

注:本文以hadoop-2.5.0-cdh5.3.2为例进行说明。
Hadoop Yarn的资源隔离是指为运行着不同任务的“Container”提供可独立使用的计算资源,以避免它们之间相互干扰。目前支持两种类型的资源隔离:CPU和内存,对于这两种类型的资源,Yarn使用了不同的资源隔离方案。
对于CPU而言,它是一种“弹性”资源,使用量大小不会直接影响到应用程序的存亡,因此CPU的资源隔离方案采用了Linux Kernel提供的轻量级资源隔离技术Cgroup;对于内存而言,它是一种“限制性”资源,使用量大小直接决定着应用程序的存亡,Cgroup会严格限制应用程序的内存使用上限,一旦使用量超过预先定义的上限值,就会将该应用程序“杀死”,因此无法使用Cgroup进行内存资源隔离,而是选择了线程监控的方式。
需要解释一下:为什么应用程序的内存会超过预先定义的上限值?Java程序(Container)为什么需要内存资源隔离?
(1)为什么应用程序的内存会超过预先定义的上限值?
这里的应用程序特指Yarn Container,它是Yarn NodeManager通过创建子进程的方式启动的;Java创建子进程时采用了“fork() + exec()”的方案,子进程启动瞬间,它的内存使用量与父进程是一致的,然后子进程的内存会恢复正常;也就是说,Container(子进程)的创建过程中可能会出现内存使用量超过预先定义的上限值的情况(取决于父进程,也就是NodeManager的内存使用量);此时,如果使用Cgroup进行内存资源隔离,这个Container就可能会被“kill”。
(2)Java程序(Container)为什么需要内存资源隔离?
对于MapReduce而言,各个任务被运行在独立的Java虚拟机中,内存使用量可以通过“-Xms、-Xmx”进行设置,从而达到内存资源隔离的目的。然而,Yarn考虑到用户应用程序可能会创建子进程的情况,如Hadoop Pipes(或者Hadoop Streaming),编写的MapReduce应用程序中每个任务(Map Task、Reduce Task)至少由Java进程和C++进程两个进程组成,这难以通过创建单独的虚拟机达到资源隔离的效果,因此,即使是通过Java语言实现的Container仍需要使用内存资源隔离。
Yarn Container支持两种实现:DefaultContainerExecutor和LinuxContainerExecutor;其中DefaultContainerExecutor不支持CPU的资源隔离,LinuxContainerExecutor使用Cgroup的方式支持CPU的资源隔离,两者内存的资源隔离都是通过“线程监控”的方式实现的。
