
pytorch实现rnn并且对mnist进行分类
1.RNN简介
rnn,相比很多人都已经听腻,但是真正用代码操练起来,其中还是有很多细节值得琢磨。
虽然大家都在说,我还是要强调一次,rnn实际上是处理的是序列问题,与之形成对比的是cnn,cnn不能够处理序列问题,因为它没有记忆能力,那为什么rnn能够处理序列问题以及有记忆能力呢?
首先简单介绍一下rnn以及lstm的背景,这里给出两个链接,链接1,链接2
以最简单的rnn为例,如下图
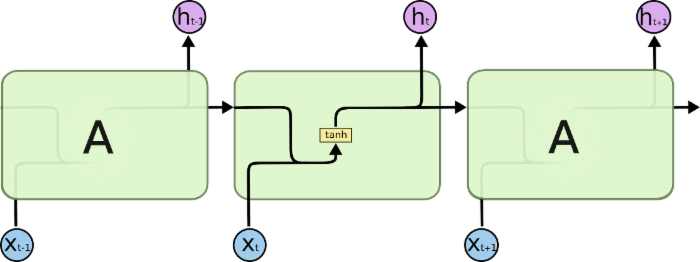
上面是rnn展开成3个单元的结构示意图,h_t是上一个时刻的输出,这个输出送到下一个时刻的输入;x_t是当前时刻的输入,h_t是当前时刻的输出,这个输出有两个用途,第一个当然还是作为当前时刻的输出,另外一个作用是作为下一个时刻的输出,所以你不难理解,为什么rnn有记忆能力,因为,下一个单元的输入是综合当前时刻的输入x_t与上一个时刻的输出h_t-1啊,所以rnn的记忆功能体现在这个地方
h_t-1与x_t经过concatenate之后经过一个权重相乘,然后加上一个偏执bias,经过一个tanh函数,就成了h_t,非常简单
公式如下
非常简单,那么问题来了
大家经常所说的是rnn展开之后像上面这一个图一样,那么不展开呢?
大概是像这样
实际上这是非常合理的,为什么呢?因为其实对于一层的rnn而言,看上面的公式,确实是只有一个w_ih,b_ih,w_hh,b_hh.记住这个是非常重要的,因为一开始的时候大家都可能会有一个误解说,为什么应该是同一个权重,为什么不是不同的权重?
我觉得,在nlp领域,假如你输入的是一个序列,就是一个句子,每个句子中的每个单词经过word2vec变换成一个向量,这个句子有长有短,而对不不同长度的句子,难不成rnn上面展开的单元的个数还是变换的?这显然是不可能的!如果这还说服不了你,那稍后看pytorch代码
刚刚还说到,关于rnn的层数的问题,这个层数很容易误解为第一个图那样展开,实际上和展开没有半毛钱关系,展开的长度随着输入的序列的长短决定,层数的定义实际上是如下这样
即是往上延伸的,输出的h_t还是会网上继续输入,t时刻的输出是h_t^',而不是h_t。
2.pytorch实现rnn
考虑到rnn的记忆特性,即rnn能够记住前面的东西,这样是否可行:即我每一时刻输入的是一个vector,这个vector对应的是图像的某一列,有多少列就对应多少时刻,那最后一个时刻输入的是最后一列,rnn最后输出的h_t实际上就是对应的哪一个类别,实际上这样是行得通的
说干就干


1 # -*-coding: utf-8 -*- 2 import torch 3 import torch.nn as nn 4 import torchvision.datasets as dsets 5 import torchvision.transforms as transforms 6 from torch.autograd import Variable 7 8 9 # Hyper Parameters 10 sequence_length = 28 # 序列长度,将图像的每一列作为一个序列 11 input_size = 28 # 输入数据的维度 12 hidden_size = 128 # 隐藏层的size 13 num_layers = 2 # 有多少层 14 15 num_classes = 10 16 batch_size = 100 17 num_epochs = 20 18 learning_rate = 0.01 19 20 # MNIST Dataset 21 train_dataset = dsets.MNIST(root='./data/', 22 train=True, 23 transform=transforms.ToTensor(), 24 download=True) 25 26 test_dataset = dsets.MNIST(root='./data/', 27 train=False, 28 transform=transforms.ToTensor()) 29 30 # Data