

引言
MapReduce作出保证:进入每个Reducer的数据行都是有序的(根据数据行的键值进行排序)。MapReduce将Mapper的输出进行排序并传递给Reducer作为输入的过程称为Shuffle。在很多场景下,Shuffle是整个MapReduce过程的核心,也是“奇迹”发生的地方,如下图所示:
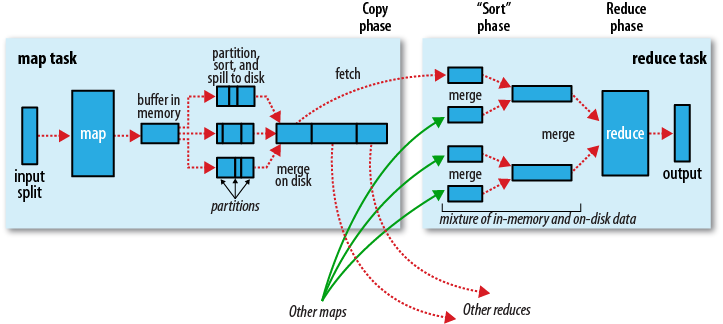
理解Shuffle的执行过程对我们优化MapReduce任务带来帮助。这里以Hadoop 0.20.2代码为基础进行介绍,同时也会涉及到如何扩展MapReduce组件,从而影响Shuffer的行为。
Map Task
Map Task产生输出的时候,并不是直接将数据写到本地磁盘,这个过程涉及到两个部分:写缓冲区、预排序。
(1)写缓冲区
每一个Map Task都拥有一个“环形缓冲区”作为Mapper输出的写缓冲区。写缓冲区大小默认为100MB(通过属性io.sort.mb调整),当写缓冲区的数据量达到一定的容量限额时(默认为80%,通过属性io.sort.spill.percent调整),后台线程开始将写缓冲区的数据溢写到本地磁盘。在数据溢写的过程中,只要写缓冲区没有被写满,Mappper依然可以将数据写出到缓冲区中;否则Mapper的执行过程将被阻塞,直到溢写结束。
溢写以循环的方式进行(即写缓冲区的数据量大致限额时就会执行溢写),可以通过属性mapred.local.dir指定写出的目录。
(2)预排序
溢写线程将数据最终写出到本地磁盘之前,首先根据Reducer的数目对这部分数据进行分区(即每一个分区中的数据会被传送至同一个Reducer进行处理,分区数目与Reducer数据保持一致),然后对每一个分区中的数据根据键值进行排序(预排序),如果MapReducer开启Combiner,则对该分区中排序后的数据执行Combine过程。Combine过程的执行“紧凑”了Mapper的输出结果,因此写入本地磁盘的数据量和传送给Reducer的数据量都会被减少,通常情况下能很大程序的提高MapReducer任务的效率。
每一次写缓冲达到溢写临界值时,都会形成一个新的溢写文件,因此当Map Task输出最后一个数据时,本地磁盘上会有多个溢写文件存在。在整个Map Task完成之前,这些溢写文件会被合并为一个分区且排序后的文件。合并可能分为多次,属性io.sort.factor控制一次最多合并多少个文件。
如果溢写文件个数超过3(通过属性min.num.spills.for.combine设置),会对合并且分区排序后的结果执行Combine过程(如果MapReduce有设置Combiner),而且combine过程在不影响最终结果的前提下可能会被执行多次;否则不会执行Combine过程(相对而言,Combine开销过大)。
如果溢写文件个数超过3(通过属性min.num.spills.for.combine设置),会对合并且分区排序后的结果执行Combine过程(如果MapReduce有设置Combiner),而且combine过程在不影响最终结果的前提下可能会被执行多次;否则不会执行Combine过程(相对而言,Combine开销过大)。
注意:Map Task执行过程中,Combine可能出现在两个地方:写缓冲区溢写过程中、溢写文件合并过程中。
通过对Map Task的输出结果进行压缩是一个好主意,可以加快写入磁盘的速度、节省磁盘空间以及减少需要传递给Reducer的数据量。默认情况下,压缩是不被开启的,可以通过属性mapred.compress.map.output、mapred.map.output.compression.codec进行相应设置。
以上两步主要对应着上图中"partition, sort, and spill to disk",但代码与实际执行过程略有不同。在Hadoop 0.20.2版本中,写缓冲区由org.apache.hadoop.mapred.MapTask.MapOutputBuffer实现,写缓冲区代码如下:
@Override
public void write(K key, V value) throws IOException,
InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
可以看出,在将Mapper的一条输出结果(由key、value表示)写出到写缓冲区之前,已经提前计算好相应的分区信息,即分区的过程在数据写入写缓冲区之前就已经完成,溢写过程实际是写缓冲区数据排序的过程(先按分区排序,如果分区相同时,再按键值排序)。
这里涉及到MapReduce的两个组件:Comparator、Partitioner。
(1)Comparator
Comparator不会影响对分区排序的过程,它影响的是对键值的排序过程,代码如下:
public int compare(int i, int j) {
final int ii = kvoffsets[i % kvoffsets.length];
final int ij = kvoffsets[j % kvoffsets.length];
// sort by partition
if (kvindices[ii + PARTITION] != kvindices[ij + PARTITION]) {
return kvindices[ii + PARTITION] - kvindices[ij + PARTITION];
}
// sort by key
