Java 实现《编译原理》简单-语法分析功能-LL(1)文法 - 程序解析
Java 实现《编译原理》简单-语法分析功能-LL(1)文法 - 程序解析
编译原理学习,语法分析程序设计
(一)要求及功能
已知 LL(1) 文法为:
G'[E]: E→TE'
E'→+TE'|ε
T→FT'
T'→*FT'|ε
F→(E)|i
为了方便处理,用:M 代替 E',N 代表 T';并展开相同同一非终结符的产生式;不影响含义,可自行再优化
即有:
G[E]: E→TM
M→+TM
M→ε
T→FN
N→*FN
N→ε
F→(E)
F→i
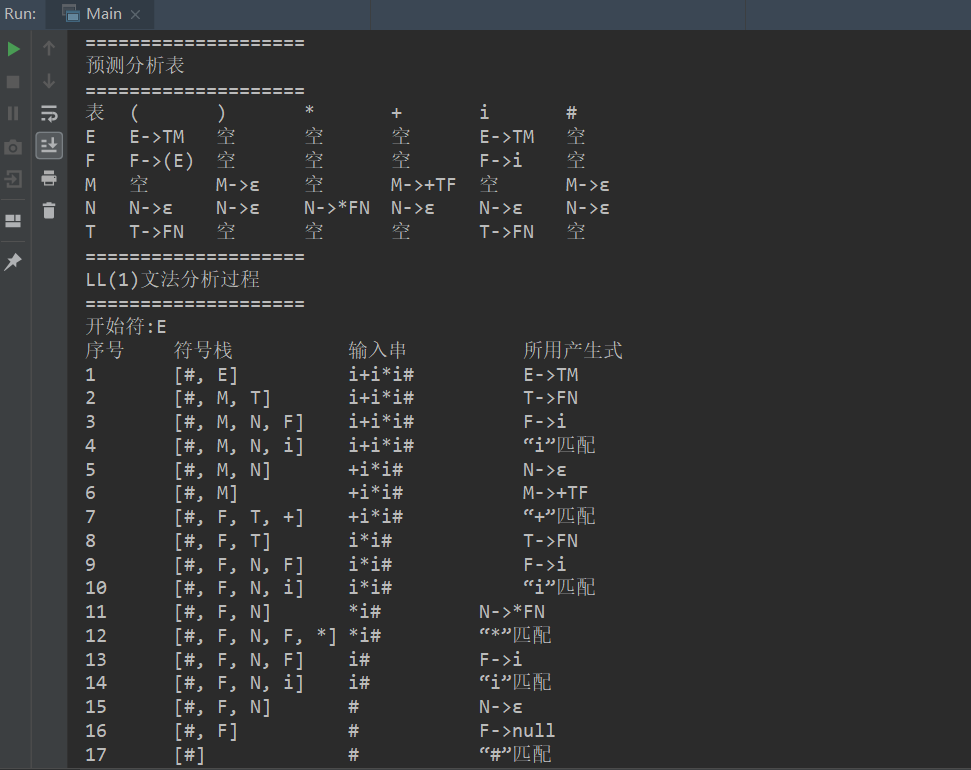
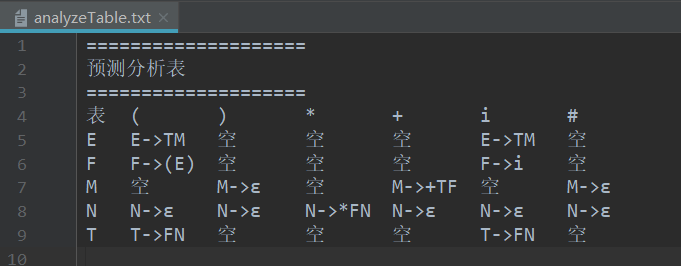
根据文法建立 LL(1) 分析表,并对输入串 i+i*i 进行语法分析,判断其是否是合法的句子
(二)整体与执行结果
所需类:
执行结果:
(三)程序源代码
(1)Grammar.java 文件:
package com.java997.analyzer.grammar;
import java.io.File;
import java.io.FileWriter;
import java.io.Serializable;
import java.io.Writer;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap;
import java.util.TreeSet;
/**
* <p>
* LL(1)文法
* 1.获取 First 集
* 2.获取 Follow 集
* 3.获取 SELECT 集
*
* @author XiaoPengwei
* @since 2019-06-18
*/
public class Grammar implements Serializable {
private static final long serialVersionUID = 1L;
public Grammar() {
super();
gsArray = new ArrayList<String>();
nvSet = new TreeSet<Character>();
ntSet = new TreeSet<Character>();
firstMap = new HashMap<Character, TreeSet<Character>>();
followMap = new HashMap<Character, TreeSet<Character>>();
selectMap = new TreeMap<Character, HashMap<String, TreeSet<Character>>>();
}
private String[][] analyzeTable;
/**
* Select集合
*/
private TreeMap<Character, HashMap<String, TreeSet<Character>>> selectMap;
/**
* LL(1)文法产生集合
*/
private ArrayList<String> gsArray;
/**
* 表达式集合
*/
private HashMap<Character, ArrayList<String>> expressionMap;
/**
* 开始符
*/
private Character s;
/**
* Vn非终结符集合
*/
private TreeSet<Character> nvSet;
/**
* Vt终结符集合
*/
private TreeSet<Character> ntSet;
/**
* First集合
*/
private HashMap<Character, TreeSet<Character>> firstMap;
/**
* Follow集合
*/
private HashMap<Character, TreeSet<Character>> followMap;
public String[][] getAnalyzeTable() {
return analyzeTable;
}
public void setAnalyzeTable(String[][] analyzeTable) {
this.analyzeTable = analyzeTable;
}
public TreeMap<Character, HashMap<String, TreeSet<Character>>> getSelectMap() {
return selectMap;
}
public void setSelectMap(TreeMap<Character, HashMap<String, TreeSet<Character>>> selectMap) {
this.selectMap = selectMap;
}
public HashMap<Character, TreeSet<Character>> getFirstMap() {
return firstMap;
}
public void setFirstMap(HashMap<Character, TreeSet<Character>> firstMap) {
this.firstMap = firstMap;
}
public HashMap<Character, TreeSet<Character>> getFollowMap() {
return followMap;
}
public void setFollowMap(HashMap<Character, TreeSet<Character>> followMap) {
this.followMap = followMap;
}
public HashMap<Character, ArrayList<String>> getExpressionMap() {
return expressionMap;
}
public void setExpressionMap(HashMap<Character, ArrayList<String>> expressionMap) {
this.expressionMap = expressionMap;
}
public ArrayList<String> getGsArray() {
