
DQN-深度Q网络
深度Q网络是用深度学习来解决强化中Q学习的问题,可以先了解一下Q学习的过程是一个怎样的过程,实际上就是不断的试错,从试错的经验之中寻找最优解
关于Q学习,我看到一个非常好的例子,另外知乎上面也有相关的讨论
其实早在13年的时候,deepmind出来了第一篇用深度学习来解决Q学习的问题的paper,那个时候deepmind还不够火,和一般的Q学习不同的是,由于12年Alex率先用CNN解决图像中的high level的语义的提取,deepmind也同时采用了CNN来直接对图像进行特征提取,而非传统的进行手工特征提取
我想从代码的角度来看一下DQN是如何实现的
pytorcyh的代码在官网上是有的,我也贴出了自己添加了注释的代码,以及写一下自己的对于代码的理解


1 # -*-coding:utf-8-*- 2 import gym 3 import math 4 import random 5 import numpy as np 6 import matplotlib 7 import matplotlib.pyplot as plt 8 from collections import namedtuple 9 from itertools import count 10 from PIL import Image 11 12 import torch 13 import torch.nn as nn 14 import torch.optim as optim 15 import torch.nn.functional as F 16 import torchvision.transforms as T 17 18 19 env = gym.make('CartPole-v0').unwrapped 20 21 # set up matplotlib 22 is_ipython = 'inline' in matplotlib.get_backend() 23 if is_ipython: 24 from IPython import display 25 26 plt.ion() 27 28 # if gpu is to be used 29 # device = torch.device("cuda" if torch.cuda.is_available() else "cpu") 30 31 Transition = namedtuple('Transition', 32 ('state', 'action', 'next_state', 'reward')) # 声明一个name为Transition,里面的变量为以下的类似dict的 33 34 35 class ReplayMemory(object): 36 37 def __init__(self, capacity): 38 self.capacity = capacity 39 self.memory = [] 40 self.position = 0 41 42 def push(self, *args): 43 """Saves a transition.""" 44 if len(self.memory) < self.capacity: 45 self.memory.append(None) 46 self.memory[self.position] = Transition(*args) 47 self.position = (self.position + 1) % self.capacity 48 49 def sample(self, batch_size): 50 return random.sample(self.memory, batch_size) 51 52 def __len__(self): # 定义__len__以便于用len函数? 53 return len(self.memory) 54 55 56 class DQN(nn.Module): 57 58 def __init__(self): 59 super(DQN, self).__init__() 60 self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2) 61 self.bn1 = nn.BatchNorm2d(16) 62 self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2) 63 self.bn2 = nn.BatchNorm2d(32) 64 self.conv3 = nn.Conv2d(32, 32, kernel_size=5, stride=2) 65 self.bn3 = nn.BatchNorm2d(32) 66 self.head = nn.Linear(448, 2) 67 68 def forward(self, x): 69 x = F.relu(self.bn1(self.conv1(x))) 70 x = F.relu(self.bn2(self.conv2(x))) 71 x = F.relu(self.bn3(self.conv3(x))) 72 return self.head(x.view(x.size(0), -1)) 73 74 75 resize = T.Compose([T.ToPILImage(), 76 T.Resize(40, interpolation=Image.CUBIC), 77 T.ToTensor()]) 78 79 # This is based on the code from gym. 80 screen_width = 600 81 82 83 def get_cart_location(): 84 world_width = env.x_threshold * 2 85 scale = screen_width / world_width 86 return int(env.state[0] * scale + screen_width / 2.0) # MIDDLE OF CART 87 88 89 def get_screen(): 90 screen = env.render(mode='rgb_array').transpose( 91 (2, 0, 1)) # transpose into torch order (CHW) 92 # Strip off the top and bottom of the screen 93 screen = screen[:, 160:320] 94 view_width = 320 95 cart_location = get_cart_location() 96 if cart_location < view_width // 2: 97 slice_range = slice(view_width) 98 elif cart_location > (screen_width - view_width // 2): 99 slice_range = slice(-view_width, None) 100 else: 101 slice_range = slice(cart_location - view_width // 2, 102 cart_location + view_width // 2) 103 # Strip off the edges, so that we have a square image centered on a cart 104 screen = screen[:, :, slice_range] 105 # Convert to float, rescare, convert to torch tensor 106 # (this doesn't require a copy) 107 screen = np.ascontiguousarray(screen, dtype=np.float32) / 255 108 screen = torch.from_numpy(screen) 109 # Resize, and add a batch dimension (BCHW) 110 return resize(screen).unsqueeze(0).cuda() 111 112 113 env.reset() 114 # plt.figure() 115 # plt.imshow(get_screen().cpu().squeeze(0).permute(1, 2, 0).numpy(), 116 # interpolation='none') 117 # plt.title('Example extracted screen') 118 # plt.show() 119 BATCH_SIZE = 128 120 GAMMA = 0.999 121 EPS_START = 0.9 122 EPS_END = 0.05 123 EPS_DECAY = 200 124 TARGET_UPDATE = 10 125 126 policy_net = DQN().cuda() 127 target_net = DQN().cuda() 128 target_net.load_state_dict(policy_net.state_dict()) 129 target_net.eval() 130 131 optimizer = optim.RMSprop(policy_net.parameters()) 132 memory = ReplayMemory(10000) 133 134 135 steps_done = 0 136 137 138 def select_action(state): 139 global steps_done 140 sample = random.random() 141 eps_threshold = EPS_END + (EPS_START - EPS_END) * \ 142 math.exp(-1. * steps_done / EPS_DECAY) 143 steps_done += 1 144 if sample > eps_threshold: 145 with torch.no_grad(): 146 return policy_net(state).max(1)[1].view(1, 1) # policy网络的输出 147 else: 148 return torch.tensor([[random.randrange(2)]], dtype=torch.long).cuda() # 随机的选择一个网络的输出或者 149 150 151 episode_durations = [] 152 153 154 def plot_durations(): 155 plt.figure(2) 156 plt.clf() 157 durations_t = torch.tensor(episode_durations, dtype=torch.float) 158 plt.title('Training...') 159 plt.xlabel('Episode') 160 plt.ylabel('Duration') 161 plt.plot(durations_t.numpy()) 162 # Take 100 episode averages and plot them too 163 if len(durations_t) >= 100: 164 means = durations_t.unfold(0, 100, 1).mean(1).view(-1) 165 means = torch.cat((torch.zeros(99), means)) 166 plt.plot(means.numpy()) 167 168 plt.pause(0.001) # pause a bit so that plots are updated 169 if is_ipython: 170 display.clear_output(wait=True) 171 display.display(plt.gcf()) 172 173 174 def optimize_model(): 175 if len(memory) < BATCH_SIZE: 176 return 177 transitions = memory.sample(BATCH_SIZE) # 进行随机的sample,序列问题是不存在的 178 # print(transitions) 179 # Transpose the batch (see http://stackoverflow.com/a/19343/3343043 for 180 # detailed explanation). 181 batch = Transition(*zip(*transitions)) 182 # print("current") 183 # print(batch.state[0]) 184 # print("next") 185 # print(batch.next_state[0]) 186 # print(torch.sum(batch.state[0])) 187 # print(torch.sum(batch.next_state[0])) 188 # print(torch.sum(batch.state[1])) 189 # # print(type(batch)) 190 # print("@#$%^&*") 191 192 # Compute a mask of non-final states and concatenate the batch elements 193 non_final_mask = torch.tensor(tuple(map(lambda s: s is not None, batch.next_state)), dtype=torch.uint8).cuda() # lambda表达式返回的是否为空的二值 194 non_final_next_states = torch.cat([s for s in batch.next_state if s is not None]) # 空的不cat,所以长度不一定是batchsize 195 # print("the non_final_mask is") 196 # print(non_final_mask) 197 # none_total = 0 198 # total = 0 199 # for s in batch.next_state: 200 # if s is None: 201 # none_total = none_total + 1 202 # else: 203 # total = total + 1 204 # print(none_total, total) 205 state_batch = torch.cat(batch.state) 206 action_batch = torch.cat(batch.action) 207 reward_batch = torch.cat(batch.reward) 208 # print(action_batch) # 非0即1 209 # print(reward_batch) 210 # print(len(non_final_mask)) 211 # Compute Q(s_t, a) - the model computes Q(s_t), then we select the 212 # columns of actions taken 213 state_action_values = policy_net(state_batch).gather(1, action_batch) # gather将torch.tensor的中对应于action的index取出,dim为1 214 # 从整体公式上而言,Q函数的值即为state_action_value的值 215 # print((policy_net(state_batch))) 216 # print(state_action_values) 217 # Compute V(s_{t+1}) for all next states. 218 next_state_values = torch.zeros(BATCH_SIZE).cuda() 219 # print(next_state_values) 220 # print("no final mask") 221 # print(non_final_mask) 222 # print("@#$%^&*") 223 next_state_values[non_final_mask] = target_net(non_final_next_states).max(1)[0].detach() # non_final_mask为1的地方进行赋值操作,其余仍为0 224 # print(target_net(non_final_next_states).max(1)[0].detach()) 225 # print("12345") 226 # print(next_state_values) 227 # Compute the expected Q values 228 expected_state_action_values = (next_state_values * GAMMA) + reward_batch 229 230 # Compute Huber loss 231 loss = F.smooth_l1_loss(state_action_values, expected_state_action_values.unsqueeze(1)) 232 233 # compare the parameters of 2 networks 234 print(policy_net.state_dict()['head.bias']) 235 print("!