Hadoop(十一)Hadoop IO之序列化与比较功能实现详解
前言
上一篇给大家介绍了Hadoop是怎么样保证数据的完整性的,并且使用Java程序来验证了会产生.crc的校验文件。这一篇给大家分享的是Hadoop的序列化!
一、序列化和反序列化概述
1.1、序列化和反序列化的定义
1)序列化:将结构化对象转换为字节流的过程,以便在网络上传输或写入到磁盘进行永久存储的过程。
2)反序列化:将字节流转回一系列的相反过程结构化对象。
注意:其实流就是字节数组,我们把数据转变成一系列的字节数组(0101这样的数据)
1.2、序列化和反序列化的应用
1)进程间的通信
2)持久化存储
1.3、RPC序列化格式要求
在Hadoop中,系统中多个节点上进程间的通信是通过“远程过程调用(RPC)”实现的。RPC协议将消息序列化成 二进制流后发送到远程节点,远程节点
将二进制流反序列化为原始信息。通常情况下,RPC序列化格式如下:
1)紧凑(compact)
紧凑格式能充分利用网络带宽。
2)快速(Fast)
进程间通信形成了分布式系统的骨架,所以需要尽量减少序列化和反序列化的性能开销,这是基本..最基本的。
3)可扩展(Extensible)
为了满足新的需求,协议不断变化。所以控制客户端和服务器的过程中,需要直接引进相应的协议。
4)支持互操作(Interoperable)
对于某些系统来说,希望能支持以不同语言写的客户端与服务器交互,所以需要设计需要一种特定的格式来满足这一需求。
二、Hadoop中和虚序列化相关的接口和类
在Java中将一个类写为可以序列化的类是实现Serializable接口
在Hadoop中将一个类写为可以序列化的类是实现Writable接口,它是一个最顶级的接口。
1.1、Hadoop对基本数据类型的包装
Hadoop参照JDK里面的数据类型实现了自己的数据类型,Hadoop自己实现的原理会使数据更紧凑一些,效率会高一些。序列化之后的字节数组大小会比
JDK序列化出来的更小一些。
所有Java基本类型的可写包装器,除了char(可以是存储在IntWritable中)。所有的都有一个get()和set()方法来检索和存储包装值。
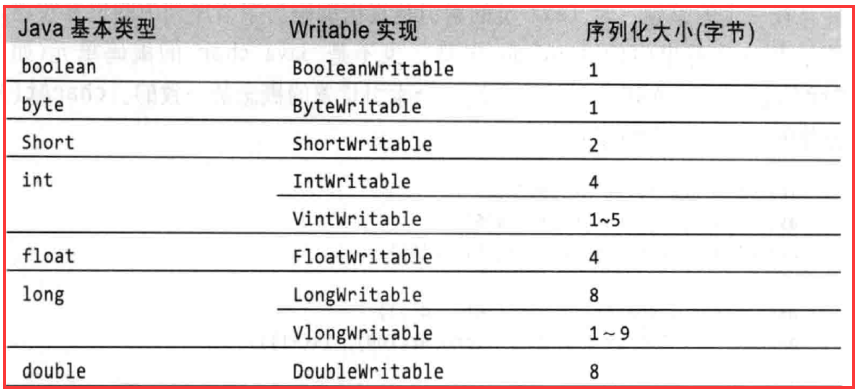
Java中的String对应着Hadoop中的Text,Text可以存储2G的字符串大小。
1.2、Writable接口
1)Writable接口概述
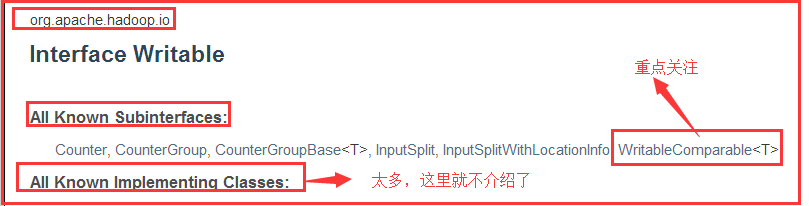
2)接口中的方法
Writable接口定义了两个方法:
一个将其状态写到DataOutput二进制流,另一个从DataInput二进制流读取状态。
3)API中Writable接口的例子:
public class MyWritable implements Writable { // Some data private int counter; private long timestamp; public void write(DataOutput out) throws IOException { out.writeInt(counter); out.writeLong(timestamp); } public void readFields(DataInput in) throws IOException { counter = in.readInt(); timestamp = in.readLong(); } public static MyWritable read(DataInput in) throws IOException { MyWritable w = new MyWritable(); w.readFields(in); return w; } }
思考:在Java中已经有序列化和反序列化相关的类和方法,为什么Hadoop还要去自己设计一套呢?
