Large-scale Parallel Collaborative Filtering for the Netflix Prize
http://www.hpl.hp.com/personal/Robert_Schreiber/papers/2008%20AAIM%20Netflix/netflix_aaim08(submitted).pdf MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS
-------------------------------------------------
MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS
recommender systems are based
on one of two strategies.
推荐系统基于两种策略:
1)基于内容的过滤方法对每个用户或产品创建一个模板;当然需要的额外信息可能很难得到。
The content filtering approach
creates a profile for each user or product to characterize
its nature. Of course,
content-based strategies require gathering external information
that might not be available or easy to collect.
2)另一种是依赖于用户过去的行为,而不需要创建具体的模板。这种方法就是协同过滤。
An alternative to content filtering relies
only on past user behavior—for example,
previous transactions or product ratings—
without requiring the creation of explicit
profiles. This approach is known as collaborative
filtering, a term coined by the
developers of Tapestry, the first recommender
system. While generally more accurate than
content-based techniques, collaborative
filtering suffers from what is called the cold
start problem, due to its inability to address
the system’s new products and users. In this aspect,
content filtering is superior.
协同过滤的主要方向有基于邻近的方法和基于隐藏因子的模型
The two primary areas of collaborative filtering are the
neighborhood methods and latent factor models
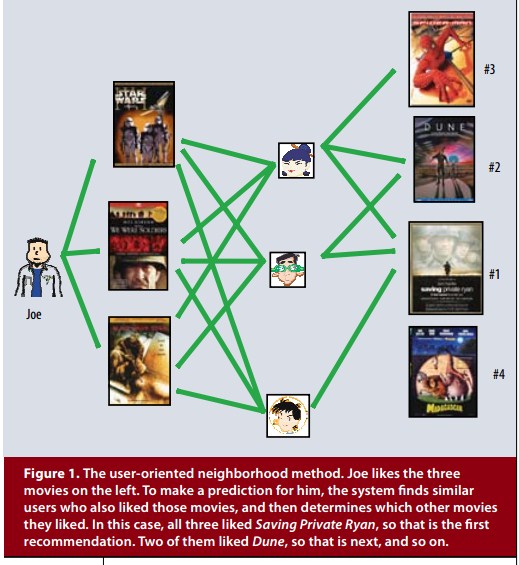
基于邻近的方法围绕着如何计算商品或者用户的关系。基于商品的方法评估一个用户对一个商品的偏好,是通过判断这个用户对”相似“商品的评分得到的;
Neighborhood
methods are centered on computing the relationships
between items or, alternatively, between users. The item-oriented
approach evaluates a user’s preference for an
item based on ratings of “neighboring” items by the same
user.
隐藏因子模型是另一种从商品和用户两方面同时解释评分特点的方法。
Latent factor models are an alternative approach
that tries to explain the ratings by characterizing both
items and users on, say, 20 to 100 factors inferred from
the ratings patterns
推荐系统依赖于不同类型的数据输入,且数据经常一个矩阵中,其中一个维度代表用户,另一个维度代表商品。一种强有力的矩阵分解方法应该是能融合额外的信息,当没有显示的的反馈时,可以通过隐式反馈来推断用户的偏好。
Recommender systems rely on different types of
input data, which are often placed in a matrix with one
dimension representing users and the other dimension
representing items of interest.
One strength of matrix factorization is that it allows
incorporation of additional information. When explicit
feedback is not available, recommender systems can infer
user preferences using implicit feedback
A BASIC MATRIX FACTORIZATION MODEL
矩阵分解模型将商品和用户都映射到一个f维度的隐藏因子空间,因此用户-产品的交互被一个内积所表示在这个空间内。
公式(1)为用户u对商品i的评分。


这个模型很像奇异值分解模型(SVD),但是由于矩阵的稀疏性,使用SVD很容易使得一些有用信息丢失。最近的研究更倾向于直接使用评分,同时使用一个调控参数来避免过度拟合。如公式(2)即为我们要优化的目标函数。

