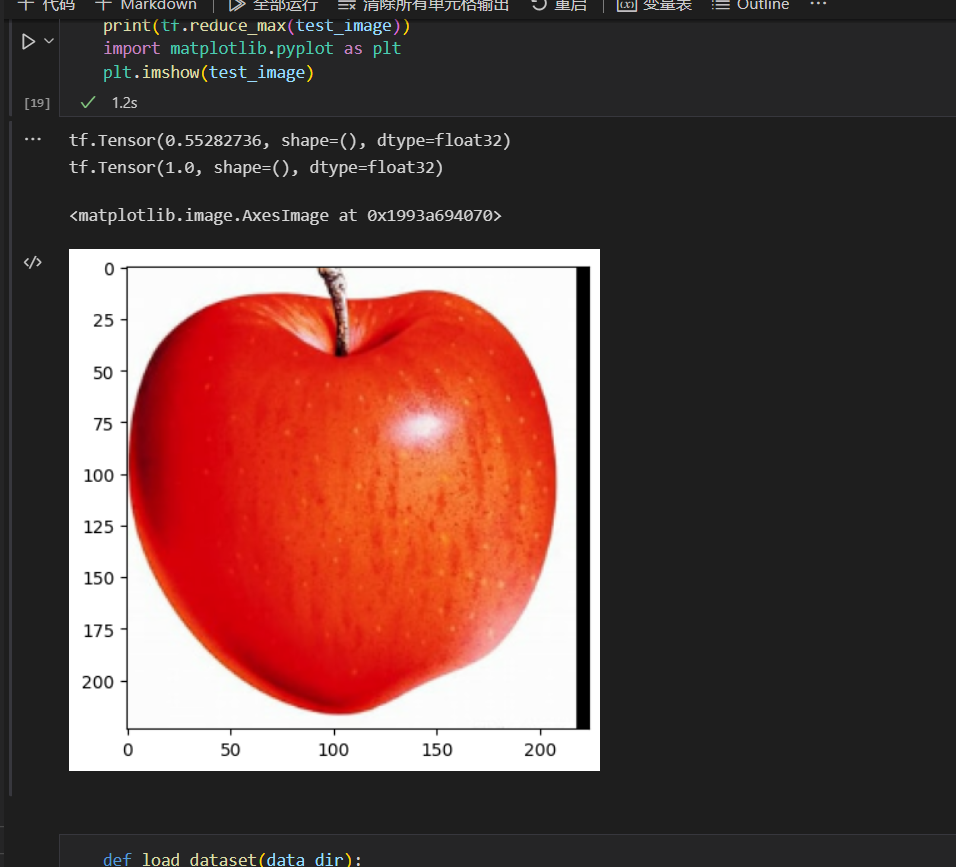

模型预测苹果为D类,实现了正确分类。
十、总结
通过这次的实验,我学会更好的使用python,利用python做好更多的事情,只要一些简单的代码,就能让电脑学会分辨苹果的成熟度,很是方便,自己也可以利用这个程序检验生活中苹果的成熟度。
十一、代码
import tensorflow as tf
from keras.applications import resnet
from keras.losses import SparseCategoricalCrossentropy
from keras.layers import *
from keras.applications.resnet import preprocess_input
from keras import Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.callbacks import ModelCheckpoint
import os
pretained = True
image_size = 224
expand_rate = 1.1
expand_size = int(expand_rate * image_size)
batch_size = 32
learning_rate = 1*1e-5
#classes = ['Apple','Carambola','Kiwi','Orange','Pear','Pitaya','Pomegranate','muskmelon',
# 'Banana','Guava','Mango','Peach','Persimmon','Plum','Tomatoes']
#data_dir = r"D:\datasets\水果分类"
classes = ['Apple A', 'Apple B', 'Apple C', 'Apple D', 'Apple E', 'Apple F']
data_dir = r"D:/苹果成熟度分类\Apple"