基于线程监控的内存隔离方案
1.配置参数
(1)应用程序配置参数
不同的应用程序对内存的需求不同,可以根据具体情况定义自己的参数,以MapReduce为例:
mapreduce.map.memory.mb:MapReduce Map Task需要使用的内存量(单位:MB);
mapreduce.reduce.memory.mb:MapReduce Reduce Task需要使用的内存量(单位:MB);
(2)Hadoop Yarn NodeManager配置参数
yarn.nodemanager.pmem-check-enabled:NodeManager是否启用物理内存量监控,默认值:true;
yarn.nodemanager.vmem-check-enabled:NodeManager是否启用虚拟内存量监控,默认值:false;
yarn.nodemanager.vmem-pmem-ratio:NodeManager Node虚拟内存与物理内存的使用比例,默认值2.1,表示每使用1MB物理内存,最多可以使用2.1MB虚拟内存;
yarn.nodemanager.resource.memory-mb:NodeManager Node最多可以使用多少物理内存(单位:MB),默认值:8192,即8GB;
2.实现原理
Yarn NodeManager Container的内存监控是由ContainersMonitorImpl(org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl)实现的,内部的MonitoringThread线程每隔一段时间就会扫描所有正在运行的Container进程,并按照以下步骤检查它们的内存使用量是否超过其上限值。
2.1构造进程树
如前所述,Container进程可能会创建子进程(可能会创建多个子进程,这些子进程可能也会创建子进程),因此Container进程的内存(物理内存、虚拟内存)使用量应该表示为:以Container进程为根的进程树中所有进程的内存(物理内存、虚拟内存)使用总量。
在Linux /proc目录下,有大量以整数命名的目录,这些整数是某个正在运行的进程的PID,而目录/proc/<PID>下面的那些文件分别表示着进程运行时的各方面信息,这里我们只关心/proc/<PID>/stat文件即可。