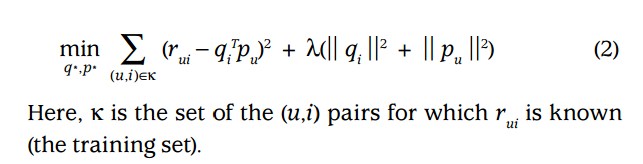
LEARNING ALGORI
学习算法:
1)随机梯度下降,这是一个古老而简单的算法,非主题,不展开。。

2) 交替最小方差算法。
对于公式(2),由于存在两个变量,所以它不是一个凸函数(如果看过机器学习的教科书,会发现最常用的优化方法就是目标函数是一个凸函数,然后通过寻找一阶导数或二阶导数为0来得到最小值;其中,最简单的是二次方程,也就是我们说的抛物线,只要寻找一阶导数为0即可)。但是如果固定其中一个变量,那么另一个变量就是一个二次方程了。所以我们可以交替的固定p、q这两个变量(商品和用户),每次优化一次变量,反复进行。
梯度下降的算法计算效率比较高,但是我们至少有两个原因使用ALS:
1)ALS更容易并行化;
2)ALS对于处理隐式数据更方便;(这里的cannot be considered sparse应该是笔误了,数据应该是稀疏的)。

到这里,有关ALS的主要内容已经完整了,后面部分的论文都是讲如何处理动态变化的数据的,属于具体问题要具体分析的部分。
ADDING BIASE 添加偏好

公式(3)将评分标识为 用户的平局评分+用户的评分偏好+用户u对商品i的评分。
于是公式(1)+(3)=》(4)

软后将公式(4)代入公式 (2)得到公式(5)

ADDITIONAL INPUT SOURCE
为了解决冷启动问题,ALS需要支持外部数据导入。假设N(u)是用户u对一个商品集合表现出的偏好。。和其他一些偏好,统统都要在处理之后累加到用户u的偏好中。于是由公式(4)中的p(u)加上这些输入的用户偏好后,得到公式(6)


TEMPORAL DYNAMIC
此外,还要考虑用户和商品特征随时间的动态变化。于是公式(4)加上时间变量,就得到公式(7)
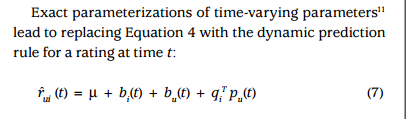
INPUTS WITH VARYING CONFIDENCE LEVELS
有时不同的评分结果的可信度是不相同的,所以要使用不同的权重对他们加以区分。ALS很容易添加一个可信度矩阵C[u,i]来对用户对某个商品的评分加上一个权重。于是公式(5)转变成了公式(8)。


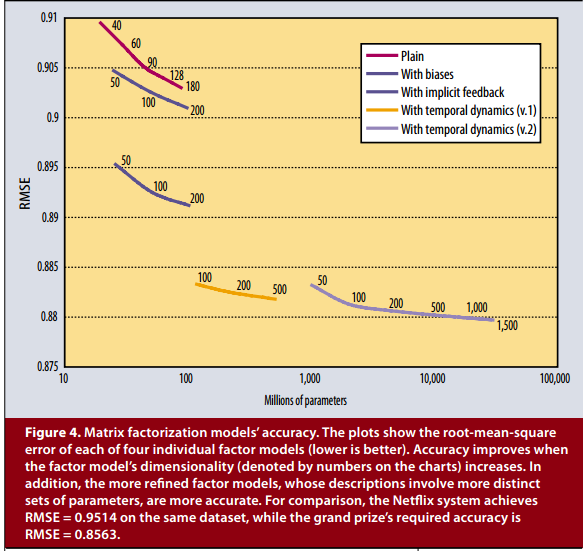
最后一个图,说明了组合不同的参数,不同的学习算法,更容易预测得更准确。