
庄健志---第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 复习爬虫知识,学习echarts可视化数据的一些知识,git管理 |
| 作业源代码 | https://github.com/962673247/first-personal-work |
| 学号 | 211806150 |
| 学习内容 | 学习时间 |
|---|---|
| 爬取数据 | 3h |
| 学习 jieba 处理数据 | 1h |
| 学习echarts插件以及词云图 | ?? |
| 学习git管理 | 3h |
-
关于作业
不得不说我的效率真的是非常慢,这里要批评下自己,假期太懒了,懒得夸张,作业刚开始发布的时候看了一眼,看见第一题是爬虫,果断选择,爬虫上学期刚学啊,正好复习一下用的上,然后当天晚上看了下要爬的网页,基本分析的差不多,然后就没有然后了,一直拖到第三天的晚上才开始写代码,然后接下来基本上就是一天学一点,后面毫不熟悉的 echarts 插件和 git 的使用,代码词云图搞完了之后第二天又玩了一天...今天才开始写博客。 -
作业分析
从作业题目来看,其实老师已经帮我们都分好了,基本上就三步走,首先爬虫获取数据,然后学习中文分词处理数据,之后学习 echart 这个插件来完成词云图的构建,但是其实我刚开始并不知道这个 echart 这个插件是怎么用的,用在什么地方,然后一开始还以为只是做个词云图,就去b站看了下词云图的视频,发现和echart 插件没什么关系,后面了解了一下这个插件的用法才知道跟前端有关系,裂了,这个前端一窍不通啊,没学过,更别说去在应用一个插件进去了...所以这个作业还是不太好做的,搞定作业之后就是 git 的学习,第一次作业那边学了点基础,现在后面继续学一下分支合并等等知识。 -
作业详解
1.爬取数据部分
首先爬虫的话很熟悉哈,上学期刚刚学基本知识都记得,打开腾讯视频网页一看,大概就知道是 ajax 异步加载的问题,要么用 selenium ,要么就去抓包,点了几下更多评论,我去...一下才
刷出来十条,我傻了,果断放弃 selenium ,F12 开始分析,点了几个之后基本上就发现了规律,我们这边可以拿2个 url 去对比一下
https://video.coral.qq.com/varticle/5963120294/comment/v2callback=varticle5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6716709711492873145&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&=1614071261726
https://video.coral.qq.com/varticle/5963120294/comment/v2callback=varticle5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6716753294460916527&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&=1614071261727
这里看这起来 url 很长,其实一对比就两个地方不一样,这个 cursor 和最后的一串数字,我们先来看这个 cursor 哈,第一条这个数据的 cursor 都是0(多次刷新网页的时候有时候可以看到第一条,大部分时候都看不到第一条这个数据),根据我们以往对这类异步加载的经验,往往下一条的 url 请求参数都隐藏在上一条的数据之中,这里复制下一条的 cursor 去上一条的 url 数据里面 ctrl+f 一搜索,果然就出现了,

这里我们注意到后面还有个 hasnext ,很容易猜想到是不是判断有没有下面的评论的依据,这也是我们抓包循环结束的条件, cursor 分析完之后我们再来看最后一串数据,几条之后不难分析出每次都加1的缘故(事实上我发现规律的后一天晚上再次打开网页的时候发现有时候不是加1,是加2或者加3,找了半天没找到这个加项,可能是网站改了反爬策略,好在第二天再次看网页的时候发现又恢复了+1的规律,这也告诉了我们爬虫作业要早点做,像我这样拖拉的很容易前功尽弃),找到规律之后大家应该都在想,那第一个是什么呢?,第一个是怎么构造出来的呢,刚开始想可能是隐藏在网页源码里面,ctrl+f 之后并不是,看着这串数字,我想到了上学期爬虫的时候也遇到过类似的数据,时间戳,在进入网页的时候根据时间生成的时间戳,13位的应该是毫秒级别的,生成一下当前时间戳在对比网页的基本一样,这样我们对ajax这个异步加载的规律就完全找到,接下来只要一集一集爬取就可以了。
在对比后面几集的url发现在数据包里面还有一串数字是亘古不变的,

