
OO第四单元总结
OO第四单元总结
一、本单元架构设计
1、第一次作业
建立了四个功能类来完成各部分查询功能,降低耦合:
AssociationManager类用以管理UML类的关联。
AttributeManager类用以管理UML类的属性。
OperationManager类用以管理UML类的操作。
InterfaceManager类用以管理UML类实现的接口。
在MyUmlClass中,实例化了上述四个类,添加方法与查询方法分别调用对应Manager中的查询方法。
建立了MyUmlInterface类,在UmlInterface的基础上,封装了父类接口的添加以及查询所有的已继承的接口的功能。
在MyUmlInteraction中,根据Umlelement建立对应的对象,查询时对应查询即可。
类图如图所示:
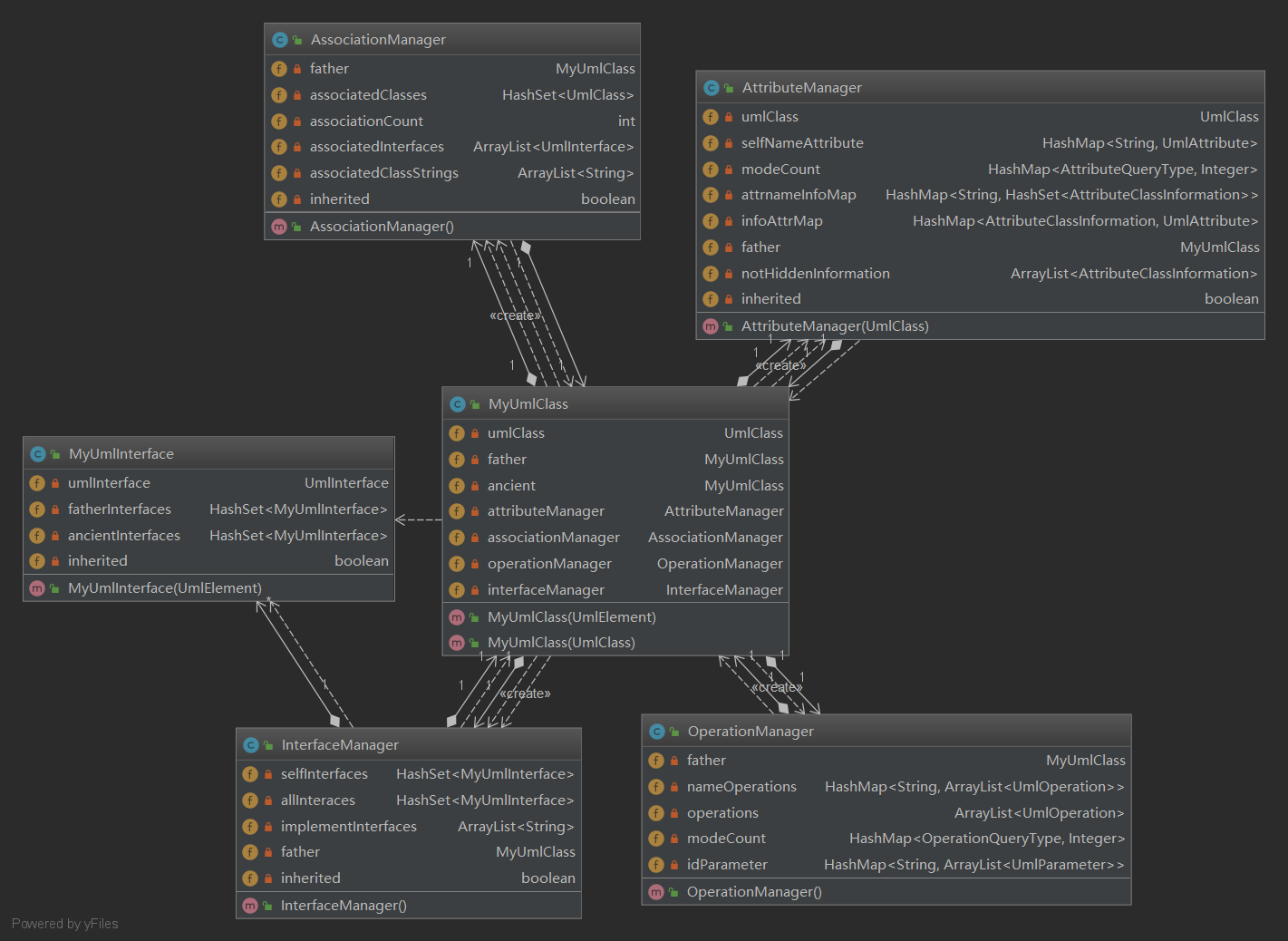
2、第二次作业
在第一次作业的基础上:
顺序图:
MyInteraction封装顺序图,内部存储lifeline、message等信息,用以管理顺序图相关的查询。
状态图:
MyUmlstate在Umlstate的基础上,存储了直接后继状态的信息,可以查询后继状态的个数。
MyUmlRegion管理下属的所有state,并提供对应查询方法。
MyUmlStateMachine实例化并管理UmlRegion,在本次作业中,由于只有一层UmlRegion,嵌套关系可以省略,但是分层管理的思想还是很重要的。
类图如下所示:

二、架构总结
第一单元
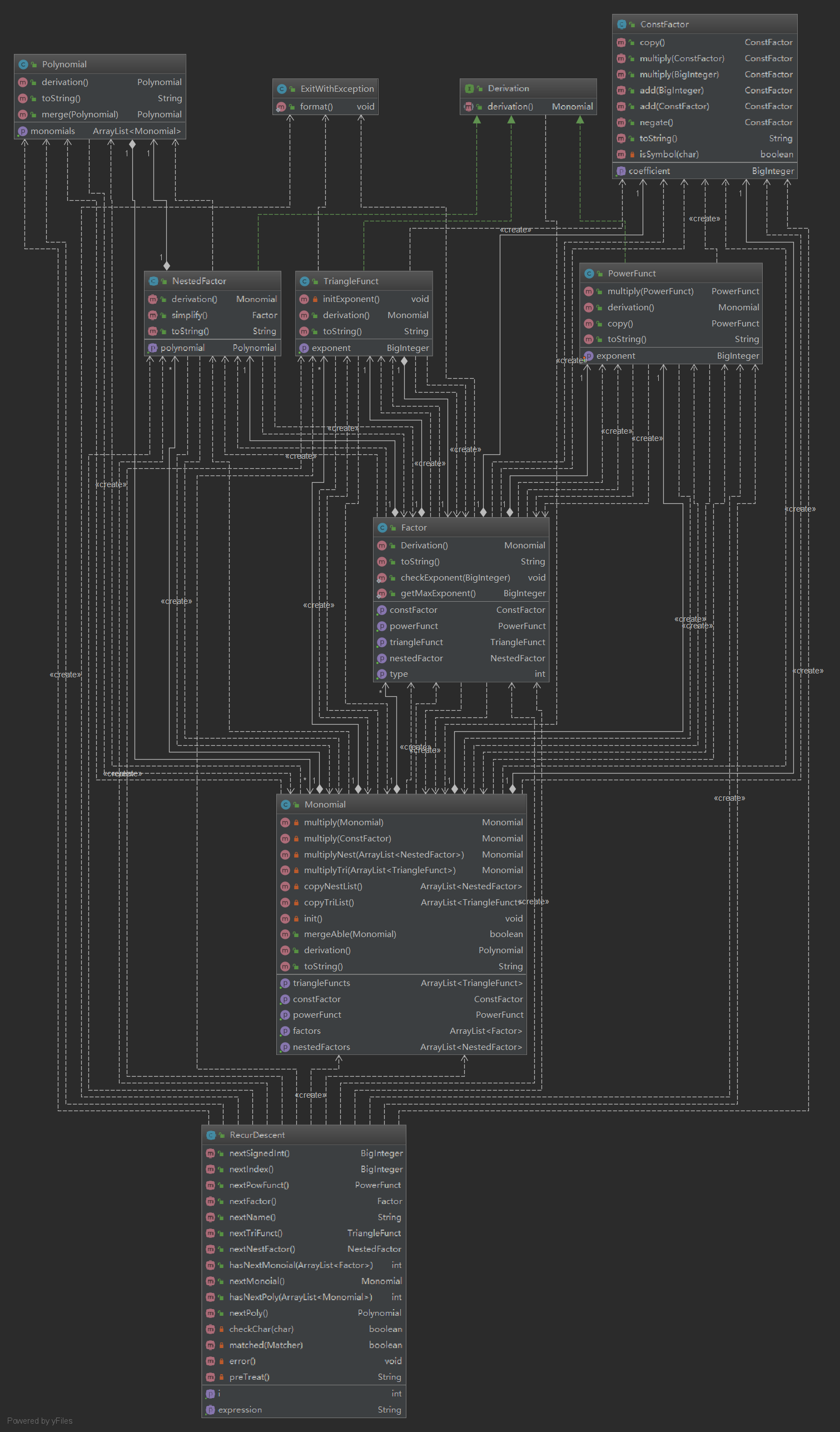
由于当时还不是很会使用接口,采用了几乎三元组的方式管理多项式,导致程序不仅耦合度高,而且可扩展性极差。
