

Js杂谈-正则的测试与回溯次数
例子来源于<精通正则表达式(第三版)>这本书,我贴出来:

这里的NFA是正则的一种引擎,书中介绍了一共三种引擎:NFA,DFA和POSIX NFA。像一般我们常用的.NET,java.util.regex中都使用传统型的NFA。
这里纠正下书中的印刷错误,第二条正则是/"([^\\*]|\\.)*"/,类似将选择分支颠倒。
先从第一条正则开始:/"(\\.|[^\\"])*"/
根据匹配优先,尽可能多的去匹配文本,筛选条件根据NFA引擎的原理,从左开始依次筛选。
至于最后的"号为什么测试3次,首先先尝试与两种分支情况匹配,都失败,最后用正则的最后一个"与之匹配。一共是3次测试。这里的回溯指如果根据顺序分支没有匹配成功,要跳回来重头选择另一种分支,这个过程类似面包屑的回溯。

箭头表示这个字符串测试的次数,加在一起则标识这个文本测试的次数32次,如果是算回溯的话,很简单,测试2次的地方回溯了1次,测试3次的地方回溯了2次。所以这条文本的回溯次数为1+1*2+1*9+2=14
这让我们看清一个问题:
类似/"(\\.|[^"\\])*"/的分支选择,如果选择第一种情况,这个正则并不是意味变成了/"(\\.)*"/,而是根据文本上的字符串一个个进行分支选择。
看一下第二条正则:/"([^\\"]|\\.)*"/
这种修改,效率会提升很多,我们来看一下。
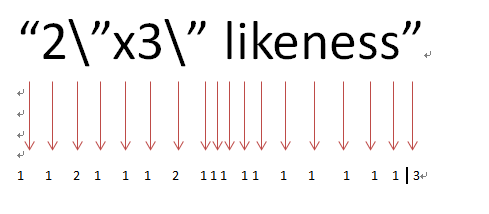
因为这个文本类似\"的字符串比较少,所以我们将[^\\"]放在分支的第一个,目的就是为了减少回溯和测试次数,这次我们看算下,测试次数为22,那回溯次数了1+1+2 =4次。回溯次数缩小了近3倍。
那对于第二个文本的话,道理是一样的。
这个文本除了"号,有12个字母,那测试次数就为1+12*2+3 = 28,回溯次数为1*12+2 =14次
换另一种正则测试时,测试次数为1+12*1+3 = 16,回溯次数为2次
NFA引擎给了程序员很大的自我空间,去完善正则的效率。
内容不多,时间刚好,以上是我的一点读书体会,如有错误,请指出,大家共通学习。

