
FCN网络的训练——以SIFT-Flow 数据集为例
参考文章: http://blog.csdn.net/u013059662/article/details/52770198
caffe的安装配置,以及fcn的使用在我前边的文章当中都已经提及到了,这边不会再细讲。在下边的内容当中,我们来看看如何使用别人提供的数据集来训练自己的模型!在这篇文章之后,我计划还要再写如何fine-tune和制作自己的数据集,以及用自己的数据集fine-tune。
(一)数据准备(以SIFT-Flow 数据集为例)
下载数据集: http://pan.baidu.com/s/1dFxaAtj ,并解压至/fcn.berkeleyvision.org/data/下,并将文件夹名重命名为sift-flow。这里一定要注意,/fcn.berkeleyvision.org/data/下本来就有一个文件夹叫sift-flow,千万不要覆盖。同时,这些原本就存在的文件夹里的东西还要全部复制到新解压的sift-flow文件夹下边。你可以先把原本的sift-slow重新命名为sitf-flow_1,然后再解压复制!
(二) 下载预训练模型
下载VGG-16的预训练模型放至/fcn.berkeleyvision.org/ilsvrc-nets/目录下,并重命名为vgg16-fcn.caffemodel。
下载地址: http://pan.baidu.com/s/1gfeF4wN
(三)源码修改
1. prototxt文件修改
进入siftflow-fcn32s文件夹下,将test.prototxt和trainval.prototxt中的fc6和fc7分别替换为其他名称,例如:fc6_new和fc7_new。
原因是我们下载的预训练模型VGG-16原模型中包含有fc6和fc7这两个全连接层,而在prototxt中,使我们新添加的卷积层,在模型加载时,如果名称一样,而结构数据不同,便会报错。如果改名之后,原来的fc6/7则会被忽略,而使用我们新的层。
2. caffe path的加入
由于FCN代码和caffe代码是独立的文件夹,因此,须将caffe的Python接口加入到path中去。这里有两种方案,一种是在所有代码中出现import caffe 之前,加入:
1 import sys 2 sys.path.append('caffe根目录/python')
另一种一劳永逸的方法是:在终端或者bashrc中将接口加入到PYTHONPATH中:
export PYTHONPATH=caffe根目录/python:$PYTHONPATH
(四)训练
1 $ cd cd siftflow-fcn32s/ 2 $ python solve.py
这里会遇见几个问题:
(1)No module named surgery,score

原因是下载的fcn源码解压根目录下有两个文件:surgery.py和score.py。这两个文件是下载下来就自带的,并不是caffe自带的,也不是前边我安装caffe时需要配置的。由于我是在/fcn根目录/siftflow-fcn32s/这个文件夹下执行的,会导致找不到这两个文件。所以,解决方案就是:
cp surgery.py score.py ./siftflow-fcn32s/
将surgery.py和score.py拷贝到siftflow-fcn32s下。
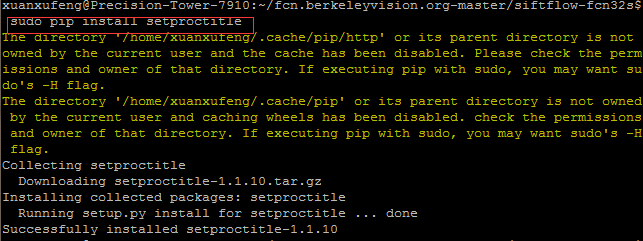
(2)ImportError: No module named setproctitle

解决方案是:安装setproctitle! sudo pip install setproctitle
(3)IndexError: list index out of range

