
深入理解mongodb查询条件语句
2018-11-18 01:22 龙恩0707 阅读(9915) 评论(0) 编辑 收藏 举报阅读目录
- 1. 理解:"$lt"、"$lte"、"$gt" 和 "$gte"
- 2. 理解 '$ne'
- 3. 理解 "$in" 和 "$or", 及 "$nin"
- 4. 理解使用正则表达式来查询
- 5. 理解查询数组 $all, $size 操作符的使用
- 6. 理解 limit, skip 和 sort
- 7. 实现分页:
1. 理解:"$lt"、"$lte"、"$gt" 和 "$gte"
首先在讲解查询条件之前,我们先看看我们的数据库中有哪些基本的数据,我们可以使用如下代码查询下:如下代码:
const mongo = require('mongodb');
const Server = mongo.Server;
const Db = mongo.Db;
const server = new Server('localhost', '27017', { auto_reconnect: true });
const db = new Db('dataDb', server, { safe: true });
db.open(function(err, db) {
if (err) {
throw err;
} else {
console.log('成功建立数据库连接');
db.collection('users', function(err, collection) {
if (err) {
throw err;
} else {
// 开始查询集合users
collection.find({}).toArray(function(err, docs) {
if (err) {
throw err;
} else {
console.log(docs);
db.close();
}
});
}
});
}
});
如下图所示:
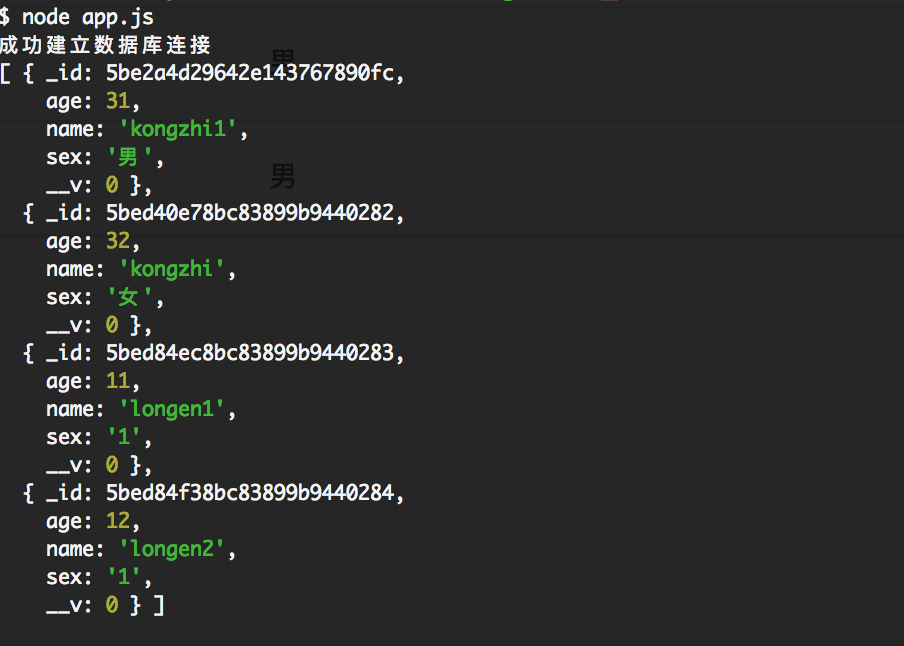
"$lt"、"$lte"、"$gt" 和 "$gte" 分别对应 <、<=、> 和 >=. 可以将其组合起来查找一个范围的值。
现在我们想查询年龄在 30岁到40岁的用户,就可以使用如下命令了,如下代码:
collection.find({"age" : {"$gte": 30, $lte: 40}});
所有代码如下:
const mongo = require('mongodb');
const Server = mongo.Server;
const Db = mongo.Db;
const server = new Server('localhost', '27017', { auto_reconnect: true });
const db = new Db('dataDb', server, { safe: true });
db.open(function(err, db) {
if (err) {
throw err;
} else {
console.log('成功建立数据库连接');
db.collection('users', function(err, collection) {
if (err) {
throw err;
} else {
// 开始查询集合users
collection.find({"age" : {"$gte": 30, $lte: 40}}).toArray(function(err, docs) {
if (err) {
throw err;
} else {
console.log(docs);
db.close();
}
});
}
});
}
});
执行结果为:
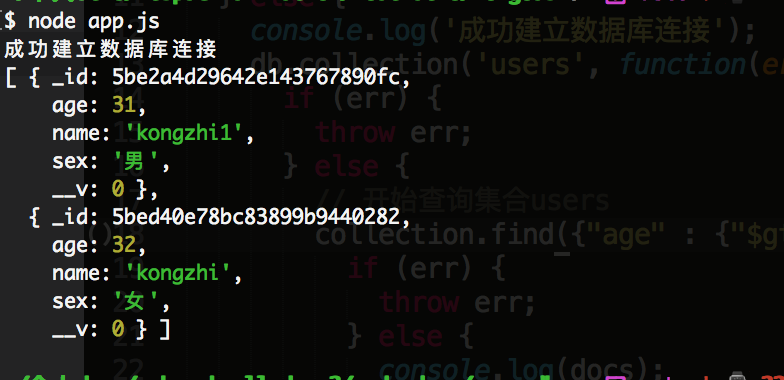
注意: 下面的查询我只会写一句代码哦,其他的代码和上面代码一样,比如查询代码,只会写这么一句:
collection.find({"age" : {"$gte": 30, $lte: 40}}),为了节约篇幅。
2. 理解 '$ne'
$ne' 的含义是,文档的键值不等于某个特定值,它的含义是 表示 '不相等的意思'。比如我现在想查询 名字不等于 'kongzhi'.
首先我们数据库还是有如下数据:
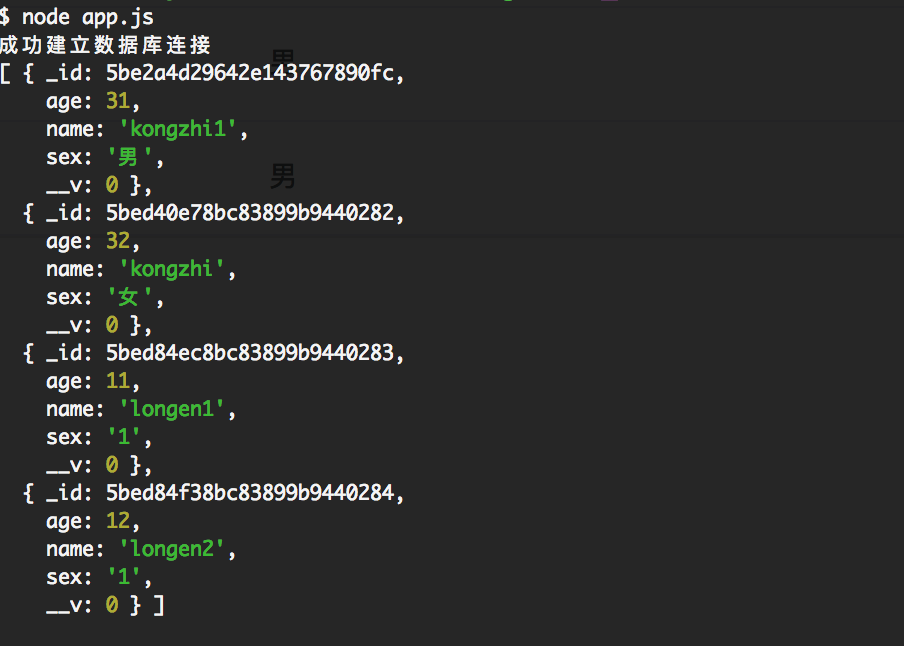
我们可以像如下查询:
collection.find({"name" : {"$ne": 'kongzhi'}})
含义是查询文档后,不包含 name = "kongzhi" 的所有数据,运行结果可以看到如下:

3. 理解 "$in" 和 "$or", 及 "$nin"
Mongodb中有两种方式进行or查询,"$in" 可以用来查询一个键的多个值;"$or" 可以在多个键中查询任意的给定值。
那么他们有什么区别呢?
