
mysql-cluster;版本,配置;
http://galeracluster.com/products/
http://www.clusterdb.com/
http://www.severalnines.com/cluster-configurator/
https://www.mysql.com/products/cluster/
https://dev.mysql.com/downloads/cluster/
http://dev.mysql.com/downloads/
http://www.oracle.com/us/products/mysql/mysqlcluster/overview/index.html
http://www.mysqlab.net/tool/mysql-cluster/config.generator/computers/4/cpus/8/memory/32/replica/4
http://huanghualiang.blog.51cto.com/6782683/1288794
http://database.51cto.com/art/201503/467371.htm
甲骨文MySQL Cluster 7.4全面上市

甲骨文公司今天宣布MySQL Cluster 7.4全面上市。这一最新版本进一步提高了性能、高可用性和先进的管理能力,可更好的支持要求极端苛刻的电信行业、Web、移动应用及云服务。
甲骨文公司今天宣布MySQL Cluster 7.4全面上市。这一最新版本进一步提高了性能、高可用性和先进的管理能力,可更好的支持要求极端苛刻的电信行业、Web、移动应用及云服务。
甲骨文公司MySQL开发副总裁Tomas Ulin表示:“数字技术的快速普及导致数据量前所未有地增加,因此企业需要尽可能提高联机交易处理系统的效率和性能。MySQL Cluster 7.4没有单点故障问题,提供满足多种应用需求的高性能,适用范围广,从大型电信企业的数据库管理员到新一代Web、云、社交及移动应用提供商的各种用户群均可受益。最新版本进行了重要更新,不仅提高了整体性能,还减轻了数据库管理员及开发运营团队的管理负担。”
MySQL Cluster是一款ACID兼容的开源事务处理型数据库,具有实时内存性能和99.999%的可用性。该产品可以支撑大型通信服务提供商的用户数据库,并可用于监测针对全球金融交易的欺诈活动。最新的7.4版本是基于一系列具有里程碑意义的版本而开发,已启用用户预览和测试,并在开发过程中提供反馈。MySQL Cluster 7.4的最新功能包括:
•更强内存性能和可扩展性:根据SysBench标准,MySQL Cluster 7.4在只读工作负载上的性能比MySQL Cluster 7.3提高了近50%,读写操作性能也提高了40%。性能改进可通过SQL或任何由MySQL Cluster支持的本地NoSQL 应用程序接口得到实现,包括Java, C++,HTTP, Memcached和JavaScript/node.js。此外,MySQL Cluster 7.4还创造了新纪录,即通过32个数据节点实现每秒2亿条NoSQL查询,以及通过 16个数据节点每秒查询近250万SQL语句。
•改进的工作负载效率分析:现在,用户可以在MySQL 集群上使用相同的记忆优化表高效运行涉及复杂分析和随机搜索的应用负载,这为OLTP工作负载提供了亚毫秒级别的超低延迟和高水平的并发性能。这些内存表可以和基于磁盘的表共同使用。
•新的跨地域冗余功能实现跨数据中心的高可用性:最新版本的MySQL Cluster7.4提供冲突性事务传回功能,并能在跨地域集群之间实现灵活可用、即时更新的复制功能,使得应用可以自由向任意站点发送查询或写入命令,同时完全不影响一致性。
•高级管理功能: MySQL Cluster为内部部署和基于云的部署提供了以下改进:
o新的分布式内存使用和数据库操作报告,提高管理效率;
o其他性能调优选项;
o更快的网络维护操作,包括软件升级速度提高多达5倍。
=========================================================================================
http://www.guohao001.com/?p=1265
针对MySQL及其派生分支的研究
第一章 关于MySQL
一、 MySQL的发展历程
MySQL是由原MySQL AB公司自主研发的,是目前IT行业最流行的开放源代码的数据库管理系统,同时它也是一个支持多线程高并发多用户的关系型数据库管理系统。从微型的嵌入式系统到中小型的Web网站,至大型的企业级应用,到处都可见其身影。
MySQL从诞生到崛起,经历了一系列艰难的发展历程。它始于1979年,最初是Michael Widenius为瑞典TcX公司创建的UNIREG数据库系统,当时的UNIREG没有SQL接口,限制了它的应用。1985年,以David Axmark为首的几个瑞典小伙成立了一家公司,他们设计了一个利用索引顺序存取数据的方法,同时结合mSQL,用以满足为大型零售商提供数据仓库服务的需要。然而mSQL严重影响性能,于是他们重新开发了一套功能类似的数据存储引擎,ISAM 存储引擎面世。1990年,TCX的客户中有人要求为它的API提供SQL支持,于是Monty雄心大起,决心自己重写一个SQL支持,终于在1996年10月,MySQL千呼万唤始出来,MySQL1.0正式发布。MySQL的发展路线图如下图所示。

图 1 MySQL发展路线图
数据来源:互联网资料整理,2014.9.13
1996年10月,MySQL 3.11.1正式发布,没有2.x版本,最开始只提供Solaris下的二进制版本,随后Linux版本出现,此时的MySQL非常简陋,除了可在一个表上做些Insert,Update,Delete和Select 操作以外没有其他更多的功能。MySQL关系型数据库于1998年1月发行第一个版本,它使用系统核心的多线程机制提供完全的多线程运行模式,并提供了面向C、C++、Eiffel、Java、Perl、PHP、Python等编程语言的编程接口(API),支持多种字段类型,并且提供了完整的操作符支持。
1999年到2000年,MySQL AB公司在瑞典成立。Monty雇了几个人与Sleepycat合作,开发出Berkeley DB引擎,MySQL从此开始支持事务处理。2000年MySQL 公布了自己的源代码,并采用GPL(GNU General Public License)许可协议,正式进入开源世界。同年4月,MySQL对旧的存储引擎ISAM进行了整理,将其命名为MyISAM。2001年,Heikki Tuuri向MySQL提出建议,希望能集成他的存储引擎InnoDB,这个引擎同样支持事务处理,还支持行级锁。2001年发布3.23 版本,该版本已经支持大多数的基本的SQL 操作,而且集成了MyISAM和InnoDB 存储引擎,InnoDB引擎被证明是最为成功的MySQL事务存储引擎。2001年10月MySQL发布4.0版本,MySQL与InnoDB正式结合。2003年4月,MySQL 4.1正式发布,12月MySQL 5.0版本发布,提供了视图、存储过程等功能。2005年10月,发布了5.0里程碑的一个版本,加入了游标、存储过程、触发器、视图和事务的支持。在5.0 之后的版本里,MySQL明确地表现出迈向高性能数据库的发展步伐。
2008年1月,MySQL AB公司被Sun公司以10亿美金收购,同年11月,MySQL 5.1发布,它提供了分区、事件管理,以及基于行的复制和基于磁盘的NDB集群系统,同时修复了大量的Bug。2009年4月,Oracle公司以74亿美元收购Sun公司。2010年12月,MySQL 5.5发布,其主要新特性包括半同步的复制及对SIGNAL/RESIGNAL的异常处理功能的支持,最重要的是InnoDB存储引擎终于变为当前MySQL的默认存储引擎。MySQL 5.5加强了MySQL各个方面在企业级的特性。
目前最新版本的MySQL是2014年3月31日发布的里程碑版本MySQL 5.7.4,同时5.7.5和5.7.6也正在计划中。
二、 MySQL的本质内涵
1. MySQL的适用场景
MySQL是目前最为流行的开源数据库管理软件,其适用范围主要体现在五类应用场景中,分别是Web网站系统、日志记录系统、数据仓库系统、嵌入式系统以及网络游戏领域。
(1) Web网站系统
Web站点是MySQL最大的客户群,也是MySQL发展史上最为重要的支撑力量。MySQL之所以能成为Web站点开发者们最青睐的数据库管理系统,是因为MySQL数据库的安装配置都非常简单,其使用过程中的维护也不是像很多大型商业数据库管理系统那么复杂,而且性能出色。还有一个非常重要的原因,就是MySQL是开放源代码的,完全可以免费使用。
(2) 日志记录系统
MySQL数据库的插入和查询都非常高效,如果设计得较好,在使用MyISAM存储引擎的时候,两者可以做到互不锁定,具有很高的并发性能。所以,对需要大量插入和查询日志记录的系统,比如处理用户的登录日志、操作日志等,都是非常适合的应用系统。
(3) 数据仓库系统
随着存储数据量的飞速增长,需要的存储空间也越来越大。数据量的不断增长,使数据的统计分析变得越来越低效,也越来越困难。对此有几种解决思路,一种是采用昂贵的高性能主机以提高计算性能,用高端存储设备提高I/O性能,这样做效果理想,但是成本非常高;第二种就是将数据复制到多台使用大容量硬盘的廉价PC Server上,以提高整体计算性能和I/O能力,这样实施效果尚可,存储空间虽有一定限制,但成本低廉;第三种,通过将数据水平拆分,使用多台廉价的PC Server和本地磁盘来存放数据,每台机器上面都只有所有数据的一部分,这样便解决了数据量的问题,所有PC Server一起并行计算,也解决了计算能力问题,通过中间代理程序调配各台机器的运算任务,即可以解决计算性能问题又可以解决I/O性能问题,成本也很低廉。在上面的三种方案中,第二种和第三种方案对MySQL有较大的优势,同时为云计算的实现提供了现实基础。通过MySQL的简单复制功能,可以很好地将数据从一台主机复制到另外一台,不仅仅在局域网内,在广域网同样可以复制。当然,其他的数据库同样也可以做到这点,不是只有MySQL有这样的功能,但是MySQL是免费的,其他数据库大多是按照主机数量或PC数量来收费的,当使用大量PC Server的时候,license费用相当惊人。第一种方案,基本上所有数据库系统都能够实现,但是其高昂的成本并不是每一家公司都能够承担的。目前基于比较成熟的数据仓库解决方案主要是MySQL与Infobright相结合的DW系统。
(4) 嵌入式系统
嵌入式环境对软件系统最大的限制是硬件资源非常有限,在嵌入式环境下运行的软件系统,必须是轻量级低消耗的软件。
MySQL在资源的使用方面伸缩性非常大,它可以在资源非常充裕的环境下运行。对于嵌入式环境来说,它是一种非常合适的数据库系统,而且MySQL有专门针对嵌入式环境的版本。
(5) 网络游戏领域
近些年来,随着网络游戏的技术发展,大部分的网络游戏后台数据库都采用MySQL数据库,如大家比较熟悉的劲舞团、魔兽世界、Second Life等。MySQL在网络游戏数据库中将扮演越来越重要的角色。
2. MySQL的体系结构
如果把数据运行的基础环境比成骨骼和框架,那么数据就是这骨骼上的血肉,体系就是这血肉上的神经网络,于是结构就成了灵魂,所以数据库的体系结构对数据库的整体表现能力有着举足轻重的作用。MySQL的体系结构也是如此,它对MySQL的发展演化有着重要影响,其体系结构如下图所示。

图 2 MySQL的体系结构
MySQL的体系结构由连接器、连接池、系统管理和控制工具、SQL接口、解析器、优化器、缓存及缓冲区、插件式存储引擎以及物理文件构成。其中连接器用于与不同语言中进行SQL交互;连接池用于管理缓冲用户连接,线程处理等需要缓存的需求;SQL接口用于接受用户的命令,并且返回用户需要查询的结果,比如Select from就是调用SQL接口;SQL命令传递到解析器的时候会被解析器验证和解析,将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就基于这个结构;优化器用于优化SQL语句的查询,通过“投影-选取-连接”策略进行查询;缓存及缓冲区用于提高查询读取速度,当缓存中的查询结果时,查询可以直接去缓存中读取数据,这个缓存机制由一系列小的缓存组成,比如表缓存、记录缓存、key缓存以及权限缓存等。存储引擎是MySQL中具体与文件打交道的子系统,MySQL的存储引擎是插件式的,它根据MySQL AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制,这种访问机制就叫存储引擎。
第二章 关于MySQL派生分支
一、 何谓派生分支
MySQL是历史上最受欢迎的免费开源程序之一,因为 MySQL 本身是开源的,于是就有很多人在MySQL代码的基础上进行改进从而发布一个新的数据库,这便是MySQL的派生分支。这些数据库基本上都是跟 MySQL 兼容的,包括数据存储、通讯协议、管理以及 SQL 支持等。同时还有一类数据库,它们也是基于MySQL代码改进来的,但它们并不完全兼容于MySQL,这一类派生分支我们暂且叫做衍生产品。
二、 产生原因分析
MySQL是成千上万系统的数据库骨干,并且可以将它和Linux一起作为过去10多年里Internet呈指数级增长的一个有力证明。那么MySQL这么重要,为什么还会出现其他越来越多的高端衍生产品呢?这需要从开发者的现实需求和MySQL发展的实际需要两方面来分析。
1.开发者的现实需求
从开发者的现实需求角度来看,MySQL是免费的开源应用程序,所以开发人员总是可以获得其代码,并按照自己的想法修改代码,然后再自行分发代码。一些人认为MySQL变得太臃肿了,提供了许多用户永远不会感兴趣的功能,牺牲了性能的简单性。他们认为如果人们对更精简的MySQL4特别满意,那么为什么还要在MySQL 5中添加额外的复杂性呢?对于这部分人群来说,更好的MySQL分支应该更简单、更快捷,因此提供的功能也应更少,这样会使这些功能极其迅速地发挥作用,并且牢记目标受众。
对于另外一些开发者来说,他们认为MySQL并没有提供足够多的新功能,或者是添加新功能的速度太慢。他们认为MySQL没有跟上高可用性的发展形势,这些目标系统运行于具有大量内存的多核处理器之上。这部分人认为MyISAM和InnoDB这两种存储引擎都没有提供他们所需的内容,于是他们创建了一种非常适合他们目标的新存储引擎。
此外,一些人希望MySQL分支的最高目标是成为MySQL的替代产品,在这些产品中,可以轻松地访问它们的分支,无需更改任何代码。他们建议分支使用与MySQL相同的代码和界面,这会使过渡非常容易。而另外一些分支声称它与MySQL不兼容,需要更改代码。每个分支的成熟度各不相同,一些分支声称已经准备就绪可以投入生产,而另外一些则声称目前自己还远达不到这一最高目标。
于是基于不同开发者的现实需求,MySQL的派生分支和衍生产品诞生了。
2.产品发展实际需要
在MySQL被Oracle收购之后,MySQL在Oracle下将如何发展仍不太确定。Oracle收购了Sun,也收购了MySQL,现在Oracle控制MySQL产品本身,并领导开发社区开发新的成品。由于Oracle已经有了一个商业数据库,因此人们担心他们可能没有足够的资源来使MySQL保持其领先地位。因此,许多分支也是这些潜在担心所产生的结果,他们担心MySQL作为领先的免费开源数据库提供的功能可能太少、发布周期太慢并且支持费用更昂贵。
于是MySQL的产品发展实际需要就构成了MySQL派生分支出现的另一要素。
三、 总体情况概述
了解MySQL存储引擎是了解MySQL派生分支及产品衍生体系的关键,因为MySQL的派生分支及衍生产品,需要在MySQL存储引擎的基础上反复修改与调整,经过不断演化和修正才会得来。MySQL存储引擎与派生分支及产品衍生体系的关系,如下图所示。