因为Hadoop认为Java设计的序列化和反序列化相关的类和方法性能不够好,效率太低了。所以就自己设计一套。
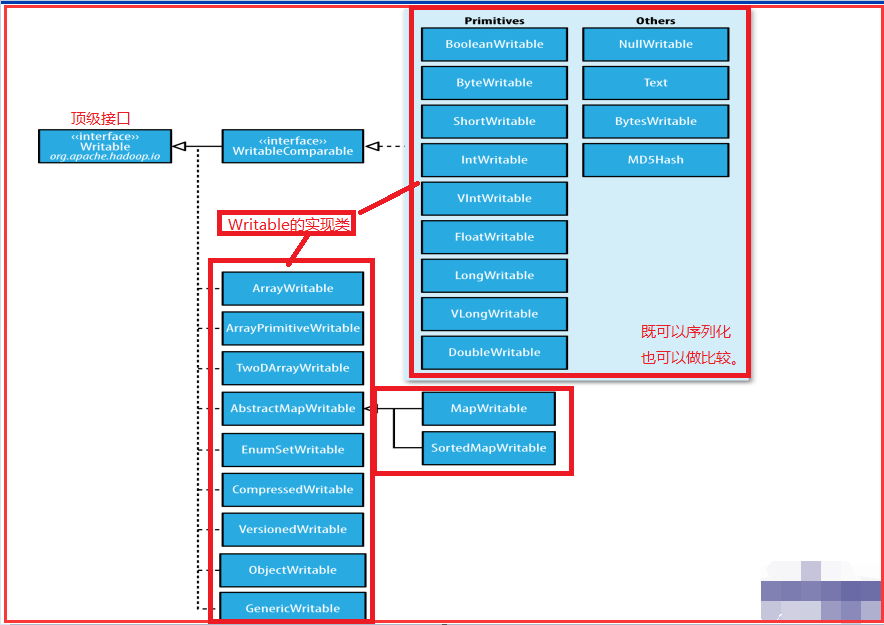
4)Writable的继承关系
1.3、实例解释Java和Hadoop数据类型序列化的差别
1)核心代码


import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.DataInputStream; import java.io.IOException; import java.io.ObjectOutputStream; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Writable; //测试使用Hadoop序列化和JDK序列化之间的区别 public class SerializationCompare_0010{ //Writable是Hadoop中所有数据类型的父类(父接口)。 public static byte[] serialize(Writable writable) throws IOException{ //这是一种编程思想,因为我们返回的是一个字节数组,所以进行了一下流的转换。 ByteArrayOutputStream baos= new ByteArrayOutputStream(); ObjectOutputStream oos= new ObjectOutputStream(baos); writable.write(oos); oos.close(); return baos.toByteArray(); } //能序列化的一定是类类型,所以这里使用int类型的包装类 public static byte[] serialize(Integer integer) throws IOException{ ByteArrayOutputStream baos= new ByteArrayOutputStream(); ObjectOutputStream oos= new ObjectOutputStream(baos); oos.writeInt(integer); oos.close(); return baos.toByteArray(); } public static Writable deserialize(byte[] bytes) throws IOException{ ByteArrayInputStream bais= new ByteArrayInputStream(bytes); DataInputStream dis= new DataInputStream(bais); IntWritable iw=new IntWritable(); iw.readFields(dis); return iw; } public static void main(String[] args) throws IOException{ IntWritable iw=new IntWritable(200); //hadoop也可以使用set方法传值 // iw.set(300); byte[] bytes=serialize(iw); System.out.println("Hadoop:"+bytes.length); //Writable deIw=deserialize(bytes); //System.out.println("Hadoop Deserialize:"+deIw); Integer integer=new Integer(200); bytes=serialize(integer); System.out.println("Java:"+bytes.length); } }
2)测试结果
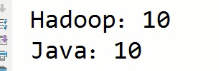 其实这里虽然是字节数组长度相同,但是在大数据中,其实是Hadoop占优势的。
其实这里虽然是字节数组长度相同,但是在大数据中,其实是Hadoop占优势的。
1.4、在Hadoop中写一个序列化的类
1)核心代码
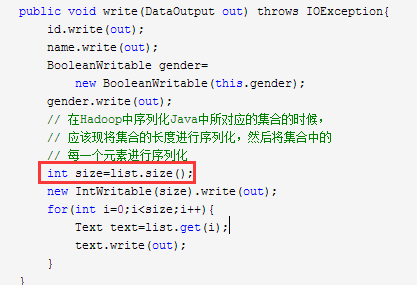