1)'$in' 可以理解为 '包含的意思',比如说,我想查询 name 包含 'longen1' 和 'longen2' 这两个值的话,可以使用 '$in'
进行查询。比如如下查询语句:
collection.find({"name" : {"$in": ['longen1', 'longen2']}})
执行结果如下所示:
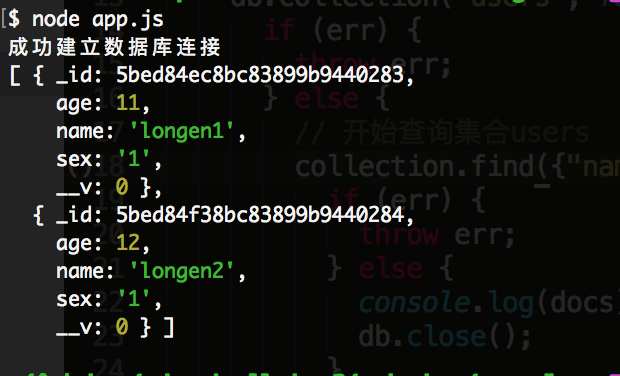
2)'$nin': 和 '$in' 相对应的是 '$nin', '$nin' 将返回与数组中所有条件都不匹配的文档。比如说,我想返回数据不包含 'longen1' 和 'longen2' 的数据,可以使用如下命令:
collection.find({"name" : {"$nin": ['longen1', 'longen2']}})
执行结果如下所示:

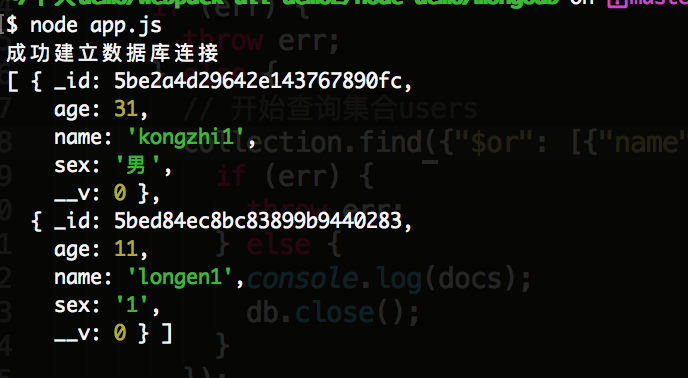
3)'$or' 的含义是 '或者的意思',就是说 我既要查询到 name='longen1', 还要查询到 name='kongzhi1' 这样的数据,就可以使用 '$or'了,'$or' 接受一个包含所有条件的数组作为参数。比如如下执行命令:
collection.find({"$or": [{"name": 'longen1'}, {"name": 'kongzhi1'}]})
执行结果如下所示:
4. 理解使用正则表达式来查询
正则表达式能够灵活有效地匹配字符串,比如说我想查找所有名为 "long" 的用户,可以如下执行代码:
collection.find({"name": /long/i});
查询结果如下所示:
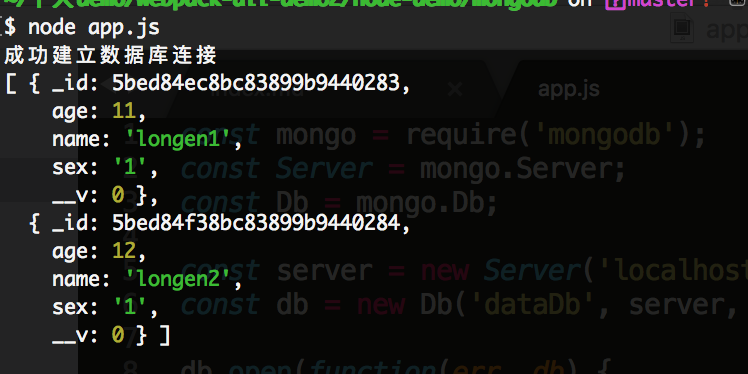
它可以模糊匹配到所有name字段含有 'long' 的字符串的,再比如,我匹配查找所有含有 'kong' 字符串的,执行代码如下:
collection.find({"name": /kong/i});
查询结果如下所示:

注意:使用正则匹配的方式和我们的javascript的正则匹配是一模一样的语法。也就是说 兼容Perl的正则表达式的语法。
5. 理解查询数组 $all, $size 操作符的使用
5.1) $all: 该操作符的含义是使用多个元素来模糊匹配数组,也就是说,如果多个数组里面包含 $all 匹配的内容的话,那么该数组都会被匹配出来。
假如现在users集合里面有如下数据:

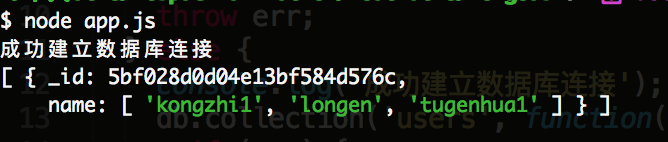
我现在想匹配 "name": ['kongzhi', 'tugenhua'] 这样的,把数组同时包含这两个数据的数组匹配出来,可以如下代码:
collection.find({"name": {$all: ['kongzhi', 'tugenhua']}})
执行结果如下:

如上也可以对整个数组进行精确匹配。
但是如果想查询数组特定位置的元素,需要使用 key.index 语法指定下标:如下代码:
collection.find({"name.0": 'kongzhi1'});
数组的下标都是从0开始的,所以上面的表达式会使用数组的第一个元素 和 kongzhi1 进行匹配。如下匹配的结果:
5.2)$size
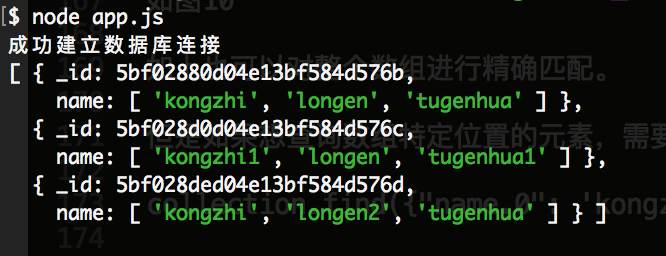
该操作符的含义是 查询特定长度的数组。如下代码:
collection.find({"name": {"$size": 3}})
它的含义是 查询 name字段的数组长度为3的。查询结果如下:
如果我们现在把查询的长度改为1或者2的话,比如如下代码:
collection.find({"name": {"$size": 1}})
那么它就会什么都不能匹配到,如下所示:
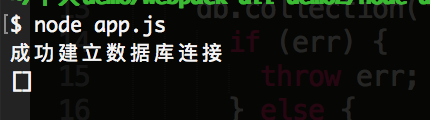