return gsArray;
}
public void setGsArray(ArrayList<String> gsArray) {
this.gsArray = gsArray;
}
public Character getS() {
return s;
}
public void setS(Character s) {
this.s = s;
}
public TreeSet<Character> getNvSet() {
return nvSet;
}
public void setNvSet(TreeSet<Character> nvSet) {
this.nvSet = nvSet;
}
public TreeSet<Character> getNtSet() {
return ntSet;
}
public void setNtSet(TreeSet<Character> ntSet) {
this.ntSet = ntSet;
}
/**
* 获取非终结符集与终结符集
*/
public void getNvNt() {
for (String gsItem : gsArray) {
String[] nvNtItem = gsItem.split("->");
String charItemStr = nvNtItem[0];
char charItem = charItemStr.charAt(0);
// nv在左边
nvSet.add(charItem);
}
for (String gsItem : gsArray) {
String[] nvNtItem = gsItem.split("->");
// nt在右边
String nvItemStr = nvNtItem[1];
// 遍历每一个字
for (int i = 0; i < nvItemStr.length(); i++) {
char charItem = nvItemStr.charAt(i);
if (!nvSet.contains(charItem)) {
ntSet.add(charItem);
}
}
}
}
/**
* 初始化表达式集合
*/
public void initExpressionMaps() {
expressionMap = new HashMap<Character, ArrayList<String>>();
for (String gsItem : gsArray) {
String[] nvNtItem = gsItem.split("->");
String charItemStr = nvNtItem[0];
String charItemRightStr = nvNtItem[1];
char charItem = charItemStr.charAt(0);
if (!expressionMap.containsKey(charItem)) {
ArrayList<String> expArr = new ArrayList<String>();
expArr.add(charItemRightStr);
expressionMap.put(charItem, expArr);
} else {
ArrayList<String> expArr = expressionMap.get(charItem);
expArr.add(charItemRightStr);
expressionMap.put(charItem, expArr);
}
}
}
/**
* 获取 First 集
*/
public void getFirst() {
// 遍历所有Nv,求出它们的First集合
Iterator<Character> iterator = nvSet.iterator();
while (iterator.hasNext()) {
Character charItem = iterator.next();
ArrayList<String> arrayList = expressionMap.get(charItem);
for (String itemStr : arrayList) {
boolean shouldBreak = false;
// Y1Y2Y3...Yk
for (int i = 0; i < itemStr.length(); i++) {
char itemitemChar = itemStr.charAt(i);
TreeSet<Character> itemSet = firstMap.get(charItem);
if (null == itemSet) {
itemSet = new TreeSet<Character>();
}
shouldBreak = calcFirst(itemSet, charItem, itemitemChar);
if (shouldBreak) {
break;
}
}
}
}
}
/**
* 计算 First 函数
*
* @param itemSet
* @param charItem
* @param itemitemChar
* @return boolean
*/
private boolean calcFirst(TreeSet<Character> itemSet, Character charItem, char itemitemChar) {
// 将它的每一位和Nt判断下
// 是终结符或空串,就停止,并将它加到FirstMap中
if (itemitemChar == 'ε' || ntSet.contains(itemitemChar)) {
itemSet.add(itemitemChar);
firstMap.put(charItem, itemSet);
// break;
return true;
} else if (nvSet.contains(itemitemChar)) {// 这一位是一个非终结符
ArrayList<String> arrayList = expressionMap.get(itemitemChar);
for (int i = 0; i < arrayList.size(); i++) {
String string = arrayList.get(i);
char tempChar = string.charAt(0);
