
《深入理解计算机系统》阅读笔记--信息的表示和处理(上)
在开始先来看一个有意思的东西:
root@localhost: lldb (lldb) print (500 * 400) * (300 * 200) (int) $0 = -884901888 (lldb) print ((500 * 400)* 300) * 200 (int) $1 = -884901888 (lldb) print ((200 * 500) * 300) * 400 (int) $2 = -884901888 (lldb) print 400 * (200 * (300 * 500)) (int) $3 = -884901888 (lldb)
结果是负数!!!! 这个结果理论上是非常不应该的,这已经违背了我们的常识,毕竟正数的乘积,最后的结果应该还是一个正数,但是这里出现负数的情况,虽然结果不对,但是好在即使我们各种交换顺序,结果都是一致的
我们再来试试浮点数呢
root@localhost: lldb (lldb) print (3.14 + 1e20) - 1e20 (double) $0 = 0 (lldb) print 3.14 + (1e20 - 1e20) (double) $1 = 3.1400000000000001 (lldb)
从结果看浮点数好像也没好到哪里去,也算错了,这个时候你肯定和我一样在想,计算机机计算机,你一个以计算文明著称的东东也计算不对了,也太不靠谱了,其实出现这种情况是有原因的,不知道你小时候有没有和我一样拿着家里的计算器上让几个非常的大的数连着相乘,最后发现结果也是现实的乱七八糟,还给你不停的报错误错误,哎想想当时如果多思考思考,去探究探究说不定自己早已经成为大神了,哈哈哈.....
言归正传,计算机是用有限数量的为来对一个数字编码的,所以当结果太大以至于不能表示时,运算就会出现类似上面两种情况的错误,这里称为溢出(这里先有一个概念)。
整数运算和浮点运算会有不同的数学属性是因为它们处理数字表示有限性的方式不同。整数的表示虽然只能编码一个相对小的数值范围,但是这种表示是精确的,浮点数虽然可以编码一个较大的数值范围,但是这种表示是近似的
由上面这个小问题来引出这次的内容,来好好探究探究操作系统是如何在表示和处理这些信息,为什么会出现溢出,为什么会计算错误,如何在自己以后写代码的过程中避免一些潜在的问题,让自己写出更高质量的代码
我们学习一门开发语言的时候,开始学习基础语法的时候都会学习各种数据类型,这些数据类型在系统中又是如何存储的呢?接着往下看。
信息的存储
二进制 十六进制 十进制
这里关于十进制和十六进制的转换有一个挺有意思的地方:
当值x是2的非负整数n次幂时,也就是x = 2n,可以非常容易的将x写成十六进制形式
