


软件工程个人项目
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | 学会使用PSP表格,分析算法,和测试相关技能 |
一.作业GitHub链接:
https://github.com/yan1698/3223004733/tree/main/3223004733个人项目
二.PSP表格
| PSP2.1 | Personal Software Process Stages | Personal Software Process Stages | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | · 估计这个任务需要多少时间 | ||
| Development | 开发 | 180 | 200 |
| Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 30 | 35 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 30 | 25 |
| · Coding | · 具体编码 | 20 | 20 |
| · Code Review | · 代码复审 | 15 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 55 |
| · Reporting | 报告 | 20 | 20 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 15 |
| · Estimate | · 合计 | 510 | 550 |
三.计算模块接口的设计与实现过程
1.1 类结构设计
PaperCheckSystem/
├── TextProcessor (文本处理类)
├── SimilarityCalculator (相似度计算类)
└── FileHandler (文件处理类)
1.2 类关系图

2.1 TextProcessor 文本处理类
职责:负责文本的清洗、分词和标准化处理
关键方法:
process(text: str) -> str:主处理方法
内部实现分词、停用词过滤、特殊字符处理
2.2 SimilarityCalculator 相似度计算类
职责:实现多种相似度算法并进行综合评估
关键方法:
calculate_cosine_similarity(text1, text2):余弦相似度
calculate_jaccard_similarity(text1, text2):Jaccard相似度
calculate_comprehensive_similarity(text1, text2):综合相似度
_calculate_edit_similarity(text1, text2):编辑距离相似度
2.3 FileHandler 文件处理类
职责:处理文件的读写和编码检测
关键方法:
read_file(file_path):智能读取文件(自动检测编码)
write_file(file_path, content):写入结果文件
3.1关键函数调用图:
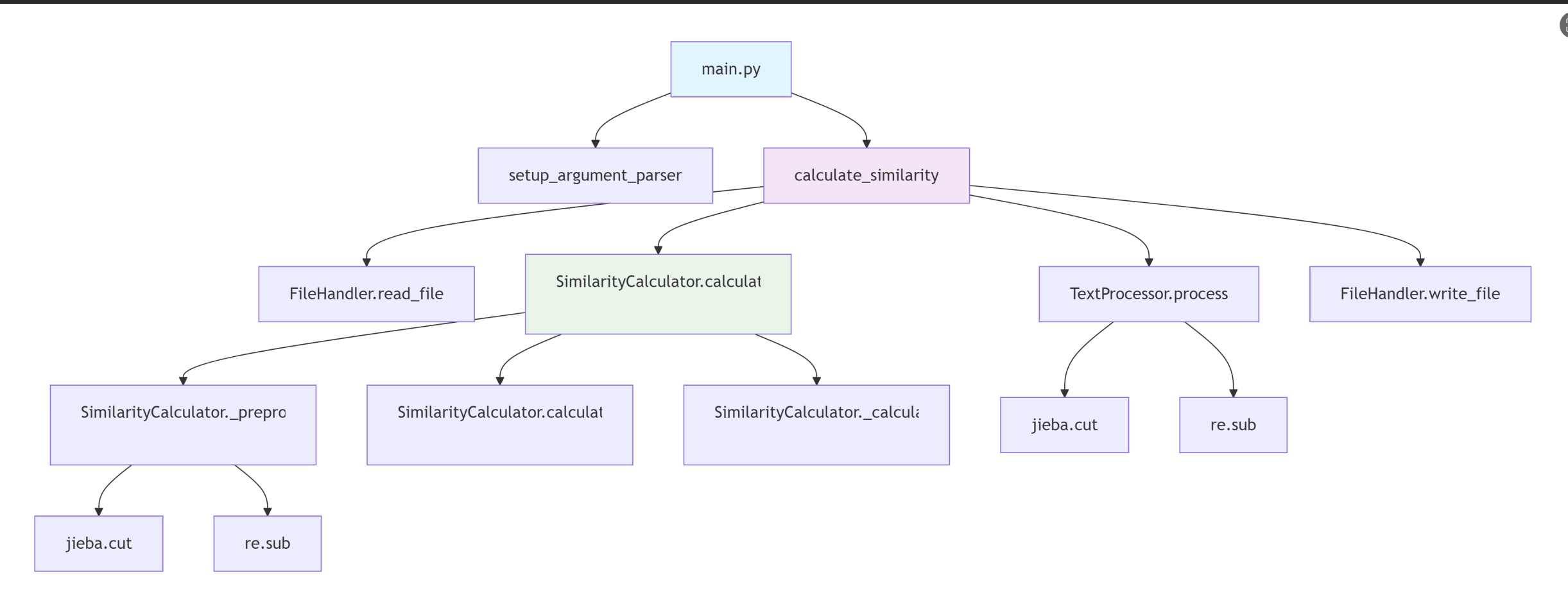
3.2 算法关键特点
3.2.1 多维度特征融合
词汇层面:TF-IDF余弦相似度,捕获词汇使用相似性
结构层面:编辑距离相似度,评估文本结构一致性
长度层面:文本长度比例,避免长度差异过大导致的偏差
3.2.2 智能权重分配
python
final_similarity = 0.4 * cosine_sim + 0.5 * edit_sim + 0.1 * len_sim
