

环境搭建
1、到apache下载solr(4..9.0),百度云盘下载地址:链接: https://pan.baidu.com/s/1cq8s6E 密码: zse7
2、解压到某个目录
3、cd into D:\Solr\solr-4.10.3\example
4、Execute the server by “java -jar startup.jar”Solr会自动运行在自带的Jetty上
也可以在example的同级目录下写一个命令脚本,命名为start.bat,脚本内容具体如下:
1 @echo off 2 title 启动服务 3 cd example 4 java -jar start.jar 5 pause
5、访问http://localhost:8983/solr/#/
PS:solr-5.0 以上默认对schema的管理是使用managed-schema,不能手动修改,需要使用Schema Restful的API操作。如果要想手动修改配置,把managed-schema拷贝一份修改为schema.xml,在solrconfig.xml中修改如下:
<!-- <schemaFactory class="ManagedIndexSchemaFactory">
<bool name="mutable">true</bool>
<str name="managedSchemaResourceName">managed-schema</str>
</schemaFactory> -->
<!-- <processor class="solr.AddSchemaFieldsUpdateProcessorFactory">
<str name="defaultFieldType">strings</str>
<lst name="typeMapping">
<str name="valueClass">java.lang.Boolean</str>
<str name="fieldType">booleans</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.util.Date</str>
<str name="fieldType">tdates</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Long</str>
<str name="valueClass">java.lang.Integer</str>
<str name="fieldType">tlongs</str>
</lst>
<lst name="typeMapping">
<str name="valueClass">java.lang.Number</str>
<str name="fieldType">tdoubles</str>
</lst>
</processor> -->
<schemaFactory class="ClassicIndexSchemaFactory"/>
创建MySQL数据
DataBase Name: mybatis
Table Name: user
Db.sql
1 SET FOREIGN_KEY_CHECKS=0; 2 -- ---------------------------- 3 -- Table structure for `user` 4 -- ---------------------------- 5 DROP TABLE IF EXISTS `user`; 6 7 CREATE TABLE `user` ( 8 `id` int(11) NOT NULL AUTO_INCREMENT, 9 `userName` varchar(50) DEFAULT NULL, 10 `userAge` int(11) DEFAULT NULL, 11 `userAddress` varchar(200) DEFAULT NULL, 12 PRIMARY KEY (`id`) 13 ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8; 14 15 -- ---------------------------- 16 -- Records of user 17 -- ---------------------------- 18 INSERT INTO `user` VALUES ('1', 'summer', '30', 'shanghai'); 19 INSERT INTO `user` VALUES ('2', 'test1', '22', 'suzhou'); 20 INSERT INTO `user` VALUES ('3', 'test1', '29', 'some place'); 21 INSERT INTO `user` VALUES ('4', 'lu', '28', 'some place'); 22 INSERT INTO `user` VALUES ('5', 'xiaoxun', '27', 'nanjing');
使用DataImportHandler导入并索引数据
1) 配置D:\Solr\solr-4.10.3\example\solr\collection1\conf\solrconfig.xml
在<requestHandler name="/select" class="solr.SearchHandler">前面上加上一个dataimport的处理的Handler
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
高亮配置