calcFirst(itemSet, charItem, tempChar);
}
}
return true;
}
/**
* 获取 Follow 集合
*/
public void getFollow() {
for (Character tempKey : nvSet) {
TreeSet<Character> tempSet = new TreeSet<Character>();
followMap.put(tempKey, tempSet);
}
// 遍历所有Nv,求出它们的First集合
Iterator<Character> iterator = nvSet.descendingIterator();
while (iterator.hasNext()) {
Character charItem = iterator.next();
System.out.println("charItem:" + charItem);
Set<Character> keySet = expressionMap.keySet();
for (Character keyCharItem : keySet) {
ArrayList<String> charItemArray = expressionMap.get(keyCharItem);
for (String itemCharStr : charItemArray) {
System.out.println(keyCharItem + "->" + itemCharStr);
TreeSet<Character> itemSet = followMap.get(charItem);
calcFollow(charItem, charItem, keyCharItem, itemCharStr, itemSet);
}
}
}
}
/**
* 计算 Follow 集
*
* @param putCharItem 正在查询item
* @param charItem 待找item
* @param keyCharItem 节点名
* @param itemCharStr 符号集
* @param itemSet 结果集合
*/
private void calcFollow(Character putCharItem, Character charItem, Character keyCharItem, String itemCharStr,
TreeSet<Character> itemSet) {
// (1)A是S(开始符),加入#
if (charItem.equals(s)) {
itemSet.add('#');
System.out.println("---------------find S:" + charItem + " ={#}+Follow(E)");
followMap.put(putCharItem, itemSet);
}
// (2)Ab,=First(b)-ε,直接添加终结符
if (TextUtil.containsAb(ntSet, itemCharStr, charItem)) {
Character alastChar = TextUtil.getAlastChar(itemCharStr, charItem);
System.out.println("---------------find Ab:" + itemCharStr + " " + charItem + " =" + alastChar);
itemSet.add(alastChar);
followMap.put(putCharItem, itemSet);
// return;
}
// (2).2AB,=First(B)-ε,=First(B)-ε,添加first集合
if (TextUtil.containsAB(nvSet, itemCharStr, charItem)) {
Character alastChar = TextUtil.getAlastChar(itemCharStr, charItem);
System.out.println(
"---------------find AB:" + itemCharStr + " " + charItem + " =First(" + alastChar + ")");
TreeSet<Character> treeSet = firstMap.get(alastChar);
itemSet.addAll(treeSet);
if (treeSet.contains('ε')) {
itemSet.add('#');
}
itemSet.remove('ε');
followMap.put(putCharItem, itemSet);
if (TextUtil.containsbAbIsNull(nvSet, itemCharStr, charItem, expressionMap)) {
char tempChar = TextUtil.getAlastChar(itemCharStr, charItem);
System.out.println("tempChar:" + tempChar + " key" + keyCharItem);
if (!keyCharItem.equals(charItem)) {
System.out.println("---------------find tempChar bA: " + "tempChar:" + tempChar + keyCharItem
+ " " + itemCharStr + " " + charItem + " =Follow(" + keyCharItem + ")");
Set<Character> keySet = expressionMap.keySet();
for (Character keyCharItems : keySet) {
ArrayList<String> charItemArray = expressionMap.get(keyCharItems);
for (String itemCharStrs : charItemArray) {
calcFollow(putCharItem, keyCharItem, keyCharItems, itemCharStrs, itemSet);
}
}
}
}
}