return comparator.compare(kvbuffer, kvindices[ii + KEYSTART],
kvindices[ii + VALSTART] - kvindices[ii + KEYSTART],
kvbuffer, kvindices[ij + KEYSTART],
kvindices[ij + VALSTART] - kvindices[ij + KEYSTART]);
}
comparator的实例化是通过job.getOutputKeyComparator()完成的,代码如下:
public RawComparator getOutputKeyComparator() { Class<? extends RawComparator> theClass = getClass( "mapred.output.key.comparator.class", null, RawComparator.class); if (theClass != null) { return ReflectionUtils.newInstance(theClass, this); } return WritableComparator.get(getMapOutputKeyClass().asSubclass( WritableComparable.class)); }
由上述代码可以看出,comparator实例有两种提供方式,亦即我们可以自定义扩展组件Comparator的方式:
a. 继承接口RawComparator,并通过属性mapred.output.key.comparator.class进行配置;
b. 为Map Output Key(Map Output Key必须实现WritableComparable接口)设置相应的WritableComparator,并通过WritableComparator的静态方法define进行注册。
RawComparator接口代码如下:
public interface RawComparator<T> extends Comparator<T> { public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2); }
RawComparator有一个实现类WritableComparator,核心代码如下:
public class WritableComparator implements RawComparator { private static HashMap<Class, WritableComparator> comparators = new HashMap<Class, WritableComparator>(); public static synchronized WritableComparator get( Class<? extends WritableComparable> c) { WritableComparator comparator = comparators.get(c); if (comparator == null) { comparator = new WritableComparator(c, true); } return comparator; } public static synchronized void define(Class c, WritableComparator comparator) { comparators.put(c, comparator); } public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { try { // parse key1 buffer.reset(b1, s1, l1); key1.readFields(buffer); // parse key2 buffer.reset(b2, s2, l2); key2.readFields(buffer); } catch (IOException e) { throw new RuntimeException(e); } // compare them return compare(key1, key2); } public int compare(WritableComparable a, WritableComparable b) { return a.compareTo(b); } public int compare(Object a, Object b) { return compare((WritableComparable) a, (WritableComparable) b); } }
分区内排序的过程就是通过RawComparator compare方法完成的,而且WritableComparator为compare方法提供了默认实现,即首先将字节数据反序列化为相应的WritableComparable实例,然后再进行比较(a.compareTo(b)),由于存在反序列化的过程,带来一定的性能开销。
(2)Partitioner
组件Partitioner一方面影响MapReduce任务的正确性(某些场景下需要保证具有相同规则的MapOutKey进入同一个Reducer进行处理),另一方面解决数据传输过程(Mapper输出传送至Reducer)中“数据倾斜”的问题(某些场景下需要均衡各个Reducer处理的数据量)。
组件Partitioner通过抽象类org.apache.hadoop.mapreduce.Partitioner提供,代码如下:
public abstract class Partitioner<KEY, VALUE> { public abstract int getPartition(KEY key, VALUE value, int numPartitions); }
并且需要通过属性mapreduce.partitioner.class进行配置。
一般情况下,具体实现时通过key(可能会涉及到value)计算Hash值,并对numPartitions(分区数目、Reducer数目)取余即可。
Reduce Task
每一个Reduce Task仅仅运行属于它的那个分区的数据,而这些数据位于集群中运行Map Tasks的节点的本地磁盘上(Map的输出结果位于运行该Map Task的节点的本地磁盘上,结果包含着多个分区的数据)。这些Map Tasks完成于不同的时间,因此Reduce Task在某一个Map Task运行完成后便立即开始拷贝它的输出结果(通过JobTracker与TaskTracker的交互获取通知),Reduce Task的这个阶段被称为“Copy Phase”。Reduce Task拥有少量的线程用于并行地获取Map Tasks的输出结果,默认线程数为5,可以通过属性mapred.reduce.parallel.copies进行设置。
如果Map Task的输出结果足够小,它会被拷贝至Reduce Task的缓冲区中;否则拷贝至磁盘。当缓冲区中的数据达到一定量(由属性mapred.job.shuffle.merge.percent、mapred.inmem.merge.threshold),这些数据将被合并且溢写到磁盘。如果Combine过程被指定,它将在合并过程被执行,用来减少需要写出到磁盘的数据量。
随着拷贝文件中磁盘上的不断积累,一个后台线程会将它们合并为更大地、有序的文件,用来节省后期的合并时间。如果Map Tasks的输出结合使用了压缩机制,则在合并的过程中需要对数据进行解压处理。
当Reduce Task的所有Map Tasks输出结果均完成拷贝,Reduce Task进入“Sort Phase”(更为合适地应该被称为“Merge Phase”,排序在Map阶段已经被执行),该阶段在保持原有顺序的情况下进行合并。这种合并是以循环方式进行的,循环次数与合并因子(io.sort.factor)有关。
Sort Phase通常不会合并为一个有序的文件,也就是“Merge Phase”的最后一次合并将被省略,省去一次磁盘操作,直接将数据“合并输入”至Reduce相应方法(这次合并的数据可以结合内存、磁盘两部分进行操作),即“Reduce Phase”。
在Reduce Phase的过程中,它处理的是所有Map Tasks输出结果中某一个分区中的所有数据,这些数据整体表现为一个根据键有序的输入,对于每一个键都会相应地调用一次Reduce Function(同一个键对应的值可能有多个,这些值将作为Reduce Function的参数),如下:
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) throws IOException, InterruptedException { ...... }
通常Reduce Function的结果被直接写出至HDFS。
这里需要重点理解一下“同一个键”,上面的描述实际隐藏了一个被称为“Group”的阶段,这个阶段决定着哪些键值对属于同一个键。如果没有特殊设置,只有在Map Task输出时那些键完全一样的数据属于同一个键,但这是可以被改变的,如下所示:
(a,b,c : 1)
(a,b,c : 2)
(a,c,e : 3)
(b,c,d : 4)
......
如果没有特殊设置,(a,b,c : 1)、(a,b,c : 2)会一并Reduce Function,而(a,c,e : 3)、(b,c,d : 4)会分别进入Reduce Function。
如果我们的计算需求要求我们统计键的第一个字母相同的所有值的和,这时就要求我们将(a,b,c : 1)、(a,b,c : 2)、(a,c,e : 3)合并进入Reduce Function,而且它们的键值为a,b,c,即第一个键值对的键值。
Group阶段决定哪些键值对属于同一个键的计算过程实际也是由一个RawComparator完成的,由属性mapred.output.value.groupfn.class决定,其实就是在键值对不断输入的过程中检查下一个键是否与当前键一致,从而决定哪些键值对属于同一个键。
一般情况下,Combiner与Reducer实际上是同一个类,亦即Combiner也存在Group阶段,但是要注意,Combiner(可能发生于三个地方)与Reducer在Group阶段使用的RawComparator是不一样的,Combiner使用的RawComparator由mapred.output.key.comparator.class指定,而Reducer使用的RawComparator由mapred.output.value.groupfn.class指定。
结语
通常MapReduce被人们粗略地认为只有两个阶段,即Map阶段、Reduce阶段,通过上面的介绍我们可以了解到在Map与Reduce之间存在着很复杂的Shuffle操作,涉及到数据的partition、sort、[combine]、spill、[comress]、[merge]、copy、[combine]、merge、group,而这些操作不但决定着程序逻辑的正确性,也决定着MapReduce的运行效率。