1 <requestHandler name="/select" class="solr.SearchHandler"> 2 <lst name="defaults"> 3 <str name="echoParams">explicit</str> 4 <int name="rows">10</int> 5 <str name="df">text</str> 6 <str name="hl">true</str> 7 <str name="hl.fl">name</str> 8 <str name="f.name.hl.fragsize">50</str> 9 <str name="hl.simple.pre"><font color="red"></str> 10 <str name="hl.simple.post"></font></str> 11 </lst> 12 </requestHandler>
2) 在同目录下添加data-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/mybatis" user="root" password="luxx" batchSize="-1" />
<document name="testDoc">
<entity name="user" pk="id"
query="select * from user">
<field column="id" name="id"/>
<field column="userName" name="userName"/>
<field column="userAge" name="userAge"/>
<field column="userAddress" name="userAddress"/>
</entity>
</document>
</dataConfig>
说明:
dataSource是数据库数据源。
Entity就是一张表对应的实体,pk是主键,query是查询语句。
Field对应一个字段,column是数据库里的column名,后面的name属性对应着Solr的Filed的名字。
3) 修改同目录下的schema.xml,这是Solr对数据库里的数据进行索引的模式
(1)保留_version_ 这个field
(2)添加索引字段:这里每个field的name要和data-config.xml里的entity的field的name一样,一一对应。
<field name="id" type="int" indexed="true" stored="true" required="true" multiValued="false" /> <!--<field name="id" type="int" indexed="true" stored="true" required="true" multiValued="false"/> --> <field name="userName" type="text_general" indexed="true" stored="true" /> <field name="userAge" type="int" indexed="true" stored="true" /> <field name="userAddress" type="text_general" indexed="true" stored="true" />
(3)删除多余的field,删除copyField里的设置,这些用不上。注意:text这个field不能删除,否则Solr启动失败。
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
(4)设置唯一主键:<uniqueKey>id</uniqueKey>,注意:Solr中索引的主键默认是只支持type="string"字符串类型的,而我的数据库中id是int型的,会有问题,解决方法:修改同目录下的elevate.xml,注释掉下面2行,这貌似是Solr的Bug,原因不明。
<doc id="MA147LL/A" /> <doc id="IW-02" exclude="true" />
4)拷贝mysql-connector-java-5.1.22-bin.jar(百度云盘下载地址:链接: https://pan.baidu.com/s/1hrFOste 密码: 6gt5)和solr-dataimporthandler-4.10.3.jar(百度云盘下载地址:链接: https://pan.baidu.com/s/1jHPT9QI 密码: jfyr)到D:\Solr\solr-4.10.3\example\solr-webapp\webapp\WEB-INF\lib。一个是mysql的java驱动,另一个在D:\Solr\solr-4.10.3\dist目录里,是org.apache.solr.handler.dataimport.DataImportHandler所在的jar。
重启Solr。
如果配置正确就可以启动成功。
solrconfig.xml是solr的基础文件,里面配置了各种web请求处理器、请求响应处理器、日志、缓存等。
schema.xml配置映射了各种数据类型的索引方案。分词器的配置、索引文档中包含的字段也在此配置。
索引测试
进入Solr主页,在Core Selector中选择collection1:http://localhost:8983/solr/#/collection1
点击Dataimport,Command选择full-import(默认),点击“Execute”,Refresh Status就可以看到结果:
Indexing completed. Added/Updated: 7 documents.Deleted 0 documents.