// (3)B->aA,=Follow(B),添加followB
if (TextUtil.containsbA(nvSet, itemCharStr, charItem, expressionMap)) {
if (!keyCharItem.equals(charItem)) {
System.out.println("---------------find bA: " + keyCharItem + " " + itemCharStr + " " + charItem
+ " =Follow(" + keyCharItem + ")");
Set<Character> keySet = expressionMap.keySet();
for (Character keyCharItems : keySet) {
ArrayList<String> charItemArray = expressionMap.get(keyCharItems);
for (String itemCharStrs : charItemArray) {
calcFollow(putCharItem, keyCharItem, keyCharItems, itemCharStrs, itemSet);
}
}
}
}
}
/**
* 获取 Select 集合
*/
public void getSelect() {
// 遍历每一个表达式
// HashMap<Character, HashMap<String, TreeSet<Character>>>
Set<Character> keySet = expressionMap.keySet();
for (Character selectKey : keySet) {
ArrayList<String> arrayList = expressionMap.get(selectKey);
// 每一个表达式
HashMap<String, TreeSet<Character>> selectItemMap = new HashMap<String, TreeSet<Character>>();
for (String selectExp : arrayList) {
/**
* 存放select结果的集合
*/
TreeSet<Character> selectSet = new TreeSet<Character>();
// set里存放的数据分3种情况,由selectExp决定
// 1.A->ε,=follow(A)
if (TextUtil.isEmptyStart(selectExp)) {
selectSet = followMap.get(selectKey);
selectSet.remove('ε');
selectItemMap.put(selectExp, selectSet);
}
// 2.Nt开始,=Nt
// <br>终结符开始
if (TextUtil.isNtStart(ntSet, selectExp)) {
selectSet.add(selectExp.charAt(0));
selectSet.remove('ε');
selectItemMap.put(selectExp, selectSet);
}
// 3.Nv开始,=first(Nv)
if (TextUtil.isNvStart(nvSet, selectExp)) {
selectSet = firstMap.get(selectKey);
selectSet.remove('ε');
selectItemMap.put(selectExp, selectSet);
}
selectMap.put(selectKey, selectItemMap);
}
}
}
/**
* 生成预测分析表
*/
public void genAnalyzeTable() throws Exception {
Object[] ntArray = ntSet.toArray();
Object[] nvArray = nvSet.toArray();
// 预测分析表初始化
analyzeTable = new String[nvArray.length + 1][ntArray.length + 1];
System.out.println("====================\n预测分析表\n====================");
File outputFile = new File("D:\\template\\analyzer\\src\\main\\java\\com\\java997\\analyzer\\grammar\\analyzeTable.txt");
try (Writer writer = new FileWriter(outputFile)) {
writer.write("====================\n预测分析表\n====================\n");
// 输出一个占位符
System.out.print("表" + "\t");
writer.write("表" + "\t");
analyzeTable[0][0] = "Nv/Nt";
// 初始化首行
for (int i = 0; i < ntArray.length; i++) {
if (ntArray[i].equals('ε')) {
ntArray[i] = '#';
}
writer.write(ntArray[i] + "\t\t");
System.out.print(ntArray[i] + "\t\t");
analyzeTable[0][i + 1] = ntArray[i] + "";
}
System.out.println("");
writer.write("\n");
for (int i = 0; i < nvArray.length; i++) {
// 首列初始化
writer.write(nvArray[i] + "\t");
System.out.print(nvArray[i] + "\t");
analyzeTable[i + 1][0] = nvArray[i] + "";
for (int j = 0; j < ntArray.length; j++) {
