
数据采集与融合技术_实验二
-
作业①:
1)天气预报信息的爬取
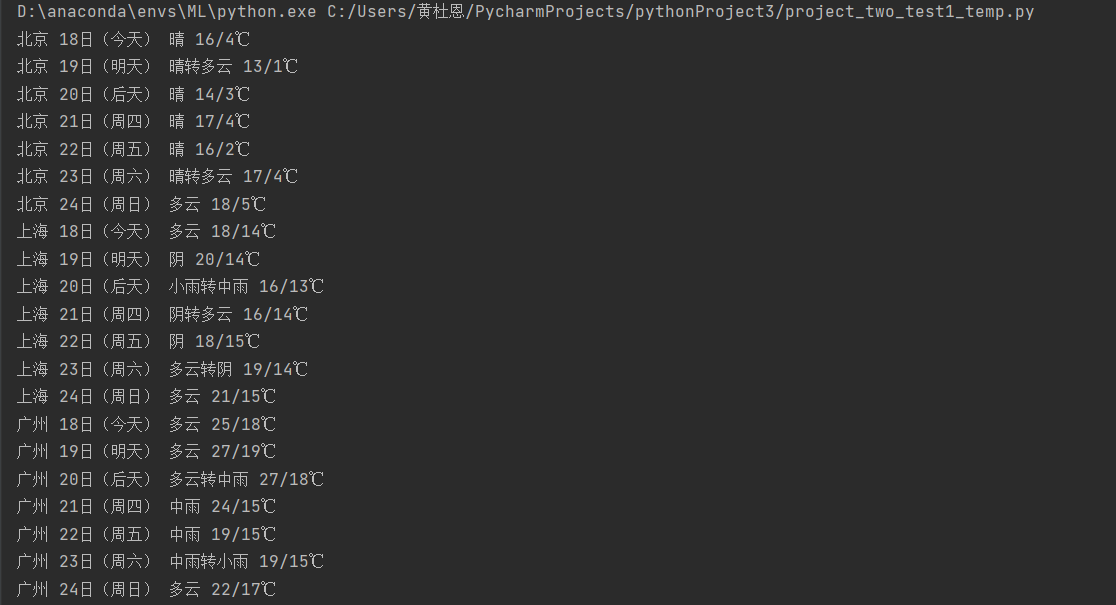
– 要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
– 输出信息:
| 序号 | 地区 | 日期 | 天气信息 | 温度 |
|---|---|---|---|---|
| 1 | 北京 | 七日(今天) | 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 | 31℃/17℃ |
完成过程(由于本题是代码复现,以下操作是个人爬取信息练手):
1.向页面发送请求,获取源代码:
headers = {}
url = 'http://www.weather.com.cn/weather/101230101.shtml'
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=10)
data = data.read()
data = data.decode() # 使用urllib库打开url链接获取相应信息同时解码
2.利用正则表达式匹配数据并存入相应列表:
pat = r'<ul class="t clearfix">(.*?)</ul>'
reg = re.compile(pat, re.S)
mat = reg.findall(data, re.DOTALL) # 使用正则表达式一级过滤
for line in mat:
res_date = r'<h1>(.*?)</h1>'
res_inf = r'<p title=.*? class="wea">(.*?)</p>'
res_tem1 = r'<span>(.*?)</span>/<i>'
res_tem2 = r'/<i>(.*?)</i>'
date = re.findall(res_date, line, re.S | re.M)
inf = re.findall(res_inf, line, re.S | re.M)
tem1 = re.findall(res_tem1, line, re.S | re.M)
tem2 = re.findall(res_tem2, line, re.S | re.M)
3.处理列表元素并打印:
print("{:^10}\t{:^9}\t{:^8}\t{:^9}\t{:^9}".format("序号", "地区", "日期", "天气信息", "温度")) # 打印表头
for i in range(len(date)): # 打印获取的信息
date[i] = date[i].strip() # 对每个列表中的元素去除空格和换行符