Requests: 1, Fetched: 7, Skipped: 0, Processed: 7
Started: 8 minutes ago
Query测试:在q中输入userName:test1进行检索就可以看到结果。
这里使用full-import索引了配置数据库中的全部数据,使用Solr可以查询对应的数据。
使用Solrj索引并检索数据
上面是使用Solr Admin页面上的功能测试索引和检索,也可以使用代码来操作Solr,下面的代码测试了在Solr索引中添加了一个User类实体,并通过查找所有的index来返回结果。
User实体类:
package com.mybatis.test.model;
import org.apache.solr.client.solrj.beans.Field;
public class User {
@Field
private int id;
@Field
private String userName;
@Field
private int userAge;
@Field
private String userAddress;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public int getUserAge() {
return userAge;
}
public void setUserAge(int userAge) {
this.userAge = userAge;
}
public String getUserAddress() {
return userAddress;
}
public void setUserAddress(String userAddress) {
this.userAddress = userAddress;
}
@Override
public String toString() {
return this.userName + " " + this.userAge + " " + this.userAddress;
}
}
使用@Field注解的属性要和Solr配置的Field对应。
测试代码:
package com.solr.test;
import java.io.IOException;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.client.solrj.response.UpdateResponse;
import org.apache.solr.common.SolrDocumentList;
import com.mybatis.test.model.User;
public class SolrTest {
private static SolrServer server;
private static final String DEFAULT_URL = "http://localhost:8983/solr/collection1";
public static void init() {
server = new HttpSolrServer(DEFAULT_URL);
}
public static void indexUser(User user){
try {
//添加user bean到索引库
try {
UpdateResponse response = server.addBean(user);
server.commit();
System.out.println(response.getStatus());
} catch (IOException e) {
e.printStackTrace();
}
} catch (SolrServerException e) {
e.printStackTrace();
}
}
//测试添加一个新的bean实例到索引
public static void testIndexUser(){
User user = new User();
user.setId(8);
user.setUserAddress("place");
user.setUserName("cdebcdccga");
user.setUserAge(83);
indexUser(user);
}
public static void testQueryAll() {
SolrQuery params = new SolrQuery();
// 查询关键词,*:*代表所有属性、所有值,即所有index
params.set("q", "*:*");
// 分页,start=0就是从0开始,rows=5当前返回5条记录,第二页就是变化start这个值为5就可以了。
params.set("start", 0);
params.set("rows", Integer.MAX_VALUE);
// 排序,如果按照id排序,那么将score desc 改成 id desc(or asc)
// params.set("sort", "score desc");
params.set("sort", "id asc");
// 返回信息*为全部,这里是全部加上score,如果不加下面就不能使用score
params.set("fl", "*,score");
QueryResponse response = null;
try {
response = server.query(params);
} catch (SolrServerException e) {
e.printStackTrace();
}
if(response!=null){
System.out.println("Search Results: ");
SolrDocumentList list = response.getResults();
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
public static void main(String[] args) {
init();
//testIndexUser();
testQueryAll();
}
}
如果在数据库中添加一条数据,但是Solr索引中没有index这条数据,就查不到,所以一般在使用Solr检索数据库里的内容时,都是先插入数据库,再在Solr中index这条数据,使用Solr的模糊查询或是分词功能来检索数据库里的内容。
Solr配置多核
进入solr-4.9.0\example下,复制collection1文件夹并重命名为collection2,进入collection2\conf,编辑core.properties文件,将name=collection1改为name=collection2,也就是复制后的文件夹名称,多核就配置好了
配置IKAnalyzer中文分词