String findUseExp = TextUtil.findUseExp(selectMap, Character.valueOf((Character) nvArray[i]),
Character.valueOf((Character) ntArray[j]));
if (null == findUseExp) {
writer.write("空\t\t");
System.out.print("空\t\t");
analyzeTable[i + 1][j + 1] = "";
} else {
writer.write(nvArray[i] + "->" + findUseExp + "\t");
System.out.print(nvArray[i] + "->" + findUseExp + "\t");
analyzeTable[i + 1][j + 1] = nvArray[i] + "->" + findUseExp;
}
}
writer.write("\n");
System.out.println();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
(2)Analyzer.java
package com.java997.analyzer.grammar;
import java.util.ArrayList;
import java.util.Stack;
/**
* <p>
* 主程序 句子分析器
*
* @author XiaoPengwei
* @since 2019-06-18
*/
public class Analyzer {
public Analyzer() {
super();
analyzeStatck = new Stack<Character>();
// 结束符进栈
analyzeStatck.push('#');
}
private ArrayList<AnalyzeProduce> analyzeProduces;
/**
* LL(1)文法
*/
private Grammar ll1Grammar;
public Grammar getLl1Grammar() {
return ll1Grammar;
}
public void setLl1Grammar(Grammar ll1Grammar) {
this.ll1Grammar = ll1Grammar;
}
/**
* 开始符
*/
private Character startChar;
/**
* 分析栈
*/
private Stack<Character> analyzeStatck;
/**
* 剩余输入串
*/
private String str;
/**
* 推导所用产生或匹配
*/
private String useExp;
public ArrayList<AnalyzeProduce> getAnalyzeProduces() {
return analyzeProduces;
}
public void setAnalyzeProduces(ArrayList<AnalyzeProduce> analyzeProduces) {
this.analyzeProduces = analyzeProduces;
}
public Character getStartChar() {
return startChar;
}
public void setStartChar(Character startChar) {
this.startChar = startChar;
}
public Stack<Character> getAnalyzeStatck() {
return analyzeStatck;
}
public void setAnalyzeStatck(Stack<Character> analyzeStatck) {
this.analyzeStatck = analyzeStatck;
}
public String getStr() {
return str;
}
public void setStr(String str) {
this.str = str;
}
public String getUseExp() {
return useExp;
}
public void setUseExp(String useExp) {
this.useExp = useExp;
}
/**
* 分析
*/
public void analyze() {
analyzeProduces = new ArrayList<AnalyzeProduce>();
// 开始符进栈
analyzeStatck.push(startChar);
System.out.println("====================\nLL(1)文法分析过程\n====================");
System.out.println("开始符:" + startChar);
System.out.println("序号\t\t符号栈\t\t\t输入串\t\t\t所用产生式");
int index = 0;
// 开始分析
// while (analyzeStatck.peek() != '#' && str.charAt(0) != '#') {
while (!analyzeStatck.empty()) {
index++;
if (analyzeStatck.peek() != str.charAt(0)) {
// 到分析表中找到这个产生式
String nowUseExpStr = TextUtil.findUseExp(ll1Grammar.getSelectMap(), analyzeStatck.peek(), str.charAt(0));
//打印表格注意, 制表符的个数
if (analyzeStatck.size()==1){
System.out.println(index + "\t\t" + analyzeStatck.toString() + "\t\t\t\t" + str + "\t\t\t"
+ analyzeStatck.peek() + "->" + nowUseExpStr);
}else if (analyzeStatck.size()==2){
