with open('data6_1.txt', 'r', encoding='utf-8') as f:
d = f.read().split('\n')
d1 = [str(i).split('\t') for i in d]
d1.sort(key=lambda x: x[2], reverse=True)
with open('data6_2.txt', 'w+',encoding='utf-8')as f:
for line in d1:
for i in line:
f.write(i + '\t')
print(i + '\t', end='')
f.write('\n')
print()
![]()
with open('data1_1.txt', 'r', encoding = 'utf-8') as f:
data = f.readlines()
n = 0
for line in data:
if line.strip('\n') == '':
continue
n += 1
print(f'共{n}行')
![]()
with open('data1_1.txt', 'r', encoding = 'utf-8') as f:
n = 0
for line in f:
if line.strip('\n') == '':
continue
n += 1
print(f'共{n}行')
![]()
with open('data1_2.txt', 'r', encoding = 'utf-8') as f:
n = 0
for line in f:
if line.strip() == '':
continue
n += 1
print(f'共{n}行')
![]()
with open('data1_2.txt', 'r', encoding = 'utf-8') as f:
n = 0
for line in f:
if line.isspace():
continue
n += 1
print(f'共{n}行')
![]()
with open('data2.txt', 'r', encoding = 'utf-8') as f:
data = f.read().split('\n')
unique_line = []
for line in data:
if data.count(line) == 1:
unique_line.append(line)
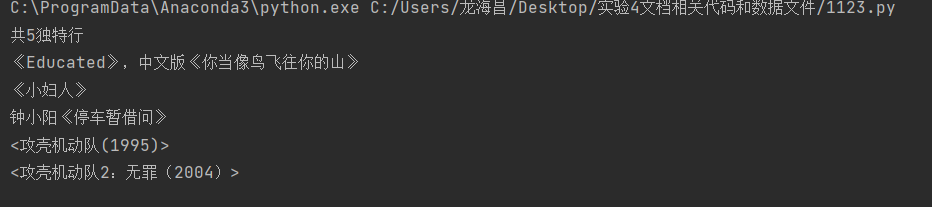
print(f'共{ len(unique_line) }独特行')
for i in unique_line:
print(i)
![]()
import csv
ls = [['城市', '大致人口'],
['南京', '850万'],
['纽约', '2300万'],
['东京', '3800万'],
['巴黎', '1000万']]
with open('data4.csv', 'w', encoding = 'utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerows(ls)
with open('data4.csv', 'r', encoding = 'utf-8') as f:
reader = csv.reader(f)
for line in reader:
print('\t'.join(line))
![]()
![]()








 浙公网安备 33010602011771号
浙公网安备 33010602011771号