下载IK Analyzer 2012FF_hf1.zip,百度云盘下载地址:链接: https://pan.baidu.com/s/1dFIm4lr 密码: nfz4,将解压后的IKAnalyzer2012FF_u1.jar放到solr-4.9.0\example\solr-webapp\webapp\WEB-INF\lib下,将IKAnalyzer.cfg.xml、stopword.dic放到solr-4.9.0\example\solr-webapp\webapp\WEB-INF\classes下,没有classes文件夹就创建一个。
打开solr-4.9.0\example\solr\collection1\conf\schema.xml文件,粘帖如下代码:
1 <fieldType name=“text_ik” class=“solr.TextField”> 2 <analyzer class=“org.wltea.analyzer.lucene.IKAnalyzer”/> 3 </fieldType> 4 5 <field name=“ik” type=“text_ik” indexed=“true” stored=“true” multiValued=“false” />
重启服务器,也就是启动.bat,然后我们前往http://localhost:8983/solr/#/collection1/analysis,随便打上一段话,比如“随便打些汉字测试分词效果”,记得Analyse Fieldname选择我们刚刚配置的ik,点击Analyse Values按钮
如图:

DIH增量从MYSQL数据库导入数据
已经学会了如何全量导入MySQL的数据,全量导入在数据量大的时候代价非常大,一般来说都会适用增量的方式来导入数据,下面介绍如何增量导入MYSQL数据库中的数据,以及如何设置定时来做。
1)数据库表的更改
前面已经创建好了一个User的表,这里为了能够进行增量导入,需要新增一个字段updateTime,类型为timestamp,默认值为CURRENT_TIMESTAMP。
有了这样一个字段,Solr才能判断增量导入的时候,哪些数据是新的。
因为Solr本身有一个默认值last_index_time,记录最后一次做full import或者是delta import(增量导入)的时间,这个值存储在文件conf目录的dataimport.properties文件中。
2)data-config.xml中必要属性的设置
transformer 格式转化:HTMLStripTransformer 索引中忽略HTML标签
query:查询数据库表符合记录数据
deltaQuery:增量索引查询主键ID 注意这个只能返回ID字段
deltaImportQuery:增量索引查询导入的数据
deletedPkQuery:增量索引删除主键ID查询 注意这个只能返回ID字段
有关“query”,“deltaImportQuery”, “deltaQuery”的解释,引用官网说明,如下所示:
The query gives the data needed to populate fields of the Solr document in full-import
The deltaImportQuery gives the data needed to populate fields when running a delta-import
The deltaQuery gives the primary keys of the current entity which have changes since the last index time
如果需要关联子表查询,可能需要用到parentDeltaQuery
The parentDeltaQuery uses the changed rows of the current table (fetched with deltaQuery) to give the changed rows in theparent table. This is necessary because whenever a row in the child table changes, we need to re-generate the document which has that field.
更多说明看DeltaImportHandler的说明文档。
针对User表,data-config.xml文件的配置内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/mybatis" user="root" password="luxx" batchSize="-1" />
<document name="testDoc">
<entity name="user" pk="id"
query="select * from user"
deltaImportQuery="select * from user where id='${dih.delta.id}'"
deltaQuery="select id from user where updateTime> '${dataimporter.last_index_time}'">
<field column="id" name="id"/>
<field column="userName" name="userName"/>
<field column="userAge" name="userAge"/>
<field column="userAddress" name="userAddress"/>
<field column="updateTime" name="updateTime"/>
</entity>
</document>
</dataConfig>
增量索引的原理是从数据库中根据deltaQuery指定的SQL语句查询出所有需要增量导入的数据的ID号。
然后根据deltaImportQuery指定的SQL语句返回所有这些ID的数据,即为这次增量导入所要处理的数据。
核心思想是:通过内置变量“${dih.delta.id}”和 “${dataimporter.last_index_time}”来记录本次要索引的id和最近一次索引的时间。
注意:刚新加上的updateTime字段也要在field属性中配置,同时也要在schema.xml文件中配置:
<field name="updateTime" type="date" indexed="true" stored="true" />
如果业务中还有删除操作,可以在数据库中加一个isDeleted字段来表明该条数据是否已经被删除,这时候Solr在更新index的时候,可以根据这个字段来更新哪些已经删除了的记录的索引。
这时候需要在dataConfig.xml中添加:
query="select * from user where isDeleted=0"
deltaImportQuery="select * from user where id='${dih.delta.id}'"
deltaQuery="select id from user where updateTime> '${dataimporter.last_index_time}' and isDeleted=0"