weights_file = "苹果分类ResNet50.h5"
def build_resnet50_model(input_size,num_classes,is_pretrained):
_input = Input((input_size,input_size,3))
_body = resnet.ResNet50(include_top=False,weights= 'imagenet' if is_pretrained else None,pooling='avg')(_input)
_output = Dense(num_classes,activation='softmax')(_body)
model = Model(inputs=_input,outputs=_output)
model.compile(optimizer=Adam(learning_rate= learning_rate),loss=SparseCategoricalCrossentropy(from_logits=False),metrics='accuracy')
return model
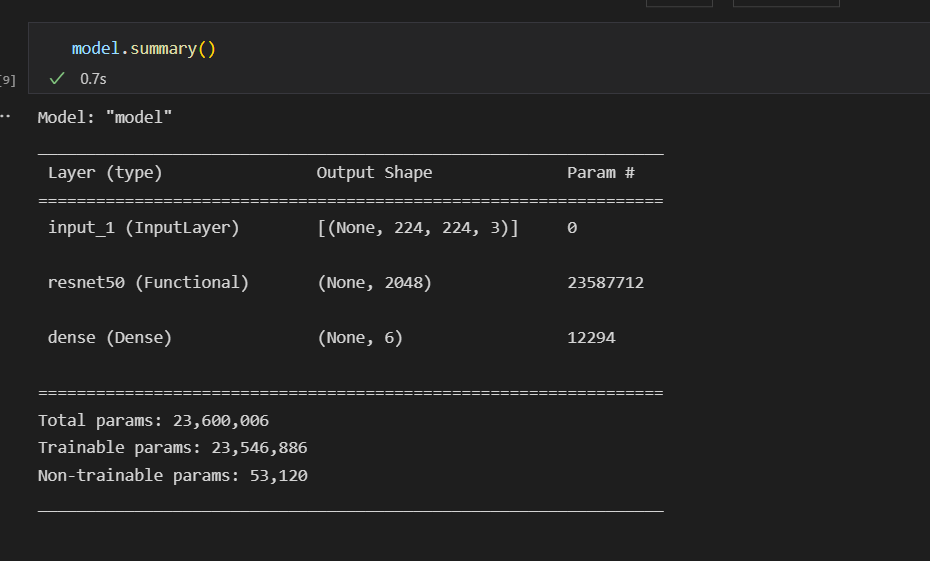
model = build_resnet50_model(image_size,len(classes),True)
model.summary()
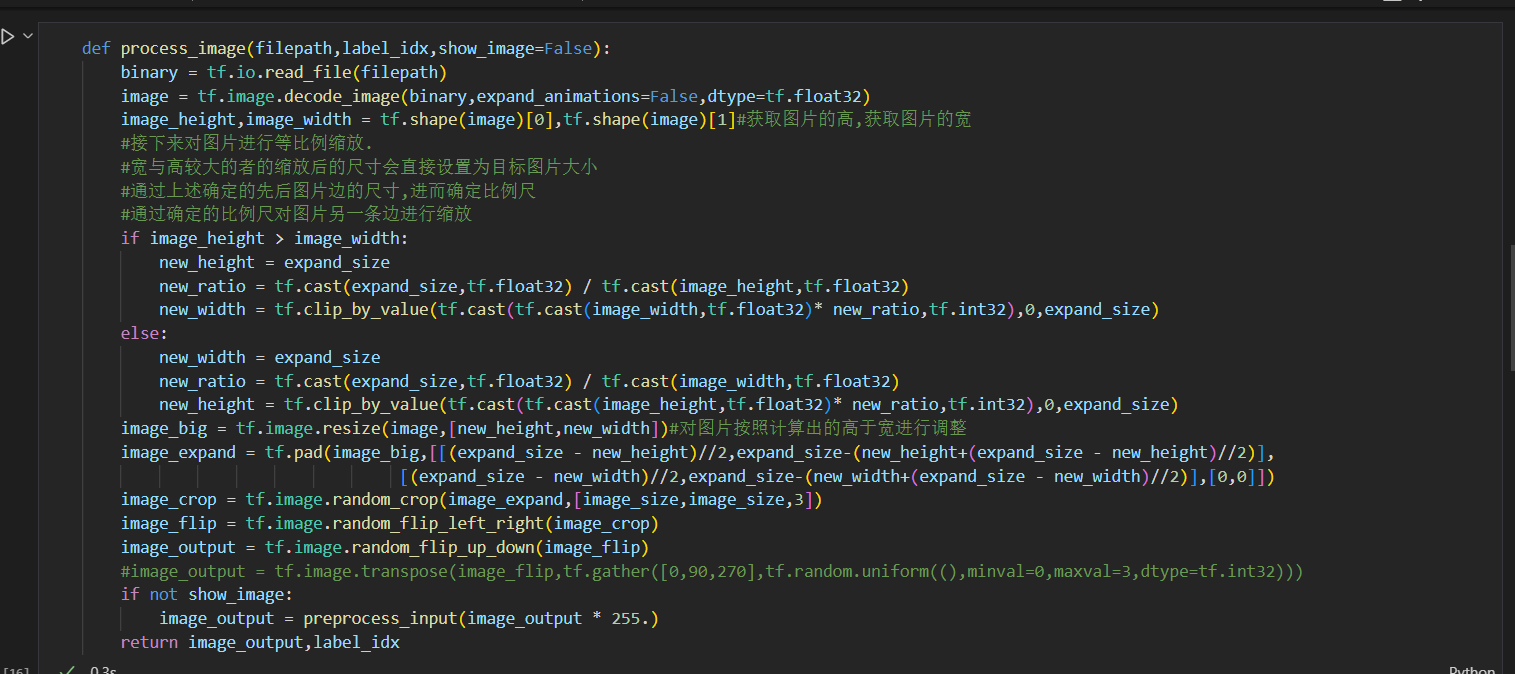
def process_image(filepath,label_idx,show_image=False):
binary = tf.io.read_file(filepath)
image = tf.image.decode_image(binary,expand_animations=False,dtype=tf.float32)
image_height,image_width = tf.shape(image)[0],tf.shape(image)[1]#获取图片的高,获取图片的宽
#接下来对图片进行等比例缩放.