import java.io.ByteArrayOutputStream; import java.io.DataInput; import java.io.DataOutput; import java.io.DataOutputStream; import java.io.IOException; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import org.apache.hadoop.io.BooleanWritable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; public class StudentDemo_0010{ public static void main(String[] args) throws IOException{ Student student=new Student(); student.setId(new IntWritable(10)); student.setName(new Text("Lance")); student.setGender(true); ByteArrayOutputStream baos= new ByteArrayOutputStream(); DataOutputStream dos= new DataOutputStream(baos); student.write(dos); byte[] data=baos.toByteArray(); System.out.println(Arrays.toString(data)); System.out.println(data.length); // 将data进行反序列化? } } class Student implements Writable{ private IntWritable id; private Text name; private boolean gender; private List<Text> list=new ArrayList<>(); Student(){ id=new IntWritable(); name=new Text(); } /** * * @param student */ Student(Student student){ // 在Hadoop中这属于引用复制,完全杜绝这种现象 //this.id=student.id; //this.name=student.name; // 在Hadoop中要使用属性值的复制 id=new IntWritable(student.id.get()); name=new Text(student.name.toString()); } @Override public void write(DataOutput out) throws IOException{ id.write(out); name.write(out); BooleanWritable gender= new BooleanWritable(this.gender); gender.write(out); // 在Hadoop中序列化Java中所对应的集合的时候, // 应该现将集合的长度进行序列化,然后将集合中的 // 每一个元素进行序列化 int size=list.size(); new IntWritable(size).write(out); for(int i=0;i<size;i++){ Text text=list.get(i); text.write(out); } } @Override public void readFields(DataInput in) throws IOException{ id.readFields(in); name.readFields(in); BooleanWritable bw=new BooleanWritable(); bw.readFields(in); gender=bw.get(); // 在反序列化集合的时候应该先反序列化集合的长度 IntWritable size=new IntWritable(); size.readFields(in); // 再反序列化流中所对应的结合中的每一个元素 list.clear(); for(int i=0;i<size.get();i++){ Text text=new Text(); text.readFields(in); list.add(text);// 此步骤有没有问题??? } } public IntWritable getId(){ return id; } public void setId(IntWritable id){ this.id=id; } public Text getName(){ return name; } public void setName(Text name){ this.name=name; } public boolean isGender(){ return gender; } public void setGender(boolean gender){ this.gender=gender; } public List<Text> getList(){ return list; } public void setList(List<Text> list){ this.list=list; } }