其实我们看这个时候x的二进制就是1后面跟了n个0,而十六进制数字0表示4个二进制0
先来看看几个转换:
当x = 32 即32 = 2^5, 5 = 4*1 + 1 转换成十六进制为0x20
当x = 64 即64 = 2^6, 6 = 4*1 + 2 转换为十六进制为0x40
当x = 128 即128 = 2^7 7 = 4*1 + 3 转换为十六进制为0x80
当x = 256 即 256 = 2^8 8 = 4*2 + 0 转换为十六进制为0x100
当x = 512 即 512 = 2^9 9 = 4*2 +1 转换为十六进制为0x200
当x = 1024 即 1024 = 2^10 10 = 4*2 + 2 转换为十六进制为0x400
所以从上面的规律可以将公式总结为i+4j j就是后面0的个数,而最前的数就是2的i次方
字数据大小
字长,指明指针数据的标称大小,虚拟地址是以这样一个字来编码的,字长决定了虚拟地址空间的最大大小。
我们老是听到别人说系统是32位,系统是64位的,其实就是和这个相关,如果是32位的机器虚拟地址的范围为:
0-2^32-1 程序最多访问2^32个字节,64位同理,这里你也就明白了64位能够支持更大的内存空间,32位字长限制虚拟地址空间为4千兆字节即4GB,这也是早起很多电脑的标配,因为32位的系统,你安装再多的内存,你右键电脑属性,看到识别的依然只是不到不到4GB,而64位的虚拟地址空间为16EB,所以你能支持更多的内存。
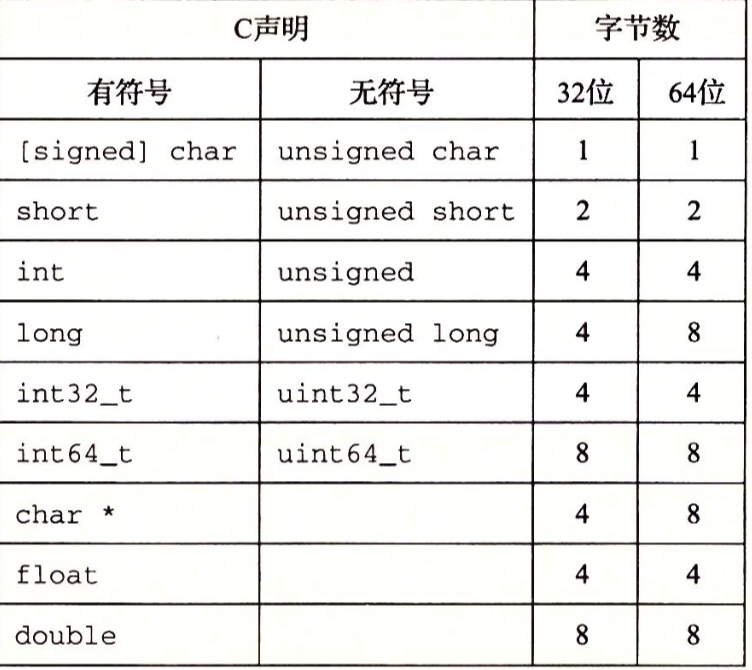
上图是32位和64位典型值,整数或者有符号的,即可以表示负数,零和正数;无符号的只能表示非负数
寻址和字节顺序
在大多数计算器上,对于多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址,这里有个例子假设一个int的变量x的地址为0x100 也就是地址表达式&x 的值为0x100 那么x的4个字节将被存储在内存0x100,0x101,0x102和0x013位置
而这个地址就涉及到一个概念就是寻址的问题,这里两种方式:大端法和小端法
假设变量x 的类型为int, 位于地址0x100 它的十六进制值为0x01234567 地址范围0x100-0x103的字节序列两种寻址方式如下图表示:
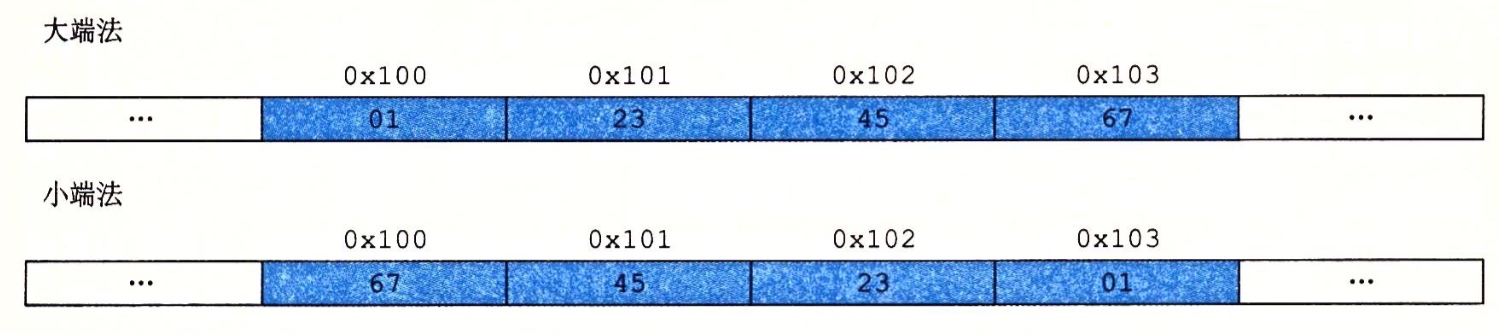
大端法和小端法 对我们大多数程序员其实是不可见的,我们也很少关心这个东西,但是在以下三种情况是需要注意的:
第一种:不同类型的机器之间通过网络传递二进制数据时,也就是当小端法机器给大端法机器发数据或者返回来发送数据,在接收数据的时候,字节顺序对接收者来说都是反的,所以为了避免这个问题出现,网络应用程序的代码编写应该遵守已经建立的关于字节顺序的规则