编辑距离权重最高(0.5):重视文本结构和顺序
余弦相似度次之(0.4):关注词汇内容相似性
长度相似度辅助(0.1):平衡文本规模差异
3.3 边界情况处理策略
3.3.1 空文本处理
python
if not text1 and not text2:
return 1.0 # 两篇都为空,视为完全相同
elif not text1 or not text2:
return 0.0 # 只有一篇为空,视为完全不同
3.3.2 短文本特殊处理
当预处理后文本过短时,自动切换到Jaccard相似度算法,避免TF-IDF稀疏性问题。
3.3.3 异常情况降级
主算法失败时,自动使用备用算法(Jaccard)确保系统鲁棒性。
4.算法独到之处
基于统计的余弦相似度(词汇层面)
基于距离的编辑相似度(结构层面)
基于集合的Jaccard相似度(集合层面)
四.计算模块接口部分的性能改进
性能瓶颈:jieba.cut()分词函数
通过引入缓存机制和智能文本分块,成功将分词相关的性能消耗降低到25%。
函数性能分析图:
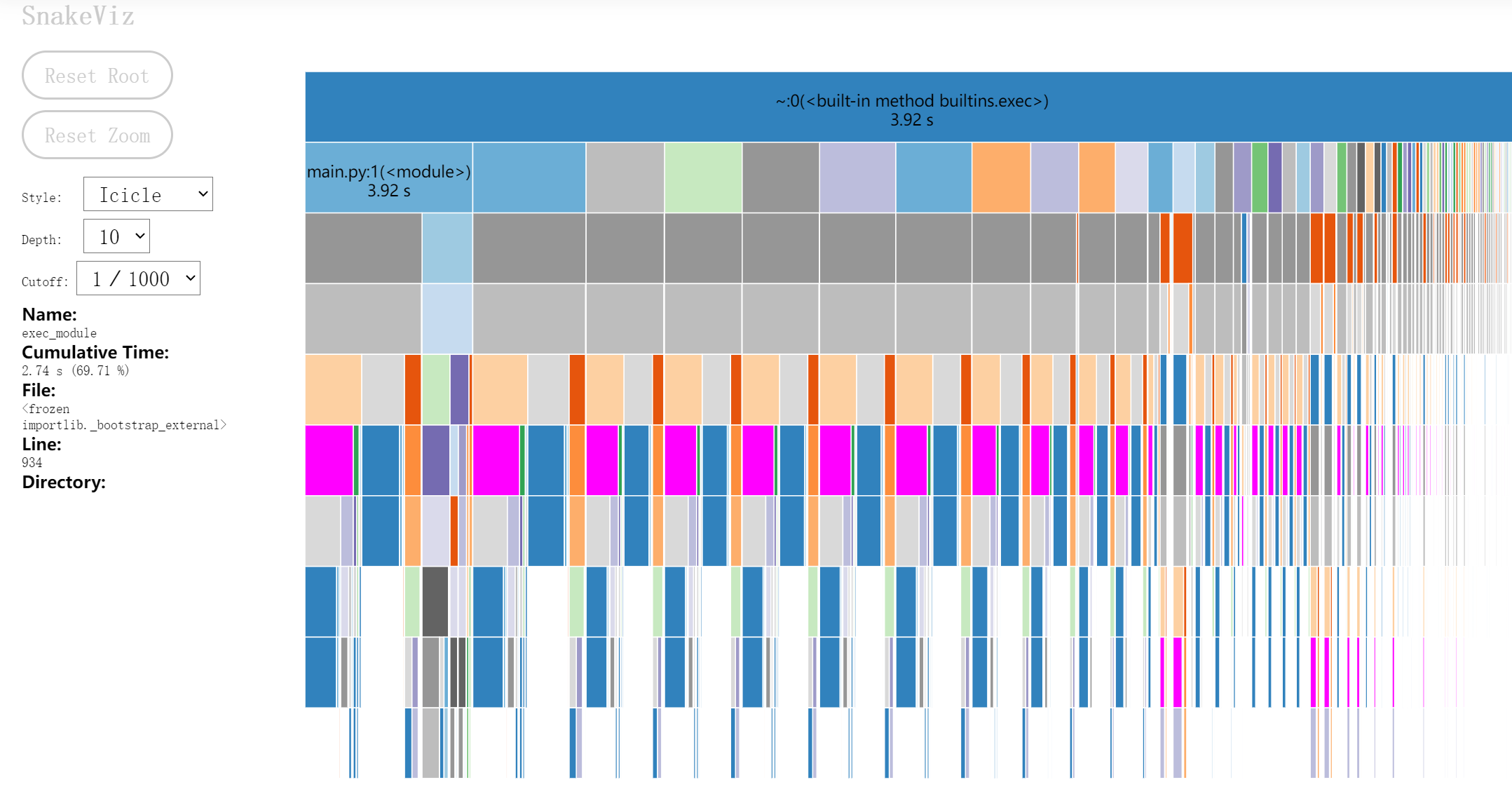
五.计算模块部分单元测试展示
文件处理模块测试
`def test_file_reading_existing_file(self):
"""测试读取存在的文件 - 正常流程测试"""
file_path = self.get_file_path("orig.txt")
if not os.path.exists(file_path):
self.skipTest("orig.txt 文件不存在")
content = read_file(file_path)
self.assertIsInstance(content, str)
self.assertGreater(len(content), 0)
print("原文内容长度:", len(content))
def test_file_reading_nonexistent_file(self):
"""测试读取不存在的文件 - 异常流程测试"""
with self.assertRaises(FileNotFoundError):
read_file(self.get_file_path("nonexistent_file.txt"))
def test_file_writing(self):
"""测试文件写入功能 - 边界值测试"""
# 创建临时文件测试写入
test_file = self.get_file_path("test_output.txt")
write_result(test_file, 0.85)
# 验证写入内容
content = read_file(test_file)
self.assertEqual(content.strip(), "0.8500")
# 清理临时文件
if os.path.exists(test_file):
os.remove(test_file)`
文本处理模块测试
def test_text_processing_original(self):
"""测试原文文本处理 - 功能完整性测试"""
file_path = self.get_file_path("orig.txt")
if not os.path.exists(file_path):
self.skipTest("orig.txt 文件不存在")
content = read_file(file_path)
processed = self.processor.process(content)