图 3 MySQL存储引擎与派生分支及产品衍生体系的关系
MySQL派生分支及衍生产品需要以MySQL存储引擎为共同基础进行功能扩展。MySQL存储引擎主要包括MyISAM、InnoDB、NDB、Archive、Federated、Memory、Merge、BDB、XtraDB、MySQL Maria、TokuDB、CascaDB、Spider for MySQL、Mroonga、OQGraph等。MySQL派生分支主要包括MariaDB、Drizzle、InnoSQL、WebScaleSQL等。MySQL衍生产品则主要包括Percona Server、MepSQL、OurDelta等。
四、 派生体系介绍
1.MySQL存储引擎介绍
存储引擎是MySQL中具体与文件打交道的子系统,MySQL的存储引擎是插件式的。目前有多种MySQL存储引擎,主要包括MyISAM、InnoDB、NDB Cluster、Archive、Federated、Memory、Merge、BDB、XtraDB等,如下图所示。
 图 4 插件式存储引擎
图 4 插件式存储引擎
(1) MyISAM存储引擎介绍
MyISAM是MySQL最早的ISAM存储引擎的升级版本,也是MySQL默认的存储引擎。MyISAM存储引擎的每一个表都被存放为三个以表名命名的物理文件,其中.frm文件用于存放表结构定义信息,.MYD文件用于存放表的数据,.MYI用于存放索引数据。MyISAM支持B-Tree索引、R-Tree索引和Full-text索引三种索引,其中B-Tree中参与一个索引的所有字段的长度之和不能超过1000字节。MyISAM的数据存放格式分为静态(FIXED)固定长度、动态(DYNAMIC)可变长度以及压缩(COMPRESSED)三种格式。当主机崩溃、磁盘硬件故障、MyISAM存储引擎中出现Bug时,可能会出现MySQL中的表文件损坏;另外,当MySQL正在做写操作的时候被中止(kill)或其他情况造成异常终止时,也会出现表文件损坏情况。当某个表文件出错时,仅会影响到该表,不会影响到其他表,更不会影响到数据库。
(2) InnoDB存储引擎介绍
InnoDB作为第三方公司所开发的存储引擎,和MySQL遵守相同的开源许可证协议。实际上InnoDB并不是MySQL公司的,而是InnoBase软件公司(在2005年被Oracle公司所收购)开发的,其最大特点是提供了事务控制等特性。
InnoDB在功能方面支持事务安全,同时提供多版本读取,对锁定机制进行了改进,并实现了外键,以上功能亮点使InnoDB为MySQL获取了极大的用户支持。在支持事务安全方面,它实现了SQL92标准所定义的所有4个级别的要求(Read uncommitted , Read committed , Repeatable和Serializable);在提供多版本读取方面,为了保证数据的一致性及并发的性能,通过UNDO信息实现了数据的多版本读取;在锁定机制的改进方面,InnoDB改变了MyISAM的锁机制,实现了行锁,为InnoDB在承受高并发压力的环境下增强了不小的竞争力;在实现外键方面,通过外键引用使数据库端控制部分数据成为可能。
InnoDB的物理结构分为数据文件和日志文件两部分。在数据文件中,表数据和索引数据存放在一起,至于是每表单独使用独享表空间存放还是所有表一起使用表空间,完全由用户决定。InnoDB的日志文件和Oracle的REDO日志类似,采用轮循策略写入,如果数据库中使用了InnoDB的表,不能删除InnoDB的日志文件,否则很可能会引起数据库崩溃,且无法重新启动。
由于InnoDB是事务安全的存储引擎,所以系统崩溃对它来说并不能造成非常严重的损失,由于REDO日志的存在,且有checkpoint机制的保护,InnoDB完全可以通过REDO日志将数据库崩溃时已经完成但还没有来得及将内存中已经修改的但未完全写入磁盘的数据进行重做操作写入数据文件,也能够将所有已部分完成并写入磁盘的未完成事务进行回滚操作(UNDO),保证数据的一致性。
(3) NDB Cluster存储引擎介绍
NDB存储引擎也叫NDB Cluster存储引擎,主要用于MySQL Cluster分布式集群环境。MySQL Cluster是在无共享存储设备的情况下实现的一种内存数据库Cluster环境,主要通过NDB存储引擎来实现。MySQL Cluster的体系结构如下图所示。

图 5 MySQL Cluster的体系结构
上图中,处于存储层的NDB节点主要实现底层数据的存储功能,保存Cluster的数据。每一个NDB节点保存完整数据的一部分(或者一份完整的数据,视节点数目和配置而定),在MySQL Cluster里面叫做fragment。而每一个fragment正常情况都会在其他的主机上面有一份(或多份)完全相同的镜像存在,只要配置得当,存储层就不会出现单点的问题。一般来说,NDB节点被组织成一个一个的NDB Group,一个NDB Group实际上就是一组存有完全相同的物理数据的NDB节点群。
(4) Merge存储引擎介绍
Merge引擎是对结构相同的MyISAM表通过一些特殊的包装对外提供一个单一的访问入口,从而达到减小应用复杂度的目的。要创建Merge表,不仅基表的结构要完全一致,包括字段的顺序、基表的索引也必须完全一致。Merge表本身并不存储数据,仅仅是为多个基表提供一个统一的存储入口。
(5) Memory存储引擎介绍
Memory存储引擎是一个将数据存储在内存中的存储引擎。Memory存储引擎不会将任何数据存放到磁盘上,在磁盘上仅仅存放了一个表结构相关信息的.frm文件。所以一但MySQL崩溃或主机崩溃后,Memory的表就只剩下一个结构了。Memory表支持索引,并且同时支持Hash和B-Tree两种格式的索引。由于是存放在内存中,所以Memory都是按照定长的空间来存储数据,而且不支持BLOB和TEXT类型的字段。Memory存储引擎实现页级锁定。
(6) BDB存储引擎介绍
BDB存储引擎全称为BerkeleyDB存储引擎,和InnoDB一样,它也不是MySQL自己开发实现的,而是由Sleepycat Software提供的,当然,也是开源存储引擎,同样支持事务安全。BDB存储引擎的数据存放也是每个表两个物理文件,一个.frm和一个.db的文件,数据和索引信息都是存放在.db文件中。此外,BDB为了实现事务安全,也有自己的REDO日志,和InnoDB一样,它可以通过参数指定日志文件存放的位置。在锁定机制方面,BDB则和Memory存储引擎一样,实现页级锁定。
(7) Federated存储引擎介绍
Federated存储引擎所实现的功能和Oracle的DBLINK基本相似,主要用来提供对远程MySQL服务器上面的数据的访问接口。
(8) Archive存储引擎介绍
Archive存储引擎主要用于通过较小的存储空间来存放过期的很少访问的历史数据。Archive表不支持索引,包含一个.frm的结构定义文件,一个.ARZ的数据压缩文件,还有一个.ARM的元数据信息文件。由于其所存放的数据的特殊性,Archive表不支持删除、修改操作,仅支持插入和查询操作。锁定机制为行级机制。
(9) XtraDB存储引擎介绍
XtraDB是由Percona公司对InnoDB存储引擎进行改进加强后的产品,是一个MySQL的存储引擎,其设计的主要目的是替代现在的 InnoDB 。XtraDB兼容InnoDB的所有特性,并且在IO性能,锁性能,内存管理等多个方面进行了增强。经测试,XtraDB与内置的MySQL 5.1 InnoDB 引擎相比,它每分钟可处理2.7倍的事务。速度是一个不可以忽略的因素,在考虑替代产品时更是如此。
(10) MySQL Maria存储引擎介绍
Maria是一个MySQL的存储引擎,利用它来扩展MyISAM,使之在异常退出时文件不至于损坏。当前Maria是以一个独立的基于MySQL 5.1的版本出现,以后MySQL将会把Maria集成到MySQL的服务器中。
(11) TokuDB存储引擎介绍
TokuDB 是一个高性能、支持事务处理的 MySQL 和 MariaDB 的存储引擎。TokuDB 的主要特点是对高写压力的支持。
(12) CascaDB存储引擎介绍
CascaDB 是另外一个写优化的存储引擎,使用带缓冲的B-tree 算法优化,灵感来自于 TokuDB。在单线程4G缓存的条件下进行随机写性能评测,效果图如下:

图 6 单线程4G缓存的条件下随机写性能评测
数据来源:互联网资料整理,2014.9.13
在单线程32G缓存的条件下进行随机写性能评测,效果图如下:

图 7 单线程32G缓存的条件下随机写性能评测
数据来源:互联网资料整理,2014.9.13
读热点数据测评效果如下图所示:

图 8 读热点数据测评效果
数据来源:互联网资料整理,2014.9.13
随机读数据测评效果如下图所示:

图 9 随机读数据测评效果
数据来源:互联网资料整理,2014.9.13
(13) MySQL的存储引擎特征比较
几个常见的MySQL存储引擎特征比较,如下表所示。
表 1 常见的MySQL存储引擎特征比较
| 特征 | MyISAM | BDB | Memory | InnoDB | Archive | NDB |
| 存储限制 | No | No | Yes | 64TB | No | Yes |
| 事务处理(提交、回滚等) | √ | √ | ||||
| 锁机制 | 表级 | 页级 | 表级 | 行级 | 行级 | 行级 |
| 多版本并发控制/快照读 | √ | √ | √ | |||
| 地理空间数据支持 | √ | |||||
| B树索引 | √ | √ | √ | √ | √ | |
| 哈希索引 | √ | √ | √ | |||
| 全文检索索引 | √ | |||||
| 集群索引 | √ | |||||
| 数据缓存 | √ | √ | √ | |||
| 索引缓存 | √ | √ | √ | √ | ||
| 压缩数据 | √ | √ | ||||
| 加密数据(通过函数) | √ | √ | √ | √ | √ | √ |
| 存储消耗(空间使用) | 低 | 低 | N/A | 高 | 非常低 | 低 |
| 内存消耗 | 低 | 低 | 中 | 高 | 低 | 高 |
| 大规模插入速度 | 高 | 高 | 高 | 低 | 非常高 | 高 |
| 集群数据库支持 | √ | |||||
| 复制支持 | √ | √ | √ | √ | √ | √ |
| 外键支持 | √ | |||||
| 备份/某一时间点的恢复 | √ | √ | √ | √ | √ | √ |
| 查询缓冲支持 | √ | √ | √ | √ | √ | √ |
| 修改数据字典统计 | √ | √ | √ | √ | √ | √ |
2.MySQL派生分支介绍
(1) MariaDB介绍
MariaDB数据库管理系统是MySQL的一个分支,由MySQL的创始人Michael Widenius主导开发,主要由开源社区在维护,采用GPL授权许可。开发这个分支的原因之一是甲骨文公司收购了MySQL后,有将MySQL闭源的潜在风险,因此社区采用分支的方式来避开这个风险。
MariaDB的目的是完全兼容MySQL,使之能轻松成为MySQL的代替品。MariaDB虽然被视为替代品,但它在扩展功能、存储引擎以及一些新的功能改进方面都强过MySQL,而且从MySQL迁移到MariaDB也非常简单,具体表现在数据和表定义文件(.frm)是二进制兼容的,同时所有客户端API、协议和结构完全一致,所有文件名、二进制、路径、端口等都一致,所有的MySQL连接器比如PHP、Perl、Python、Java、.NET、MyODBC、Ruby以及MySQL C connector等在MariaDB中都保持不变,mysql-client包在MariaDB服务器中也能够正常运行,共享的客户端库与MySQL是二进制兼容的,也就是说,在大多数情况下,完全可以卸载MySQL然后安装MariaDB,之后就可以像之前一样正常运行。
在存储引擎方面,使用XtraDB来代替MySQL的InnoDB。MariaDB直到5.5版本,均依照MySQL的版本,因此,使用MariaDB5.5的人会从MySQL 5.5中了解到MariaDB的所有功能。
与 MySQL 相比较,MariaDB 更强的地方在于它综合集成了Maria存储引擎、PBXT 存储引擎、XtraDB 存储引擎以及FederatedX 存储引擎,同时具备更快的复制查询处理能力,具备线程池,能够发出更少的警告和Bug,运行速度更快,具有更多的扩展能力,可提供更好的功能测试,支持对 Unicode 的排序。
相对于MySQL的最新版本来说,在性能、功能、管理、NoSQL扩展方面,MariaDB包含了更丰富的特性,比如微秒的支持、线程池、子查询优化、组提交、进度报告等,详细情况如下表所示:
表 2 MariaDB包含的更丰富特性
|
High Performance |
Developers |
DBAs |
NoSQL |
|
Thread pool 线程池 |
Microsecond precision & type 微秒支持 |
Segmented MyISAM keycache MyISAM缓存分段 |
HandleSocket 直接InnoDB/XtrDB访问 |
|
Group commit for the binary log binlog组提交 |
SphinxSE for full-text search SphinxSE全文索引支持 |
Authentication plugins – PAM, Active Directory 授权插件 |
Dynamic columns 动态列 |
|
Non-blocking client library 非阻塞库 |
Subqueries materialize 子查询优化 |
LIMIT ROWS EXAMINED LIMIT行检查限制 |
|
|
GIS functionality 地理信息系统支持 |
Progress reporting 进度报告 |
为了让MariaDB比MySQL提供更多更好的信息,极少情况下MariaDB会出现不兼容情况。如果使用MariaDB 5.1替代MySQL5.1,将看到如下列举的全部已知用户级不兼容情况:
表 3 使用MariaDB 5.1替代MySQL5.1的不兼容情况
| 1. 安装的包名称,用MariaDB代替MySQL |
| 2.时间控制可能不同,MariaDB在许多情况下比MySQL快 |
| 3.mysqld在MariaDB读取是my.cnf中[MariaDB ]的部分 |
| 4.如果它不是完全相同的MariaDB编译版本,不能使用仅提供二进制的存储引擎库给MariaDB使用 (这是因为服务器内部结构THD在MySQL和MariaDB之间不同。这也是与常见的MySQL版本不同的)。 |
| 5.CHECKSUM TABLE可能产生不同的结果,由于MariaDB并不忽视NULL的列,MySQL 5.1忽略(未来的MySQL版本应该计算checksums和MariaDB一样)。在MariaDB 开启mysqld –old选项,可以得到“旧式”的校验和。但是要注意,这个MyISAM存储引擎和Aria 存储引擎在MariaDB实际上在内部使用新的checksum,因此,如果使用的是—old , CHECKSUM命令将会更慢,因为它需要,一行一行的计算checksum。 |
| 6. 慢速查询日志有更多信息关于查询, 如果有一个脚本解析慢速查询日志这可能是一个问题 |
| 7. MariaDB默认情况下比MySQL需要更多的内存,因为我们有默认情况下启用Aria存储引擎处理内部临时表。如果需要MariaDB使用很少的内存(这是以牺牲性能为代价的),可以设置aria_pagecache_buffer_size的值为 1M(默认值为128M)。 |
MariaDB 5.2与MySQL 5.1的不兼容性同MariaDB 5.1和MySQL 5.1的一样,只是需要额外再补充一条:
“新增SQL_MODE的取值:IGNORE_BAD_TABLE_OPTIONS。如果未设置该值,使用一个表、字段或索引的属性(选项)不被支持的存储引擎将会导致错误。这个变化可能引起警告不正确的表定义出现在错误日志中,请利用mysql_upgrade修复这个警告。”
实际上,MariaDB 5.2是MariaDB 5.1和MySQL 5.1替代品。MariaDB 5.3与MySQL 5.1和MariaDB 5.2的不兼容性如下表所示:
表 4 使用MariaDB 5.3替代MySQL5.1的不兼容情况
| 1.一些错误信息涉及到错误转换的,MariaDB的差别在于消息中提供了更多的信息关于到底是哪里出了错。 |
| 2.MariaDB专用的错误编号已经从1900开始,为的是不与MySQL的错误冲突。 |
| 3.MariaDB在所有工作场景中可以基于微秒计时工作;而MySQL在某些情况下,如datetime和time,确实会丢失微秒部分。 |
| 4.旧的–maria启动选项被删除。应该使用–aria前缀代替。(MariaDB 5.2都支持这—maria-和- aria-) |
| 5.SHOW PROCESSLIST有一个额外的process列,显示一些命令的进度。可以启动mysqld用–old 标志禁用它。 |
| 6.INFORMATION_SCHEMA.PROCESSLIST对进度报告有三个新列: STAGE, MAX_STAGE和 PROGRESS |
| 7.以/*M! 或/*M!#####起头的长注释会得到执行。 |
| 8.如果使用max_user_connections = 0(也就是说任何数量的连接)启动mysqld,就不能在mysqld运行时修改全局变量。这是因为当mysqld以max_user_connections = 0启动时,它不分配计数结构(包括每个连接的互斥锁)。如果稍后改变变量,这将导致错误的计数器。如果希望在运行时能改变这个变量,请在启动时将它设置为一个较高的值。 |
| 9.可以设置max_user_connections(包括全局变量和GRANT选项两种场景)为-1来阻止用户连接到服务器。全局变量max_user_connections变量不影响拥有super特权的用户连接。 |
(2) InnoSQL介绍
InnoSQL是MySQL数据库的一个分支版本,其完全兼容于Oracle MySQL,添加的补丁、插件、存储引擎都是动态的。InnoSQL的目标是提供更好的MySQL数据库性能,以及将一些富有创意的想法用于数据库的生产环境。
目前InnoSQL支持的主要特性包括:
- InnoDB Flash Cache
- MySQL Profiler
- Virtual Sync Replication with group commit
- Share Memory for InnoDB。
InnoDB的Flash cache架构如下图所示。