deletedPkQuery="select id from user where isDeleted=1"
这时候Solr进行增量索引的时候,就会删除数据库中isDeleted=1的数据的索引。
测试增量导入
如果User表里有数据,可以先清空以前的测试数据(因为加的updateTime没有值),用我的Mybatis测试程序添加一个User,数据库会以当前时间赋值给该字段。在Solr中使用Query查询所有没有查询到该值,使用dataimport?command=delta-import增量导入,再次查询所有就可以查询到刚刚插入到MySQL的值。
设置增量导入为定时执行的任务
可以用Windows计划任务,或者Linux的Cron来定期访问增量导入的连接来完成定时增量导入的功能,这其实也是可以的,而且应该没什么问题。
但是更方便,更加与Solr本身集成度高的是利用其自身的定时增量导入功能。
1、下载apache-solr-dataimportscheduler-1.0.jar放到\solr-webapp\webapp\WEB-INF\lib目录下:
百度云盘下载:链接: https://pan.baidu.com/s/1pLa8BbX 密码: xkfw (注:是经过修改的,没有修改的apache-solr-dataimportscheduler-1.0.jar有bug,会使定时增量任务失效,具体参考:http://www.denghuafeng.com/post-242.html)
2、修改solr的WEB-INF目录下面的web.xml文件:
为<web-app>元素添加一个子元素
<listener>
<listener-class>
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
</listener-class>
</listener>
3、新建配置文件dataimport.properties:
在SOLR_HOME\solr目录下面新建一个目录conf(注意不是SOLR_HOME\solr\collection1下面的conf),然后用解压文件打开apache-solr-dataimportscheduler-1.0.jar文件,将里面的dataimport.properties文件拷贝过来,进行修改,下面是最终我的自动定时更新配置文件内容:
################################################# # # # dataimport scheduler properties # # # ################################################# # to sync or not to sync # 1 - active; anything else - inactive syncEnabled=1 # which cores to schedule # in a multi-core environment you can decide which cores you want syncronized # leave empty or comment it out if using single-core deployment # syncCores=game,resource syncCores=collection1 # solr server name or IP address # [defaults to localhost if empty] server=localhost # solr server port # [defaults to 80 if empty] port=8983 # application name/context # [defaults to current ServletContextListener's context (app) name] webapp=solr # URLparams [mandatory] # remainder of URL #http://localhost:8983/solr/collection1/dataimport?command=delta-import&clean=false&commit=true params=/dataimport?command=delta-import&clean=false&commit=true # schedule interval # number of minutes between two runs # [defaults to 30 if empty] interval=1 # 重做索引的时间间隔,单位分钟,默认7200,即1天; # 为空,为0,或者注释掉:表示永不重做索引 # reBuildIndexInterval=2 # 重做索引的参数 reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true # 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000; # 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期 reBuildIndexBeginTime=03:10:00
这里为了做测试每1分钟就进行一次增量索引,同时disable了full-import全量索引。
4、测试
在数据库中插入一条数据,在Solr Query中查询,刚开始查不到,Solr进行一次增量索引后就可以查询到了。
一般来说要在你的项目中引入Solr需要考虑以下几点:
1、数据更新频率:每天数据增量有多大,及时更新还是定时更新
2、数据总量:数据要保存多长时间
3、一致性要求:期望多长时间内看到更新的数据,最长允许多长时间延迟
4、数据特点:数据源包括哪些,平均单条记录大小
5、业务特点:有哪些排序要求,检索条件
6、资源复用:已有的硬件配置是怎样的,是否有升级计划
命令窗口显示如下:

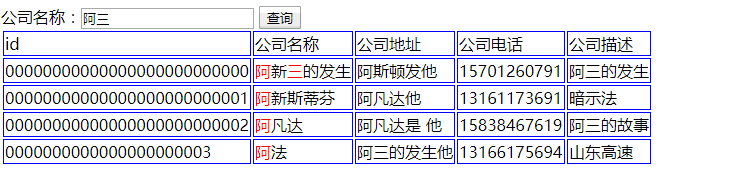
最终查询效果如下:
参考:
http://wiki.apache.org/solr/DataImportHandler
http://wiki.apache.org/solr/Solrj
http://www.denghuafeng.com/post-242.html
http://www.cnblogs.com/luxiaoxun/p/4442770.html
http://blog.csdn.net/menghuannvxia/article/details/41984445
http://www.cnblogs.com/edwinchen/p/3977366.html
http://blog.csdn.net/tianyijavaoracle/article/details/44137989
完整代码以及配置好的solr,百度网盘下载地址:链接: https://pan.baidu.com/s/1i568XZf 密码: gwwh