Loader (Input Pipeline) 31 train_loader = torch.utils.data.DataLoader(dataset=train_dataset, 32 batch_size=batch_size, 33 shuffle=True) 34 35 test_loader = torch.utils.data.DataLoader(dataset=test_dataset, 36 batch_size=batch_size, 37 shuffle=False) 38 39 # RNN Model (Many-to-One) 40 class RNN(nn.Module): 41 def __init__(self, input_size, hidden_size, num_layers, num_classes): 42 super(RNN, self).__init__() 43 self.hidden_size = hidden_size 44 self.num_layers = num_layers 45 self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True) # batch_first=True仅仅针对输入而言 46 self.fc = nn.Linear(hidden_size, num_classes) 47 48 def forward(self, x): 49 # 设置初始状态h_0与c_0的状态是初始的状态,一般设置为0,尺寸是,x.size(0) 50 h0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size).cuda()) 51 c0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size).cuda()) 52 53 # Forward propagate RNN 54 out, (h_n, c_n) = self.lstm(x, (h0, c0)) # 送入一个初始的x值,作为输入以及(h0, c0) 55 56 # Decode hidden state of last time step 57 out = self.fc(out[:, -1, :]) # output也是batch_first, 实际上h_n与c_n并不是batch_first 58 return out 59 60 rnn = RNN(input_size, hidden_size, num_layers, num_classes) 61 rnn.cuda() 62 63 # Loss and Optimizer 64 criterion = nn.CrossEntropyLoss() 65 optimizer = torch.optim.Adam(rnn.parameters(), lr=learning_rate) 66 67 # Train the Model 68 for epoch in range(num_epochs): 69 for i, (images, labels) in enumerate(train_loader): 70 # a = images.numpy() 71 images = Variable(images.view(-1, sequence_length, input_size)).cuda() # 100*1*28*28 -> 100*28*28 72 # b = images.data.cpu().numpy() 73 labels = Variable(labels).cuda() 74 75 # Forward + Backward + Optimize 76 optimizer.zero_grad() 77 outputs = rnn(images) 78 loss = criterion(outputs, labels) 79 loss.backward() 80 optimizer.step() 81 82 if (i+1) % 100 == 0: 83 