解决方案:修改GPU编号为0号GPU

(4)No modulw named siftflow_layers

解决方案:疯了,干错把根目录下边的所有.py文件全拷贝到siftflow-fcn32s里边去吧。

好了,现在可以开始训练了!看看训练过程:
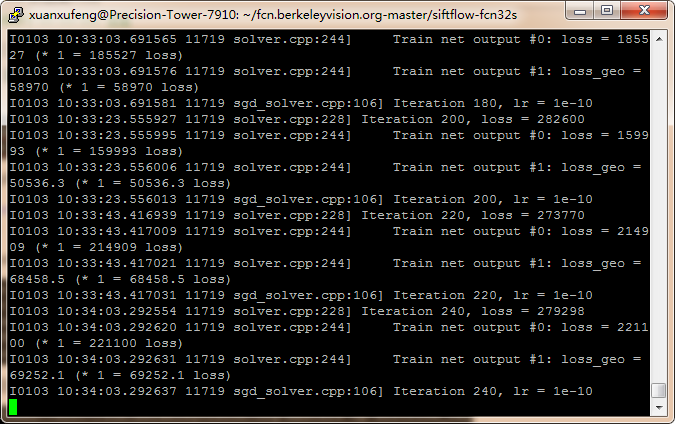
由于损失loss很大,我也不知道什么时候能收敛,所以先放一放,等跑出结果来我再过来更新!
-------------------------------------------------------------2017.1.12更新----------------------------------------------------------------------
经过半个月的折腾和讨论,现在可以确定原先的参考文章是有问题的,这个网络没有办法收敛。下面更正几条:
1. 一般情况下不要直接修改test.prototxt和trainval.prototxt,而是执行net.py这个脚本,执行完成后也不要将test.prototxt和trainval.prototxt中的fc6和fc7替换为其他名称.
2. 这是重点,没有收敛的根源在这里!修改solve.py:
1 import sys 2 import caffe 3 import surgery, score 4 5 import numpy as np 6 import os 7 8 import setproctitle 9 setproctitle.setproctitle(os.path.basename(os.getcwd())) 10 11 vgg_weights = '../ilsvrc-nets/vgg16-fcn.caffemodel' 12 vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt' 13 # init 14 #caffe.set_device(int(sys.argv[1])) 15 caffe.set_device(0) 16 caffe.set_mode_gpu() 17 18 #solver = caffe.SGDSolver('solver.prototxt') 19 #solver.net.copy_from(weights) 20 solver = caffe.SGDSolver('solver.prototxt') 21 vgg_net = caffe.Net(vgg_proto, vgg_weights, caffe.TRAIN) 22 surgery.transplant(solver.net, vgg_net) 23 del vgg_net 24 25 # surgeries 26 interp_layers = [k for k in solver.net.params.keys() if 'up' in k] 27 surgery.interp(solver.net, interp_layers) 28 29 # scoring 30 test = np.loadtxt('../data/sift-flow/test.txt', dtype=str) 31 32 for _ in range(50): 33 solver.step(2000) 34 # N.B. metrics on the semantic labels are off b.c. of missing classes; 35 # score manually from the histogram instead for proper evaluation 36 score.seg_tests(solver, False, test, layer='score_sem', gt='sem') 37 score.seg_tests(solver, False, test, layer='score_geo', gt='geo')
可以对比一下之前的solve.py,发现区别在这: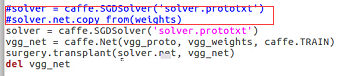
红色框出来的是原先的内容,被我注释掉了,换成了下面四行!为什么要这样做呢?我们来看看这个transplant函数的定义吧:
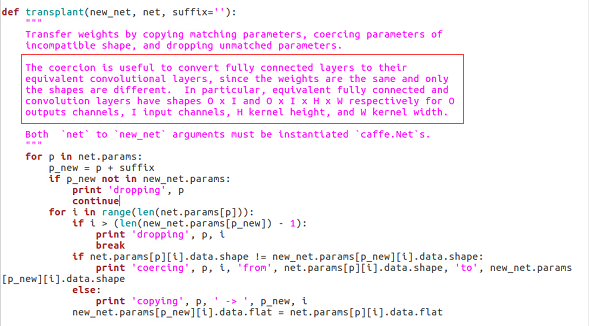
所以,原先的方法仅仅是从vgg-16模型中拷贝参数,但是并没有改造原先的网络,这才是不收敛的根源啊!
3.修改solver.prototxt:
1 train_net: "trainval.prototxt" 2 test_net: "test.prototxt" 3 test_iter: 200 4 # make test net, but don't invoke it from the solver itself 5 test_interval: 999999999 6 display: 20 7 average_loss: 20 8 lr_policy: "fixed" 9 # lr for unnormalized softmax 10 base_lr: 1e-10 11 # high momentum 12 momentum: 0.99 13 # no gradient accumulation 14 iter_size: 1 15 max_iter: 300000 16 weight_decay: 0.0005 17 snapshot:4000 18 snapshot_prefix:"snapshot/train" 19 test_initialization: false
这里我们增加了 snapshot:4000 snapshot_prefix:"snapshot/train" ,每4000次我们会在当前目录下的snapshot下保存一下模型(需要提前建立snapshot目录)。
4. 有的人可能会出现out of memory错误。这里有两种判断:(1)根本没法迭代,那么你就要把batchsize设置小一点了。默认是 iter_size: 1 (solver.prototxt),另外在siftflow_layers.py中 top[0].reshape(1, *self.data.shape) 这里默认也是1,batchsize = iter_size* 1。如果已经是最小了,即这两个地方都是1了,如果你还是out of memory,那么要么更换好的硬件(GPU),要么resize 数据集到更小的尺寸。(2)如果先提示“Begin seg tests”,然后out of memory,那么是在执行score.py时内存溢出了,这时还是上面的两种解决方案。
好了,上面是我这段时间研究后的补充,感谢小伙伴@踏雪霏鸿 ,最初是他发现了这里的错误,最终帮助大家解决了问题。下面我们就可以重新开始训练模型了!
1 python solve.py
这一次收敛速度会非常快,而且loss会降到很可观的数字。