System.out.println(index + "\t\t" + analyzeStatck.toString() + "\t\t\t" + str + "\t\t\t"
+ analyzeStatck.peek() + "->" + nowUseExpStr);
}else if (analyzeStatck.size()==3){
System.out.println(index + "\t\t" + analyzeStatck.toString() + "\t\t" + str + "\t\t\t"
+ analyzeStatck.peek() + "->" + nowUseExpStr);
}else {
System.out.println(index + "\t\t" + analyzeStatck.toString() + "\t" + str + "\t\t\t"
+ analyzeStatck.peek() + "->" + nowUseExpStr);
}
AnalyzeProduce produce = new AnalyzeProduce();
produce.setIndex(index);
produce.setAnalyzeStackStr(analyzeStatck.toString());
produce.setStr(str);
if (null == nowUseExpStr) {
produce.setUseExpStr("无法匹配!");
} else {
produce.setUseExpStr(analyzeStatck.peek() + "->" + nowUseExpStr);
}
analyzeProduces.add(produce);
// 将之前的分析栈中的栈顶出栈
analyzeStatck.pop();
// 将要用到的表达式入栈,反序入栈
if (null != nowUseExpStr && nowUseExpStr.charAt(0) != 'ε') {
for (int j = nowUseExpStr.length() - 1; j >= 0; j--) {
char currentChar = nowUseExpStr.charAt(j);
analyzeStatck.push(currentChar);
}
}
continue;
}
// 如果可以匹配,分析栈出栈,串去掉一位
if (analyzeStatck.peek() == str.charAt(0)) {
if (analyzeStatck.size()==1){
System.out.println(index + "\t\t" + analyzeStatck.toString() + "\t\t\t\t" + str + "\t\t\t" + "“"
+ str.charAt(0) + "”匹配");
}else if (analyzeStatck.size()==2){
System.out.println(index + "\t\t" + analyzeStatck.toString() + "\t\t\t" + str + "\t\t\t" + "“"
+ str.charAt(0) + "”匹配");
}else if (analyzeStatck.size()==3){
System.out.println(index + "\t\t" + analyzeStatck.toString() + "\t\t" + str + "\t\t\t" + "“"
+ str.charAt(0) + "”匹配");
}else {
System.out.println(index + "\t\t" + analyzeStatck.toString() + "\t" + str + "\t\t\t" + "“"
+ str.charAt(0) + "”匹配");
}
AnalyzeProduce produce = new AnalyzeProduce();
produce.setIndex(index);
produce.setAnalyzeStackStr(analyzeStatck.toString());
produce.setStr(str);
produce.setUseExpStr("“" + str.charAt(0) + "”匹配");
analyzeProduces.add(produce);
analyzeStatck.pop();
str = str.substring(1);
continue;
}
}
}
}
(3)AnalyzeProduce.java
package com.java997.analyzer.grammar;
import java.io.Serializable;
/**
* <p>
* 分析过程 Bean
*
* @author XiaoPengwei
* @since 2019-06-18
*/
public class AnalyzeProduce implements Serializable {
private static final long serialVersionUID = 10L;
private Integer index;
private String analyzeStackStr;
private String str;
private String useExpStr;
public Integer getIndex() {
return index;
}
public void setIndex(Integer index) {
this.index = index;
}
public String getAnalyzeStackStr() {
return analyzeStackStr;
}
public void setAnalyzeStackStr(String analyzeStackStr) {
this.analyzeStackStr = analyzeStackStr;
}
public String getStr() {
return str;
}
public void setStr(String str) {
this.str = str;
}
public String getUseExpStr() {
return useExpStr;
}
public void setUseExpStr(String useExpStr) {