更类似于面向过程的思维方式,导致类的抽象层次无法很好的把握。抽象层次越高,码量会越大,维护起来也更为复杂,在抽象与下次作业的扩展无关时,只能徒增工作量。而抽象层次过低,则会导致代码耦合度过高,甚至于出现完全面向过程、一main到底的情况。如何平衡抽象层次与架构的关系,是当时困惑我的一个主要问题。
第一单元第二次作业中,我把变量抽象成了一个类,在第三次作业的需求中,这个抽象当然是毫无意义的,保留只会增加码量。于是在重构的过程中,我就删除了这一级的抽象。
可见,抽象层次还是与具体需求密切相关的。改需求真的是一生之敌。
附上当时的类图。
第二单元
多线程电梯问题中,我对架构的重要性有了一定的了解,对于多线程可能存在的并发问题及相应的解决措施,也算一知半解。在架构的过程中,我把调度器与电梯的职能划分清楚:调度器负责接收与分配请求,电梯负责按照一定的逻辑/算法,运送人员。这样一来,每个线程的分工就非常明确了。在第二次作业中,虽然只有一个电梯,可以采用主动从调度器拿请求的方法,但我还是采用了调度器主动分配,利于多电梯的扩展。
不过有个比较遗憾的地方是,本单元作业存在电梯类逻辑过于复杂的问题,方法数达到了20多个,这不仅不利于维护,而且带来了很大的风险。
第三单元
涉及到了面向过程与面向对象思想的结合。建立Graphs类来管理图相关的算法(floyd,bfs,dfs等),以公共静态方法的形式存储。这样可以将数据结构相关的图算法与业务逻辑分离,便于管理。
在面向对象与面向过程逻辑的结合中,对面向对象的思想的理解更加深刻了。
三、测试与实践总结
第一单元
python生成随机数据+sympy库对拍,依靠大数据轰炸测试。
使用已成熟的运算库来作为正确输出对拍,只需提供随机输入便可自动测试。
第二单元