图 10 Flash Cache架构
(3) Drizzle介绍
Drizzle是一个精简版的MySQL分支,在目前的MySQL代码基本之上,将存储过程、视图、触发器、查询缓存、PREPARE语句等没有必要的功能从代码中删掉,简化对数据类型和存储引擎的支持,并且进行大胆的重构,最终实现将MySQL代码大大简化的目的,理顺MySQL的架构,改善 MySQL的代码质量,提高系统的稳定性和性能。
该产品在设计时就考虑到了其目标市场,即具有大量内容的多核服务器、运行Linux的64位机器、云计算中使用的服务器、托管网站的服务器和每分钟接收数以万计点击率的服务器。这是一个相当具体的市场。Drizzle是完全开源的产品,公开接受开发人员的贡献。它不像MariaDB那样有支持其开发的公司,也不像Percona那样有大量外部开发人员为其提供贡献。
Drizzle有很好的成长空间并会提供一些新功能,但可能需要重写大部分MySQL代码,所以会给系统稳定性带来一定风险。
(4) WebScaleSQL介绍
WebScaleSQL是由FB、谷歌、LinkedIn和Twitter四家公司共同组织改编的MySQL开源通用分支。该项目包括了来自这四家公司的MySQL工程师团队的工作成果,由于它是开源的,因此其他感兴趣的个人和公司也能够基于自身的资源和规模进行定制。Facebook公布了到目前为止,其工程师为WebScaleSQL新分支所做的改动,包括建立面向内建测试系统的一个自动化框架,此框架可呈现每次改动(change)、运行(run)和发布(publish)的结果;建设一套完整的压力测试套件,以及一个自动化性能测试原型;对MySQL现有测试中发现的问题架构代码做出了一些改动,以避免可能导致的失败或错误;对WebScaleSQL的性能改进,包括缓冲池清洗以及对某些查询类型的优化,以及支持NUMA交错政策的支持等。
3.MySQL衍生产品介绍
(1) Percona Server介绍
Percona Server是Percona公司分支的一个MySQL数据库版本。该版本对高负载情况下的InnoDB存储引擎进行了一定的优化,为DBA提供一些非常有用的性能诊断工具,另外有更多的参数和命令可以用来控制服务器行为。Percona Server 只包含 MySQL 的服务器版,并没有提供相应对 MySQL的Connector 和 GUI 工具进行改进。Percona Server使用了一些google-mysql-tools, Proven Scaling, Open Query 对 MySQL 进行改造。
Percona团队的最终声明是“Percona Server是由Oracle发布的最接近官方MySQL Enterprise发行版的版本”,因此与其他更改了大量基本核心MySQL代码的分支有所区别。Percona Server的一个缺点是他们自己管理代码,不接受外部开发人员的贡献,以这种方式确保他们对产品中所包含功能的控制。2012年08月15日,Percona Server发布5.6 Alpha。2012年08月23日,Percona Server发布5.5.27-28.0。2013年04月11日,Percona Server for MySQL 5.5.30-30.2 发布。
虽然Percona Server是MySQL的一个衍生版本,但与MySQL相比,在性能、稳定性和可管理性上都进行了改进。Percona 表示它考虑的不仅仅是性能峰值问题,还包括性能的稳定性以及可预测性,Percona Server中带有自适应的检查点算法。
拿Percona Server与MySQL 5.5进行性能对比,对Percona 进行测试的是一台DELL的PowerEdge R900机器,使用Raid10 的磁盘阵列,大约50G的测试数据,配置参数如下:
- innodb_buffer_pool_size=24G
- innodb_log_file_size=2000M
- innodb_log_files_in_group=2
- innodb_flush_log_at_trx_commit=2
经过8小时后的测试结果如下图所示:

图 11 Percona 5.5.7 与 MySQL 5.5.8的对比效果图
数据来源:互联网资料整理,2014.9.13
从上图可以看出,Percona Server 在性能上的波动更小。
(2) MepSQL介绍
MepSQL 是一个 MySQL 的衍生版本。MepSQL初始基于 Facebook补丁的 MySQL 代码,增加了用户友好的安装包和文档。MepSQL 主要侧重于高性能和来自社区开发的新特性、工具和文档。只提供Linux版本。
(3) OurDelta介绍
OurDelta是MySQL的第三方服务商。他们根据自己的观点各自维护着自己的MySQL第三方发行版,包括修正BUG,溶入功能增强性补丁等等。
第三章 主流技术及趋势
一、 分布式数据库
1. 分布式数据库的优势
分布式数据库系统通常使用较小的计算机系统,每台计算机可单独放在一个地方,每台计算机中都可能有数据库管理系统的一份完整拷贝副本,或者部分拷贝副本,并具有自己局部的数据库,位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的逻辑上集中、物理上分布的大型数据库。
这种组织数据库的方法克服了物理中心数据库组织的弱点。首先,降低了数据传送代价,因为大多数的对数据库的访问操作都是针对局部数据库的,而不是对其他位置的数据库访问;其次,系统的可靠性提高了很多,因为当网络出现故障时,仍然允许对局部数据库进行操作,而且一个位置的故障不影响其他位置的处理,只有当访问出现故障位置的数据时,在某种程度上才会受到影响;第三,便于系统的扩充,增加一个新的局部数据库,或在某个位置扩充一台适当的小型计算机,都很容易实现。然而有些功能要付出更高的代价。例如,为了调配在几个位置上的活动,事务管理的性能比在中心数据库时花费更高,而且会抵消许多其他的优点。
2. 分布式数据库的切分及整合
分布式数据库的数据存储需要通过切分的方式来实现。简单来说,就是指通过某种特定的条件,将存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。数据的切分同时还可以提高系统的总体可用性,因为单台设备崩溃之后,只有总体数据的某部分不可用,而不是所有的数据。数据切分共有四种类型,分别是水平分片、垂直分片、导出分片以及混合分片。水平分片是按一定的条件把全局关系的所有元组划分成若干不相交的子集,每个子集为关系的一个片段。垂直分片是把一个全局关系的属性集分成若干子集,并在这些子集上作投影运算,每个投影称为垂直分片。导出分片又称为导出水平分片,即水平分片的条件不是本关系属性的条件,而是其他关系属性的条件。混合分片是以上三种方法的混合,可以先水平分片再垂直分片,或先垂直分片再水平分片,或其他形式,不同切分方式会导致结果不同。
分布式数据的读取需要通过整合来实现,在进行整合的时候,可以考虑两种思路:第一种思路是在每个应用程序模块中配置管理自己需要的一个或多个数据源,直接访问各个数据库,在模块内完成数据的整合;第二种思路是通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明。当系统不断变得庞大复杂的时候,对于这两种思路,人们更愿意倾向于第二种,虽然短期内需要付出的成本可能会相对更大一些,但是对整个系统的扩展性来说,是非常有帮助的。这种思路有几种解决方案可供借鉴:
(1) 自行开发中间代理层
在决定选择通过数据库的中间代理层解决数据源整合的架构方向之后,很多人会倾向于选择自行开发符合应用特定场景的代理层应用程序。通过自行开发中间代理层可以最大程度的应对自身应用的特性,最大化的定制很多个性化需求,在面对变化的时候也可以灵活的应对。但选择自行开发,享受个性化定制最大乐趣的同时,也需要投入更多的成本来进行前期研发以及后期的持续升级改进工作,而且本身的技术门槛也比简单的Web应用高许多。所以在决定选择自行开发之前,需要进行全面比较及评估。
(2) 利用MySQL Proxy实现数据切分及整合
MySQL Proxy是MySQL官方提供的一个数据库代理层产品,和MySQL Server一样,同样是一个基于GPL开源协议的开源产品。MySQL Proxy可用来监视、分析或者传输数据源之间的通讯信息,目前具备的功能主要有连接路由、Query分析、Query过滤和修改、负载均衡以及基本的HA机制等。实际上, MySQL Proxy 本身并不具有上述所有的这些功能,而是提供了实现上述功能的基础。要实现这些功能,还需要通过我们自行编写LUA脚本来实现。MySQL Proxy实际上是在客户端请求与MySQL Server之间建立了一个连接池。所有客户端请求都是发向MySQL Proxy,然后经由MySQL Proxy进行相应的分析,判断出是读操作还是写操作,然后分发至对应的MySQL Server上。对于多节点Slave集群,也可以起到负载均衡的效果。以下是MySQL Proxy的基本架构图:

图 12 MySQL Proxy基本架构图
(3) 利用Amoeba实现数据切分及整合
Amoeba是一个基于Java开发的、专注于解决分布式数据库数据源整合Proxy程序的开源框架,基于GPL3开源协议。目前, Amoeba已经具有Query路由、Query过滤、读写分离、负载均衡以及HA机制等相关内容。Amoeba主要解决以下几个问题:
- 数据切分后复杂数据源整合;
- 提供数据切分规则并降低数据切分规则给数据库带来的影响;
- 降低数据库与客户端的连接数;
- 读写分离路由;
可以看出,Amoeba所做的事情,正好就是通过数据切分来提升数据库的扩展性所需要的。Amoeba并不是一个代理层的Proxy 程序,而是一个开发数据库代理层Proxy程序的开发框架,目前基于Amoeba所开发的Proxy程序有Amoeba For MySQL和Amoeba For Aladin两个。
Amoeba For MySQL主要是专门针对MySQL数据库的解决方案,前端应用程序请求的协议以及后端连接的数据源数据库都必须是MySQL。对于客户端的任何应用程序来说,Amoeba For MySQL和一个MySQL数据库没有什么区别,任何使用MySQL协议的客户端请求,都可以被Amoeba For MySQL解析并进行相应的处理。Amoeba For MySQL的架构信息如下图所示:

图 13 Amoeba For MySQL的架构
Amoeba For Aladin 则是一个适用更为广泛,功能更为强大的Proxy程序。他可以同时连接不同数据库的数据源为前端应用程序提供服务,但是仅仅接受符合MySQL协议的客户端应用程序请求。也就是说,只要前端应用程序通过MySQL协议连接上来之后,Amoeba For Aladin会自动分析Query语句,根据Query语句中所请求的数据来自动识别出该Query的数据源是在什么类型数据库的哪一个物理主机上面。Amoeba For Aladin的架构信息如下图所示:

图 14 Amoeba For Aladin的架构
上两图看似完全一样,但细看之后,才会发现两者主要的区别仅在于通过MySQL Protocol Adapter处理之后,根据分析结果判断出数据源数据库,然后选择特定的JDBC驱动和相应协议连接后端数据库。其实通过上面两个架构图可以发现,Amoeba仅仅只是一个开发框架,除了选择已经提供的For MySQL 和For Aladin这两款产品之外,还可以基于自身的需求进行相应的二次开发,得到更适应我们自己应用特点的Proxy程序。对于使用MySQL数据库来说,不论是Amoeba For MySQL还是 Amoeba For Aladin都可以很好的使用。当然,考虑到任何一个系统越是复杂,其性能肯定就会有一定的损失,维护成本自然也会相对更高一些。所以,对于仅仅需要使用MySQL数据库的时候,还是建议使用Amoeba For MySQL。
Amoeba For MySQL的使用非常简单,所有的配置文件都是标准的XML文件,总共有四个配置文件。分别为:
- amoeba.xml:主配置文件,配置所有数据源以及 Amoeba 自身的参数设置;
- rule.xml:配置所有 Query 路由规则的信息;
- functionMap.xml:配置用于解析 Query 中的函数所对应的 Java 实现类;
- rullFunctionMap.xml:配置路由规则中需要使用到的特定函数的实现类;
(4) 利用HiveDB实现数据切分及整合
和前面的 MySQL Proxy以及Amoeba一样,HiveDB同样是一个基于Java针对MySQL数据库的提供数据切分及整合的开源框架,只是目前的HiveDB仅仅支持数据的水平切分,主要解决大数据量下数据库的扩展性及数据的高性能访问问题,同时支持数据的冗余及基本的HA机制。
HiveDB的实现机制与MySQL Proxy和Amoeba有一定的差异,他并不是借助 MySQL的Replication功能来实现数据的冗余,而是自行实现了数据冗余机制,其底层主要是基于 Hibernate Shards来实现的数据切分工作。在HiveDB中,通过用户自定义的各种 Partition Keys(其实就是制定数据切分规则),将数据分散到多个MySQL Server中。在访问的时候,在运行Query请求的时候,会自动分析过滤条件,并行从多个MySQL Server中读取数据,并合并结果集返回给客户端应用程序。
单纯从功能方面来讲,HiveDB可能并不如MySQL Proxy和Amoeba那样强大,但是其数据切分的思路与前面二者并无本质差异。此外,HiveDB并不仅仅只是一个开源爱好者所共享的内容,而是存在商业公司支持的开源项目。
(5) 其他实现数据切分及整合的方案
除了上面介绍的几个数据切分及整合的整体解决方案之外,还存在很多其他同样提供了数据切分与整合的解决方案。如基于 MySQL Proxy的基础上做了进一步扩展的HSCALE,通过Rails构建的Spock Proxy,以及基于Python 的Pyshards等等。不管选择使用哪一种解决方案,总体设计思路基本上都不应该会有任何变化,那就是通过数据的垂直和水平切分,增强数据库的整体服务能力,让应用系统的整体扩展能力尽可能的提升,扩展方式尽可能的便捷。
只要我们通过中间层Proxy应用程序较好的解决了数据切分和数据源整合问题,那么数据库的线性扩展能力将很容易做到像我们的应用程序一样方便,只需要通过添加廉价的PC Server 服务器,即可线性增加数据库集群的整体服务能力,让数据库不再轻易成为应用系统的性能瓶颈。
3. 分布式数据库架构设计原则
在进行分布式数据库架构设计时,有几点原则需要注意:1.要持续进行数据分片;2.要坚持硬件解决首选的原则;3.将数据库简化为存储;4.坚持关系型和非关系型结合;5.谨慎考虑多机房部署。
二、 关于NoSQL
在过去几年,关系型数据库一直是数据持久化的唯一选择,数据工作者考虑的也只是在这些传统数据库中做筛选,比如MySQL、SQL Server或者是Oracle。我们使用Python、Ruby、Java、.Net等语言编写应用程序,这些语言有一个共同的特性,就是面向对象。但是我们使用MySQL、PostgreSQL、Oracle以及SQL Server,这些数据库同样有一个共同的特性,就是它们都是关系型数据库。这就涉及到了匹配关系的问题,如下图所示。

图 15 关系不匹配示意
由于存储结构是面向对象的,但是数据库却是关系的,所以在每次存储或者查询数据时,我们都需要做转换。类似Hibernate、Entity Framework这样的ORM框架确实可以简化这个过程,但是在对查询有高性能需求时,这些ORM框架就捉襟见肘了。随着网络应用程序的规模日渐变大,我们需要储存更多的数据、服务更多的用户以及需求更多的计算能力。为了应对这种情形,我们需要不停的扩展。扩展分为两类:一种是纵向扩展,即购买更好的机器,更多的磁盘、更多的内存等等;另一种是横向扩展,即购买更多的机器组成集群。在巨大的规模下,纵向扩展发挥的作用并不是很大。首先单机器性能提升需要巨额的开销并且有着性能的上限,在Google和Facebook这种规模下,永远不可能使用一台机器支撑所有的负载。鉴于这种情况,我们需要新的数据库,因为关系数据库并不能很好的运行在集群上。于是就有了以Google、Facebook、Amazon这些试图处理更多传输所引领的NoSQL的出现。
当下已经存在很多的NoSQL数据库,比如MongoDB、Redis、Riak、HBase、Cassandra等等。每一个都拥有以下几个特性中的一个:比如不再使用SQL语言(如MongoDB、Cassandra就有自己的查询语言);比如通常是开源项目;比如为集群运行而生;比如它们都是弱结构化,不会严格的限制数据结构类型等。
NoSQL数据库可以大体上分为4个种类,分别是:键值数据库(Key-value)、面向文档数据库(Document-Oriented)、列存储数据库(Column-Family Databases)以及图数据库( Graph-Oriented Databases)。下面分别结合数据库产品的使用情况、数据库适用场景和不适用场景来分别予以说明:
1. 键值数据库
键值数据库就像在传统语言中使用的哈希表。可以通过key来添加、查询或者删除数据,鉴于使用主键访问,所以会获得不错的性能及扩展性。键值数据库的主要产品包括:Riak、Redis、Memcached、Amazon’s Dynamo以及Project Voldemort等。
键值数据库主要适用于储存用户信息的场景,比如会话、配置文件、参数、购物车等等。这些信息一般都和ID(键)挂钩,这种情景下键值数据库是个很好的选择。
键值数据库不适用于以下场景:
- 取代通过键查询,而是通过值来查询。Key-Value数据库中根本没有通过值查询的途径。
- 需要储存数据之间的关系。在Key-Value数据库中不能通过两个或以上的键来关联数据。
- 事务的支持。在Key-Value数据库中故障产生时不可以进行回滚。
键值数据库的使用情况如下表所示。
表 5 键值数据库使用情况
| 有谁在使用 | 数据库名称 |
| GitHub | Riak |
| BestBuy | Riak |
| Redis和Memcached | |
| StackOverFlow | Redis |
| Redis | |
| Youtube | Memcached |
| Wikipedia | Memcached |
2. 面向文档数据库
面向文档数据库会将数据以文档的形式储存。每个文档都是自包含的数据单元,是一系列数据项的集合。每个数据项都有一个名称与对应的值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。数据存储的最小单位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用XML、JSON或者JSONB等多种形式存储。面向文档数据库的产品主要有:MongoDB、CouchDB以及RavenDB。
面向文档数据库主要适用于日志和分析的场景。对于日志场景,在企业环境下,每个应用程序都有不同的日志信息。Document-Oriented数据库并没有固定的模式,所以我们可以使用它储存不同的信息。对于分析场景,鉴于它的弱模式结构,不改变模式下就可以储存不同的度量方法及添加新的度量。
面向文档数据库不适用于在不同的文档上添加事务。Document-Oriented数据库并不支持文档间的事务,如果对这方面有需求则不应该选用这种解决方案。
面向文档数据库的使用情况如下表所示。
表 6 面向文档数据库使用情况
| 有谁在使用 | 数据库名称 |
| SAP | MongoDB |
| Codecademy | MongoDB |
| Foursquare | MongoDB |
| NBC News | RavenDB |
3. 列存储数据库
列存储数据库将数据储存在列族(column family)中,一个列族存储经常被一起查询的相关数据。举个例子,如果我们有一个Person类,我们通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。列存储数据库的产品主要有Cassandra和HBase。
列存储数据库主要适用于日志和博客平台。对于日志,因为我们可以将数据储存在不同的列中,每个应用程序可以将信息写入自己的列族中。对于博客平台,我们储存每个信息到不同的列族中。举个例子,标签可以储存在一个列族,类别可以在一个列族,而文章则在另一个列族中。
键值数据库不适用于以下场景:
- 如果我们需要ACID事务。Vassandra就不支持事务。
- 原型设计。如果我们分析Cassandra的数据结构,我们就会发现结构是基于我们期望的数据查询方式而定。在模型设计之初,我们根本不可能去预测它的查询方式,而一旦查询方式改变,我们就必须重新设计列族。
列存储数据库的使用情况如下表所示。
表 7 列存储数据库使用情况
| 有谁在使用 | 数据库名称 |
| Ebay | Cassandra |
| Cassandra | |
| NASA | Cassandra |
| Cassandra 、 HBase | |
| HBase | |
| Yahoo! | HBase |
4. 图数据库
图数据库允许我们将数据以图的方式储存。实体会被作为顶点,而实体之间的关系则会被作为边。比如我们有三个实体,Steve Jobs、Apple和Next,则会有两个“Founded by”的边将Apple和Next连接到Steve Jobs。图数据库的典型产品有Neo4J、Infinite Graph以及OrientDB。
图数据库主要适用于一些关系性较强的数据中,此外在推荐引擎中也比较适用。如果我们将数据以图的形式表现,那么将会非常有益于推荐的制定。
对于适用范围很小很小的情况下,不适用图数据库,因为很少有操作涉及到整个图。
图数据库的使用情况如下表所示。
表 8 图数据库使用情况
| 有谁在使用 | 数据库名称 |
| Adobe | Neo4J |
| Cisco (Neo4J)、(Neo4J) | Neo4J |
| T-Mobile | Neo4J |
事实上,NoSQL不使用SQL是一个错误。不使用SQL不是因为它的性能不好,而是因为关系产品架构不适合某些类型的任务。但在没有这些类型的任务时,又很容易陷入认为SQL等同于关系技术的陷阱。关系架构的关键一点是将物理实例从逻辑实现中分离了出来,不过大多数包含关系存储和关系访问层的关系产品也是如此。
三、 关于NewSQL
NewSQL是对各种新的可扩展、高性能数据库的简称,这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。NewSQL数据库在SQL处理上所有改进,这些数据库从一开始就设计了SQL接口(而不是之后才添加的),而且在底层不需要关系存储引擎。
较为流行的一种NewSQL数据库为VoltDB,是Michael Stonebraker的作品。它是一种标准关系数据库,但是将所有关系发展累积超过四十年的不必要的小组件剔除,使其比传统版本更精简更有效,因此它比商业数据库执行效率更好,并且缩小了它的覆盖面,几乎所有的NewSQL数据库都是如此。
另一种NewSQL数据库是Xeround公司的,该公司是一个基于云服务的数据库公司,提供灵活的scaling和NoSQL roots。像所有其他NewSQL数据库一样,该公司的NewSQL数据库主要侧重于事务处理,除了它固有的能力,Xeround公司在数据库方向的另一个不同表现为,它看起来像MySQL,这使其很容易将现有的MySQL用户迁移到云端。
此外还有两个有意思的NewSQL数据库,分别是NuoDB(前身为NimbusDB)和JustOneDB。NuoDB在一个与BitTorrent类似的端到端环境中使用一种分布式对象架构(像许多NoSQL数据库一样)。当更新一条记录时,会将其改变追加到已经存在的数据上,而不是替代它,因此可以看到数据库中的所有历史数据。该架构涉及到事务节点和归档节点的使用,其中前者使用内存,后者使用键/值存储来保持数据。因多个归档节点可以保持没有请求备份的相同数据,也就不必要为高可用性来复制数据,以及不必要进行分块。这听起来很像标准的NoSQL数据库,但最大的不同是,NuoDB数据库被特别设计来支持SQL,且完全支持ACID(原子性-Atomicity、一致性-Consistency、独立性-Isolation、持久性-Durability)。而JustOneDB又是另外一回事,它也完全支持ACID(像Oracle NoSQL数据库)且被设计支持SQL。它的环境看上去像PostgreSQL,且运行在Heroku的云端。但是它使用完全不同的存储架构,其公司称之为隧道存储(tunnel storage)。它能支持查询处理以及OLTP,并且和NuoDB一样,JustOneDB总是追加数据且从不删除它们的源数据。但它与它的竞争对手的不同之处在于,它侧重于scalling up而不是scalling out,也就是说如何在一台服务器上scale而不是跨服务器的。该公司的观点认为,在理想情况下人们一般希望越晚scale越好,这也就是为什么公司会侧重于scalling up而不是scalling out。
四、 关于MemSQL
MemSQL是一款内存数据库,它通过将数据存在内存中,将SQL语句预编译为C++而获得极速的执行效率。MemSQL宣称这是世界上最快的分布式关系型数据库,兼容MySQL但快30倍,能实现每秒150万次事务。 MemSQL由前Facebook工程师Eric Frenkiel和微软SQL Server高级工程师Nikita Shamgunov(CTO)联合创办,MemSQL的高性能数据库还参照了Facebook的脚本,有着强烈的Facebook印记。
MemSQL具有无可比拟的效率,MemSQL执行效率比传统的基于磁盘的数据库要快30倍,它优于其他内存数据库,因为它将SQL语句预编译为C++。MemSQL具有强大的SQL执行能力,能支持全功能的关系型数据库,开发者不必修改现有程序即可获得NoSQL键/值存储系统的效率。它还可以进行横向和纵向扩展,MemSQL支持纵向扩展,CPU越好效率就越高,而且支持向多CPU扩展。此外,MemSQL还可与MySQL节点结合起来处理PB级的负载。MemSQL缺省支持数据持久性,支持数据从内存到磁盘/SSD的同步,保证数据的安全可靠。MemSQL简易安装,只需30秒即可完成安装并使用MemSQL,兼容MySQL,学习曲线平滑。
MemSQL面临着 众多竞争对手的挑战,他们都宣称比SQL表现更强劲,都有一个熟谙数据库技术的创始团队。MemSQL是一个比较有争议的关系型数据库,在与不同的数据比较时,需要在完全不同的配置文件中运行。数据缓冲的内存在MemSQL中本质上是解除绑定的,而InnoDB在MySQL5.5把它限制在了128MB,这是MySQL5.1默认设置的16倍。至于写入性能方面,MemSQL 能写出2G的快照日志,而InnoDB设置为10MB的事务日志,所以会更快地开始检查点。尽管如此,对于基准来说,稳定持久是最重要的。MemSQL宣称支持ACID,其中耐久性是最重要的一环。MySQL的InnoDB默认是很耐用的,如果事务返回为“同意”,就会在崩溃后刻到磁盘上。MemSQL默认也是很“耐久”的,它也会有一个事务日志,而这并不意味着跟磁盘有关。最后总结:MemSQL每秒持久事务比InnoDB慢500倍;MemSQL在做一些简单的读写查询时,比MySQL慢上千倍,也许是慢百万倍。
五、 数据库技术格局概览
数据库的选择简单而复杂,简单指的是对于大部分互联网公司MySQL加上缓存就够用了。复杂指的是快速增长而心存高远的组织机构对大数据的预期,导致技术人员在数据库技术上的选择颇为犹豫和为难。而技术变革期所带来的群雄逐鹿,竞相融合的境况,也加大了选择的难度。
下图是对现有数据库技术的一个分类,可将主体分为关系型数据库和非关系型数据库两大类,在这两大类的交叉中,又存在生产型数据库及分析型数据库。此外,还包括对NoSQL与NewSQL的分类,以及按图、文档和键值等的属性分类。