this.useExpStr = useExpStr;
}
}
(4)Main.java
package com.java997.analyzer.grammar;
import java.util.ArrayList;
import java.util.TreeSet;
/**
* <p>
* 主程序
*
* @author XiaoPengwei
* @since 2019-06-18
*/
public class Main {
public static void main(String[] args) throws Exception {
// 第一步:获取 LL(1)文法
ArrayList<String> gsArray = new ArrayList<String>();
Grammar grammar = new Grammar();
//初始化 LL(1), 设定该文法的产生式
initGs(gsArray);
grammar.setGsArray(gsArray);
grammar.getNvNt();
grammar.initExpressionMaps();
grammar.getFirst();
// 设置开始符
grammar.setS('E');
grammar.getFollow();
grammar.getSelect();
//打印预测分析表, 并保存文件
grammar.genAnalyzeTable();
// 创建一个分析器
Analyzer analyzer = new Analyzer();
// 设定开始符号
analyzer.setStartChar('E');
analyzer.setLl1Grammar(grammar);
// 待分析的字符串
analyzer.setStr("i+i*i#");
// 执行分析, 打印分析步骤, 保存文件
analyzer.analyze();
}
/**
* 获取非终结符集与终结符集
*
* @param gsArray
* @param nvSet
* @param ntSet
*/
private static void getNvNt(ArrayList<String> gsArray, TreeSet<Character> nvSet, TreeSet<Character> ntSet) {
for (String gsItem : gsArray) {
String[] nvNtItem = gsItem.split("->");
String charItemStr = nvNtItem[0];
char charItem = charItemStr.charAt(0);
// nv在左边
nvSet.add(charItem);
}
for (String gsItem : gsArray) {
String[] nvNtItem = gsItem.split("->");
// nt在右边
String nvItemStr = nvNtItem[1];
// 遍历每一个字
for (int i = 0; i < nvItemStr.length(); i++) {
char charItem = nvItemStr.charAt(i);
if (!nvSet.contains(charItem)) {
ntSet.add(charItem);
}
}
}
}
/**
* 初始化 LL(1)文法, 设定产生式
*
* @param gsArray
*/
private static void initGs(ArrayList<String> gsArray) {
//E' = M
//T' = N
gsArray.add("E->TM");
gsArray.add("M->+TF");
gsArray.add("M->ε");
gsArray.add("T->FN");
gsArray.add("N->*FN");
gsArray.add("N->ε");
gsArray.add("F->(E)");
gsArray.add("F->i");
}
}
(5)TextUtil.java
package com.java997.analyzer.grammar;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Set;
import java.util.TreeMap;
import java.util.TreeSet;
/**
* <p>
* 字符工具类
*
* @author XiaoPengwei
* @since 2019-06-18
*/
public class TextUtil {
/**
* (3)B->aA,=Follow(B)
*
* @param nvSet
* @param itemCharStr
* @param a
* @param expressionMap
*/
public static boolean containsbA(TreeSet<Character> nvSet, String itemCharStr, Character a,
HashMap<Character, ArrayList<String>> expressionMap) {
String aStr = a.toString();
String lastStr = itemCharStr.substring(itemCharStr.length() - 1);
return lastStr.equals(aStr);
}
/**
* 形如 aBb,b=空
*
* @param nvSet
* @param itemCharStr
* @param a
* @param expressionMap
*/
public static boolean containsbAbIsNull(TreeSet<Character> nvSet, String itemCharStr, Character a,
HashMap<Character, ArrayList<String>> expressionMap) {
String aStr = a.toString();
if (containsAB(nvSet, itemCharStr, a)) {
Character alastChar = getAlastChar(itemCharStr, a);