这前面一串是什么数字的,也不管那么多,直接复制到网页源码那边搜索一下,果然

这个数字隐藏在网页源码之中,也就是说每一集的网页都附带着这种数字,用来构造请求数据包的参数,那就是说我们需要获取所有网页的这串数字,问题再次转移到所有集的网页的构造,因为一共有20集,20集的url你都要构造出来,然后去获得里面的这串数字,进而爬取评论,当然你也可以把这20集的网页的url全部复制,然后一个个爬...但是作为学习计算机的人员肯定要倔强的分析一下,把网页url分析了一下,发现
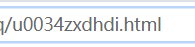
其中只有 u0034zxdhdi 这串字母是特别的,老规矩丢到网页源码一搜索,果然还是老套路,下一集的 url 构造参数隐藏在上一集的源码里面,但是在我多搜索几次之后发现
原来这里一集就有着20集网页全部的参数,正好一次性全部提取了,
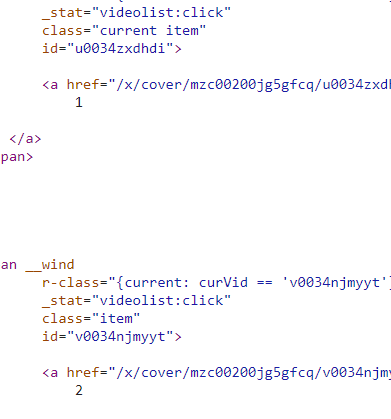
至此,网页爬取的分析过程全部结束,然后就是代码的编写。
爬取每集的url构造参数
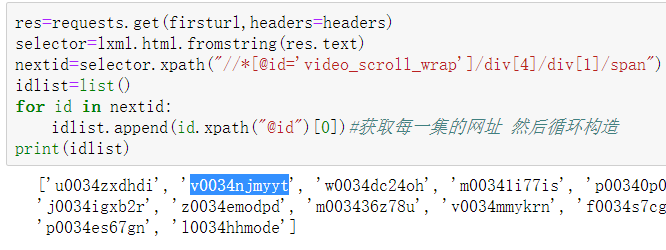
根据上面获得的url爬取抓包参数
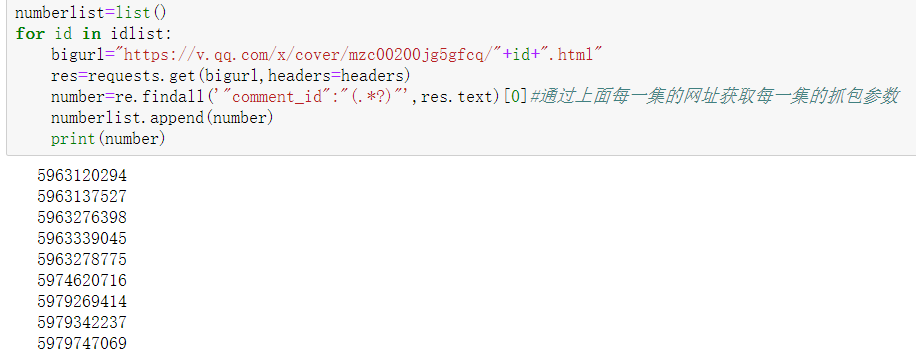
循环构造数据包url并爬取评论
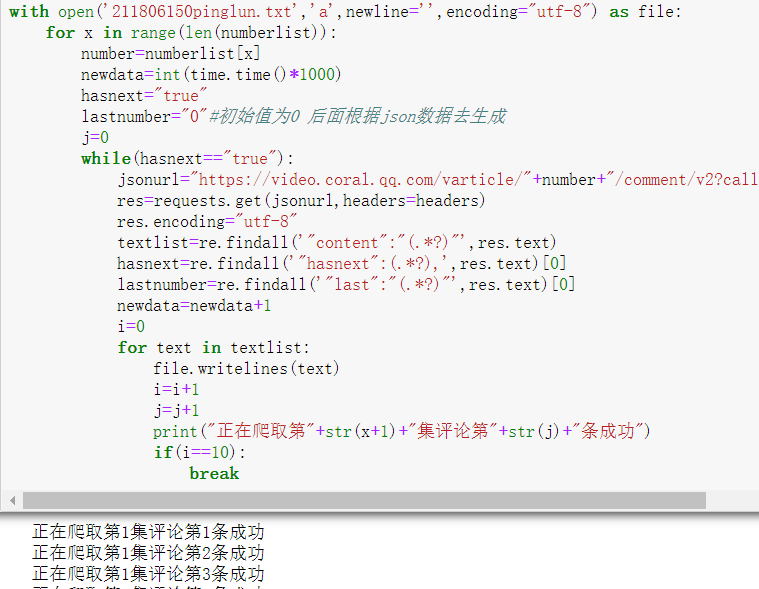
爬虫完成2.数据处理过程
数据处理的过程的话,我们需要知道处理成什么样的数据样式,从学习echart-wordcloud的github上的一些用例可以知道,处理之后的数据大概就是要满足{name:"",value:""}这样的格式,可我们获得的都是文本啊,还要在老师的作业提示下可以看到分词的作用,了解了一下分词的结果和用法之后选择了jieba分词,因为我b站看的视频里面也是用的jieba分词,虽然视频里面并没有使用echart插件,但是分词的用法都是一样的,网络上有很多jieba的学习资料,学习起来也比较简单,基本作用就是中文分词,使用起来也很方便,三种模式中我选择了精准模式,分割好数据之后统计词语的数量,即可完成对数据的处理工作。
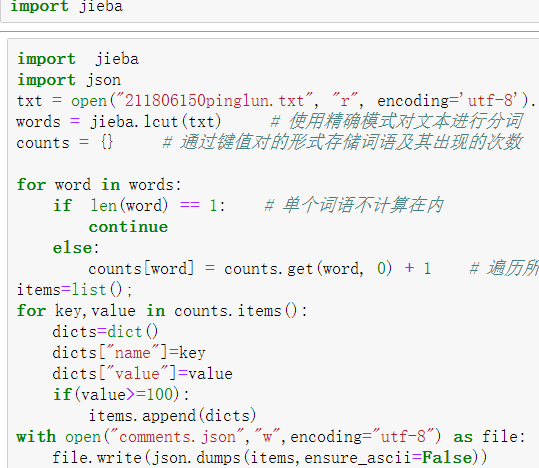
这里还有个小插曲,在保存数据的时候,由于评论里面带有emoji表情,保存到文本的时候会发生错误,txt文本无法保存表情,根据网上的解决方法是安装emoji库,确实有效。3.学习 echart 插件及词云图的制作
这里推荐大家直接去 echart 的官网来学习这个插件,里面有很多用例,可以让你大致知道整个的代码结构和轮廓,当然没有前端基础的我刚开始看起来还是特别奇怪,直到现在我还是有很多疑问,例如
我在网上下载了很多这种 js ,也看了很多用 echart 插件做的词云图的源码,我现在还没搞清楚到底什么时候该引入哪个插件,以及这些插件的区别是什么,例如这个 echarts-wordcloud.js 和 echarts-wordcloud.min.js 区别是什么,什么时候该用哪一个,这在不同的代码里面我替换这些经常发生错误,但是有时候又可以运行,由于 echart 官网上面正好就是没有词云图的案例,这使我不得不在各种网站上面寻找用例学习,最后找到了 github 上面的 echarts-wordcloud 的账号,不知道是不是官方账号,学习了一下之后感觉理解了一些,虽然应付作业是没啥问题,改几个参数,数据改一下就好了,但是感觉对 echart 的学习还不详细。这里就不贴代码了,代码基本上是套模板改数据的问题,看看效果图吧。