6. 理解 limit, skip 和 sort
6.1) limit: 该操作符是限制结果数量的含义,可以在find后使用 limit函数,比如整个users集合里面有如下数据:

一共有6条数据。
现在我们使用limit函数,比如限制只返回3条数据,代码可以如下写:
collection.find().limit(3).toArray(function(err, docs) {})
执行结果如下所示:
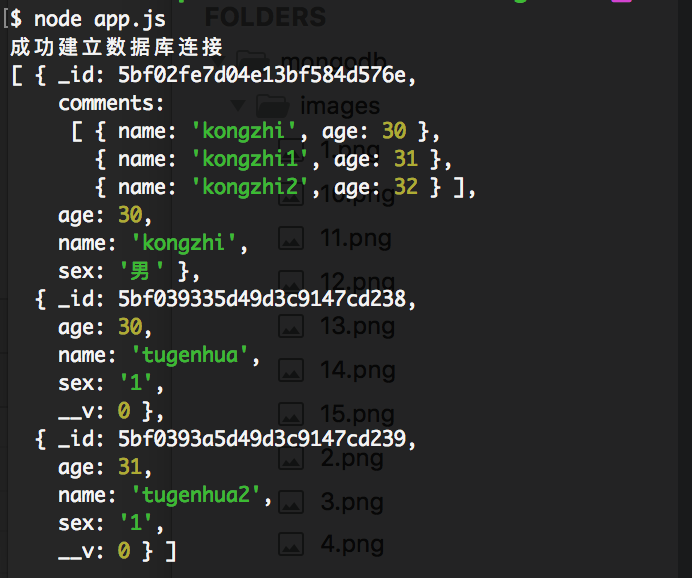
limit指上限,可以理解为返回最多3个,但是如果数据库集合里面数据没有3个的话,那么就会返回匹配数量的结果。
6.2) skip 该操作符的含义是 跳过集合中的多少个数据,然后返回集合中剩下的数据,比如如下匹配代码:
collection.find().skip(3).toArray(function(err, docs) {})
它会跳过集合中三个数据,然后返回集合中剩余的数据,执行结果如下所示:
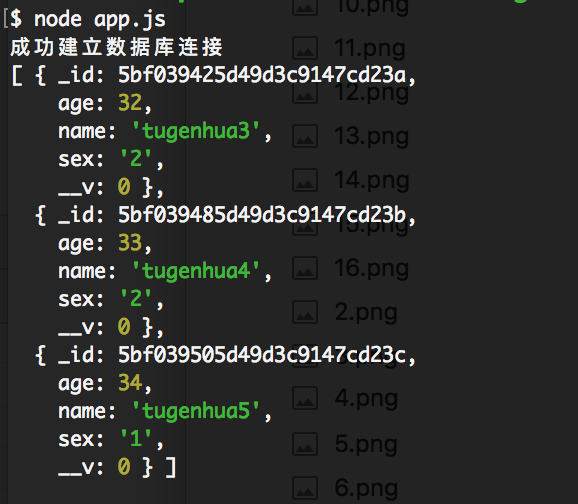
6.3)sort, 该操作符接收一个对象作为参数,这个对象是一组 键/值对,键对应集合中的键名,值代表排序的方向,排序的方向可以是1(升序),或者 -1(降序)。如果指定了多个键,则按照这些键被指定的顺序逐个排序。
比如我们现在想要按照 age 降序,代码可以如下写:
collection.find().sort({age: -1}).toArray(function(err, docs) {})
执行结果如下所示:
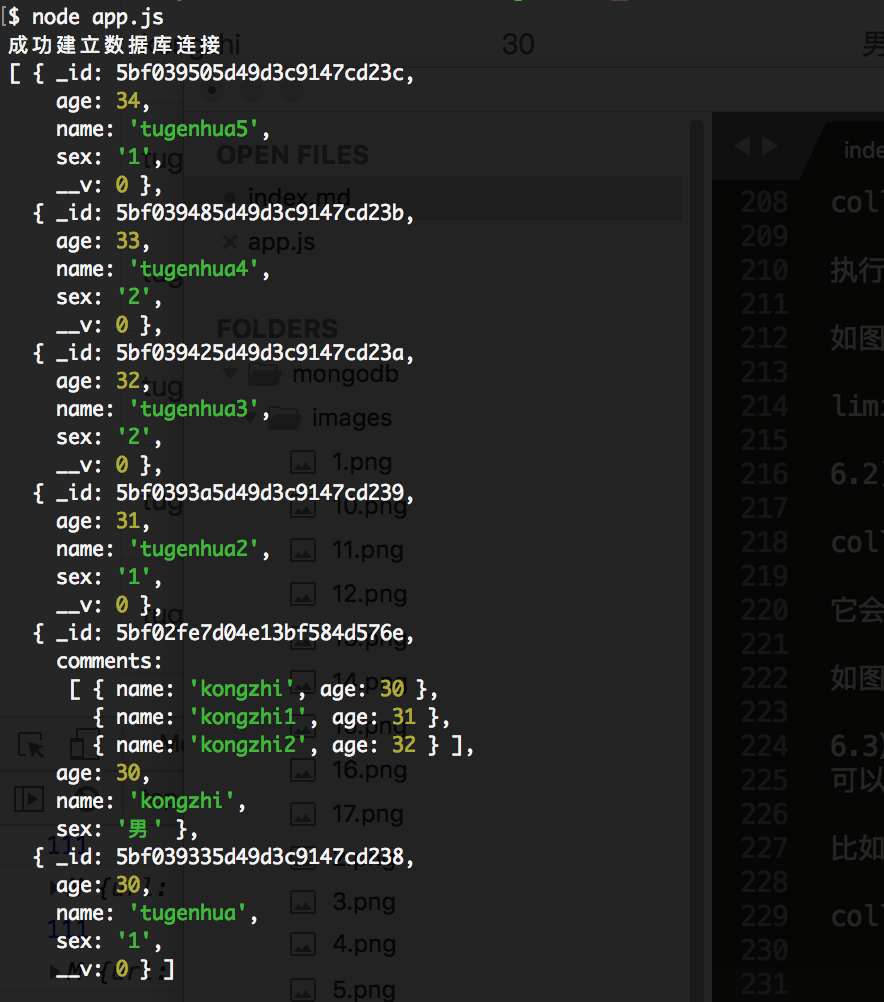
7. 实现分页:
7.1)使用skip进行分页:如上三个操作符可以组合使用,对于分页来说非常有用,比如我想每页返回2条数据,并且按age从高到底进行排序;可以如下写代码:
collection.find().limit(2).sort({age: -1}).toArray(function(err, docs) {})
执行结果如下所示:
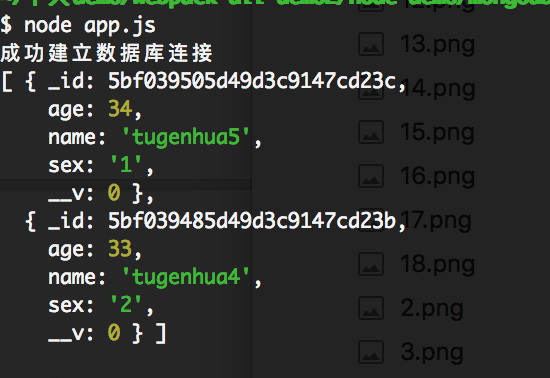
当我们点击下一页的时候,可以查看更多的结果,我们可以通过skip实现,只需要跳过前面2条数据就好了。
collection.find().limit(2).skip(2).sort({age: -1}).toArray(function(err, docs) {})
执行结果如下:

因此我们可以简单这样实现一个分页,根据传进来的页码及一页多少条来判断。比如我们默认一页10条数据,然后默认跳过0条,就是第一页的数据,如果用户传递进来当前的页码是2,每页的条数是20条的话,那么就使用用户传递进来的参数进行操作。
var page = 1,
pagesize = 10;
if ('用户传进来的页码') {
page = '用户传进来的页码'
}
if ('用来传进来的页码大小') {
pagesize = '用户传进来的页码大小';
}
/*
跳过多少条的逻辑: 如果当前的页码是第一页的话,那么就跳过0条;
如果当前的页码是大于1的话,比如第2页,那么跳过的条数是 (2-1) * 一页多少条数据
skipCount(跳过的条数的计算方式) = (page - 1) * pagesize;
*/
因此执行分页的代码如下:
collection.find().limit(pagesize).skip(skipCount).sort({age: -1}).toArray(function(err, docs) {})
注意:skip进行分页有缺点的,如果使用skip跳过很多条数据的时候,查询的速度会变得非常慢,因为我们先要找到需要被跳过
的数据,然后再抛弃这些数据。因此我们不要使用skip对结果分页的。