inf[i] = inf[i].strip()
tem1[i] = tem1[i].strip()
tem2[i] = tem2[i].strip()
print("{:^10}\t{:^5}\t{:^10}\t{:^12}\t{:^3}\t{:^3}".format(i + 1, "福州", date[i], inf[i], tem1[i], tem2[i]))
4.输出结果展示:
5.原题代码复现运行结果展示:
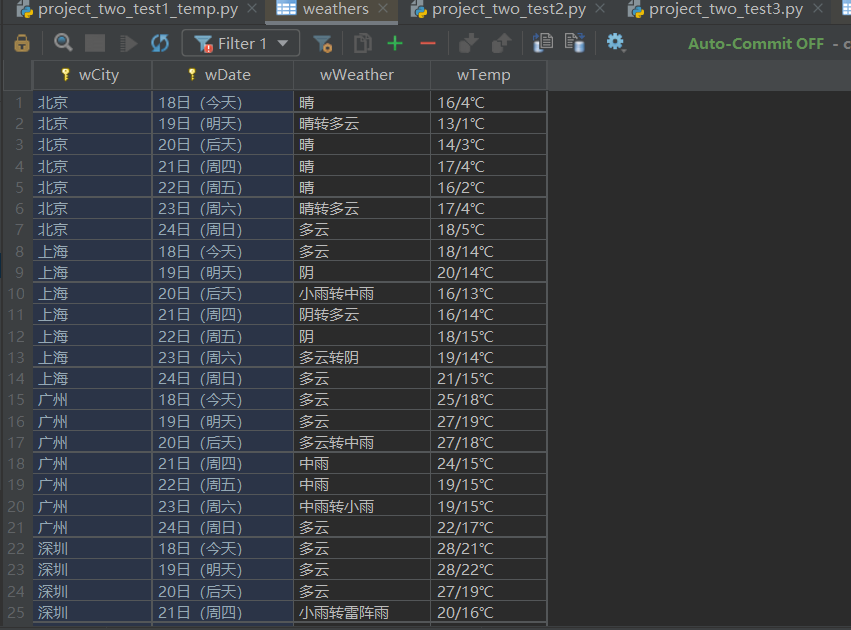
6.数据库存储结果展示:
7.个人编写爬虫地址(无数据库操作):https://gitee.com/huang-dunn/crawl_project/blob/master/实验二作业1/project_two_test1.py
8.原题复现代码地址:https://gitee.com/huang-dunn/crawl_project/blob/master/实验二作业1/project_two_test1_copy.py
2)心得体会:本题加深了个人对于正则表达式的运用,同时也初步理解了数据库的相关编程以及掌握了Database Navigator插件的使用。
-
作业②
1)爬取股票信息
– 要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并保存在数据库。
– 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
– 技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。
– 根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
– 参考链接:https://zhuanlan.zhihu.com/p/50099084
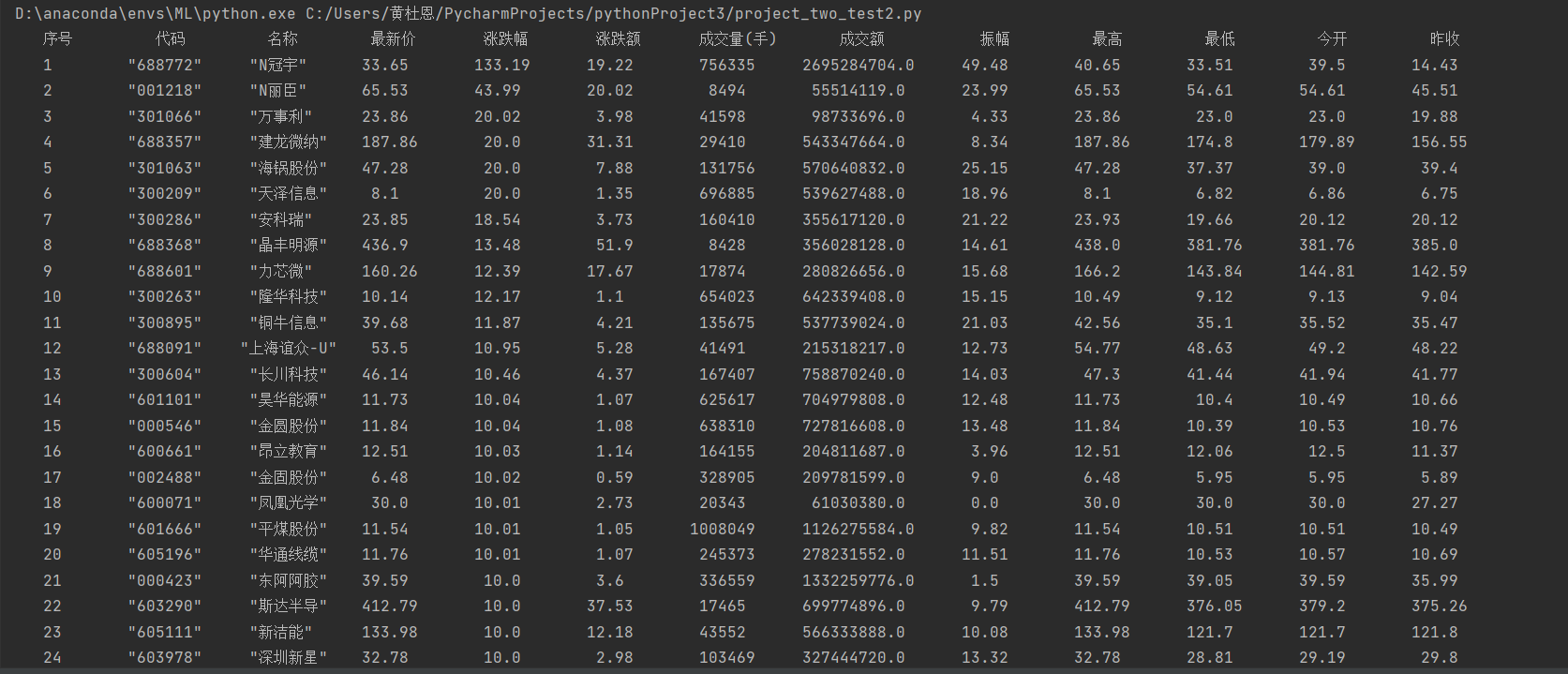
– 输出信息
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2 | ...... |
完成过程:
1.向页面发送请求,获取源代码:
url = 'http://91.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124034597017477158265_1634133416030&pn=' \
+ str(i) + \
'&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,' \