文件/proc/<PID>/stat仅仅包含一行(多列)文本,可以通过正则表达式从中抽取进程的运行时信息,包括:进程名称、父进程PID、父进程用户组ID、Session ID、用户态运行的时间(单位:jiffies)、核心态运行的时间(单位:jiffies)、占用虚拟内存大小(单位:page)和占用物理内存大小(单位:page)等。
ContainersMonitorImpl内部维护着每个Container进程的PID,通过遍历/proc下各个进程的stat文件内容(父进程PID、占用虚拟内存大小和占用物理内存大小),我们可以构建出每个Container的进程树,从而得出每个进程树的虚拟内存、物理内存使用总量。
2.2判断Container进程树的内存使用量(物理内存、虚拟内存)是否超过上限值
虽然我们已经可以获得各个Container进程树的内存(物理内存、虚拟内存)使用量,但是我们不能仅凭进程树的内存使用量(物理内存、虚拟内存)是否超过上限值就决定是否“杀死”一个Container,因为“子进程”的内存使用量是有“波动”的,为了避免“误杀”的情况出现,Hadoop赋予每个进程“年龄”属性,并规定刚启动进程的年龄是1,MonitoringThread线程每更新一次,各个进程的年龄加一,在此基础上,选择被“杀死”的Container的标准如下:如果一个Contaier对应的进程树中所有进程(年龄大于0)总内存(物理内存或虚拟内存)使用量超过上限值的两倍;或者所有年龄大于1的进程总内存(物理内存或虚拟内存)使用量超过上限值,则认为该Container使用内存超量,可以被“杀死”。(注意:这里的Container泛指Container进程树)
综上所述,Yarn的内存资源隔离实际是内存使用量监控。
3.源码分析
3.1MonitoringThread
线程监控的核心工作主要是由MonitoringThread(org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl.MonitoringThread)完成的,内部就是一个“while”循环,以指定的时间间隔进行监控:

其中,时间间隔monitoringInterval由参数yarn.nodemanager.container-monitor.interval-ms指定,默认值:3000,单位:ms。
下面介绍“while”循环的处理逻辑。
3.2 将新启动的Container加入监控列表以及将已完成的Container移出监控列表;
每次监控开始之前都需要更新监控列表:trackingContainers,将新启动的Container加入监控列表,由containersToBeAdded表示;将已完成的Container移出监控列表,由containersToBeRemoved表示。