2)测试执行:

注意:" 第一部分":代表的是id,占四个字节。
“第二部分”:代表的是name,首先5是代表字符的长度,后面是字符的ASCII码。
注意如果将name的值改为中文,比如“二蛋子”如果是GBK编码就会占6个字节,如果是UTF-8编码就会占9个字节。
“第三部分”:代表的是gender,1表示ture,0表示false。
“第四部分”:在我们list中的size,虽然这里没有数据,但是int类型的仍然会占4个字节数。
四、Hadoop中和比较相关的接口和类
4.1、WritableComparable<T>接口
1)概述
继承了两个接口

2)相关方法
继承过来的三个方法

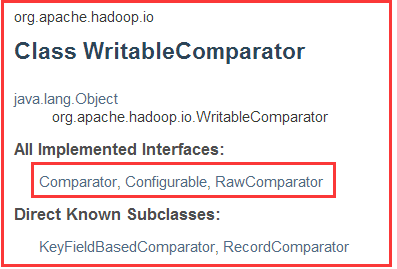
4.2、RawComparator<T>接口
1)概述
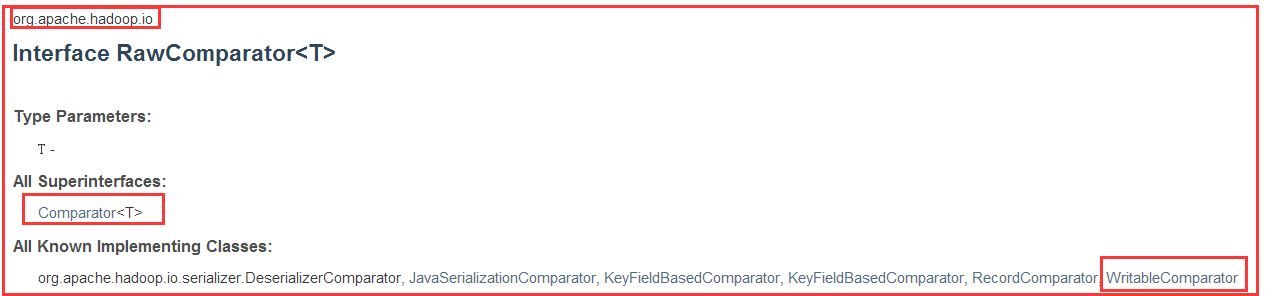
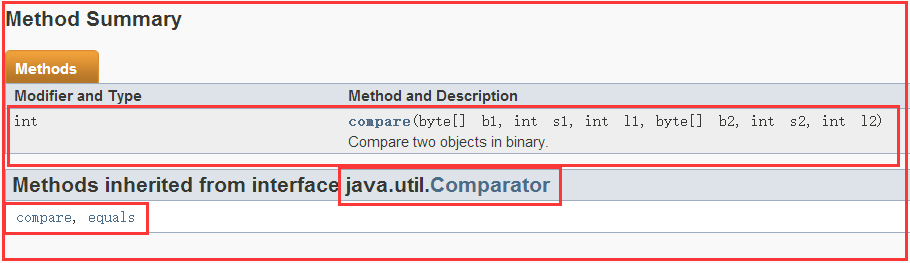
2)相关方法
除了Comparator中继承的两个方法,它自己也定义了一个方法有6个参数,这是在字节流的层面上去做比较。(第一个参数:指定字节数组,第二个参数:从哪里开始比较,第三个参数:比较多长)
在考虑到使用RawComparator比较不方便,有出现了一个实现类。
4.3、WritableComparator类
1)概述
2)构造方法

3)相关方法
截取了部分
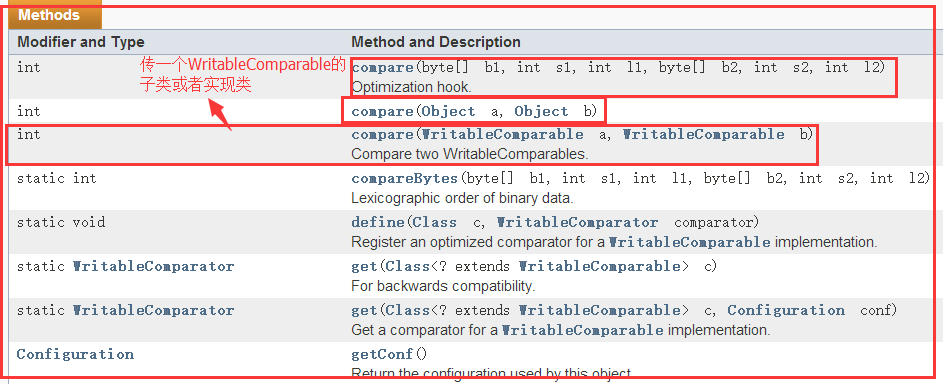
介绍了上面的类和这些方法,我们Hadoop中有实现了一些既可以序列化也可以比较的类:

那我们如果自定义一个类型去实现比较的功能呢?在我们前面写了一个Student的类,它具有序列化的功能,那怎么样才能有比较的功能呢?
在Java中如果让一个类的对象具有可比较性
1)实现Comparable接口
2)编写独立的比较器,Comparator
而在Hadoop如果你要实现比较的功能有:
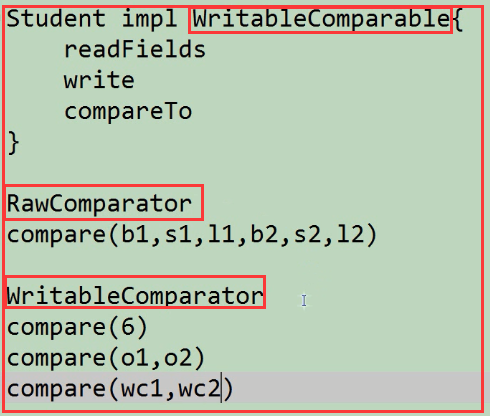
从上面的图中可以看出:
要是一个类具有比较功能又有序列化的功能可以去实现WritableComparable接口,如果你要一个类只要有比较功能
可以去写一个比较器用RawComparator或WritableComparator。
总的来说最好还是去实现WritableComparable接口,因为又有序列化的功能又有比较的功能。
五、Hadoop实现序列化和比较功能
功能分析:

5.1、核心代码
import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.DataInput; import java.io.DataInputStream; import java.io.DataOutput; import java.io.DataOutputStream; import java.io.IOException; import org.apache.hadoop.io.BooleanWritable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.IntWritable.Comparator; import org.apache.hadoop.io.RawComparator; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.VIntWritable; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableUtils; public class P00120_AccountWritable_0010{ public static void main(String[] args){ AccountWritable aw1=new AccountWritable(); aw1.set(new IntWritable(30),new Text("zyh"),new BooleanWritable(true)); AccountWritable aw2=new AccountWritable(); aw2.set(new IntWritable(30),new