
使用PyTorch简单实现卷积神经网络模型
这里我们会用 Python 实现三个简单的卷积神经网络模型:LeNet 、AlexNet 、VGGNet,首先我们需要了解三大基础数据集:MNIST 数据集、Cifar 数据集和 ImageNet 数据集
三大基础数据集
MNIST 数据集
MNIST数据集是用作手写体识别的数据集。MNIST 数据集包含 60000 张训练图片,10000 张测试图片。其中每一张图片都是 0~9 中的一个数字。图片尺寸为 28×28。由于数据集中数据相对比较简单,人工标注错误率仅为 0.2%。

Cifar 数据集
Cifar 数据集是一个图像分类数据集。分为 Cifar-10 和 Cifar-100 两个数据集。Cifar 数据集中的图片为 32×32 的彩色图片,这些图片是由 Alex Krizhenevsky 教授、Vinod Nair 博士和 Geoffrey Hilton 教授整理的。Cifar-10 数据集收集了来自 10 个不同种类的 60000 张图片,这些种类有:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。在 Cifar-10 数据集上,人工标注的正确率为94%。

ImageNet数据集
ImageNet 数据集是一个大型图像数据集,由斯坦福大学的李飞飞教授带头整理而成。在 ImageNet 中,近 1500 万张图片关联到 WordNet 中 20000 个名次同义词集上。ImageNet 每年举行计算机视觉相关的竞赛, ImageNet 的数据集涵盖计算机视觉的各个研究方向,其用做图像分类的数据集是 ILSVRC2012 图像分类数据集。
ILSVRC2012 数据集的数据和 Cifar-10 数据集一致,识别图像中主要物体,其包含了来自 1000 个种类的 120 万张图片,每张图片只属于一个种类,大小从几千字节到几百万字节不等。卷积神经网络也正是在此数据集上一战成名。

三种经典的卷积神经网络模型
三种经典的卷积神经网络模型:LeNet 、AlexNet 、VGGNet。这三种卷积神经网络的结构不算特别复杂,下面使用 PyTorch 进行实现
LeNet模型
LeNet 具体指的是 LeNet-5。LeNet-5 模型是 Yann LeCun 教授于 1998 年在论文 Gradient-based learning applied to document recognition 中提出的,它是第一个成功应用于数字识别问题的卷积神经网络。在 MNIST 数据集上,LeNet-5 模型可以达到大约 99.2% 的正确率。LeNet-5 模型总共有7层,包括有2个卷积层,2个池化层,2个全连接层和一个输出层,下图展示了 LeNet-5 模型的架构。
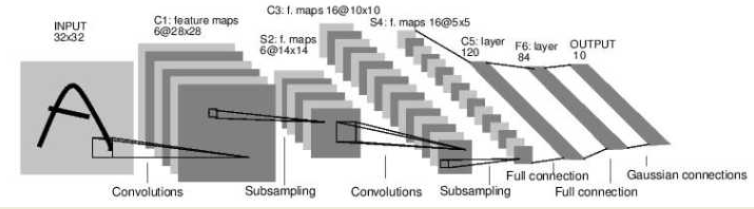
使用 PyTorch 实现


class LeNet(nn.Module): def __init__(self): super(LeNet, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16*5*5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): out = F.relu(self.conv1(x)) out = F.max_pool2d(out, 2) out = F.relu(self.conv2(out)) out = F.max_pool2d(out, 2) out = out.view(out.size(0), -1) out = F.relu(self.fc1(out)) out = F.relu(self.fc2(out)) out = self.fc3(out) return out
AlexNet模型
Alex Krizhevsky 提出了卷积神经网络模型 AlexNet。AlexNet 在卷积神经网络上成功地应用了 Relu,Dropout 和 LRN 等技巧。在 ImageNet 竞赛上,AlexNet 以领先第二名 10% 的准确率而夺得冠军。成功地展示了深度学习的威力。它的网络结构如下:
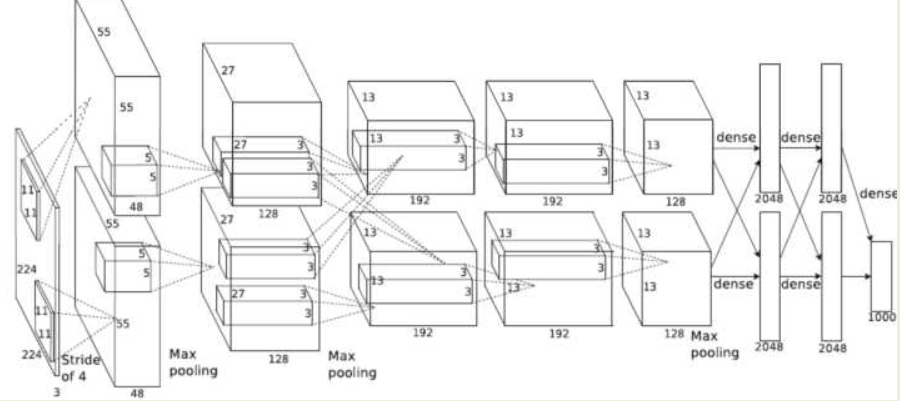
由于当时GPU计算能力不强,AlexNet使用了两个GPU并行计算,现在可以用一个GPU替换。以单个GPU的AlexNet模型为例,包括有:5个卷积层,3个池化层,3个全连接层。其中卷积层和全连接层包括有relu层,在全连接层中还有dropout层。具体参数的配置可以看下图
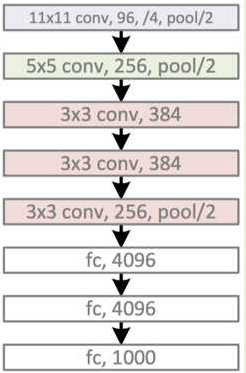
使用 PyTorch 实现