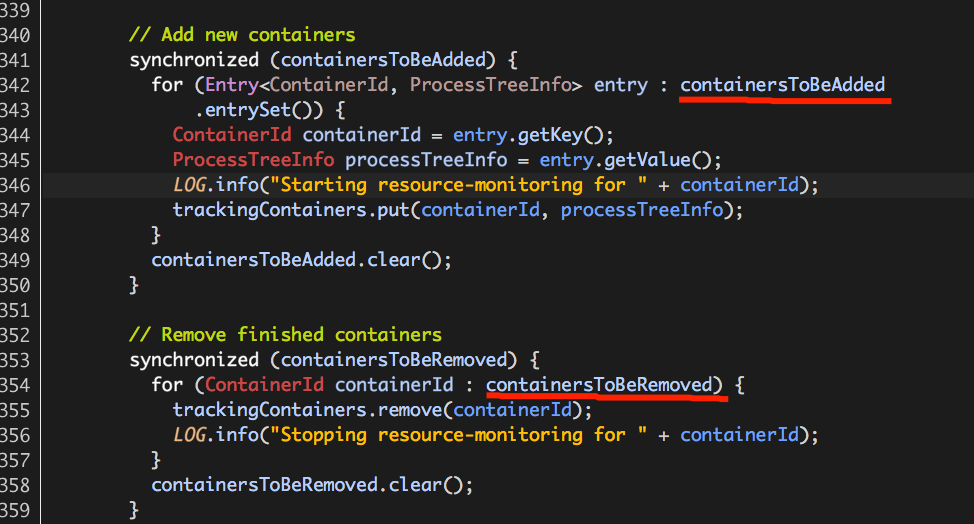
containersToBeAdded和containersToBeRemoved都是通过“事件”由org.apache.hadoop.yarn.server.nodemanager.containermanager.monitor.ContainersMonitorImpl.handle负责更新的,如下:
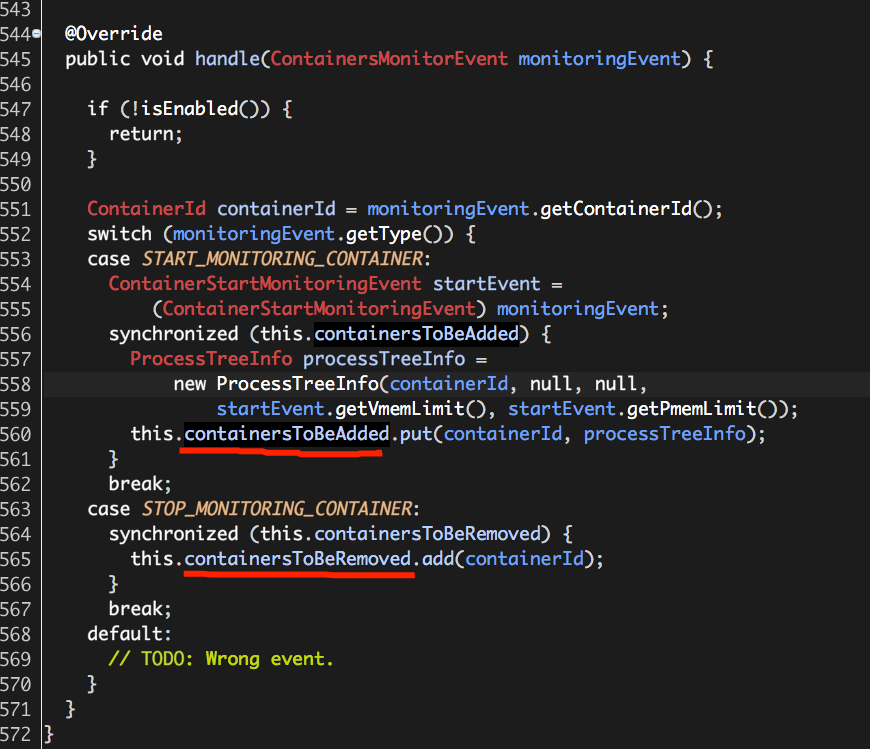
对于事件START_MONITORING_CONTAINER,它表示有新的Container进程,为其构建一个ProcessTreeInfo实例,用于保存Container的进程树信息,也就是说,这里考虑的不仅仅是Container进程,而是以Container进程为父进程的整个进程树,构造函数参数含义依次如下:
containerId:Container ID;
pid:Container进程的PID;
pTree:Container进程树内存使用量计算器实例,不同的Hadoop运行平台(Windows、Linux)因为统计内存使用量的方式不同,因此需要不同的计算器实例;通过该计算器实例,可以获得当前Container进程树的内存使用量;
vmemLimit:Container进程树可使用的虚拟内存上限值;
pmemLimit:Container进程树可使用的物理内存上限值;
注意:pid、pTree的初始值为Null。
更新监控列表trackingContainers之后,下一步就是对监控列表中的Container进程树的内存使用量进行监控。
3.3遍历监控列表trackingContainers,逐个处理其中的进程树;

可以看出,监控列表trackingContainers中的每一个进程树元素是由ContainerId和ProcessTreeInfo共同表示的。
下面介绍单独一个进程树的内存监控过程。
3.4初始化进程树信息ProcessTreeInfo;
如3.2所述,进程树监控列表trackingContainers是被不断更新的,而新加入监控的Container进程树信息是由ProcessTreeInfo表示的,

其中pid、pTree的初始值为Null,因此监控过程中如果发现进程树信息ProcessTreeInfo的pid、pTree为Null,要对其进行初始化。
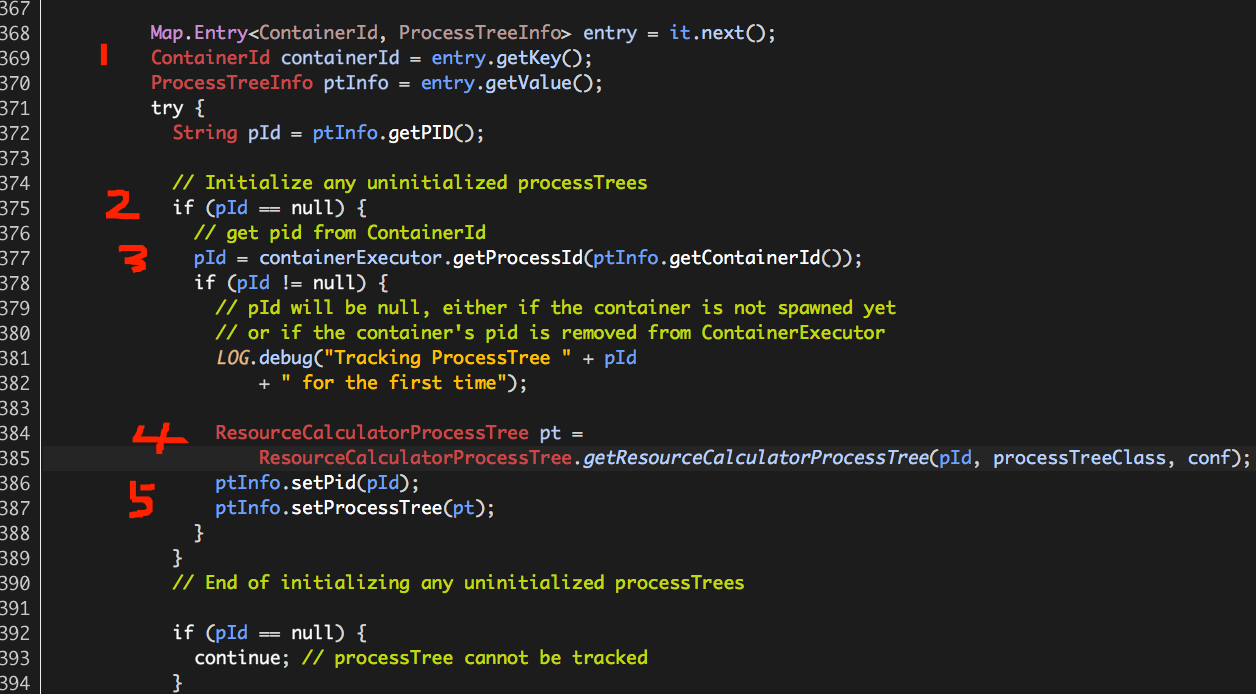
(1)获取进程树元素,由containerId和ptInfo表示;