Text("zyh"),new BooleanWritable(true)); AccountWritable.DiyComparator comparator=new AccountWritable.DiyComparator(); System.out.println(comparator.compare(aw1,aw2)); } } class AccountWritable implements WritableComparable<AccountWritable>{ private IntWritable code; private Text name; private BooleanWritable gender; AccountWritable(){ code=new IntWritable(); name=new Text(); gender=new BooleanWritable(); } // 把参数类型和类类型相同的构造器,叫复制构造器 AccountWritable(AccountWritable aw){ code=new IntWritable(aw.getCode().get()); name=new Text(aw.getName().toString()); gender=new BooleanWritable(aw.getGender().get()); } public void set(IntWritable code,Text name,BooleanWritable gender){ this.code=new IntWritable(code.get()); this.name=new Text(name.toString()); this.gender=new BooleanWritable(gender.get()); } @Override public int compareTo(AccountWritable o){ /*return this.code.compareTo(o.code)!=0?code.compareTo(o.code): (name.compareTo(o.name)!=0?name.compareTo(o.name):(this.gender.compareTo(o.gender)!=0?gender.compareTo(o.gender):0));*/ int comp=this.code.compareTo(o.code); if(comp!=0){ return comp; }else{ comp=this.name.compareTo(o.name); if(comp!=0){ return comp; }else{ comp=this.gender.compareTo(o.gender); if(comp!=0){ return comp; }else{ return 0; } } } } @Override public void write(DataOutput out) throws IOException{ code.write(out); name.write(out); gender.write(out); } @Override public void readFields(DataInput in) throws IOException{ code.readFields(in); name.readFields(in); gender.readFields(in); } //实现一个比较器 static class DiyComparator implements RawComparator<AccountWritable>{ private IntWritable.Comparator ic= new Comparator(); private Text.Comparator tc= new Text.Comparator(); private BooleanWritable.Comparator bc= new BooleanWritable.Comparator(); @Override public int compare(byte[] b1,int s1,int l1,byte[] b2,int s2,int l2){ // code被序列化后在b1和b2数组中的起始位置以及字节长度 int firstLength=4; int secondLength=4; int firstStart=s1; int secondStart=s2; int firstOffset=0; int secondOffset=0; // 比较字节流中的code部分 int comp=ic.compare( b1,firstStart,firstLength, b2,secondStart,secondLength); if(comp!