这里我没有一直跑下去,因为我准备用voc数据集,所以跑了一会就去跑voc数据集了。但是,这次是有小伙伴做过测试的,效果可以,所以基本上siftflow32s的训练步骤就是这些了!需要训练siftflow-fcn32s的朋友可以按这个走,然后用训练得到的32s的模型去训练16s的模型,最后用16s的模型去训练8s的。
5. 最后,由于从32s->16s和16s->8s不需要重新构造卷积层,所以上面第二点提到的注释和替换的那部分就不需要了,直接用solver.net.copy_from(weights)就可以了!
其二,deploy.prototxt的第一层(input层),维度要和输入图片大小对应,如下图:
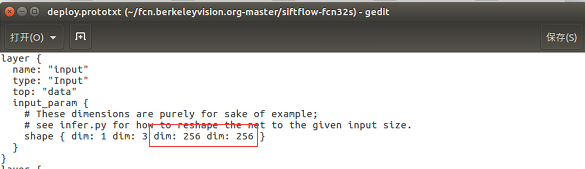
因为siftflow数据集是256*256的,要一一对应。如果发现要训练的模型下没有deploy.prototxt这个文件,可以从test.prototxt或者trainval.prototxt复制,然后删除最后一层loss层:
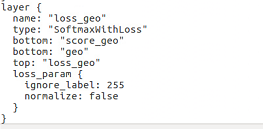
再添加一层输入层,这个输入层可以从voc-fcn8s这个文件夹里的deploy.protottx里边复制,内容如下(注意根据输入图片的尺寸修改):
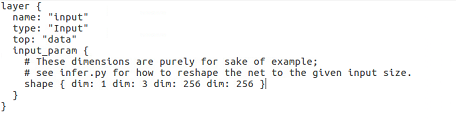
其三,很多人要用自己的数据集训练fcn,那怎么做呢?
是这样的,我们可以先用fcn32s的模型(已经训练好的)和自己的数据集再训练一遍得到新的fcn32s,这其实有专业术语——fine-tune.
然后用上面训练好的fcn32s和自己的数据集,训练出fcn16s。最后,再用上一步的fcn16s和自己的数据集训练出fcn8s。
-------------------------------------------------------结束语--------------------------------------------------------------------------
虽然这样一篇博客看上去好像也没有多少东西,但是却凝结了我和很多人长时间努力的汗水,昼夜奋战搞出来的。我相信,在看过我这篇文章之前,应该是没有多少中文资料的,要么只言片语,要么误导性的。后面也许会有一些博客陆续出来,那基本上也是的小伙伴们写的,但是基本上比较简单,言简意赅,不会像我这么细致写出来。
为什么要做这样一件工作呢?辛苦搞出来的东西,就这样送人了,而且还要再花时间写这么长的博文,打这么多的字。我希望后来人能少走一些弯路,不像我这么痛苦;同时,我希望看过我博客的人也能秉承奉献的精神,把自己的工作公开出来,避免别人少走弯路,这既是对自己工作的总结和梳理,也是对后来人的极大帮助!搞学术不能闭门造车,希望我等共勉!