这里还有个疑问,我这边的数据貌似跟其他同学的有不一样的地方,例如中国词语我这边是有3000+个,我看其他同学只有1000以下,所以我在想是不是我的数据或者是 jieba 分词的模式出错了。不过按道理数据的爬取应该是没什么问题的,因为我在每集的爬取总数里面的数量都是大致和腾讯视频那边显示的总数接近的,我感觉缺少的部分可能是评论回复的部分,这个地方我确实没有去爬取。
作业的分析,数据,代码都完成了之后就是上传代码到 github 的问题,第一次自我介绍那个作业里面 git 的学习很模糊,并没有官方的学习,只是百度了一下如何 push ,这次在作业里面看见了参考资料,感觉写的很不错,清晰明了,一个下午看了大部分 git 的使用方法,很快就完成了作业要求。
提交分支什么的感觉没什么必要贴代码,我就整理几个新学习到的代码吧
git clone <你的仓库地址> 克隆远程仓库到本地
git branch 查看有几个分支 也可以看当前分支是什么
git checkout切换分支
git merge <>合并分支到当前分支
值得一提的是 git commit -m "" 引号里面不是要写说明嘛,然后我这个说明经常写错,写错了怎么办,刚开始以为我直接再commt一次改一下说明行不行,结果是不行的,他会显示文件已经存在,最后在百度里面找到了这个代码解决了问题。

-
参考资料
b站词云图的学习
jieba分词的学习
廖雪峰博客-git
echarts官网
echarts-wordcloud的学习github


 浙公网安备 33010602011771号
浙公网安备 33010602011771号