(2)判断如果ptInfo(进程树信息)中的pId(Container进程的PID)为null,则表示需要初始化ptInfo;
(3)获取ProcessTreeInfo pid,将其保存至pId;
Container进程PID(pid)可以通过ContainerId(ptInfo.getContainerId())从ContainerExecutor(containerExecutor)中获取;如果获取不到相应的PID,可能是因为Container进程尚没有被启动或者ContainerExecutor已将其移除,也意味着此进程树无需监控。
(4)获取ProcessTreeInfo pTree,将其保存至pt;
这里需要介绍一下ResourceCalculatorProcessTree(org.apache.hadoop.yarn.util.ResourceCalculatorProcessTree)的作用。
每一次对ProcessTreeInfo进行监控时,我们都必须获取该进程树内所有进程的运行状态(这里我们仅关心物理、虚拟内存使用情况等),也就是说,我们需要一个“计算器”,能够将进程树内所有进程的运行状态计算出来,ResourceCalculatorProcessTree就是用来充当“计算器”角色的,如下注释所示:
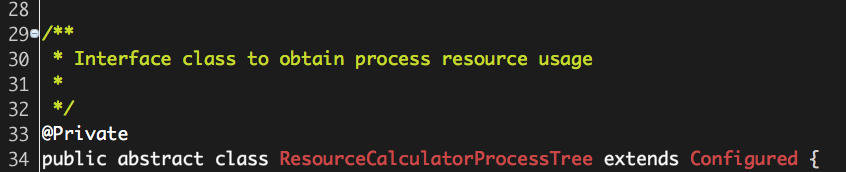
ResourceCalculatorProcessTree是一个抽象类,也就意味着它可以有多种实现,具体选取哪一种实现取决于ResourceCalculatorProcessTree.getResourceCalculatorProcessTree:

其中,processTreeClass由参数yarn.nodemanager.container-monitor.process-tree.class指定,默认值为null。
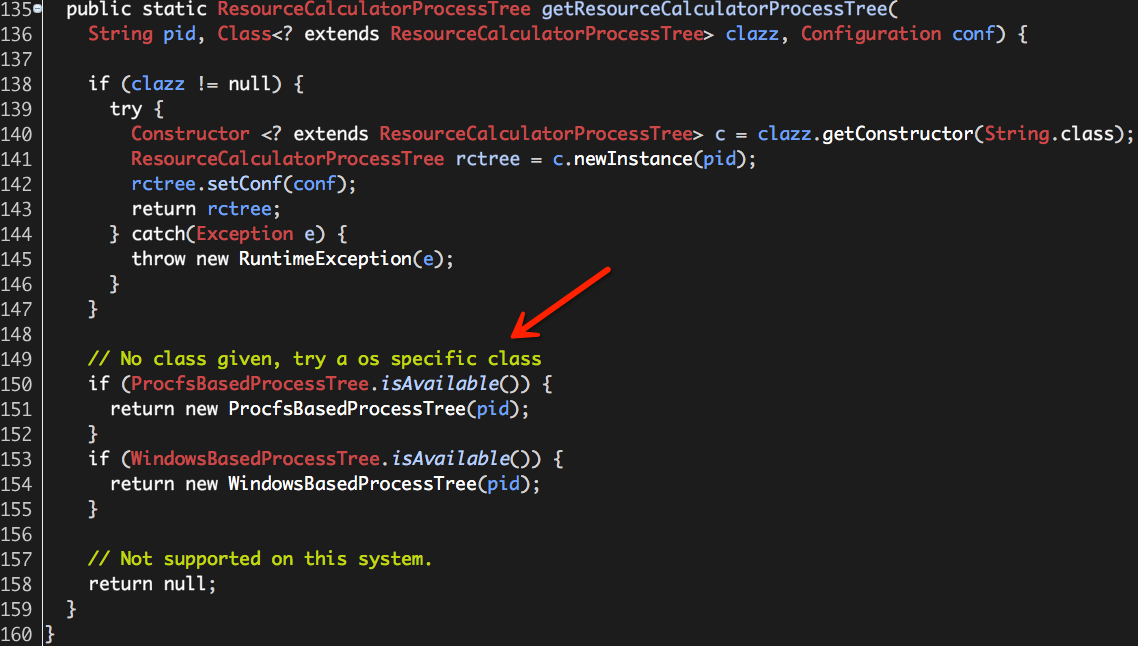
因为传入的参数clazz值为null,所以我们仅仅关注上图红色箭头所指的逻辑即可。
ProcfsBasedProcessTree和WindowsBasedProcessTree分别对应着ResourceCalculatorProcessTree在Linux平台和Windows平台的实现,通常我们关注ProcfsBasedProcessTree即可,也就是说,Linux平台下pTree的实例类型为ProcfsBasedProcessTree。
(5)将pId、pt更新至ptInfo,初始化过程完成;