class AlexNet(nn.Module): def __init__(self, num_classes): super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 256, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), ) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) x = x.view(x.size(0), 256 * 6 * 6) x = self.classifier(x) return x
VGGNet模型
VGGNet是牛津大学计算机视觉组和Google DeepMind公司的研究人员一起研发的一种卷积神经网络。通过堆叠3×3 的小型卷积核和2×2的最大池化层,VGGNet成功地构筑了最深达19层的卷积神经网络。由于VGGNet的拓展性强,迁移到其他图片数据上的泛化性比较好,可用作迁移学习。
下图为 VGG16 的整体架构图
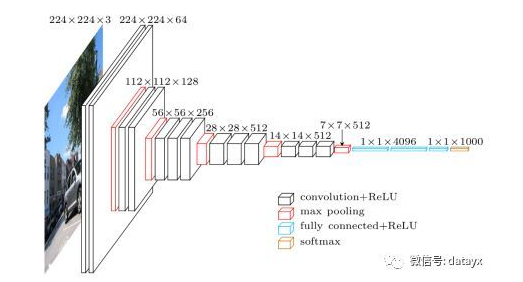
从左至右,一张彩色图片输入到网络,白色框是卷积层,红色是池化,蓝色是全连接层,棕色框是预测层。预测层的作用是将全连接层输出的信息转化为相应的类别概率,而起到分类作用。
可以看到 VGG16 是13个卷积层+3个全连接层叠加而成。
使用 PyTorch 实现
cfg = { 'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], 'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], 'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], 'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'], } class VGG(nn.Module): def __init__(self, vgg_name): super(VGG, self).__init__() self.features = self._make_layers(cfg[vgg_name]) self.classifier = nn.Linear(512, 10) def forward(self, x): out = self.features(x) out = out.view(out.size(0), -1) out = self.classifier(out) return out def _make_layers(self, cfg): layers = [] in_channels = 3 for x in cfg: if x == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1), nn.BatchNorm2d(x), nn.ReLU(inplace=True)] in_channels = x layers += [nn.AvgPool2d(kernel_size=1, stride=1)] return nn.Sequential(*layers)
VGG16 是基于大量真实图像的 ImageNet 图像库预训练的网络
VGG16 对应的供 keras 使用的模型人家已经帮我们训练好,我们将学习好的 VGG16 的权重迁移(transfer)到自己的卷积神经网络上作为网络的初始权重,这样我们自己的网络不用从头开始从大量的数据里面训练,从而提高训练速度。这里的迁移就是平时所说的迁移学习。
from keras.models import Sequential from keras.layers.core import Flatten, Dense, Dropout from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D from keras.optimizers import SGD import cv2, numpy as np def VGG_16(weights_path=None): model = Sequential() model.add(ZeroPadding2D((1, 1), input_shape=(3, 244, 244))) # 卷积输入层指定输入图像大小(网络开始输入(3,224,224)的图像数据,即一张宽224,高244的彩色RGB图片) model.add(Convolution2D(64, 3, 3, activation='relu')) # 64个3*3的卷积核,生成64*244*244的图像 model.add(ZeroPadding2D(1, 1)) # 补0,(1, 1)表示横向和纵向都补0,保证卷积后图像大小不变,可以用padding='valid'参数代替 model.add(Convolution2D(64, 3, 3, activation='relu')) # 再次卷积操作,生成64*244*244的图像,激活函数是relu model.add(MaxPooling2D((2, 2), strides=(2, 2))) # pooling操作,相当于变成64*112*112,小矩阵是(2,2),步长(2,2),指的是横向每次移动2格,纵向每次移动2格。 # 再往下,同理,只不过是卷积核个数依次变成128,256,512,而每次按照这样池化之后,矩阵都要缩小一半。 model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(128, 3, 3, activation='relu')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(128, 3, 3, activation='relu')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) # 128*56*56 model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation='relu')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation='relu')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(256, 3, 3, activation='relu')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) # 256*28*28 model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) # 512*14*14 model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(ZeroPadding2D((1, 1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(MaxPooling2D((2, 2), strides=(2, 2))) # 128*7*7 # 13层卷积和池化之后,数据变成了512 * 7 * 7 model.add(Flatten) # 压平上述向量,变成一维512*7*7=25088 # 三个全连接层 ''' 4096只是个经验值,其他数当然可以,试试效果,只要不要小于要预测的类别数,这里要预测的类别有1000种, 所以最后预测的全连接有1000个神经元。如果你想用VGG16 给自己的数据作分类任务,这里就需要改成你预测的类别数。 ''' model.add(Dense(4096, activation='relu')) # 全连接层有4096个神经元,参数个数是4096*25088 model.add(Dropout(0.5)) # 0.5的概率抛弃一些连接 model.add(Dense(4096, activation='relu')) # 全连接层有4096个神经元,参数个数是4096*25088 model.add(Dropout(0.5)) # 0.5的概率抛弃一些连接 model.add(Dense(1000, activation='softmax')) if weights_path: model.load_weights(weights_path) return model # 如果要设计其他类型的CNN网络,就是将这些基本单元比如卷积层个数、全连接个数按自己需要搭配变换,
# 模型需要事先下载 model = VGG_16('vgg16_weights.h5') sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True) model.compile(optimizer=sgd, loss='categorical_crossentropy') # 加载图片 def load_image(img): im = cv2.resize(cv2.imread(img), (224, 224)).astype(np.float32) im[:,:,0] -= 103.939 im[:,:,1] -= 116.779 im[:,:,2] -= 123.68 im = im.transpose((2, 0, 1)) im = np.expand_dims(im, axis=0) return im # 读取vgg16类别的文件 f = open('synset_words.txt', 'r') lines = f.readline() f.close() def predict(url): im = load_image(url) pre = np.argmax(model.predict(im)) print(lines[pre]) # 测试图片 predict('xx.jpg')
参考:https://www.cnblogs.com/wmr95/articles/7814892.html