#宽与高较大的者的缩放后的尺寸会直接设置为目标图片大小
#通过上述确定的先后图片边的尺寸,进而确定比例尺
#通过确定的比例尺对图片另一条边进行缩放
if image_height > image_width:
new_height = expand_size
new_ratio = tf.cast(expand_size,tf.float32) / tf.cast(image_height,tf.float32)
new_width = tf.clip_by_value(tf.cast(tf.cast(image_width,tf.float32)* new_ratio,tf.int32),0,expand_size)
else:
new_width = expand_size
new_ratio = tf.cast(expand_size,tf.float32) / tf.cast(image_width,tf.float32)
new_height = tf.clip_by_value(tf.cast(tf.cast(image_height,tf.float32)* new_ratio,tf.int32),0,expand_size)
image_big = tf.image.resize(image,[new_height,new_width])#对图片按照计算出的高于宽进行调整
image_expand = tf.pad(image_big,[[(expand_size - new_height)//2,expand_size-(new_height+(expand_size - new_height)//2)],
[(expand_size - new_width)//2,expand_size-(new_width+(expand_size - new_width)//2)],[0,0]])
image_crop = tf.image.random_crop(image_expand,[image_size,image_size,3])
image_flip = tf.image.random_flip_left_right(image_crop)
image_output = tf.image.random_flip_up_down(image_flip)
#image_output = tf.image.transpose(image_flip,tf.gather([0,90,270],tf.random.uniform((),minval=0,maxval=3,dtype=tf.int32)))
if not show_image:
image_output = preprocess_input(image_output * 255.)
return image_output,label_idx
test_image,_ = process_image(r"D:/苹果成熟度分类\Apple\Apple03.jpg",'',show_image=True)
print(tf.reduce_mean(test_image))
print(tf.reduce_max(test_image))
import matplotlib.pyplot as plt
plt.imshow(test_image)
def load_dataset(data_dir):
filepaths = []
label_idices = []
for label_idx,current_dir in enumerate(classes):
for filename in os.listdir(os.path.join(data_dir,current_dir)):
filepath = os.path.join(data_dir,current_dir,filename)
filepaths.append(filepath)
label_idices.append(label_idx)
return filepaths,label_idices
x_train,x_test,y_train,y_test = train_test_split(*load_dataset(data_dir),shuffle=True,random_state=1234)
train_dataset = tf.data.Dataset.from_tensor_slices((x_train,y_train)).shuffle(2048,seed=1234).map(process_image,num_parallel_calls=32).prefetch(tf.data.AUTOTUNE).batch(batch_size)
test_dataset = tf.data.Dataset.from_tensor_slices((x_test,y_test)).shuffle(2048,seed=1234).map(process_image,num_parallel_calls=32).prefetch(tf.data.AUTOTUNE).batch(batch_size)
model.compile(optimizer=Adam(learning_rate=2*1e-4),loss=SparseCategoricalCrossentropy(from_logits=False),metrics='accuracy')
if os.path.exists(weights_file):
model.load_weights(weights_file)
else:
model.fit(train_dataset,validation_data=test_dataset,epochs=10)
def predict_image(imagepath):
input_image = tf.expand_dims(process_image(imagepath,'')[0],axis=0)
output_probs = model(input_image)
image_label_idx = tf.argmax(output_probs,axis=-1)[0]
image_label = tf.gather(classes,image_label_idx).numpy()
image_label = image_label.decode("UTF-8")
return image_label
label = predict_image(r"D:/苹果成熟度分类\Apple\Apple03.jpg")
print("预测的分类为: ",label)