3.5根据ResourceCalculatorProcessTree(ProcfsBasedProcessTree)更新进程树的运行状态(这里仅关注物理、虚拟内存),并获取相关的监控信息;
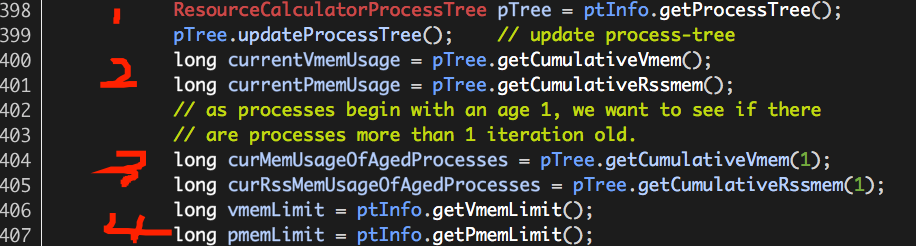
(1)获取当前进程树的ResourceCalculatorProcessTree实例pTree,并更新其内部状态updateProcessTree(),实际就是更新进程树中的进程信息(详细处理逻辑见后);
(2)获取当前进程树中所有进程的虚拟内存使用总量(currentVmemUsage)、物理内存使用总量(currentPmemUsage);
(3)获取当前进程树中所有年龄大于1的进程的虚拟内存使用总量(curMemUsageOfAgedProcesses)、物理内存使用总是(curRssMemUsageOfAgedProcesses);
(4)获取当前进程树的虚拟内存使用总量上限值(vmemLimit)、物理内存使用总量上限值(pmemLimit);
3.6判断进程树的内存使用量是否超过上限值,虚拟内存与物理内存需要分别处理;
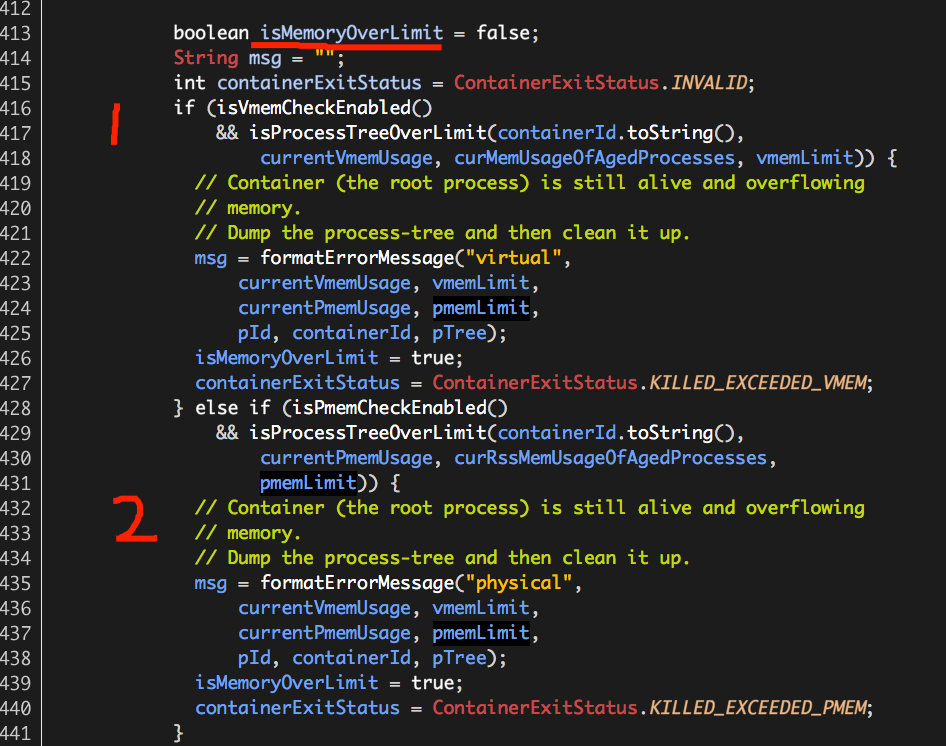
isMemoryOverLimit的值用于表示进程树的内存使用量是否超过上限值,值为true表示超量(虚拟内存或物理内存两者至少有其一超量);值为false表示未超量(虚拟内存和物理内存两者均未超量);初始值设置为false。
(1)如果开启虚拟内存监控,则判断进程树虚拟内存使用总量是否超过其上限值;
(2)如果开启物理内存监控,则判断进程树物理内存使用总量是否超过其上限值;
虚拟、物理内存监控选项的开启分别由参数yarn.nodemanager.vmem-check-enabled、yarn.nodemanager.pmem-check-enabled指定,默认值均为true,表示两者均开启监控。
判断虚拟、物理内存使用总量是否超过上限值由isProcessTreeOverLimit()(详细处理逻辑见后)统一处理,两者仅传入的参数值不同,参考上图代码。
3.7如果isMemoryOverLimit值为true,则表示进程树的内存使用量超量(或者虚拟内存、或者物理内存),执行“kill”并从监控列表移除;
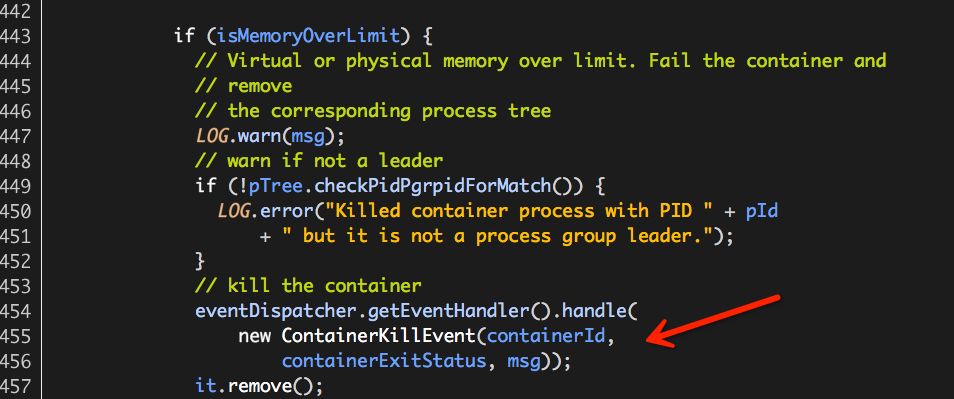
至此,进程树内存使用总量监控处理逻辑完成。
3.8ResourceCalculatorProcessTree(ProcfsBasedProcessTree) updateProcessTree
