

pyspider源码解读--调度器scheduler.py
pyspider源码解读--调度器scheduler.py
scheduler.py
首先从pyspider的根目录下找到/pyspider/scheduler/scheduler.py
其中定义了四个类:
class Project(object)
class Scheduler(object)
class OneScheduler(Scheduler)
class ThreadBaseScheduler(Scheduler)
这四个类的作用分别如下:
Project
单个项目的Paused状态切换即是由这个类实例化的对象来完成,其中的方法有—paused(),update(project_info)
Scheduler
整体的调度过程,包括从入库,读库,对task的操作(主要是各个队列之间的get和put,以及task执行包的封装),状态的切换
OneScheduler
debug中用到的类,其继承自Scheduler,不同的是,它不会将需要抓取的task丢入到一个消费者队列中,而是会直接调用一个process立刻去执行fetch(其实现在send_task这一函数)
ThreadBaseScheduler
这个类用到的地方很少,在pyspider/libs/bench.py中用到过,作压力测试
主要看Scheduler类
Scheduler(object)
先看所有函数的名字以及其中的注释,首先看到的是run以及run_once
关于变量,在具体看某一个函数的时候,可以再去查询这个变量第一次出现的位置,结合函数的作用就能大致明白这个变量的功能了。
def run_once(self):
'''comsume queues and feed tasks to fetcher, once'''
self._update_projects()
self._check_task_done()
self._check_request()
while self._check_cronjob():
pass
self._check_select()
self._check_delete()
self._try_dump_cnt()
self._update_projects()
更新project的状态,并且回显到webui上 (这个操作经由几步调用,其会去读所有项目的库,并且load到各自的task_queue中)
self._check_task_done()
去不断取出scheduler的status_queue优先级最高的任务,并检测其状态
self._check_request()
其会优先去取_postpone_request中的延迟task,因为这些极有可能是上次版本运行改变遗留下的一些认为有(比如某个任务正在跑,我们手动stop了它,然后修改了脚本,再重新启动它),将其发送给on_request
然后去获取newtask_queue中的任务,并且不断将这些任务交给on_request, on_request会作一些判断,然后将其put到各自project的task_queue中
总结如上三个方法
上面的操作无非都是向各个项目的 task_queue中填充内容,从数据库读取 / 从新产生 的任务中生成
self._check_select()
这个函数会优先从缓冲队列中读取任务(当任务太多的时候,会将多余任务放到缓冲队列中),然后正常遍历所有的project,并且将其中的task_queue取出(在此之前,每个project首先会更新各自的task_queue的优先级队列:两个,一个time,一个process),并且使用自定义方法get()取得优先级最高的task(这个获取是从proicess优先级队列中取出的)
time优先级 和 process优先级 队列 的关系是:process是真正被取出去执行的任务,time是生成process的一个条件,也就是从time中取时间优先级最高的不断添加到process中
更新完了之后,将获取到的taskid按顺序保存,传递给_load_put_task()函数,经由其从数据库中(根据taskid)读信息,再传递给on_select_task()方法
on_select_task()这个函数是给每个taskid填充完整的信息,最后添加到所在project的active队列中,表明其正在被调度
最后由send_task()方法传递到 out_queue队列中(如果out_queue满了,会放到缓冲deque中)
其余两个方法
self._check_delete()
self._try_dump_cnt()
前者是检测是否有到达约定时间需要删除的项目,后者是定时回显webui页面上的任务数目状态(60s一次)
run_once
这个函数的功能就是将需要被调度的taskid,经过一系列中间转换,带上了一些优先级,最后全部丢入到调度器类本身的一个out_queue队列中,这个队列作为一个生产者,供给fetch消费
详细流程,队列间传递消息
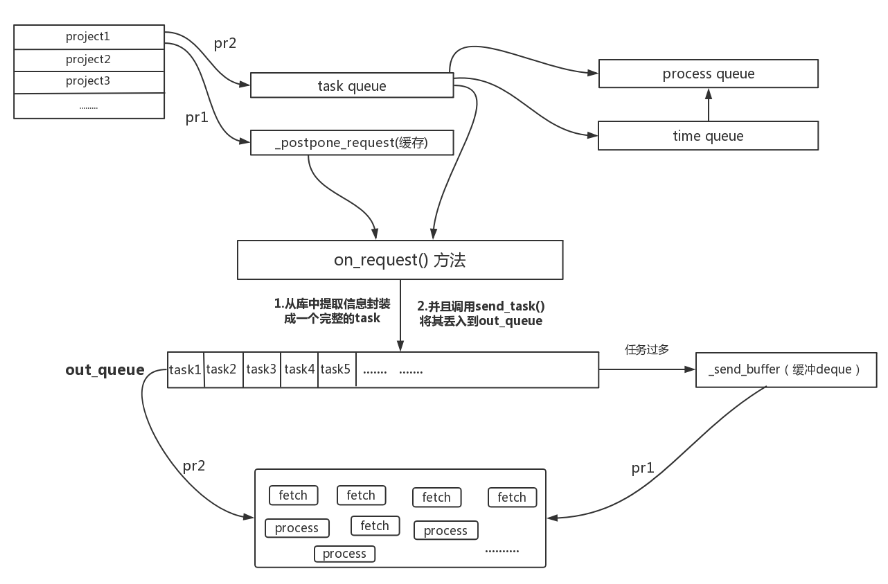
调度情况如上图,其中的queue指的是作者在其中自己封装实现的一些优先级队列(其实现在/pyspider/scheduler/task_queue.py),deque一般都是被用作缓冲队列。
--------------------------
1.队列统计:方便查看爬虫状态,优化爬虫爬取速度新增的状态统计。
每个组件之间的数字就是对应不同队列的排队数量,通常就是0或个位数,如果达到了几十甚至一百说明下游组件出现了瓶颈或错误,需要分析处理
2.组名:新建project后一般是不能修改project名字,如果需要特殊标记,可以通过更改group名字。
注:组名改为delete后如果状态是stop状态,24小时后会被系统自动删除
3.运行状态:五个
TODO : 新建项目后的默认状态
STOP : 停止
CHECKING :只要修改了代码,自动变成检查状态
DEBUG :在这个模式下运行,遇到错误信息会停止继续运行
RUNNING : 这里运行时遇到错误会尝试,如果还是错误会跳过这个任务继续运行
4.速度控制:rate是每秒爬取页面数 , burst是并发数 ,如1/3是三个并发,每秒爬取一个页面。
5.简单统计:5m是五分钟内任务执行的情况 , 1h是一小时内任务统计 , 1d是一天内运行任务统计 , all是所有任务统计
6.任务列表:显示最新任务列表,方便查看状态,查看错误等
7.结果查看:查看项目爬取的结果(默认是保存到sqlite3 db中,支持以json和csv格式下载)
golang技术交流群:316397059,vuejs技术交流群:458915921 囤币一族:621258209,有兴趣的可以加入
微信公众号: 心禅道(xinchandao)投资论道