python生成随机数据+正确性逻辑(不得超速、不得超载,必须送到指定楼层等)分析输出。
依赖指导书所给的正确性逻辑,可以判断输出中电梯状态是否违法,依次可判断输出是否正确。
第三单元
Junit单元测试与小范围的python随机数据对拍。
Junit测试的优点在于,白盒测试有利于定位错误,可以尽可能地覆盖代码的每一处。因此采用黑盒+白盒的测试方法,既可以用大量数据的轰炸测试寻找bug,又可以在出现bug时快速定位问题所在,不可谓不妙。
第四单元
Junit测试与部分对拍。
手搭数据生成器工作量太大了,考期实在没那个精力了。
四、课程收获
1、对面向对象的思想与架构设计有了自己的了解,包括不限于工厂模式、观察者模式等。
2、认识到了架构优先的重要性,遇到一个问题应该首先思考如何架构,而不是直接动手写代码,后者往往会面临一次次的重构。
3、对于代码规范的表达形式有了一定了解。
4、初步了解了Uml类图、顺序图的层次与含义。
5、最不重要的一点,学会了一点Java。
五、建议
1、在前几次作业中,引导学生完成从面向过程到面向对象思维的转变。在刚开始介绍面向对象含义的时候,大家对这个概念可能有一定自己的理解,但不是很深刻。如果这个时候有一些提示性的操作,例如建立好求导接口,要求在作业中实现等,可能会使得这个过度更加平滑一些。
2、有时间限制的作业,提供给学生参考时间的渠道。例如在网站上提供一个窗口,可以提交代码,只返回对应的CPU时间、内存占用等信息,不返回评测信息。数据也由学生提交。这样可以使得学生对程序耗时有一个大致的估计。评测机的环境与本地相差较大,有一些同学反映本地可以立刻给出答案的点,在评测机上就TLE了。
3、助教问题。结束的时候才知道9个助教已经确定了,本来还想申请一下助教的,没想到直接内定了。这样的事情不公开,还是觉得很奇怪。