System.out.println("----------------+++++++++++++++++++--" + expressionMap.toString());
ArrayList<String> arrayList = expressionMap.get(alastChar);
if (arrayList.contains("ε")) {
System.out.println(alastChar + " contains('ε')" + aStr);
return true;
}
}
return false;
}
/**
*是否包含这种的字符串<Br>
* (2)Ab,=First(b)-ε,直接添加终结符
*
* @param ntSet
* @param itemCharStr
* @param a
* @return boolean
*/
public static boolean containsAb(TreeSet<Character> ntSet, String itemCharStr, Character a) {
String aStr = a.toString();
if (itemCharStr.contains(aStr)){
int aIndex = itemCharStr.indexOf(aStr);
String findStr;
try {
findStr = itemCharStr.substring(aIndex + 1, aIndex + 2);
} catch (Exception e) {
return false;
}
return ntSet.contains(findStr.charAt(0));
} else {
return false;
}
}
/**
* 是否包含这种的字符串<Br>
* (2).2Ab,=First(b)-ε
* @param nvSet
* @param itemCharStr
* @param a
* @return boolean
*/
public static boolean containsAB(TreeSet<Character> nvSet, String itemCharStr, Character a) {
String aStr = a.toString();
if (itemCharStr.contains(aStr)) {
int aIndex = itemCharStr.indexOf(aStr);
String findStr;
try {
findStr = itemCharStr.substring(aIndex + 1, aIndex + 2);
} catch (Exception e) {
return false;
}
return nvSet.contains(findStr.charAt(0));
} else {
return false;
}
}
/**
* 获取 A 后的字符
*
* @param itemCharStr
* @param a
*/
public static Character getAlastChar(String itemCharStr, Character a) {
String aStr = a.toString();
if (itemCharStr.contains(aStr)) {
int aIndex = itemCharStr.indexOf(aStr);
String findStr = "";
try {
findStr = itemCharStr.substring(aIndex + 1, aIndex + 2);
} catch (Exception e) {
return null;
}
return findStr.charAt(0);
}
return null;
}
/**
* 是否为 ε 开始的
*
* @param selectExp
*/
public static boolean isEmptyStart(String selectExp) {
char charAt = selectExp.charAt(0);
return charAt == 'ε';
}
/**
* 是否是终结符开始的
*
* @param ntSet
* @param selectExp
*/
public static boolean isNtStart(TreeSet<Character> ntSet, String selectExp) {
char charAt = selectExp.charAt(0);
return ntSet.contains(charAt);
}
/**
* 是否是非终结符开始的
*
* @param nvSet
* @param selectExp
* @return
*/
public static boolean isNvStart(TreeSet<Character> nvSet, String selectExp) {
char charAt = selectExp.charAt(0);
return nvSet.contains(charAt);
}
/**
* 查找产生式
*
* @param selectMap
* @param peek 当前 Nv
* @param charAt 当前字符
* @return
*/
public static String findUseExp(TreeMap<Character, HashMap<String, TreeSet<Character>>> selectMap, Character peek,
char charAt) {
try {
HashMap<String, TreeSet<Character>> hashMap = selectMap.get(peek);
Set<String> keySet = hashMap.keySet();
for (String useExp : keySet) {
TreeSet<Character> treeSet = hashMap.get(useExp);
if (treeSet.contains(charAt)) {
return useExp;
}
}
} catch (Exception e) {
return null;
}
return null;
}
}
执行 Main.java