第二种:主要是于都表示整数数据的字节序列时字节顺序也是非常重要,主要发生在检查机器级程序时。
第三种:当编写规避正常的类型系统的程序时。在C语言中通常会使用强制类型转换cast或者联合union来允许一种数据引用一个对象,而这种数据类型与创建这个对象时定义的数据类型是不同的。
其实上面三种情况我们作为一名普通的开发者也很少回去关注,毕竟高级语言已经对做了更高级的抽象,同时替我们也做了很多事情来规避一些错误的发生
在这部分的练习题中有个挺有意思的题:
这里已经计算的出整数3510593的十六进制为0x00359141
而浮点数3510593.0的十六进制为0x4A564504
我们先看看这两个十六进制的二进制表示分别为:
00000000001101011001000101000001
*********************
01001010010101100100010100000100
我们发现中间有星号的部分是完全一样的,并且我们整数的除了最高位1,其他所有位都嵌在浮点数中,这是巧合么,当然不是啦,继续深入研究
表示字符串
C语言中字符串被编码为一个以null其值为0字符结尾的字符数组,每个字符都由某个标准编码来表示
最常见的是ASCII字符编码,使用ASCII码作为字符码的任何系统上都将得到相同的结果,与字节顺序和字大小无关。也正是这样文本数据比二进制数据具有更强的平台独立性
表示代码
其实我们的代码在不同类型的机器上编译时,生成的结果也是不同的,所以你在linux上编译的代码肯定是不能再windows上运行的,反之亦然
布尔代数
与 And:A=1 且 B=1 时,A&B = 1
或 Or:A=1 或 B=1 时,A|B = 1
非 Not:A=1 时,~A=0;A=0 时,~A=1
异或 Exclusive-Or(Xor):A=1 或 B=1 时,AB = 1;A=1 且 B=1 时,AB = 0
对应与集合运算则是交集、并集、差集和补集,假设集合 A 是 {0, 3, 5, 6},集合 B 是 {0, 2, 4, 6},全集为 {0, 1, 2, 3, 4, 5, 6, 7}
& 交集 Intersection {0, 6}
| 并集 Union {0, 2, 3, 4, 5, 6}
^ 差集 Symmetric difference {2, 3, 4, 5}
~ 补集 Complement {1, 3, 5, 7}
逻辑运算
C语言提供了逻辑运算符|| && ! 分别对应命题逻辑中的OR AND NOT 运算
逻辑运算任务所有非零的参数都表示TRUE, 而参数0表示FALSE
逻辑运算符和对应的位级运算的第二个重要区别是:如果对第一个参数求值就能确定表达式结果,那么逻辑运算符就不会对第二个参数求值