图 16 数据库技术格局图
图中MySQL/PostgreSQL是传统关系型数据库的代表;HBase是Big Tables技术的代表(行索引,列存储);Neo4j是图数据库代表,用来存储复杂、多维度的图结构数据;Redis是基于Key-Value的NoSQL代表,有Redis-to-go提供存储服务;MongoDB/CouchDB是基于Document的NoSQL代表,Couchbase是Document/Key-Value技术的融合;VoltDB是NewSQL的代表,具备数据一致性和良好的扩展性,性能宣称是MySQL的数十倍以上。
第四章 现实问题及建议
一、 数据处理需求
在现实世界中,信息系统往往以处理数据为主要核心任务,数据先被创建或获得,然后存储、维护和使用,最终被销毁。在其生命周期过程中,数据可能被提取、导入、导出、迁移、验证、编辑、更新、清洗、转型、转换、整合、隔离、汇总、引用、评审、报告、分析、挖掘、备份、恢复、归档和检索,然后最终被删除。在整个生命周期过程中,都会涉及对数据需求的处理,不同的应用场景有不同的解决方式。因此当我们面对一个数据处理需求时,首先应当理性回归到业务场景中去思考问题的解决办法。
例如对于涉及基于XBRL进行数据录入的业务场景,如何实现数据的有效录入问题,可以思考出解决此问题需要满足的两个数据处理条件:一个是数据如何在数据库中进行存储,一个是如何实现数据字段增减变化的录入过程。对于“数据如何在数据库中进行存储”的需求实现,可以考虑通过数据结构转换,先将XBRL文档本身的半结构化数据转化为对应的结构化数据,通过在数据库管理系统中进行物理模型构建,实现数据的最终存储和管理;对于“如何实现数据字段增减变化的录入过程”问题,要结合具体业务有针对性地进行分析,先看这样做是否有其必要性以及是否存在其他替代解决方案,如果目标是根据业务规划自动调整系统界面字段的数目,则可以考虑改善软件架构设计方法,以类似模型驱动架构(MDA)的方式通过建模实现目标系统的架构设计。对数据库而言,数据库本身只能解决数据的存储与管理问题,并不能解决业务逻辑的处理问题,业务逻辑的处理需要通过开发特定的应用程序才能得以解决。
对于涉及到大量手机数据分析的需求,单从数据库产品本身来看,MySQL及其派生分支都能有效支持高性能的查询需求。至于这个场景下的即席分析功能的实现,属于业务逻辑处理范畴,同样需要通过开发应用程序才能得以解决。
此外,数据容灾也是一个非常值得关注的话题,它涉及技术路线、架构方法以及产品等诸多因素。备份是否完整,能否满足要求,关键还是要看所设计的备份策略是否合理,以及备份操作是否确实按照所设计的备份策略进行了。针对不同的用途,所需要的备份类型是不一样的,备份策略也各有不同。从经验来看,对于较为核心的在线应用系统,必须有在线备用主机通过MySQL的复制进行相应的备份,复制线程可以一直开启,恢复线程可以每天恢复一次,尽量让备机的数据延后主机的时间在一定时间段之内,延后多长时间合适主要根据实际需求决定,一般来说延后一天是一个比较常规的做法;对于重要级别稍微低一些的应用,恢复时间要求不是太高的话,为了节约硬件成本,不必使用在线的备份主机来单独运行备用MySQL,可以通过一定的时间周期进行一次物理全备份,同时每小时(或者其他合适的时间段)都将产生的二进制日志进行备份,这样丢失数据会比较少,恢复所需要的时间由全备周期长短决定;对于恢复基本没有太多时间要求,但是不希望太多数据丢失的应用场景,则可以在一定时间周期内进行一次逻辑全备份,同时也备份相应的二进制日志,使用逻辑备份而不使用物理备份的原因是因为逻辑备份实现简单,可以完全在线联机完成,备份过程不会影响应用提供服务;对于一些搭建临时数据库的备份应用场景,仅仅须要通过一个逻辑全备份即可满足需求,都不须要用二进制日志来进行恢复,因为这样的需求对数据并没有太苛刻的要求。
二、 性能影响因素
影响性能的因素是多方位的,包括商业需求对性能的影响、系统架构及实现对性能的影响、Query语句对系统性能的影响、Schema设计对系统的性能影响以及硬件环境对系统性能的影响等。
商业需求对性能的影响主要体现在不合理的需求造成资源投入产出比过低,无用功能堆积使系统过度复杂,影响整体性能。系统架构及实现对性能的影响主要体现在数据库中存放的数据位置并不都合适,且没有合理利用应用层的Cache机制,数据层的数据并非都是最精简的,过度依赖数据库Query语句的功能造成数据库操作效率低下,重复执行相同的Query造成资源浪费。此外,Query语句、Schema设计和硬件环境都会对系统的性能有着严重的影响。
三、 问题解决建议
针对客观问题,建议先从业务方向入手,深入分析业务需求,理清业务规则,合理规划目标系统的数据架构和技术架构,在分解并细化问题的前提下给出合理的实施解决路径,综合运用合适的技术路线和架构方法,选择适当的产品有针对性地解决问题。
在使用MySQL及其派生分支时,需要根据MySQL已提供的功能来权衡它们的优缺点。对于大多数人来说,MySQL将仍然是满足数据库需求的首选,是一个非常适合大多数使用情况的数据库。但是对于追求比目前MySQL所能提供的更高的可用性、可扩展性和性能的人来说,派生分支和衍生产品中的任意一款产品都会是不错的选择,但需要在使用它们之前先解决掉不稳定性所带来的各种问题。
随着MySQL的不断成熟及开放式插件存储引擎架构的不断出现,相信在未来的数年中,MySQL数据库仍将继续飞速发展。
http://www.linuxidc.com/Linux/2011-08/40601.htm
MySQL架构设计相关的方式方法和软件介绍
前言
最近,我在学习了解MySQL数据库架构相关的内容,从网上搜索了大量的相关资料和文章,粗粗阅览了一遍,发现架构相关的东西深不可测,需要非常丰富的知识阅历和实践经验。
我的阅历和经验明显不够用,所以我把了解到的相关内容作了下分类整理,算作这次学习的一个大致总结吧!这篇文章的大部分内容都来自网络,由于我的水平有限,整理的也并不准确,其中可能有很多错误之处,希望大家能不吝指正!希望这篇文章能抛砖引玉,帮助我们了解数据库架构相关的一些内容。
1 数据切分方案
当数据库比较庞大,读写操作特别是写入操作过于频繁,很难由一台服务器支撑的时候,我们就要考虑进行数据库的切分。所谓数据库的切分,就是我们按照某些特定的条件,将一台数据库上的数据分散到多台数据库服务器上。因为使用多台服务器,所以当一台服务器宕机后,整个系统只有部分数据不可用,而不是全部不可用。因此,数据库切分不仅能够用多台服务器分担数据库的负载压力,还可以提高系统的总体可用性。
数据的切分有两种方式:垂直切分和水平切分。
1.1 垂直切分
垂直切分就是按照系统功能模块,将每个模块访问的数据表切分到不同的数据库中。
适用情况:垂直切分适用于架构设计较好,各个模块间的交互点比较统一而且比较少,耦合度较低的系统。
优点:数据库的切分简单明了,规则明确;系统模块清晰明确,容易整合;数据维护方便,定位容易。
缺点:无法在数据库内实现表关联,只能在程序中实现;对于访问量大且数据量超大的数据表仍然会存在性能问题;事物处理会变得更为复杂,跨服务器的分布式事务会增多;过度切分会导致系统过度复杂、无法扩展、维护困难。
1.2 水平切分
水平切分就是对数据量超大的数据表,按照其中数据的逻辑关系,根据某个字段的某种规则,将其中的数据切分到多个数据库上。
适用情况:水平切分适用于有超大数据量的表且有合适的字段和规则进行水平切分的数据库。数据库进行水平切分后的多个数据库不应该存在交互的情况。
优点:可以在数据库内实现表关联;不会存在超大数据量且超高负载的数据表;可以在数据库内实现事务处理,事务处理相对简单;在合理的切分规则下,扩展性较好。
缺点:切分规则一般比较复杂,很难找出一个适合整个数据库的切分规则;数据的维护难度增加,人工定位数据难度增加;系统模块的耦合度较高,数据迁移拆分难度增加。
在实际进行数据切分时,我们首先应该根据系统模块的设计,合理地进行垂直切分。当模块细分到一定程度后,如果继续进行细分,就会使系统架构过于复杂,整个系统面临失控的危险。这时,我们就要利用水平切分的优势,来避免继续进行垂直切分导致的系统复杂化、面临失控的问题。同时,因为数据已经进行了合理的垂直切分,所以水平切分规则相对简单,系统模块耦合度较高的问题也已得到解决。总之,数据切分应该遵循一个原则,那就是“先合理垂直切分,再适时水平切分;先模块化切分,后数据集切分”。
2 数据整合方案
数据在经过垂直和水平切分被存放在不同的数据库服务器上之后,系统面临的最大问题就是如何来让这些来自不同数据库服务器上的数据得到较好的整合。解决这个问题有两种方式,第一种:在系统的每个模块中配置管理该模块需要的一个或者几个数据库及其所在服务器的信息,数据在模块中进行整合;第二种:通过中间代理层来统一管理所有的数据源,数据库集群对系统应用透明。第一种方案在初期开发时所需成本较小,但是长期来看,系统的扩展性会受到较大的限制。第二种方案则刚好相反,短期内付出的成本相对较大,但有利于系统的扩展。第二种方案可以通过一些第三方软件实现。
2.1 MySQLProxy
MySQLProxy可用来监视、分析、传输应用与数据库之间的通信。它可以实现连接路由,Query分析,Query过滤和修改,负载均衡,以及基本的HA机制等。
原理:MySQLProxy 实际上是在应用请求与数据库服务之间建立了一个连接池。所有应用请求都发向MySQLProxy,然后经由MySQLProxy 进行相应的分析,判断出是读操作还是写操作,分发至对应的MySQLServer 上。对于多节点Slave集群,也可以起到负载均衡的效果。
优点:MySQLProxy具有很大的灵活性,我们可以最大限度的使用它。
缺点:MySQLProxy实际上并不直接提供相关功能,这些功能都要依靠自行编写LUA脚本实现。
2.2 Amoeba
Amoeba是一个基于Java开发的Proxy程序开源框架,致力于解决分布式数据库的数据整合问题。它具有Query路由,Query过滤,读写分离,负载均衡功能以及HA机制等。Amoeba可以整合数据切分后的复杂数据源,降低数据切分给整个系统带来的影响,降低数据库与客户端的连接数,实现数据的读写分离。
原理:Amoeba相当于一个SQL请求的路由器,它集中地响应应用的请求,依据用户事先设置的规则,将SQL请求发送到特定的数据库服务器上执行。据此实现负载均衡、读写分离、高可用性等需求。
优点:基于XML的配置文件,用SQLJEP语法编写规则,配置比较简单
缺点:目前还不支持事务;对返回大数量的查询并不合适;不支持分库分表,只能做到分数据库实例。
2.3 HiveDB
HiveDB也是一个基于Java开发,针对MySQL数据库提供数据切分及整合的开源框架。但是,目前的HiveDB仅支持数据的水平切分。HiveDB主要解决大数据量下数据库的扩展性及数据的高性能访问问题,同时支持数据的冗余及基本的HA机制。
原理:HiveDB通过用户自定义的各种Partition keys将数据分散到多个数据库服务器上,访问时解析query请求,自动分析过滤条件,并行从多个数据库上读取数据后合并结果集返回给客户端应用程序。HiveDB的实现机制与Amoeba和MySQLProxy不同,它不用借助其他复制同步技术即可自行实现数据的冗余。其底层主要是基于Hibernate Shards 来实现的。Hibernate Shards是Google 技术团队在对 Google 财务系统数据 Sharding 过程中诞生的。Hibernate Shards是在框架层实现的,有其独特的特性:标准的 Hibernate 编程模型,会用 Hibernate 就能搞定,技术成本较低;相对弹性的 Sharding 策略以及支持虚拟 Shard 等。
优点:有商业公司支持,可自行实现数据冗余。
缺点:仅支持水平分区
在数据的整合过程中,还存在一些问题,比如:分布式事务的问题,跨节点JOIN的问题,跨节点排序分页的问题等。对于分布式事务的问题,我们需要将其拆分成多个单数据库内的小事务,由应用程序进行总控;跨节点JOIN的问题,我们需要先从一个节点中取出数据,然后由应用程序去其他节点进行JOIN或者使用Federated引擎;跨节点排序分页时,我们可以并行地从多个节点中读取数据,然后由应用程序进行排序分页。
3 数据冗余方案
任何设备或服务,只要是单点,就存在着很大的安全隐患。因为一旦这台设备或服务宕机之后,在短时间内就很难有备用设备或服务来顶替其功能。数据库作为系统的核心,必须存在一个备份以在出现异常时能够快速顶替原有服务,实现高可用性。同时,要实现数据库的读写分离,也必须采用复制技术保持多数据库节点的数据同步。实现数据同步的方式有很多,下面简要介绍常用的几个。
3.1 MySQL Replication
MySQL Replication是MySQL自带的一个异步复制的功能。复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器,也就是主从模式。
原理:MySQL使用3个线程来执行复制功能。当开始复制时,从服务器会创建一个I/O线程连接主服务器并要求主服务器发送记录在其上的二进制日志中的语句。主服务器会创建一个线程将二进制日志中的内容发送到从服务器。从服务器I/O线程读取主服务器线程发送的内容并将该数据复制到从服务器数据目录中的本地文件中,这个文件称为中继日志。第三个线程是SQL线程,是由从服务器创建的,用来读取中继日志并执行日志中包含的更新。常用的架构方式为:主-从、主-主、主-从级联、主-主-从级联等。
优点:部署简单、实施方便,是MySQL自动支持的功能,主备机切换方便,可以通过第三方软件或者自行编写简单的脚本即可自动完成主备切换。
缺点:实际使用时,只能单主机进行写入,不一定能满足性能要求;服务器主机硬件故障时,可能会造成部分尚未传输至从机的数据丢失。
3.2 MySQLCluster
MySQL Cluster 是MySQL适用于分布式计算环境的高可用、高冗余版本,采用了NDB Cluster 存储引擎(“NDB”是一种“内存中”的存储引擎,它具有可用性高和数据一致性好的特点),允许在1个 Cluster 中运行多个MySQL服务器。
原理:MySQL Cluster将标准的MySQL服务器与NDB Cluster存储引擎集成了起来。MySQL Cluster由一组计算机构成,每台计算机上均运行着多种进程,包括MySQL服务器,NDB Cluster的数据节点,管理服务器,以及(可能)专门的数据访问程序。所有这些程序一起构成了MySQL Cluster。将数据保存到NDB Cluster存储引擎时,表(结构)被保存到了数据节点中,应用程序能够从所有其他MySQL服务器上直接访问这些表。 参见下图:

优点:可用性非常高,性能非常好;每一份数据至少在不同主机上面存在一份拷贝,且实时同步;通过无共享体系结构,系统能够使用廉价的硬件,而且对软硬件无特殊要求。
3.3 DRBD磁盘网络镜像方案
DRBD(Distributed Replicated Block Device),是由LINBIT 公司开发的,通过网络来实现块设备的数据镜像同步的一款开源Cluster软件,也被俗称为网络RAID1。
原理:DRBD介于文件系统与磁盘介质之间,通过捕获上层文件系统的所有IO操作,调用内核中的IO模块来读写底层的磁盘介质。当DRBD捕获到文件系统的写操作之后,会在进行本地的磁盘写操作的同时,以TCP/IP协议,通过本地主机的网络设备(NIC)将IO传递至远程主机的网络设备。当远程主机的DRBD监听到传递过来的IO信息之后,会立即将该数据写入到该DRBD所维护的磁盘设备。DRBD在处理远程数据写入的时候有三种复制模式,适用于不同的可靠性和性能要求情景。
优点:功能强大,数据在底层块设备级别跨物理主机镜像,可根据性能和可靠性要求配置不同级别的同步;IO操作保持顺序,可满足对数据一致性的苛刻要求。
缺点:非分布式文件系统环境无法支持镜像数据同时可见,性能和可靠性两者相互矛盾,无法适用于性能和可靠性要求都比较苛刻的环境,维护成本比较高。
3.4 RaiDB
RaiDB,其全称为RedundantArrays of Inexpensive Databases,也就是通过Raid理念来管理数据库的数据:通过将多个廉价的数据库实例组合到一个数据库阵列,提供比单台数据库更好的性能和容错性,同时隐藏分布式数据库的复杂性,提供给应用程序一个独立的数据库。
原理:在RaiDB中,控制器在数据库阵列的前面。应用程序发送请求到RaiDB控制器,控制器将请求分发给一组数据库。跟磁盘的Raid一样,RaiDB也有不同的级别或数据分发方案,如RaiDB-0、RaiDB-1、RaiDB-1-0、RaiDB-0-1等,用于提供不同的成本、性能、容错权衡。
优点:和磁盘的Raid一样,RaiDB也可以大幅提高数据的读写速度,并提供容错功能
缺点:只能支持将数据库中的表分割到不同的数据库实例上,数据表本身不能再进行分割了;不支持分布式的join;扩展性的提升取决于表的数目和各个表的负载情况。
http://www.2cto.com/database/201504/387166.html
- 实战体验几种MySQLCluster方案
 我要投稿
我要投稿-
1.背景
MySQL的cluster方案有很多官方和第三方的选择,选择多就是一种烦恼,因此,我们考虑MySQL数据库满足下三点需求,考察市面上可行的解决方案:
高可用性:主服务器故障后可自动切换到后备服务器可伸缩性:可方便通过脚本增加DB服务器负载均衡:支持手动把某公司的数据请求切换到另外的服务器,可配置哪些公司的数据服务访问哪个服务器需要选用一种方案满足以上需求。在MySQL官方网站上参考了几种解决方案的优缺点:

综合考虑,决定采用MySQL Fabric和MySQL Cluster方案,以及另外一种较成熟的集群方案Galera Cluster进行预研。
2.MySQLCluster
简介:
MySQL Cluster 是MySQL 官方集群部署方案,它的历史较久。支持通过自动分片支持读写扩展,通过实时备份冗余数据,是可用性最高的方案,声称可做到99.999%的可用性。
架构及实现原理:

MySQL cluster主要由三种类型的服务组成:
NDB Management Server:管理服务器主要用于管理cluster中的其他类型节点(Data Node和SQL Node),通过它可以配置Node信息,启动和停止Node。 SQL Node:在MySQL Cluster中,一个SQL Node就是一个使用NDB引擎的mysql server进程,用于供外部应用提供集群数据的访问入口。Data Node:用于存储集群数据;系统会尽量将数据放在内存中。

缺点及限制:
对需要进行分片的表需要修改引擎Innodb为NDB,不需要分片的可以不修改。NDB的事务隔离级别只支持Read Committed,即一个事务在提交前,查询不到在事务内所做的修改;而Innodb支持所有的事务隔离级别,默认使用Repeatable Read,不存在这个问题。外键支持:虽然最新的Cluster版本已经支持外键,但性能有问题(因为外键所关联的记录可能在别的分片节点中),所以建议去掉所有外键。Data Node节点数据会被尽量放在内存中,对内存要求大。数据库系统提供了四种事务隔离级别:
A.Serializable(串行化):一个事务在执行过程中完全看不到其他事务对数据库所做的更新(事务执行的时候不允许别的事务并发执行。事务串行化执行,事务只能一个接着一个地执行,而不能并发执行。)。
B.Repeatable Read(可重复读):一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,但是不能看到其他其他事务对已有记录的更新。
C.Read Commited(读已提交数据):一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,而且能看到其他事务已经提交的对已有记录的更新。
D.Read Uncommitted(读未提交数据):一个事务在执行过程中可以看到其他事务没有提交的新插入的记录,而且能看到其他事务没有提交的对已有记录的更新。3.MySQL Fabric
简介:
为了实现和方便管理MySQL 分片以及实现高可用部署,Oracle在2014年5月推出了一套为各方寄予厚望的MySQL产品 -- MySQL Fabric, 用来管理MySQL 服务,提供扩展性和容易使用的系统,Fabric当前实现了两个特性:高可用和使用数据分片实现可扩展性和负载均衡,这两个特性能单独使用或结合使用。
MySQL Fabric 使用了一系列的python脚本实现。
应用案例:由于该方案在去年才推出,目前在网上暂时没搜索到有大公司的应用案例。
架构及实现原理:
Fabric支持实现高可用性的架构图如下:

Fabric使用HA组实现高可用性,其中一台是主服务器,其他是备份服务器, 备份服务器通过同步复制实现数据冗余。应用程序使用特定的驱动,连接到Fabric 的Connector组件,当主服务器发生故障后,Connector自动升级其中一个备份服务器为主服务器,应用程序无需修改。
Fabric支持可扩展性及负载均衡的架构如下:

使用多个HA 组实现分片,每个组之间分担不同的分片数据(组内的数据是冗余的,这个在高可用性中已经提到)
自增长键不能作为分片的键;事务及查询只支持在同一个分片内,事务中更新的数据不能跨分片,查询语句返回的数据也不能跨分片。
应用程序只需向connector发送query和insert等语句,Connector通过MasterGroup自动分配这些数据到各个组,或从各个组中组合符合条件的数据,返回给应用程序。
缺点及限制:
影响比较大的两个限制是:

测试高可用性
服务器架构:
功能
IP
Port
Backing store(保存各服务器配置信息)
200.200.168.24
3306
Fabric 管理进程(Connector)
200.200.168.24
32274
HA Group 1 -- Master
200.200.168.23
3306
HA Group 1 -- Slave
200.200.168.25
3306
安装过程省略,下面讲述如何设置高可用组、添加备份服务器等过程
首先,创建高可用组,例如组名group_id-1,命令:
mysqlfabric group create group_id-1
往组内group_id-1添加机器200.200.168.25和200.200.168.23:
mysqlfabric group add group_id-1 200.200.168.25:3306
mysqlfabric group add group_id-1 200.200.168.23:3306
然后查看组内机器状态:

由于未设置主服务器,两个服务的状态都是SECONDARY
提升其中一个为主服务器:
mysqlfabric group promote group_id-1 --slave_id 00f9831f-d602-11e3-b65e-0800271119cb
然后再查看状态:
设置成主服务器的服务已经变成Primary。
另外,mode属性表示该服务器是可读写(READ_WRITE),或只读(READ_ONLY),只读表示可以分摊查询数据的压力;只有主服务器能设置成可读写(READ_WRITE)。
这时检查25服务器的slave状态:
可以看到它的主服务器已经指向23
然后激活故障自动切换功能:
mysqlfabric group activate group_id-1
激活后即可测试服务的高可以性
首先,进行状态测试:
停止主服务器23
然后查看状态:

可以看到,这时将25自动提升为主服务器。
但如果将23恢复起来后,需要手动重新设置23为主服务器。
实时性测试:
目的:测试在主服务更新数据后,备份服务器多久才显示这些数据
测试案例:使用java代码建连接,往某张表插入100条记录,看备份服务器多久才能同步这100条数据
测试结果:
表中原来有101条数据,运行程序后,查看主服务器的数据条数:
可见主服务器当然立即得到更新。
查看备份服务器的数据条数:
但备份服务器等待了1-2分钟才同步完成(可以看到fabric使用的是异步复制,这是默认方式,性能较好,主服务器不用等待备份服务器返回,但同步速度较慢)
使用半同步加强数据一致性:异步复制能提供较好的性能,但主库只是把binlog日志发送给从库,动作就结束了,不会验证从库是否接收完毕,风险较高。半同步复制会在发送给从库后,等待从库发送确认信息后才返回。可以设置从库中同步日志的更新方式,从而减少从库同步的延迟,加快同步速度。 安装半同步复制:
对于从服务器同步数据稳定性问题,有以下解决方案:
在mysql中运行
install plugin rpl_semi_sync_master soname 'semisync_master.so';
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
SET GLOBAL rpl_semi_sync_master_enabled=ON;
SET GLOBAL rpl_semi_sync_slave_enabled=ON;
修改my.cnf :
rpl_semi_sync_master_enabled=1
rpl_semi_sync_slave_enabled=1
sync_relay_log=1
sync_relay_log_info=1
sync_master_info=1
稳定性测试:
测试案例:使用java代码建连接,往某张表插入1w条记录,插入过程中将其中的master服务器停了,看备份服务器是否有这1w笔记录
测试结果,停止主服务器后,java程序抛出异常:

但这时再次发送sql命令,可以成功返回。证明只是当时的事务失败了。连接切换到了备份服务器,仍然可用。
翻阅了mysql文档,有章节说明了这个问题:
里面提到:当主服务器当机时,我们的应用程序虽然是不需做任何修改的,但在主服务器被备份服务器替换前,某些事务会丢失,这些可以作为正常的mysql错误来处理。
数据完整性校验:
测试主服务器停止后,备份服务器是否能够同步所有数据。
重启了刚才停止主服务器后,查看记录数
可以看到在插入1059条记录后被停止了。
现在看看备份服务器的记录数是多少,看看在主服务器当机后是否所有数据都能同步过来

大约经过了几十秒,才同步完,数据虽然不是立即同步过来,但没有丢失。
1.2、分片:如何支持可扩展性和负载均衡
fabric分片简介:当一台机器或一个组承受不了服务压力后,可以添加服务器分摊读写压力,通过Fabirc的分片功能可以将某些表中数据分散存储到不同服务器。我们可以设定分配数据存储的规则,通过在表中设置分片key设置分配的规则。另外,有些表的数据可能并不需要分片存储,需要将整张表存储在同一个服务器中,可以将设置一个全局组(Global Group)用于存储这些数据,存储到全局组的数据会自动拷贝到其他所有的分片组中。