'm:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,' \
'f152&_=1634133416034 ' # 翻页处理
ky = {}
r = requests.get(url, headers=ky)
r.encoding = 'utf-8'
html = r.text
2.利用正则表达式匹配数据并存入相应列表:
pat = r'"[f][0-9]{1,3}":(.*?),'
data = re.compile(pat, re.S).findall(html) # 正则表达式筛选信息
3.处理列表元素并打印:
for k in range(0, len(data) + 1, 31):
j = k - 1
print(
"{:^8}\t{:^8}\t{:^8}\t{:^8}\t{:^8}\t{:^8}\t{:^8}\t{:^12}\t{:^8}\t{:^8}\t{:^8}\t{:^8}\t{:^8}".format
(temp, data[j + 12], data[j + 14], data[j + 2], data[j + 3], data[j + 4], data[j + 5],
data[j + 6], data[j + 7], data[j + 15], data[j + 16], data[j + 17], data[j + 18]))
4.输出结果展示:
5.创建数据库:
self.cursor.execute(
"create table informs (序号 varchar(16), 代码 varchar(16), 名称 varchar(16), 最新价 varchar(16), 涨跌幅 varchar("
"16), 涨跌额 varchar(16), 成交量 varchar(16), 成交额 varchar(16), 振幅 varchar(16), 最高 varchar(16), "
"最低 varchar(16),今开 varchar(16),昨收 varchar(16), constraint pk_informs primary key (代码))")
6.插入相关数据于数据库:
self.cursor.execute("insert into informs (序号, 代码, 名称, 最新价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低,今开,昨收) "
"values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(x1, x2, x3, x4, x5, x6, x7, x8, x9, x10, x11, x12, x13))