位移运算
表达式x << k 表示x想左移动k位 ,x向左边移动k位,丢弃最高的k位,并在有点补k个0
表示是x << k 这个分两种:逻辑右移(左边补0) 和算术右移(右边补符号位)
现在几乎所有的编译器或者机器组合都对有符号使用算术右移面对无符号数,右移必须是逻辑的
整数的表示
我们对整数主要分为:有符号和无符号
先记一些术语:

关于32位程序上C语言以及64位程序上C语言的典型取值范围:
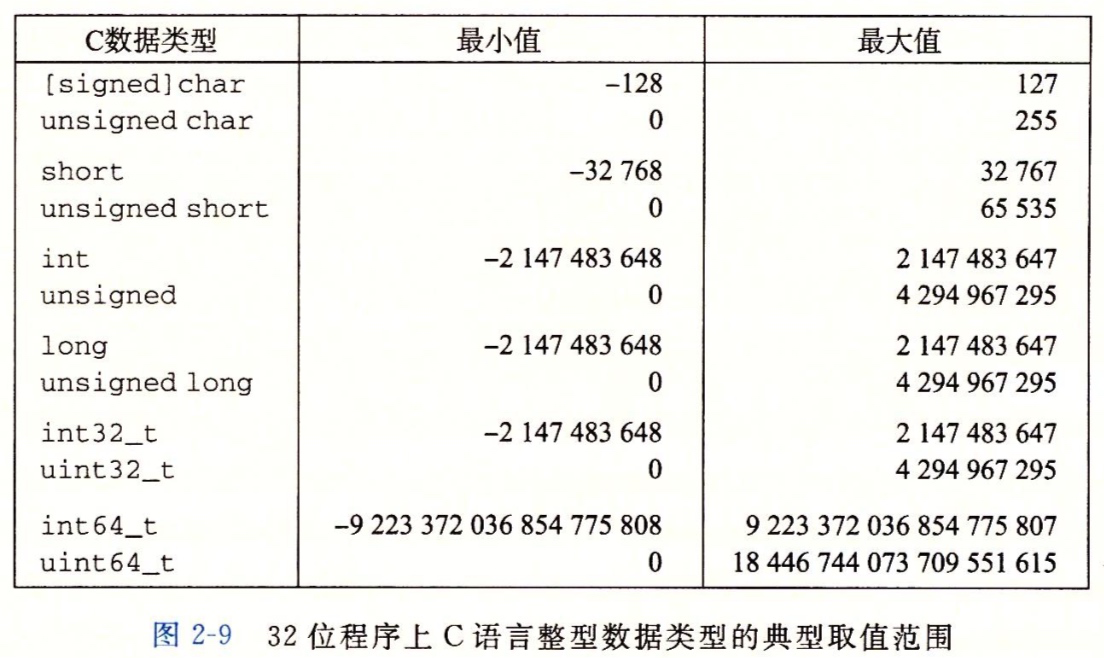

在上面两个图中我们都可以看出负数的范围比正数的范围大1,为啥会这样的,继续往下看
无符号数的编码
下面是几种情况B2U 给出的从为向量到整数的映射
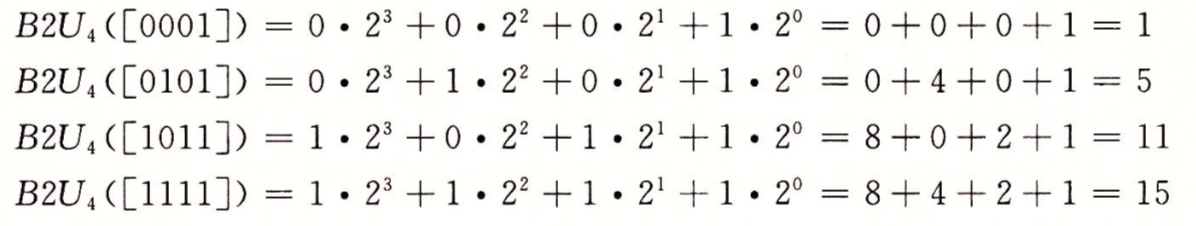
所以我们可以考虑w位所能表示的值的范围,最小值用位向量表示[000...0] ,也就是整数值0
而最大值的表示则是2^w - 1
补码编码
其实在很多时候我们还是希望用到负数,最常见的有符号的计算机表示方式就是补码形式
最高有效位解释为负权 用函数B2T表示补码编码
最高有效位称为符号位,它的权重为-2^w-1 是无符号表示中权重的负数
符号位被设置为1 时,表示为负,当设置为0 时表示为非负,通过下面理解:

这个时候再看补码所能表示的值的范围:
最小值的的位向量为[1000...0] 其整数值为-2^w-1
最大值的位向量为[01111...1] 其整数值为2^w-1 - 1
我们还是以4位表示:
TMin = B2T([1000]) = 2^3 = -8
TMax = B2T([0111]) = 2^2 + 2^1 + 2^0 = 4+2+1 = 7
同无符号表示一样,在可表示的取值范围内的每个数字都有一个唯一的w位的补码编码
这个属性总结为一句话:补码编码的唯一性
小结:其实我们通过上面的无符号的编码和补码编码就可以看出,补码的范围是不对称的
|TMin| = |TMax| + 1
我们学习编程语言的时候,一般在基础部分都会讲到关于整数和负数的表示范围,尤其是强类型语言中
当时总是说负数表示的最大范围一直被-1 当时很多时候老师都会告诉你是因为符号位占了一位,当时可能是一个模糊的概念,为啥是符号位占了一位,从补码的这个概念,其实你就应该完全明白了为啥符号位占了一位
其次这里我们还可以知道一个规律就是无符号数值刚好比补码的最大值的2倍 再加1:UMax = 2TMax + 1

有符号和无符号之间的转换
c语言允许在各种不同的数字数据之间做强制类型转换
其实在c语言中,强制类型的转换的结果是保持位值不变,只是改变了解释这些位的方式
-12345 的16 位补码表示与53191 的16位无符号表示是一样的