4.Galera Cluster
简介:
Galera Cluster号称是世界上最先进的开源数据库集群方案

主要优点及特性:
真正的多主服务模式:多个服务能同时被读写,不像Fabric那样某些服务只能作备份用同步复制:无延迟复制,不会产生数据丢失热备用:当某台服务器当机后,备用服务器会自动接管,不会产生任何当机时间自动扩展节点:新增服务器时,不需手工复制数据库到新的节点支持InnoDB引擎对应用程序透明:应用程序不需作修改
架构及实现原理:
首先,我们看看传统的基于mysql Replication(复制)的架构图:
Replication方式是通过启动复制线程从主服务器上拷贝更新日志,让后传送到备份服务器上执行,这种方式存在事务丢失及同步不及时的风险。Fabric以及传统的主从复制都是使用这种实现方式。
而Galera则采用以下架构保证事务在所有机器的一致性:
客户端通过Galera Load Balancer访问数据库,提交的每个事务都会通过wsrep API 在所有服务器中执行,要不所有服务器都执行成功,要不就所有都回滚,保证所有服务的数据一致性,而且所有服务器同步实时更新。
由于同一个事务需要在集群的多台机器上执行,因此网络传输及并发执行会导致性能上有一定的消耗。所有机器上都存储着相同的数据,全冗余。若一台机器既作为主服务器,又作为备份服务器,出现乐观锁导致rollback的概率会增大,编写程序时要小心。不支持的SQL:LOCK / UNLOCK TABLES / GET_LOCK(), RELEASE_LOCK()…不支持XA Transaction
缺点及限制:
目前基于Galera Cluster的实现方案有三种:Galera Cluster for MySQL、Percona XtraDB Cluster、MariaDB Galera Cluster。
我们采用较成熟、应用案例较多的Percona XtraDB Cluster。
应用案例:
超过2000多家外国企业使用:

包括:

集群部署架构:
功能
IP
Port
Backing store(保存各服务器配置信息)
200.200.168.24
3306
Fabric 管理进程(Connector)
200.200.168.24
32274
HA Master 1
200.200.168.24
3306
HA Master 2
200.200.168.25
3306
HA Master 3
200.200.168.23
3306
4.1、测试数据同步
在机器24上创建一个表:

立即在25 中查看,可见已被同步创建

使用Java代码在24服务器上插入100条记录

立即在25服务器上查看记录数

可见数据同步是立即生效的。
4.2、测试添加集群节点
添加一个集群节点的步骤很简单,只要在新加入的机器上部署好Percona XtraDB Cluster,然后启动,系统将自动将现存集群中的数据同步到新的机器上。
现在为了测试,先将其中一个节点服务停止:
然后使用java代码在集群上插入100W数据

查看100w数据的数据库大小:

这时启动另外一个节点,启动时即会自动同步集群的数据:

启动只需20秒左右,查看数据大小一致,查看表记录数,也已经同步过来

5.对比总结
MySQL Fabric
Galera Cluster
使用案例
2014年5月才推出,目前在网上暂时没搜索到有大公司的应用案例
方案较成熟,外国多家互联网公司使用
数据备份的实时性
由于使用异步复制,一般延时几十秒,但数据不会丢失。
实时同步,数据不会丢失
数据冗余
使用分片,通过设置分片key规则可以将同一张表的不同数据分散在多台机器中
每个节点全冗余,没有分片
高可用性
通过Fabric Connector实现主服务器当机后的自动切换,但由于备份延迟,切换后可能不能立即查询数据
使用HAProxy实现。由于实时同步,切换的可用性更高。
可伸缩性
添加节点后,需要先手工复制集群数据
扩展节点十分方便,启动节点时自动同步集群数据,100w数据(100M)只需20秒左右
负载均衡
通过HASharding实现
使用HAProxy实现负载均衡
程序修改
需要切换成jdbc:mysql:fabric的jdbc类和url
程序无需修改
性能对比
使用java直接用jdbc插入100条记录,大概2000+ms
跟直接操作mysql一样,直接用jdbc插入100条记录,大概600ms
6.实践应用
综合考虑上面方案的优缺点,我们比较偏向选择Galera 如果只有两台数据库服务器,考虑采用以下数据库架构实现高可用性、负载均衡和动态扩展:

如果三台机器可以考虑:

===================================================
http://www.zhihu.com/question/21307639
LVS+Keepalived+MySQL(有脑裂问题?但似乎很多人推荐这个)
DRBD+Heartbeat+MySQL(有一台机器空余?Heartbeat切换时间较长?有脑裂问题?)
MySQL Proxy(不够成熟与稳定?使用了Lua?是不是用了他做分表则可以不用更改客户端逻辑?)
MySQL Cluster (社区版不支持INNODB引擎?商用案例不足?)
MySQL + MHA (如果配上异步复制,似乎是不错的选择,又和问题?)
MySQL + MMM (似乎反映有很多问题,未实践过,谁能给个说法)
哪个(相对)好,或者还有其他方案?各有啥优劣,哪种真正大量的被商用,读写分离时如何保证读到刚写入的东东?
谢谢。修改
4 个回答

LVS+Keepalived+MySQL(有脑裂问题?但似乎很多人推荐这个)
DRBD+Heartbeat+MySQL(有一台机器空余?Heartbeat切换时间较长?有脑裂问题?)
MySQL Proxy(不够成熟与稳定?使用了Lua?是不是用了他做分表则可以不用更改客户端逻辑?)
MySQL Cluster (社区版不支持INNODB引擎?商用案例不足?)
MySQL + MHA (如果配上异步复制,似乎是不错的选择,又和问题?)
MySQL + MMM (似乎反映有很多问题,未实践过,谁能给个说法)
回答:
不管哪种方案都是有其场景限制 或说 规模限制,以及优缺点的。
1. 首先反对大家做读写分离,关于这方面的原因解释太多次数(增加技术复杂度、可能导致读到落后的数据等),只说一点:99.8%的业务场景没有必要做读写分离,只要做好数据库设计优化 和配置合适正确的主机即可。
2.Keepalived+MySQL --确实有脑裂的问题,还无法做到准确判断mysqld是否HANG的情况;
3.DRBD+Heartbeat+MySQL --同样有脑裂的问题,还无法做到准确判断mysqld是否HANG的情况,且DRDB是不需要的,增加反而会出问题;
3.MySQL Proxy -- 不错的项目,可惜官方半途夭折了,不建议用,无法高可用,是一个写分离;
4.MySQL Cluster -- 社区版本不支持NDB是错误的言论,商用案例确实不多,主要是跟其业务场景要求有关系、这几年发展有点乱不过现在已经上正规了、对网络要求高;
5.MySQL + MHA -- 可以解决脑裂的问题,需要的IP多,小集群是可以的,但是管理大的就麻烦,其次MySQL + MMM 的话且坑很多,有MHA就没必要采用MMM
建议:
1.若是双主复制的模式,不用做数据拆分,那么就可以选择MHA或 Keepalive 或 heartbeat
2.若是双主复制,还做了数据的拆分,则可以考虑采用Cobar;
3.若是双主复制+Slave,还做了数据的拆分,需要读写分类,可以考虑Amoeba;
上述所有的内容都要依据公司内部的业务场景、数据量、访问量、并发量、高可用的要求、DBA人群的数量等 综合权衡,若是需要可以联系我:jinguanding#hotpu.cn
 温国兵,Database enthusiast.
温国兵,Database enthusiast.
-------------------------------------------------------------------
恕本人才疏学浅,暂时不能回答此问题。DB菜鸟一枚,对MySQL没有多大深入的了解。
针对这个问题,在OSC(开源中国)、StackOverFlow、CSDN论坛上问或许更合适些。
 王珂,系统工程师、数据库工程师,致力于传媒新…
王珂,系统工程师、数据库工程师,致力于传媒新…

========================================================================
http://f.dataguru.cn/thread-270667-1-1.html
|
全方位解读mysql各种版本,mysql生产环境各种方案的应用,包括mysql集群负载均衡,mysql读写分离,mysql主从复制,mysql多主复制,mysql drbd,mysql mmm,mysql galera wsrep,mysql ndb,各种方案的应用场景 目前mysql开源版本最新版本是MySQL Community Server 5.6.14,mysql下载地址http://dev.mysql.com/downloads/mysql/ 对于mysql数据库5.6版本已经引入了no sql模块memcache,功能冒似非常的强大,可以无缝和NO SQL与长统的sql直接转化并存储,有兴趣的朋友可以参考下mysql数据库官方API说明。今天主要分享下工作常用的mysql方案。 1. 最基本的mysql主从复制master-slave,对应读多些少的应用,一主多从,应用层面配置多个数据库源做个半自动的读写分离,让从库分担读压力。 在新版的mysql5.6数据库引入了全新的gtids全局事务ID,给mysql用户带来了全新的主从复制体验。给我个人的感觉是mysql5.6这个技术是个革命性的变化,主要体现在 主要的增强改进是添加了Global Transaction Identifiers (GTIDs)功能,为了解决以下问题: -能够无缝的故障恢复和master与slave的切换 -能把slave指向新的master -减少手工干预和降低服务故障时间 你可以下载新的MySQL Replication High Availability Guide 了解更多,下列部分提供了GTIDS和mysql如何一起来配合来实现自动故障恢复的复制集群 简单的说就是主从维护成本降低了,主要配置好主从,指定同步的库,到数据导入主库,数据自动开始同步到从库,无需像早起的版本,还有在主库做快照,把快照导入到从库,在手工指定日志起点等。总之大家可以升级下体验下功能。 2. mysql ndb这个就不必说,为了高可用而设计,适合读多写少情况,如果并发写的比较多,建议不要使用哦。 当前mysql nbd 7.3.3版本 http://dev.mysql.com/downloads/cluster/ MySQL集群是一种在无共享架构系统里应用内存数据库集群的技术。这种无共享的架构可以使得系统使用非常便宜的并且是最小配置的硬件,MySQL集群是一种分布式设计,目标是要达到没有任何单点故障点,因此,任何组成部分都应该拥有自己的内存和磁盘,任何共享存储方案如网络共享,网络文件系统和SAN设备是不推荐或不支持的,通过这种冗余设计,MySQL 声称数据的可用度可以达到99.999%; NDB” 是一种“内存中”的存储引擎,它具有可用性高和数据一致性好的特点,MySQL Cluster 能够使用多种故障切换和负载平衡选项配置NDB存储引擎,但在 Cluster 级别上的存储引擎上做这个最简单,MySQL Cluster的NDB存储引擎包含完整的数据集,仅取决于 Cluster本身内的其他数据,目前,MySQL Cluster的 Cluster部分可独立于MySQL服务器进行配置;在MySQL Cluster中, Cluster的每个部分被视为1个节点; 使用mysql ndb 就是可以用廉价的硬件做一个负载均衡的mysql集群 3. msyql drbd drbd是一个基于软件形式实现的类是软raid1,使用mysql drbd只是实现了热备。并没有什么负载均衡,没有所谓的读写分离哦,这个很多人使用哦。我也有相应的文章和现成的脚本直接部署该应用 4. mysql mmm 实现了主主切换功能,多了一个监控,在成本上考虑,目前好像实际使用的人比较少,本人使用了该方案的集成。 5. mysql garela wsrep mysql多主并发型复制技术,多是主,没有从。这个本人测试过,通过存储过程在该集群(4台)同时插入一样10万条数据,效果还是很让人满意,没有出现任何错误已经数据一不一致现象。 涉及到的软件有 mysql,mysql wsrep补丁包(并行复制),garela集群管理软件。稍后本人会把详细的配置方案的文档放出,这个非常不错的方案。 6. mysql haproxy 方案 一主多从,对多个从利用haproxy进行负载均衡。使用到虚IP连接haproxy的负载均衡实体哦。 对应haproxy对mysql健康检查,需要利用xinet和手工编写一个haproxy监控页面方便haproxy检测健康状态。如果单纯从3306端口来判断,会导致haproxy判断mysql健康状况不准确而引发应用链接到故障的mysql节点导致不可用的情况哦。切记。稍后章节会放出相应的配置方案。尽情期待。 7.通过mysqlproxy和淘宝mysql的变形虫amoeba读写分离工具。不推荐,前者本身还是beta版本,后者是针对淘宝特有的应用编写,如果你使用的话,涉及到的sql有比较操作的话,需要对应用程序做相关的转移操作,参考淘宝变形虫读写分离工具amoeba的API。 好了,mysql数据库相应的各种方案就介绍到这里。各种方案都有优缺点。个人比较看好mysql garela wsrep。 当然看你具体应用了,一句话,够用就好。 |
,,,,,,,,,,,,,,,,,
http://blog.csdn.net/mchdba/article/category/1583151
https://dev.mysql.com/doc/refman/4.1/en/mysql-cluster-multi-computer.html
15.2 MySQL Cluster Multi-Computer How-To
[+/-]
This section is a “How-To” that describes the basics for how to plan, install, configure, and run a MySQL Cluster. Whereas the examples in Section 15.3, “MySQL Cluster Configuration” provide more in-depth information on a variety of clustering options and configuration, the result of following the guidelines and procedures outlined here should be a usable MySQL Cluster which meets the minimum requirements for availability and safeguarding of data.
This section covers hardware and software requirements; networking issues; installation of MySQL Cluster; configuration issues; starting, stopping, and restarting the cluster; loading of a sample database; and performing queries.
Basic assumptions. This How-To makes the following assumptions:
-
The cluster is to be set up with four nodes, each on a separate host, and each with a fixed network address on a typical Ethernet network as shown here:
Node IP Address Management (MGMD) node 192.168.0.10 MySQL server (SQL) node 192.168.0.20 Data (NDBD) node "A" 192.168.0.30 Data (NDBD) node "B" 192.168.0.40 This may be made clearer in the following diagram:
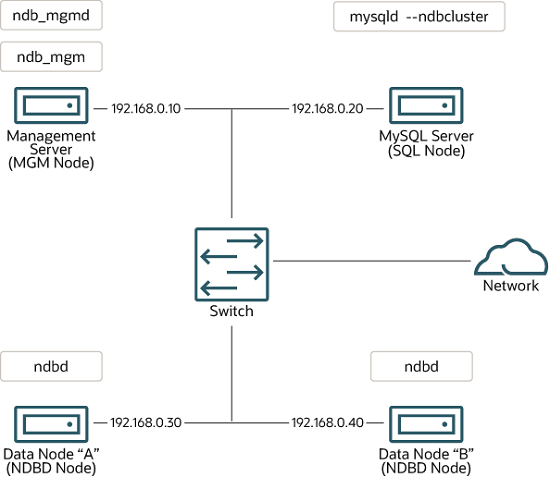
In the interest of simplicity (and reliability), this How-To uses only numeric IP addresses. However, if DNS resolution is available on your network, it is possible to use host names in lieu of IP addresses in configuring Cluster. Alternatively, you can use the
/etc/hostsfile or your operating system's equivalent for providing a means to do host lookup if such is available.NoteA common problem when trying to use host names for Cluster nodes arises because of the way in which some operating systems (including some Linux distributions) set up the system's own host name in the
/etc/hostsduring installation. Consider two machines with the host namesndb1andndb2, both in theclusternetwork domain. Red Hat Linux (including some derivatives such as CentOS and Fedora) places the following entries in these machines'/etc/hostsfiles:# ndb1
/etc/hosts: 127.0.0.1 ndb1.cluster ndb1 localhost.localdomain localhost# ndb2
/etc/hosts: 127.0.0.1 ndb2.cluster ndb2 localhost.localdomain localhostSUSE Linux (including OpenSUSE) places these entries in the machines'
/etc/hostsfiles:# ndb1
/etc/hosts: 127.0.0.1 localhost 127.0.0.2 ndb1.cluster ndb1# ndb2
/etc/hosts: 127.0.0.1 localhost 127.0.0.2 ndb2.cluster ndb2In both instances,
ndb1routesndb1.clusterto a loopback IP address, but gets a public IP address from DNS forndb2.cluster, whilendb2routesndb2.clusterto a loopback address and obtains a public address forndb1.cluster. The result is that each data node connects to the management server, but cannot tell when any other data nodes have connected, and so the data nodes appear to hang while starting.You should also be aware that you cannot mix
localhostand other host names or IP addresses inconfig.ini. For these reasons, the solution in such cases (other than to use IP addresses for allconfig.iniHostNameentries) is to remove the fully qualified host names from/etc/hostsand use these inconfig.inifor all cluster hosts. -
Each host in our scenario is an Intel-based desktop PC running a supported operating system installed to disk in a standard configuration, and running no unnecessary services. The core operating system with standard TCP/IP networking capabilities should be sufficient. Also for the sake of simplicity, we also assume that the file systems on all hosts are set up identically. In the event that they are not, you should adapt these instructions accordingly.
-
Standard 100 Mbps or 1 gigabit Ethernet cards are installed on each machine, along with the proper drivers for the cards, and that all four hosts are connected through a standard-issue Ethernet networking appliance such as a switch. (All machines should use network cards with the same throughout. That is, all four machines in the cluster should have 100 Mbps cards or all four machines should have 1 Gbps cards.) MySQL Cluster works in a 100 Mbps network; however, gigabit Ethernet provides better performance.
Note that MySQL Cluster is not intended for use in a network for which throughput is less than 100 Mbps or which experiences a high degree of latency. For this reason (among others), attempting to run a MySQL Cluster over a wide area network such as the Internet is not likely to be successful, and is not supported in production.
-
For our sample data, we use the
worlddatabase which is available for download from the MySQL Web site (seehttp://dev.mysql.com/doc/index-other.html). We assume that each machine has sufficient memory for running the operating system, host NDB process, and (on the data nodes) storing the database.
Although we refer to a Linux operating system in this How-To, the instructions and procedures that we provide here should be easily adaptable to other supported operating systems. We also assume that you already know how to perform a minimal installation and configuration of the operating system with networking capability, or that you are able to obtain assistance in this elsewhere if needed.
For information about MySQL Cluster hardware, software, and networking requirements, see Section 15.1.3, “MySQL Cluster Hardware, Software, and Networking Requirements”.
MySQL Cluster MySQL集群
Linux最新版本7.3.2
| 文件 | 大小 | md5 |
|---|---|---|
| mysqlcluster-7.3.2-linux-x32.tar.gz | 431.0MB | 03093541b6416fc93935750d614d875b |
| mysqlcluster-7.3.2-linux-x64.tar.gz | 441.8MB | 330c71a87fbf8f0468ec9c5e0ad6e794 |
官方下载地址:http://dev.mysql.com/downloads/cluster/
Window最新版本7.3.2
| 文件 | 大小 | md5 |
|---|---|---|
| mysqlcluster-7.3.2-windows-x32.msi | 100.2MB | 9d25735d7e8af1a2e805f9a1fecc3a1f |
| mysqlcluster-7.3.2-windows-x64.msi | 95.5MB | 6fe30e2045f074f471761cb17f0c3d1c |
基本概念:
“NDB” 是一种“内存中”的存储引擎,也是事务型存储引擎,具备ACID属性。
管理(MGM)节点:负责管理MySQL Cluster内的其他节点,如提供配置数据、启动并停止节点、运行备份等。由于这类节点负责管理其他节点的配置,应在启动其他节点之前首先启动这类节点。MGM节点是用命令“ndb_mgmd”启动的。
数据节点:用于保存 Cluster的数据。数据节点的数目与副本的数目相关,是片段的倍数。数据节点是用命令“ndbd”启动的。
SQL节点:用来访问 Cluster数据的节点。也就是Mysql服务,可以使用service mysqld start启动。
管理服务器(MGM节点)负责管理 Cluster配置文件和 Cluster日志。 Cluster中的每个节点从管理服务器检索配置数据,并请求确定管理服务器所在位置的方式。当数据节点内出现新的事件时,节点将关于这类事件的信息传输到管理服务器,然后,将这类信息写入 Cluster日志。