updateProcessTree用于更新当前Container进程的进程树:
(1)获取所有的进程列表;

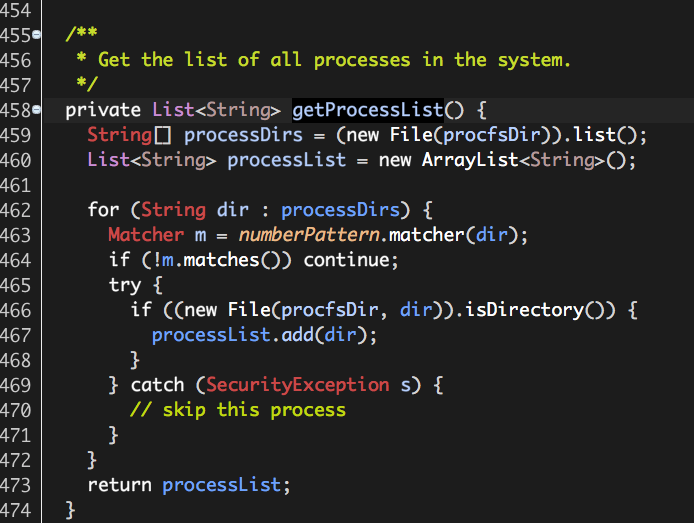
其中,procfsDir的值为/proc/,numberPattern表示的正则表达式为[1-9][0-9]*(用于匹配进程PID)。对于Linux系统而言,所以运行着的进程都对应着目录“/proc/”下的一个子目录,子目录名称即为进程PID,子目录中包含着进程的运行时信息。所谓的进程列表,实际就是Linux目录“/proc/”下的这些进程子目录名称。

进程列表processList包含的信息:1、10、100、...。
(2)更新进程树processTree;

因为Container进程树中的进程随时都可能启动或停止,因此每次监控开始之前都需要更新该Container进程的进程树;而且为了方便处理进程的年龄(加一),将该Container进程“旧”的进程树processTree缓存至oldProcs,然后清空processTree(详情见后)。
(3)遍历(1)中进程列表,为每一个进程构建ProcessInfo,并将其保存至allProcessInfo;

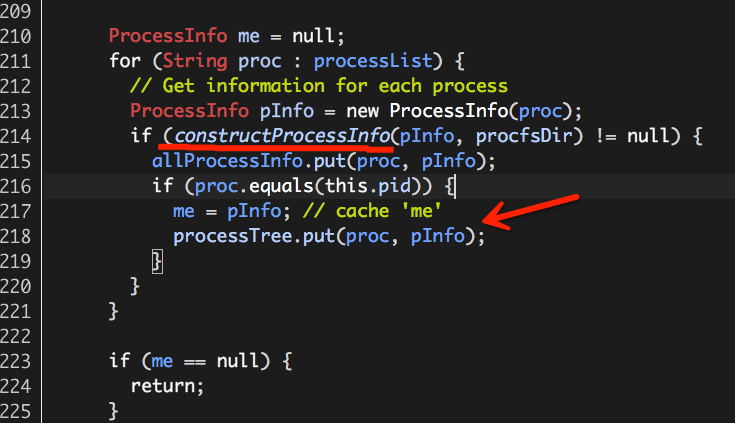
ProcessInfo的构建过程由方法constructProcessInfo()完成,处理逻辑很简单:
a.读取“procfsDir/<pid>/stat”(即“/proc/<pid>/stat”)的文件内容,实际内容只有一行;
b.通过正则表达式抽取其中的信息,并更新至pInfo;

可以看出,ProcessInfo保存着一个进程的以下信息:
name:进程名称;
ppid:父进程PID;
pgrpId:父进程所属用户组ID;
session:进程所属会话组ID;
utime:进程用户态占用时间;
stime:进程内核态占用时间;
vsize:进程虚拟内存使用量;
rss:进程物理内存使用量;
遍历构建的过程中,如果发现“我”进程(即当前的Container进程),则将“我”保存至进程树processTree,因为当前的Container进程必须是此Container进程树中的一员;如果没有发现“我”进程,则表示Container进程(树)已经运行结束,无需监控。
(4)维护进程之间的父子关系;
allProcessInfo中保存着所有的进程信息,其中key为PID,value为对应的ProcessInfo,我们通过ProcessInfo的ppid(父进程PID),即可以维护出这些进程之间的父子关系。