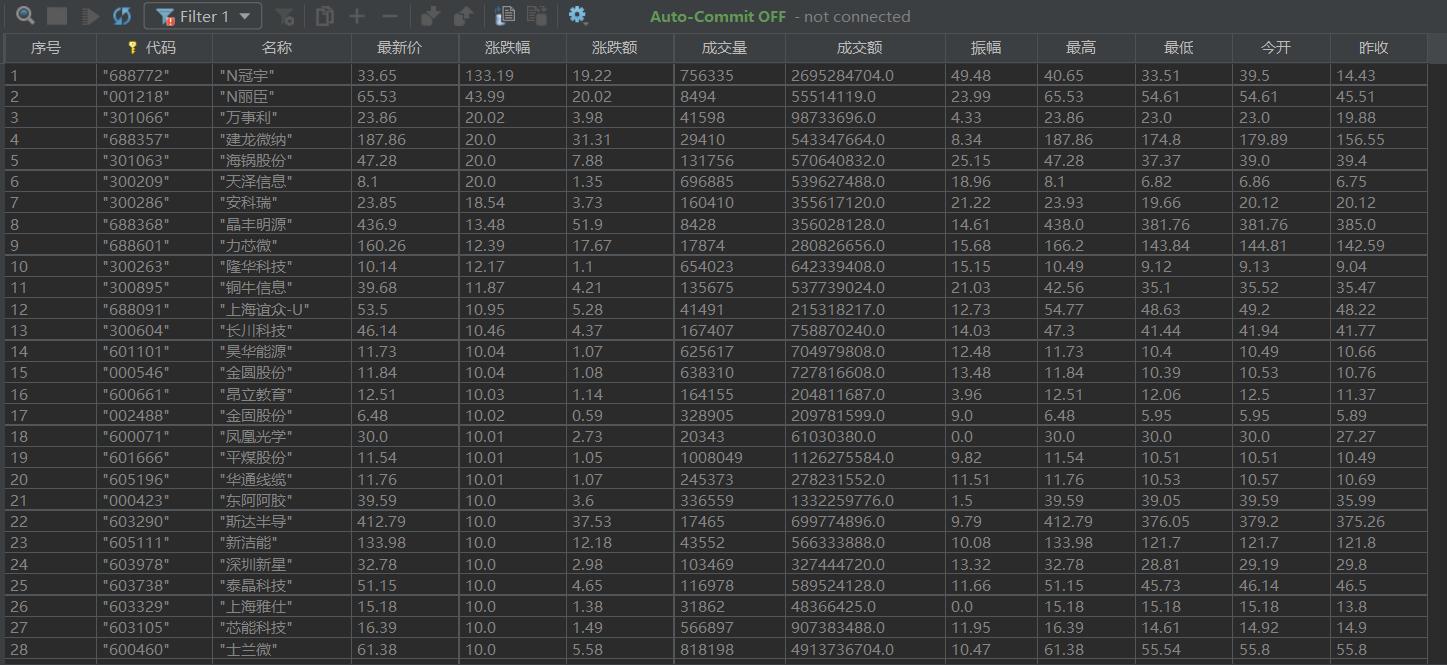
7.数据库存储结果展示:
8.相关代码链接:https://gitee.com/huang-dunn/crawl_project/blob/master/实验二作业2/project_two_test2.py
2)心得体会:通过此题的程序编写,我对sqlite3的使用更加的熟练同时也初次尝试了爬取json格式的信息。
-
作业③
1)爬取股票信息
– 要求: 爬取中国大学2021主榜 https://www.shanghairanking.cn/rankings/bcur/2021
– 所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
– 技巧: 分析该网站的发包情况,分析获取数据的api
– 输出信息:
| 排名 | 学校 | 总分 |
|---|---|---|
| 1 | 清华大学 | 969.2 |
GIF图(分析js文件过程):
其中开头的字符对应末尾的字符,可创建字典进行解决
完成过程:
1.向页面发送请求,获取源代码:
url = 'https://www.shanghairanking.cn/_nuxt/static/1632381606/rankings/bcur/202111/payload.js'
ky = {}
r = requests.get(url, headers=ky)
r.encoding = 'utf-8'
html = r.text
2.利用正则表达式匹配数据存入相应列表并创建字典:
key = [], val = []
pat1 = r'function(\(.*?)\)' # 正则表达式筛选信息
data1 = re.compile(pat1, re.S).findall(html)
data1 = re.split(',', str(data1))
for line in data1:
line = line.replace("'", '').replace("[", '').replace("]", '').replace("(", '') # 处理数据格式
key.append(line)
pat2 = r'}}\((.*?)\)\)\);$' # 正则表达式筛选信息
data2 = re.compile(pat2, re.S).findall(html)
data2 = re.split(',', str(data2))
for line in data2:
line = line.replace('"', '').replace("'", '').replace("]", '') # 处理数据格式
val.append(line)
del (val[0]) # 第一个元素是括号没有有效信息直接删除