上面数字太大了,通过简单的数字来表示,可能更好理解:
对于数字16 ,二进制表示为1111 十六进制表示为0xF
这个时候的UMax 的值为:16,TMin 的值为:-8,Tmax 的值为7
其实这个时候还有一个有意思的点是,如果就是这个4位的话,表示-1 的表示方式:
二进制形式为:1111 发现其实和 最大的无符号数的表示方式是一样的
所以在c语言中,假设我们定义了一个无符号的数 u= 4194967295 ,如果我们通过(int)u 进行强制转换,我们得到的结果就是-1,代码内容如下:
#include <stdio.h> int main() { unsigned u = 4294967295u; int tu = (int)u; printf("u=%u,tu=%d\n",u,tu); return 0; }
程序的打印的结果和我们上面说的是一致的,这里需要知道的是4294967295 这个数字是32位能表示的最大数字,即这个是32位中的Umax
再看一个代码:
#include <stdio.h> int main() { short int v = -12345; unsigned short uv = (unsigned short)v; printf("v = %d, uv = %u\n",v, uv); return 0; }
从执行结果可以看出v = -12345, uv = 53191
从上面的两个例子,都可以看出强制类型转换的结果都是保持位值不变,只是改变了解释这些位的方式
并且我们知道的是-12345 的16位补码表示与53191的16位无符号表示是完全一样的。我们代码中将short强制类型转换为unsigned short 改变了数值,但是不改变位表示
小结:
对于大多数C语言的实现,处理同样的字长的有符号和无符号数之间相互转换的一般规则是:
数值可能会改变,但是位模式不变
这里位是固定的,假设为w位,给定0<=x<=UMax 范围内的一个整数x, 函数U2B 会给出x的唯一的w位无符号表示,同样的,当x满足TMin<=x <=TMax 函数T2B 会给出x的唯一的w位的补码表示
现在将函数T2U 定义为T2U = B2U 也就是这个函数的输入是一个TMin - TMax 的数,而结果得到的是一个0-UMax的值,这里两个数有相同的位模式,除了参数是无符号的,而结果是以补码表示的
同样的对于0-UMax 之间的值x ,定义函数U2T 为U2T = B2T 生成一个数的无符号表示和x的补码表示相同

从上图我们可以看出T2U(-12345) = 53191 并且 U2T(53191) = -12345
所以十六进制表示写作0xCFC7 的16位位模式及时-12345的补码表示,又是53191的无符号表示。同时我们需要注意12345 + 53191 = 65536 = 2^16