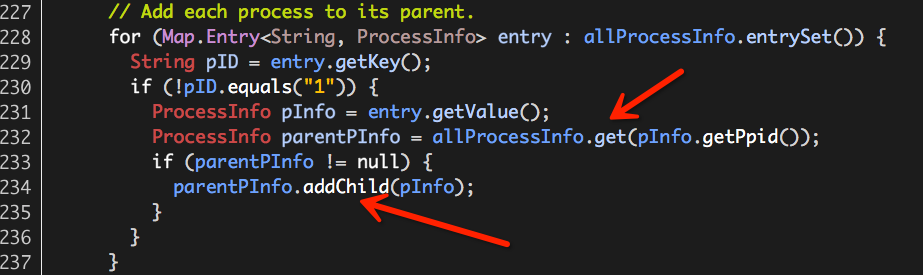
对于每一个ProcessInfo(进程)pInfo:
a.根据pInfo ppid找出其父进程的ProcessInfo:parentPInfo;
b.将pInfo加入parentPInfo的子进程列表中(ProcessInfo addChild);
(5)构建当前Container进程(即(3)中的me)的进程树;

a.将pInfoQueue初始化为me;
b.如果pInfoQueue不为空,执行以下操作:
b1.取出pInfoQueue的头元素pInfo,将其加入进程树processTree(注意重复检测);
b2.将pInfo的所有子进程加入pInfoQueue;
c.执行b;
上述流程执行完毕之后,processTree中保存着当前Container进程的进程树。
(6)更新当前Container进程的进程树中所有进程的年龄;
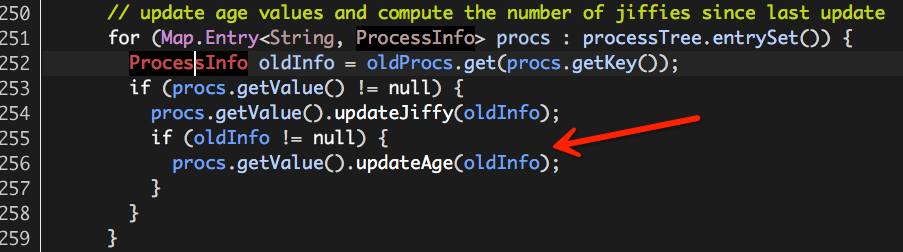
处理逻辑很简单:遍历进程树,对于其中的每一个ProcessInfo,如果它是一个“老”进程(即出现在“老”进程树oldInfo中),则将其年龄加一。(注:ProcessInfo age初始值为一)
到此,进程树更新完毕。
我们以虚拟内存为例说明进程树的虚拟内存使用总量是如何计算的,如下:

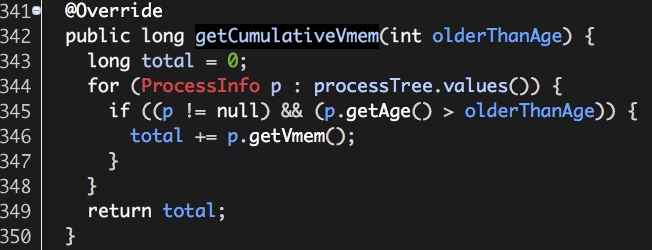
其实就是根据进程年龄做过滤,然后叠加ProcessInfo中的相关值(虚拟内存:vmem)。
3.9ContainersMonitorImpl.isProcessTreeOverLimit
isProcessTreeOverLimit用于判断内存使用量是否超过上限值,虚拟内存和物理内存共用此方法。
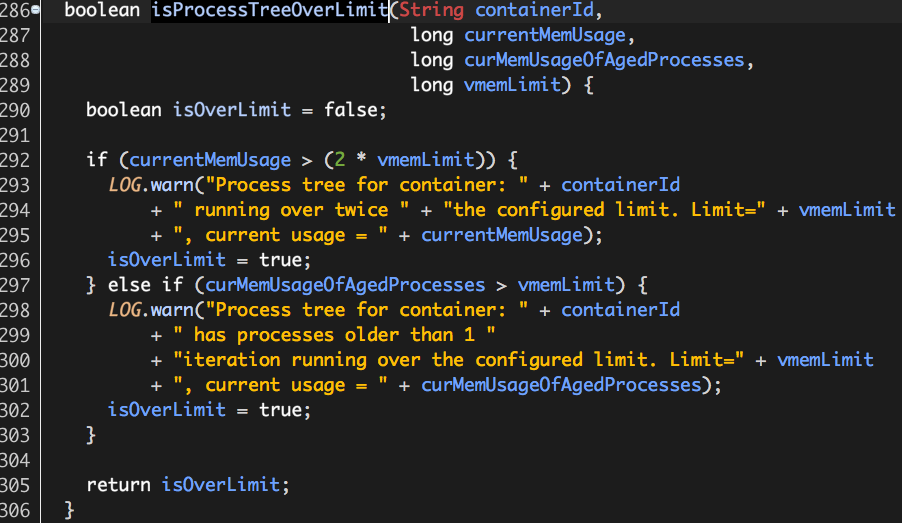
currentMemUsage:进程树中所有进程的虚拟或物理内存使用总量;
curMemUsageOfAgedProcesses:进程树中所有年龄大于1的进程的虚拟或物理内存使用总量;
vmemLimit:进程树虚拟或物理内存使用上限;
满足以下二个条件之一,则认为进程树内存使用超过上限:
(1)currentMemUsage大于vmemLimit的两倍,这样做的目录主要是为了防止误判(见本文开篇所述);
(2)curMemUsageOfAgedProcesses大于vmemLimit(年龄大于一的进程可以认内存使用比较“稳定”);
至此,Hadoop Yarn基于线程监控的内存隔离方案介绍完毕。

