

【索引压缩】
信息检索系统中的两个主要数据结构:词典及倒排索引。下面将介绍对这两个数据结构的各种压缩技术,这些技术对于构建高效的 IR 系统非常关键。 进行压缩的一个优点显而易见:它能够节省磁盘空间。要达到 1∶4 的压缩比是非常容易的,也就是说可以降低 75%的索引存储开销。
索引压缩还有两个隐含的优点。第一是能增加高速缓存(caching)技术的利用率。在搜索 系统中,词典中某些条目及其索引往往比其他条目及其索引的使用更频繁。例如,如果将一个频 繁使用的查询词项 t 的倒排记录表放到高速缓存中,那么对仅由 t 构成的查询进行应答所需要的 计算完全可以在内存中完成。如果采用压缩技术,那么高速缓存中就可以放更多的信息。当查询词项 t 的信息放在高速缓存时,处理查询 t 便不再需要进行磁盘操作,而只需将其倒排记录表在内存中解压缩即可。因此,我们能充分减少 IR 系统的应答时间。由于内存比磁盘更贵,所以, 相对于磁盘空间的减少,采用高速缓存技术带来的速度提升是采用压缩技术的更主要的原因。
第二个隐含的优点是,压缩能够加快数据从磁盘到内存的传输速度。高效的解压缩算法在现代硬件上运行相当快,这样将压缩的数据块传输到内存并解压所需要的总时间往往会比将未压缩的数据块传输到内存要快。举例来说,即使会增加在内存进行解压缩的开销,我们也可以 通过加载一个小很多的压缩倒排记录表来减少 I/O 时间。因此,在大部分情况下,使用压缩倒排记录表的检索系统会比没用压缩的系统的运行速度要快。
如果压缩的主要目的是为了节省磁盘空间,那么压缩算法的速度就不用特别考虑。但是, 如果要提高高速缓存利用率和磁盘到内存的传输率,则解压缩的速度必须要快。本章介绍的压缩算法都非常高效,都可以达到上面提到的索引压缩的全部 3 个目标。
【将词典看成单一字符串的压缩方法】
采用定长方法来存储词项存在着明显的空间浪费。 一种解决上述缺陷的方法是,将所有的词项存成一个长字符串,并给每个词项增加一个定位指针,它在指向下一词项的指针同时也标识着 当前词项的结束。 (就是目前构架中的var_data)
实际上,按照词典顺序排序的连续词项之间往往具有公共前缀。因此,可以采用一种称为前端编码(front coding)的技术。 公共前缀被识别出来之后,后续的词项中便可以使用一个特殊的字符来表示这段前缀。

【倒排记录表的压缩】
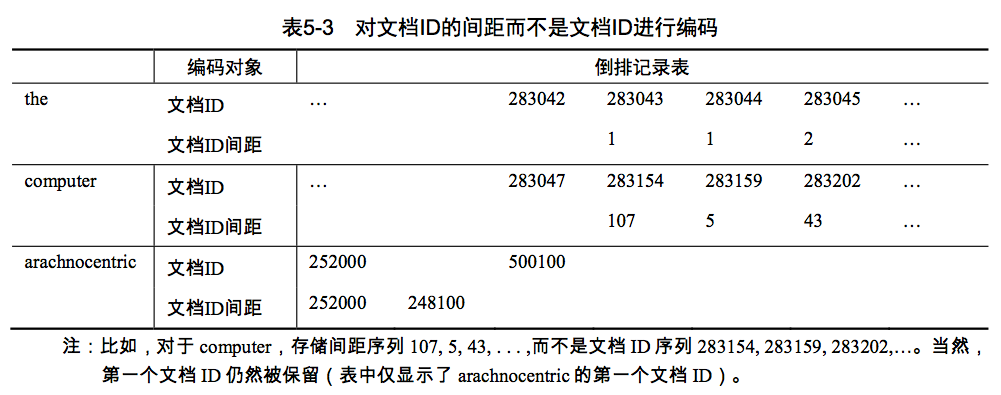
想象一下在文档 集中遍历文档来寻找某个高频词项(如 computer)的过程:我们会找到一篇包含 computer 的文 档,然后可能会跳过几篇不包含它的文档,之后又会找到另一篇包含 computer 的文档。这个过 程可以不断循环下去(参见表 5-3)。这里面最关键的思路就是(一些词项对应的)倒排记录表 中文档 ID 之间的间距(gap)不大,因此可以考虑用比 20 比特短很多的位数来表示它。实际上, 对于一些高频词(如 the 和 and)来说,绝大部分间距都是 1。当然,对于只在文档集中出现一 两次的罕见词(如表 5-3 中的 arachnocentric),其间距的数量级和文档 ID 的数目是一样的,因 此仍然需要 20 比特。为了对这种间距分布的情况进行空间压缩,需要使用一种变长编码方法, 它可以对短间距采用更短的位数来表示。
【可变字节码】
VB(Variable byte, 可变字节)编码利用整数个字节来对间距编码。字节的后 7 位是间距的有效编码区,而第 1 位是延续位(continuation bit)。如果该位为 1,则表明本字节是某个间距编 码的最后一个字节,否则不是。要对一个可变字节编码进行解码,可以读入一段字节序列,其中前面的字节的延续位都为 0,而最后一个字节的延续位为 1。根据上述标识可以把每个字节的 7 位部分抽取出来并连接在一起形成编码。