=0){ return comp; }else{ try{ // 获取记录字符串的起始位置 firstStart=firstStart+firstLength; secondStart=secondStart+secondLength; // 获取记录字符串长度的VIntWritable的值的长度,被称为offset firstOffset=WritableUtils.decodeVIntSize(b1[firstStart]); secondOffset=WritableUtils.decodeVIntSize(b2[secondStart]); // 获取字符串的长度 firstLength=readLengthValue(b1,firstStart); secondLength=readLengthValue(b2,secondStart); }catch(IOException e){ e.printStackTrace(); } // 比较字节流中的name部分 comp=tc.compare(b1,firstStart+firstOffset,firstLength,b2,secondStart+secondOffset,secondLength); if(comp!=0){ return comp; }else{ firstStart+=(firstOffset+firstLength); secondStart+=(secondOffset+secondLength); firstLength=1; secondLength=1; // 比较字节流中的gender部分 return bc.compare(b1,firstStart,firstLength,b2,secondStart,secondLength); } } } private int readLengthValue( byte[] bytes,int start) throws IOException{ DataInputStream dis= new DataInputStream( new ByteArrayInputStream( bytes,start,WritableUtils.decodeVIntSize(bytes[start]))); VIntWritable viw=new VIntWritable(); viw.readFields(dis); return viw.get(); } @Override public int compare(AccountWritable o1,AccountWritable o2){ ByteArrayOutputStream baos1=new ByteArrayOutputStream(); DataOutputStream dos1=new DataOutputStream(baos1); ByteArrayOutputStream baos2=new ByteArrayOutputStream(); DataOutputStream dos2=new DataOutputStream(baos2); try{ o1.write(dos1); o2.write(dos2); dos1.close(); dos2.close(); byte[] b1=baos1.toByteArray(); byte[] b2=baos2.toByteArray(); return compare(b1,0,b1.length,b2,0,b2.length); }catch(IOException e){ e.printStackTrace(); } return 0; } } public IntWritable getCode(){ return code; } public void setCode(IntWritable code){ this.code=code; } public Text getName(){ return name; } public void setName(Text name){ this.name=name; } public BooleanWritable getGender(){ return gender; } public void setGender(BooleanWritable gender){ this.gender=gender; } }
注意如果一个类即实现了WritableComparatable接口又写了比较器,优先使用比较器。
喜欢就点个“推荐”!

