
MapReduce高级编程
1. Chaining MapReduce Jobs任务链
2. Join data from different data source
<1>. Changing MapReduce jobs
1.1 Chaining MapReduce jobs in a sequence
MapReduce程序能够执行一些复杂数据处理的工作,通常的情况下,需要将这个任务task分割成多个较小的subtask,然后每个subtask通过hadoop中的job运行完成,然后教案subtask的结果收集起来,完成这个复杂的task。
最简单的就是“顺序”执行了。编程模型也比较简单。我们知道在MapReduce编程中启动一个任务JobClient.runJob(),这时仅仅到这个任务job完成了之后,该语句才能结束,所以如果想要顺序执行任务的话,只需要在每个任务完成之后重新开始一个新的任务。
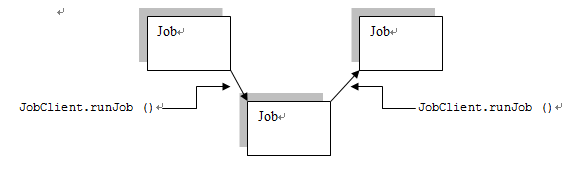
1.2 Chaining MapReduce jobs with complex dependency
但是在更多的情况下仅仅按照顺序执行是完全不够的,在hadoop中提供了JobContrl类来封装一系列的job和这些job之间的依赖关系。
JobControl中提供了addJob方法将一个job添加到这个job的集合中;
同时每个每个job类提供了addDependingJob方法。
例如,我们现在需要运行5个job:job1, job2, job3, job4, job5,如果job2需要在job1运行完成之后,运行;job4需要在job3运行完成之后运行,最终job5需要在job2和job4运行完成之后才能运行。那么这时可以这样建立模型:

1.3 Chaining preprocessing and postprocessing steps
hadoop中一个每个任务可以有多个Mapper和Reducer,这时程序的执行顺序如下:
The Mapper classes are invoked in a chained (or piped) fashion, the output of the first becomes the input of the second, and so on until the last Mapper, the output of the last Mapper will be written to the task's output.
也就是类似于linux下的管道命令mapper1 | mapper2 | reducer1 | mapper3 | mapper4。
<2>. Joining data from different sources
如果存在这样的两个数据源Customers和Orders,
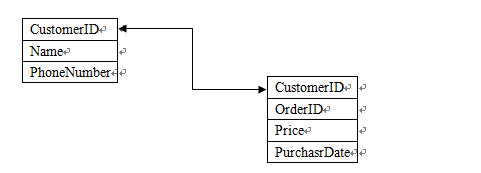
如果我们想要分析这个数据的话, 这时就需要使用hadoop的datajoin功能。首先我们来看看hadoop data join的流程。
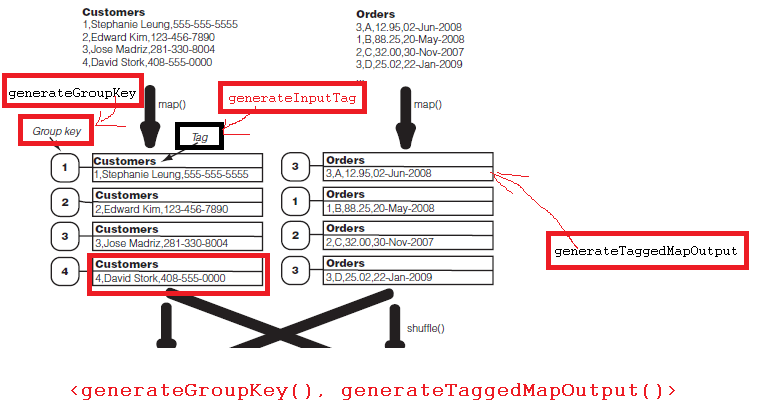
首先map函数从Customers和Orders中读取数据,输出<K1-2, V1-2>,<K2-1, V2-1>;
然后hadoop开始partition,shuffle,这时和原先处理不同的是这里将把group key相同的打包,发送到一个reduce函数中;
这时reduce函数得到的将是group key相同的一组数据。

然后在reduce函数中,将执行data join形成combination,然后将combination发送到combine()函数输出每个结果record。

在hadoop中存在DataJoinMapperBase基类和DataJoinReducerBase基类用来实现data join。对于data join的mapper需要继承自DataJoinMapperBase,并且该mapper需要实现三个方法:
对于需要实现data join的reducer而言,需要继承自DataJoinReducerBase,这时需要重写方法combine,首先需要明确的是combine作用的对象:
For each tuple in the cross product, it calls the following method, which is expected to be implemented in a subclass. protected abstract TaggedMapOutput combine(Object[] tags, Object[] values); The above method is expected to produce one output value from an array of records of different sources.
combine显然是针对的是an array of records of different sources,即:
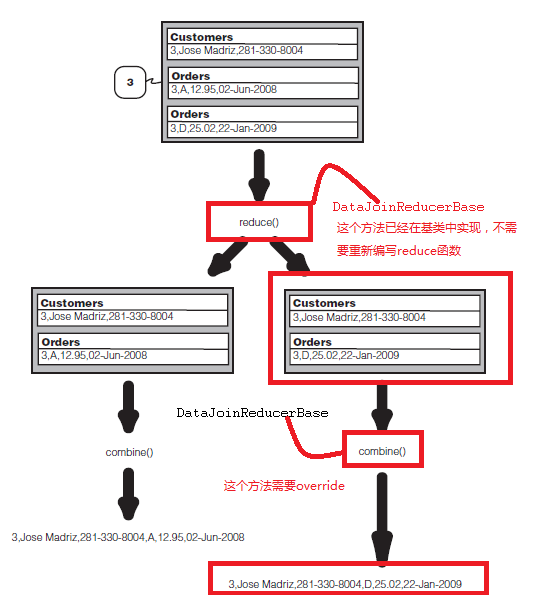
也就是说combine仅仅是负责得到最终的输出格式。