print ('Epoch [%d/%d], Step [%d/%d], Loss: %.4f' 84 %(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.data[0])) 85 86 # Test the Model 87 correct = 0 88 total = 0 89 for images, labels in test_loader: 90 images = Variable(images.view(-1, sequence_length, input_size)).cuda() 91 outputs = rnn(images) 92 _, predicted = torch.max(outputs.data, 1) 93 total += labels.size(0) 94 correct += (predicted.cpu() == labels).sum() 95 96 print('Test Accuracy of the model on the 10000 test images: %d %%' % (100 * correct / total)) 97 98 # Save the Model 99 torch.save(rnn.state_dict(), 'rnn.pkl')
在实际上用的时候,我并没有调用rnn,而是用lstm类
# RNN Model (Many-to-One) class RNN(nn.Module): def __init__(self, input_size, hidden_size, num_layers, num_classes): super(RNN, self).__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True) # batch_first=True仅仅针对输入而言 self.fc = nn.Linear(hidden_size, num_classes) def forward(self, x): # 设置初始状态h_0与c_0的状态是初始的状态,一般设置为0,尺寸是,x.size(0) h0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size).cuda()) c0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size).cuda()) # Forward propagate RNN out, (h_n, c_n) = self.lstm(x, (h0, c0)) # 送入一个初始的x值,作为输入以及(h0, c0) # Decode hidden state of last time step out = self.fc(out[:, -1, :]) # output也是batch_first, 实际上h_n与c_n并不是batch_first return out
实际上是定义了一个lstm,lstm输出的out最后一个,实际上也就是h_n^',这个参数送到一个全连接层,这个全连接层最后输出的是10类别
loss由softmax定义
mages = Variable(images.view(-1, sequence_length, input_size)).cuda() # 100*1*28*28 -> 100*28*28
作者经过这样的操作能够得到batchsize×sequence×length的向量,输入到rnn中,由于作者设置了batch_first,所以第一个维度是batch,第二个维度是sequence,那么就可以把没衣服图像的每一列当做一个时刻输入到网络中的一个vector
然后反传,优化
实际上我把训练的loss画出来,发现loss振荡非常剧烈
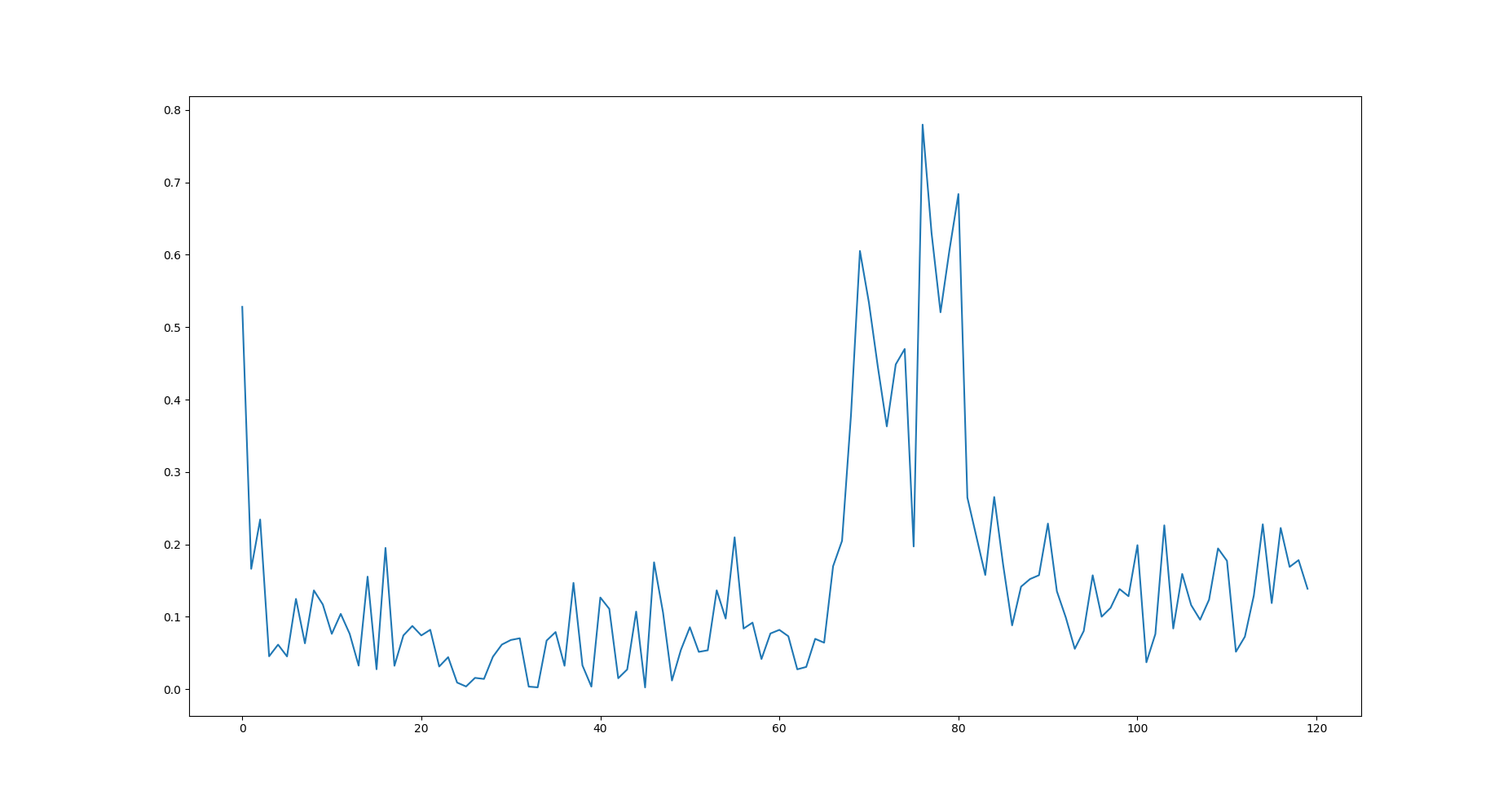
尽管最后的精度能够达到93%左右,确实能够发现网络不稳定
posted on 2018-01-25 19:35 YongjieShi 阅读(12170) 评论(1) 编辑 收藏 举报


