

Hadoop_FileInputFormat分片
Hadoop学习笔记总结
01. InputFormat和OutFormat
1. 整个MapReduce组件

InputFormat类和OutFormat类都是抽象类。
可以实现文件系统的读写,数据库的读写,服务器端的读写。
这样的设计,具有高内聚、低耦合的特点。
2. 提交任务时,获取split切片信息的流程
-
JobSubmitter初始化submitterJobDir资源提交路径,是提交到HDFS保存文件路径,一些Jar包和配置文件:

-
接下来,是JobSubmitter中将切片信息写入submitJobDir目录。
int maps = writeSplits(job, submitJobDir); -
writeSplits方法中,首先会通过反射拿到用户设置的InputFormat子类的实例(默认为TextInputFormat类),然后调用FileInputFormat的getSplit方法(父类公共方法)再获得切片的信息,封装到InputSplit中,返回List
。 InputFormat<?, ?> input = ReflectionUtils.newInstance(job.getInputFormatClass(), conf); List<InputSplit> splits = input.getSplits(job); -
最后将切片描述信息写到submitterJobDir资源提交路径中。
JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array); -
InputSplit包含block块所在位置主机,路径,偏移量等信息。分片数据不包含数据本身,而是指向数据的引用。
-
input.getSplits()方法解析

由FileInputFormat类中getSplits方法决定。
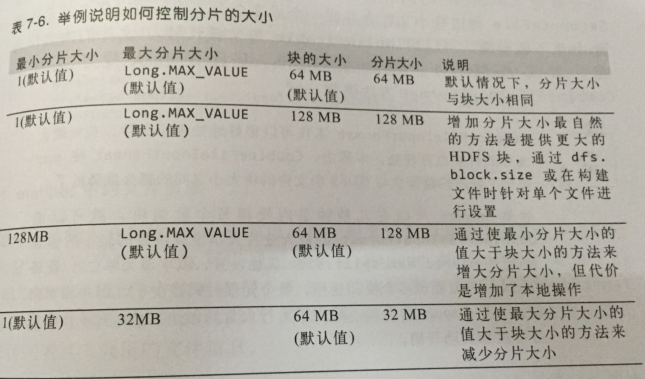
计算公式://computeSplitSize中 minSize=max{getFormatMinSplitSize(),mapred.min.split.size} (getFormatMinSplitSize()大小默认为1B) maxSize=mapred.max.split.size(不在配置文件中指定时大小为Long.MAX_VALUE) //blockSize是默认的配置大小:128MB //分片大小的计算公式 splitSize=max{minSize,min{maxSize,blockSize}}
默认情况下,minSize < blockSize < maxSize
所以,默认不在配置文件配置split最大值和最小值,分片大小就是blockSize,128MB。
公式的含义:取分片大小不大于block,并且不小于在mapred.min.split.size配置中定义的最小Size。
举例说明如何控制分片大小:
3. 为什么Hadoop不擅长小文件
逻辑上,FileInputFormat生成的分块是一个文件或者该文件的一部分,如果是很多小文件,就生成了很多的逻辑block。默认情况下,一个分片就是一个block,因而,会有很多个map任务,每次map操作都有很多额外的开销。
因此,运行大量小文件的任务,会增加运行作业的额外开销;浪费NameNode内存。
解决:CombineFileInputFormat
参考《Hadoop权威指南》
初接触,记下学习笔记,还有很多问题,望指导,谢谢。