@#$%^&*") 236 print(target_net.state_dict()['head.bias']) 237 238 # Optimize the model 239 optimizer.zero_grad() 240 loss.backward() 241 for param in policy_net.parameters(): 242 param.grad.data.clamp_(-1, 1) 243 optimizer.step() 244 245 246 num_episodes = 50 247 for i_episode in range(num_episodes): 248 # print("the episode is %f" % i_episode) 249 # Initialize the environment and state 250 env.reset() 251 last_screen = get_screen() 252 # print(last_screen) 253 # print("#QW&*!$") 254 current_screen = get_screen() # 得到一张图片,而非一个batch 255 # print(current_screen) 256 state = current_screen - last_screen # 两帧之间的差值,作为一个state,并且输入网络,类比于RNN对pose的估计 257 for t in count(): # 创建一个无限循环迭代器,t的数值会一直增加 258 # Select and perform an action 259 action = select_action(state) 260 _, reward, done, _ = env.step(action.item()) # done表示游戏是否结束, reward由gym内部决定;输入action,gym展示下一个状态 261 reward = torch.tensor([reward]).cuda() 262 263 # Observe new state 264 last_screen = current_screen 265 current_screen = get_screen() 266 if not done: 267 next_state = current_screen - last_screen 268 else: 269 next_state = None 270 271 # Store the transition in memory 272 memory.push(state, action, next_state, reward) # memory存储state,action,next_state,以及对应的reward 273 # print("the length of the memory is %d" % len(memory)) 274 # Move to the next state 275 state = next_state 276 277 # Perform one step of the optimization (on the target network) 278 optimize_model() 279 if done: 280 episode_durations.append(t + 1) 281 plot_durations() 282 break 283 # Update the target network 284 if i_episode % TARGET_UPDATE == 0: # 只有在某个频率下才会update target网络结构 285 target_net.load_state_dict(policy_net.state_dict()) 286 287 print('Complete') 288 env.render() 289 env.close() 290 plt.ioff() 291 plt.show() 292 env.close()
作者调用了一个gym的库,这个库可以用作强化学习的训练样本,但是蛋疼的是,在用pycharm进行debug的时候,gym库总会报错,如果直接运行则不会,我想可能是因为gym库并不可以进行调试
anyway,代码的总体流程是,调用gym,声明一个事件,在强化学习中被称为agent,这个agent会展示当前的状态,然后会接收一个action,输出下一个的状态以及这个action所得到的奖励,ok,至于这个agent采取了action之后所得到的奖励是如何计算的,
这个agent采取了这个action下一个状态是啥,gym已经给你们写好了
在定义网络结构之前,作者实际上是把自己试错的状态存储了起来,存储的内容有,当前的state,采取action,以及nextstate,以及这个action相应的reward,而state并不是当前游戏的截屏,而是两帧之间的差值,reward是gym自己返回的
至于为什么这样做?有点儿类似与用RNN解决slam的问题,为什么输入到网络中的是视频两帧之间的差值,而不是视频自己本身的内容,要给自己挖个坑
存储了这些状态之后就可以训练网络了,主体的网络结构如下
1 class DQN(nn.Module): 2 3 def __init__(self): 4 super(DQN, self).__init__() 5 self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2) 6 self.bn1 = nn.BatchNorm2d(16) 7 self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2) 8 self.bn2 = nn.BatchNorm2d(32) 9 self.conv3 = nn.Conv2d(32, 32, kernel_size=5, stride=2) 10 self.bn3 = nn.BatchNorm2d(32) 11 self.head = nn.Linear(448, 2) 12 13 def forward(self, x): 14 x = F.relu(self.bn1(self.conv1(x))) 15 x = F.relu(self.bn2(self.conv2(x))) 16 x = F.relu(self.bn3(self.conv3(x))) 17 return self.head(x.view(x.size(0), -1))
网络输出的两个值,分别是对应不同的action,其实也不难理解,训练的网络最终能够产生的输出当然是决策是怎样的,不过这种自己不断的试错,并且把自己试错的数据保存下来,严格意义上来说真的是无监督学习?
anyway,作者用这些试错的数据进行训练
不过,网络的loss怎么设计?
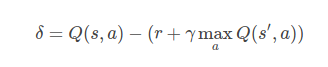
loss如上,实际上就是求取两个Q函数之间的差值,ok,前一个Q函数的自变量描述的是当前的状态s以及对应的行为a,后一个r+Q描述的是当前的reward加上,在下一个state如何采取下一步行动能够让Q最大的项
而这两项如何在代码中体现,实际上作者定义了两个网络,一个成为policy,另外一个为target网络
优化的目标是policy net,target网络为定期对policy的copy,如下
1 # Update the target network 2 if i_episode % TARGET_UPDATE == 0: # 只有在某个频率下才会update target网络结构 3 target_net.load_state_dict(policy_net.state_dict())
policy net输入state batch,并且将实际中的对应的action的那一列输出,action非0即1,所以policy_net输出的是batch_size的列向量
在这段代码中,这个网络的输出就是Q函数的值,
target_net网络输入的是next_state,并且因为不知道其实际的action是多少,所以取最大的,输出乘以一个gamma,并且加上当前状态的reward即可
其实永远是policy_net更新在前,更新的方向是让两个网络的输出尽可能的接近,其实也不仅仅是这样,这中间还有一个reward变量,可是为什么target_net的更新要永远滞后,一种更加极端的情况是,如果把next_state输入到policy网络中呢?
posted on 2018-05-05 18:31 YongjieShi 阅读(4635) 评论(0) 编辑 收藏 举报