dic = dict(map(lambda x, y: [x, y], key, val)) # 创建字典
3.利用正则表达式匹配数据并存入相应列表:
pat3 = r',univData:\[(.*?)\}\]'
data3 = re.compile(pat3, re.S).findall(html)
pat_name = r'univNameCn:"(.*?)"'# 正则表达式筛选信息
pat_rank = r'ranking:(.*?),'
pat_grade = r'score:(.*?),'
name = re.compile(pat_name, re.S).findall(str(data3))
rank = re.compile(pat_rank, re.S).findall(str(data3))
grade = re.compile(pat_grade, re.S).findall(str(data3))
4.处理列表元素,若元素出现于字典就将其翻译,同时打印结果:
print("{:^15}\t{:^15}\t{:^15}".format("排名", "学校", "总分")) # 打印表头
for i in range(len(name)):
if rank[i] in dic:
rank[i] = dic[rank[i]]
if grade[i] in dic:
grade[i] = dic[grade[i]]
print("{:^15}\t{:^20}\t{:^15}".format(rank[i].strip(), name[i].strip(), grade[i].strip()))
5.输出结果展示:
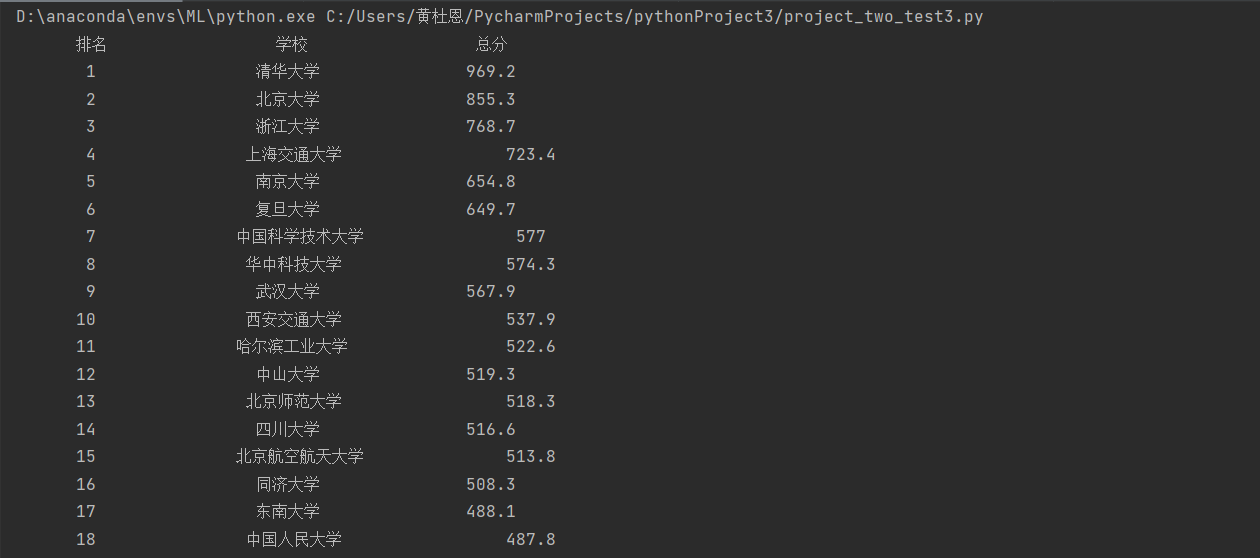
6.创建数据库:
self.cursor.execute(
"create table schools (rank varchar(64),name varchar(64),grade varchar(64),constraint pk_school primary key (name))")
7.插入相关数据于数据库:
self.cursor.execute("insert into schools (rank, name, grade) values (?,?,?)",
(rank, name, grade))
8.数据库存储结果展示:
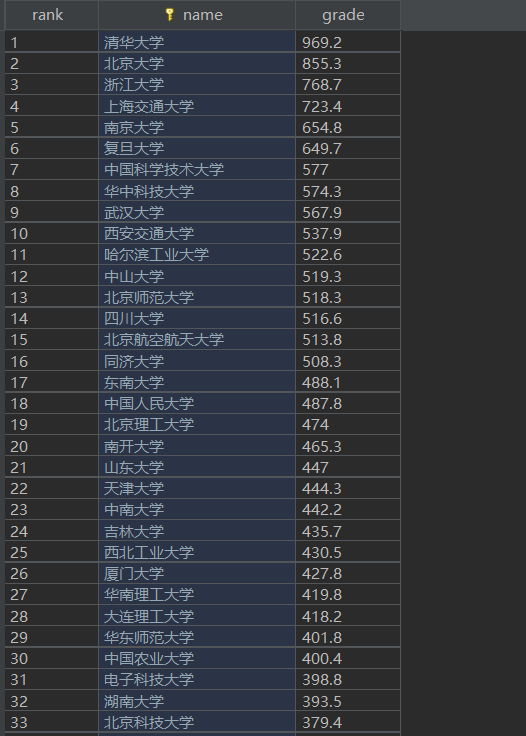
9.相关代码链接:https://gitee.com/huang-dunn/crawl_project/blob/master/实验二作业3/project_two_test3.py