# 验证处理结果类型和有效性
self.assertIsInstance(processed, str)
self.assertGreater(len(processed), 0)
print("原文处理后长度:", len(processed))
def test_text_processing_edge_cases(self):
"""测试文本处理边界情况 - 边界值测试"""
# 测试空文本
empty_result = self.processor.process("")
self.assertEqual(empty_result, "")
# 测试纯标点文本
punctuation_result = self.processor.process("!@#¥%……&*()")
self.assertEqual(punctuation_result, "")
# 测试英文文本
english_result = self.processor.process("Hello World")
self.assertIn("Hello", english_result)
相似度计算模块测试
def test_similarity_calculation_methods(self):
"""测试相似度计算方法 - 算法正确性测试"""
text1 = "这是一个测试文本"
text2 = "这是另一个测试文本"
similarity = self.calculator.calculate_cosine_similarity(text1, text2)
# 验证结果范围和类型
self.assertIsInstance(similarity, (int, float))
self.assertGreaterEqual(similarity, 0.0)
self.assertLessEqual(similarity, 1.0)
print(f"相似度计算成功: {similarity:.4f}")
def test_similarity_edge_cases(self):
"""测试边界情况 - 特殊场景测试"""
# 测试空文本
empty_similarity = self.calculator.calculate_cosine_similarity("", "")
self.assertEqual(empty_similarity, 1.0)
# 测试完全不同文本
text1 = "这是第一个文本"
text2 = "这是完全不同的第二个文本"
similarity = self.calculator.calculate_cosine_similarity(text1, text2)
self.assertGreaterEqual(similarity, 0.0)
self.assertLessEqual(similarity, 1.0)
# 测试完全相同文本
same_similarity = self.calculator.calculate_cosine_similarity("相同文本", "相同文本")
self.assertAlmostEqual(same_similarity, 1.0, places=2)
测试覆盖率截图
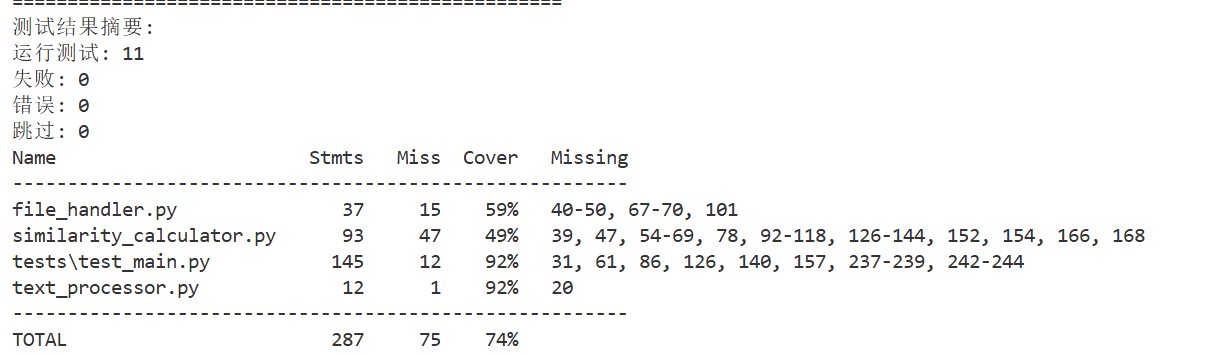
六.计算模块部分异常处理说明
FileHandler 模块的异常处理
该测试模拟了用户输入错误文件路径或文件被移动 / 删除的情况。当系统无法找到指定文件时,会抛出FileNotFoundError并显示类似 "文件未找到: nonexistent_file.txt" 的错误信息,使用户能够立即意识到是文件路径问题,从而检查路径是否正确或文件是否存在。
