

从词频统计中,认识spark计算
记得学习编程语言时,老师直接让我打印Hello World!。这种直接动手操作,然后看到效果的方式;比先讲一大堆语法、概念更容易让人理解,接受。
自然而然的,词频统计(WordCount)就是学习分布式计算的第一步。
val master = "local"
val conf = new SparkConf().setMaster(master).setAppName("WordCount")
val sc = new SparkContext(conf)
sc.textFile("realRatings.txt")
.flatMap(_.split(","))
.map(word=>(word,1))
.reduceByKey(_+_)
.sortBy(_._1.toInt)
.collect()
.foreach(println)
其中数据文件是:
1001,1,4
1001,3,3
1001,5,4
1003,1,5
1003,3,4
1002,2,2
1002,4,3
1002,5,4
1004,2,2
1004,4,3
运行结果是:
(1,2)
(2,4)
(3,5)
(4,6)
(5,3)
(1001,3)
(1002,3)
(1003,2)
(1004,2)
运行时出现错误
class "javax.servlet.FilterRegistration"'s signer information does not match signer information of other classes in the same package;
参考解决方案http://stackoverflow.com/questions/28086520/spark-application-throws-javax-servlet-filterregistration;本地spark-hive_2.11现依赖
<artifactId>javax.servlet</artifactId> <groupId>org.eclipse.jetty.orbit</groupId>
而初始化org.apache.spark.ui.WebUI需要
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>9.3.6.v20151106</version>
</dependency>
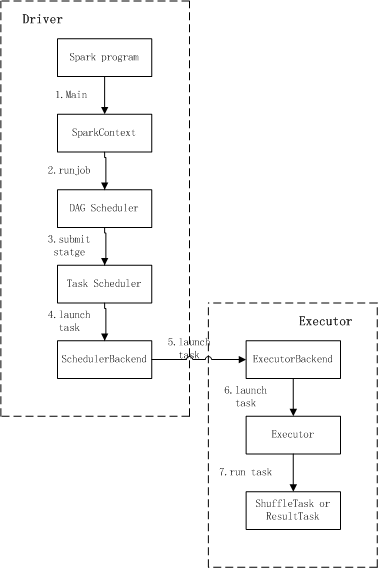
看下任务执行流程及相关的基本概念。Application、Job、Driver、Stage、Task、RDD
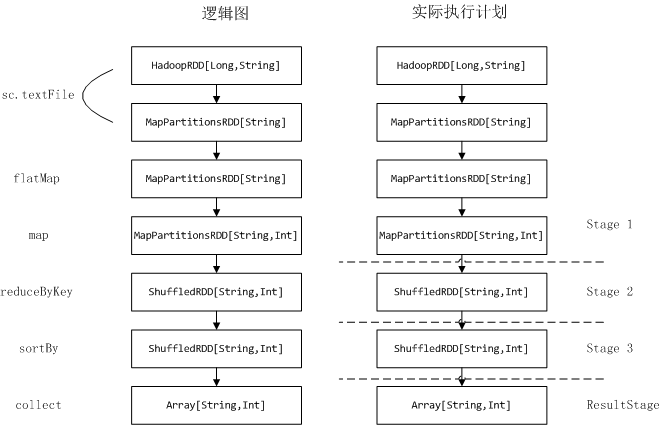
RDD两类操作方式:transformation和action
Task任务类型:ShuffleMapTask和ResultTask
伯克利大学AMPLab实验室从2009年针对当时的Map-Reduce框架执行速度的问题。进行研发改进,到2010年开源;2013年开源到apache。现在比较成熟的组件;他的优点就是统一一套API;能够完成离线、在线、机器学习和图计算不同场景的数据处理。减低的学习成本。
而spark架构使我们熟悉的主从结构;master节点负责接收提交了任务,管理、分配资源;worker节点负责实际任务执行。

现在在回到例子。这是实际执行流程图:
spark load data to hive and sparkSQL(目前使用典型场景)
数据解析模板:


1 val sqlContext = new HiveContext(sc) 2 import sqlContext.implicits._ 3 4 val filePath = s"${fsdir}/flume/${event}/$today" 5 sc.textFile(filePath) 6 .map(EventInfo(_)) 7 .coalesce(load_parallelism) 8 .toDF() 9 .write.parquet(tmpPath.toUri().toString()) 10 11 sqlContext.sql("load data inpath '"+tmpPath.toUri()+s"' into table ${event_minute} partition (date='$today')")
统计逻辑模板:

1 val connectionProperties = new Properties 2 connectionProperties.put("user", user) 3 connectionProperties.put("password", pwd) 4 5 sqlContext.sql(s"select $dateNum as click_date ,eventid as event_name,label,acc,cast(count(1) as int) as click_times,cast(count(distinct deviceid) as int) as click_users "+ 6 s"from $event where date='$statDay' and (eventid in ('m_banner','m_news','m_well','m_help','m_points','m_star','m_more') or (eventid='recreate_click' and label='5' ) ) "+ 7 s"group by eventid,label,acc ") 8 .toDF() 9 .coalesce(load_parallelism) 10 .write.mode(SaveMode.Append) 11 .jdbc(url, mysqlTableName, connectionProperties)
UC Berkeley AMPLabl:https://zhuanlan.zhihu.com/p/21350352?refer=bittiger