也就是说,无符号表示中的UMax 有着和补码表示-1相同的位模式,这两者之间的关系:1+UMax(w) = 2^w 注意:这里的w表示位数
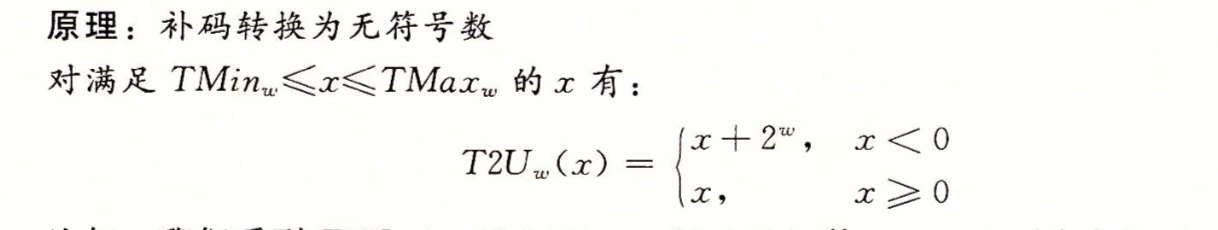
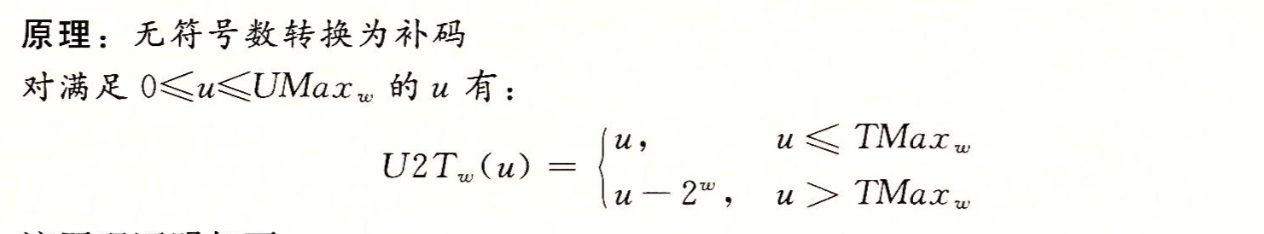
扩展一个位表示
一个常见的运算是在不同的字长的整数之间转换,同时保持数值不变。
但是如果目标数据类型太小以至于不能表示想要的值时,就会出问题了,然而,从一个较小的数据类型转换到一个比较大的类型,总是可以的
要将一个无符号数转换为一个更大的数据类型,只需要在表示的开头添加0 这种运算被称为零扩展
要将一个补码数字转换为一个更大的数据类型,只需要在表示的开头添加最高有效位的值,这种运算称为符号扩展
可以通过下面的例子理解:
给出字长w= 3 到w = 4的符号扩展的结果位向量[101]表示值-4+1=-3,因为这里是对补码的扩展,所以应用的是符号扩展,得到为向量[1101] 表示的值-8+4+1 = -3 扩展之后我们得到的值还是-3 ,类似的向量[111] 和[1111]都表示-1
截断数字
我们在代码中通常有时候都会用到强制转换,即将高位向低位转换

总结
有符号到无符号的隐式强制转换会导致某些非直观的错误,从而导致我们自己的程序出现我们意想不到的错误
并且这种包含隐式强制类型转换的细微差别很难被发现。
通过代码可能更好理解:
这个代码中,函数sum_elements好的参数length 为数组a的长度,如果我们正常赋值这个代码不会有任何问题,但是如果在整个项目中,你传递参数的时候,length传递的不是数组a的长度,而传递了0 这个时候length -1 就会变成负数,但是最开始我们定义length的时候定义的是无符号的,所以就会变成当前位数的最大值即UMax 所以《= 是总是满足条件的,这个时候你再取数组的值的时候就会超出数组的最大长度,程序就会出现异常错误。
#include <stdio.h> float sum_elements(float a[], unsigned length) { int i; float result = 0; for (i =0; i< length -1; i++) result = a[i]; printf("%f",result); return result; } int main(){ float a[5] = {1.1,2.3,1.4,3.22,1.24}; sum_elements(a,5); }
其实上面的这个情况也是有符号到无符号数的隐式转换会导致错误或者漏洞的方式,避免这类错误的一种方法就是绝对不使用无符号数,而实际上除了C以外也很少语言支持无符号整数