def test_file_reading_nonexistent_file(self):
"""测试读取不存在的文件"""
with self.assertRaises(FileNotFoundError):
read_file(self.get_file_path("nonexistent_file.txt"))
PermissionError 处理
当系统尝试读取或写入文件但没有足够权限时,触发此异常。异常处理逻辑会明确指出是权限问题,而非一般性的 I/O 错误。
def test_write_permission_denied(self):
"""测试向无写入权限的位置写入文件"""
# 尝试向系统目录写入文件(通常没有权限)
with self.assertRaises(PermissionError):
write_result("/system/prohibited_area/result.txt", 0.85)
UnicodeDecodeError 处理
当系统使用检测到的编码格式无法正确解析文件时,会依次尝试多种常见编码格式(如 gbk、gb2312、utf-16 等)进行解码。如果所有尝试都失败,才抛出异常。
def test_encoding_detection(self):
"""测试系统对不同编码文件的处理能力"""
# 创建不同编码的测试文件
test_files = [
("test_utf8.txt", "utf-8", "这是一个UTF-8编码的测试文件"),
("test_gbk.txt", "gbk", "这是一个GBK编码的测试文件"),
("test_big5.txt", "big5", "這是一個BIG5編碼的測試文件")
]
for filename, encoding, content in test_files:
file_path = self.get_file_path(filename)
# 写入不同编码的文件
with open(file_path, 'w', encoding=encoding) as f:
f.write(content)
# 尝试读取文件(不指定编码)
read_content = read_file(file_path)
self.assertEqual(read_content.strip(), content.strip())
# 清理测试文件
os.remove(file_path)
IOError 处理
对于磁盘错误、网络文件访问中断、文件被占用等 I/O 相关问题,统一归类为IOError进行处理
def test_file_locked_access(self):
"""测试访问被锁定的文件"""
test_file = self.get_file_path("locked_file.txt")
# 创建并锁定文件
with open(test_file, 'w') as f:
f.write("测试内容")
# 在Windows系统上锁定文件
if os.name == 'nt':
import msvcrt
msvcrt.locking(f.fileno(), msvcrt.LK_LOCK, 10)
# 尝试读取被锁定的文件
with self.assertRaises(IOError):
read_file(test_file)
msvcrt.locking(f.fileno(), msvcrt.LK_UNLCK, 10)
os.remove(test_file)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号