集群配置概述:
安装版本:mysql cluster 7.3.2
操作系统 :centos6.3(X64)
软件名称 :mysql-cluster-gpl-7.3.2-linux-glibc2.5-x86_64.tar.gz (通用版)
管理节点IP:192.168.0.202
数据节点-SQL节点IP:192.168.0.203
数据节点-SQL节点IP:192.168.0.204
安装依赖包:yum install -y glibc perl libaio-devel
x32位系统要安装兼容库组:yum groupinstall “Compatibility libraries”
一、管理节点安装配置
1、安装mysql-cluster
|
1
2
3
4
5
6
7
8
|
groupadd mysqluseradd -g mysql -s /sbin/nologin mysqltar -zxvf mysql-cluster-gpl-7.3.2-linux-glibc2.5-x86_64.tar.gzmv mysql-cluster-gpl-7.3.2-linux-glibc2.5-x86_64 /usr/local/mysql-clusterchown -R root.mysql /usr/local/mysql/chown -R mysql.mysql /usr/local/mysql/data//usr/local/mysql/scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --user=mysql & #初始化数据库cp -rf /usr/local/mysql/bin/ndb_mgm* /usr/local/bin/ #复制ndb节点管理命令到本地,方便使用 |
2、修改mysql主配置文件
|
1
2
3
4
5
6
7
8
9
10
11
12
|
vi /etc/my.cnf[MYSQLD] user = mysql socket = /tmp/mysql.sock basedir = /usr/local/mysql #安装目录 datadir = /usr/local/mysql/data #数据库存放目录 character-set-server=UTF8 ndbcluster #运行NDB存储引擎 ndb-connectstring=192.168.0.202 lower_case_table_names=1 #表名是否区分大小写1为不区分,不然linux下表名是区分大小写的[MYSQL_CLUSTER]ndb-connectstring=192.168.0.202 #Mysql Cluster管理节点IP |
3、创建mysql集群配置文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
mkdir /var/lib/mysql-clustervi /var/lib/mysql-cluster/config.ini[ndbd default]NoOfReplicas=2 #定义在Cluster环境中相同数据的份数,最大为4DataMemory=256M #分配的数据内存大小,根据本机服务器内存适量来分配IndexMemory=256M #设定用于存放索引(非主键)数据的内存段大小#一个NDB节点能存放的数据量是会受到DataMemory和IndexMemory两个参数设置的约束,两者任何一个达到限制数量后,都无法再增加能存储的数据量。如果继续存入数据系统会报错“table is full”。[ndb_mgmd]nodeid=1hostname=192.168.0.202datadir=/var/lib/mysql-cluster/[ndbd]nodeid=2hostname=192.168.0.203datadir=/usr/local/mysql/data[ndbd]nodeid=3hostname=192.168.0.204datadir=/usr/local/mysql/data[mysqld]nodeid=4hostname=192.168.0.203[mysqld]nodeid=5hostname=192.168.0.204保存退出!chown mysql.mysql /var/lib/mysql-cluster/config.ini |
二、两台数据节点和SQL节点配置相同
1、安装mysql-cluster
|
1
2
3
4
5
6
7
8
9
10
|
tar -zxvf mysql-cluster-gpl-7.3.2-linux-glibc2.5-x86_64.tar.gzmv mysql-cluster-gpl-7.3.2-linux-glibc2.5-x86_64 /usr/local/mysqlgroupadd mysqluseradd -g mysql -s /sbin/nologin mysqlchown -R root.mysql /usr/local/mysqlchown -R mysql.mysql /usr/local/mysql/data/usr/local/mysql/scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --user=mysql & #初始化数据库cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqldcp /usr/local/mysql/support-files/medium.cnf /etc/my.cnfchmod +x/etc/init.d/mysqld |
2、修改mysql配置文件
|
1
2
3
4
5
6
7
8
9
10
11
|
vi /etc/my.cnf[MYSQLD]user=mysqlcharacter_set_server=utf8ndbclusterndb-connectstring=192.168.0.202default-storage-engine=ndbcluster #设置默认是NDB存储引擎datadir=/usr/local/mysql/databasedir=/usr/local/mysql[MYSQL_CLUSTER]ndb-connectstring=192.168.0.202 #mysql cluster 管理节点IP |
三、测试(先关闭三台服务器的防火墙(IPTABLES)与 Selinux)
1、启动管理节点
|
1
2
3
|
ndb_mgmd -f /var/lib/mysql-cluster/config.ini --initialnetstat -tuplna | grep 1186 #默认连接端口1186,启动成功tcp 0 0 0.0.0.0:1186 0.0.0.0:* LISTEN 1369/ndb_mgmd |
#--initial:第一次启动时加上,其它时候不要加,不然会数据清空,除非是在备份、恢复或配置变化后重启时。
如果启动出现报错:把config.ini里设置的nodeid都给删除即可!

2、启动两台数据节点和SQL节点
数据节点:/usr/local/mysql/bin/ndbd --initial
SQL节点:bin/mysqld_safe --user=mysql & 或 service mysqld start
3、查看集群状态
ndb_mgm -e show #显示管理节点和数据节点则配置成功
4、创建一个数据库验证是否同步
|
1
2
3
4
5
6
|
mysql -u root -pMysql>create database test;Mysql>use test;Mysql>create table abc (id int) engine=ndbcluster;#指定数据库表的引擎为NDB,否则同步失败Mysql>Insert into abc ()values (1);Mysql>select * from abc; |
#此时看两个数据是否数据一致,如果一致说明集群已经成功!
注意事项:
1.在建表的时候一定要用ENGINE=NDB或ENGINE=NDBCLUSTER指定使用NDB集群存储引擎,或用ALTER TABLE选项更改表的存储引擎。
2.NDB表必须有一个主键,因此创建表的时候必须定义主键,否则NDB存储引擎将自动生成隐含的主键。
3.Sql节点的用户权限表仍然采用MYISAM存储引擎保存的,所以在一个Sql节点创建的MySql用户只能访问这个节点,如果要用同样的用户访问别的Sql节点,需要在对应的Sql节点追加用户。
四、管理和维护命令
关闭mysql集群:ndb_mgm -e shutdown
重启mysql集群:ndb_mgmd -f /var/lib/mysql-cluster/config.ini
重启数据节点:/usr/local/mysql/bin/ndbd
启动SQL节点:/usr/local/mysql/bin/mysqld_safe --user=mysql & 或 service mysqld restart
查看mysql状态:ndb_mgm -e show
启动顺序:
管理节点 -> 数据节点 -> SQL节点
关闭顺序:
SQL节点 -> 数据节点 -> 管理节点
本文出自 ““企鹅”那点事儿” 博客,请务必保留此出处http://lizhenliang.blog.51cto.com/7876557/1290451
https://www.centos.bz/2012/11/mysql-cluster-install-configure/
MySQL集群安装与配置
MySQL Cluster 是 MySQL 适合于分布式计算环境的高实用、高冗余版本。它采用了NDB Cluster 存储引擎,允许在1个 Cluster 中运行多个MySQL服务器。MySQL Cluster 能够使用多种故障切换和负载平衡选项配置NDB存储引擎,但在 Cluster 级别上的存储引擎上做这个最简单。下面我们简单介绍MySQL Cluster如何安装与配置。
基本设定
管理(MGM)节点:192.168.0.111
MySQL服务器(SQL)节点:192.168.0.110
数据(NDBD)节点"A":192.168.0.112
数据(NDBD)节点"B":192.168.0.113
一、mysql集群安装
mysql的集群安装可以有三种方式,一是直接下载二进制使用,二是使用rpm安装,三是源码编译。我们这里使用第一种安装。
1、每个节点做相同的操作
- cd /tmp
- wget http://cdn.mysql.com/Downloads/MySQL-Cluster-7.2/mysql-cluster-gpl-7.2.8-linux2.6-i686.tar.gz
- tar xzf mysql-cluster-gpl-7.2.8-linux2.6-i686.tar.gz
- mv mysql-cluster-gpl-7.2.8-linux2.6-i686 /usr/local/mysql
注意:这里下载的是32位的二进制包,如果你的系统是64位,需要下载64位的包。
2、存储节点和SQL节点安装
- groupadd mysql
- useradd -g mysql mysql
- /usr/local/mysql/scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --user=mysql
- chown -R root /usr/local/mysql
- chown -R mysql /usr/local/mysql/data
- chgrp -R mysql /usr/local/mysql
- cp /usr/local/mysql/support-files/my-medium.cnf /etc/my.cnf
二、节点配置
1、配置存储节点和SQL节点
- vi /etc/my.cnf
- 类似于:
- # Options for mysqld process:
- [MYSQLD]
- ndbcluster # run NDB engine
- ndb-connectstring=198.168.0.111 # location of MGM node
- # Options for ndbd process:
- [MYSQL_CLUSTER]
- ndb-connectstring=198.168.0.111 # location of MGM node
2、配置管理节点
- mkdir /var/lib/mysql-cluster
- cd /var/lib/mysql-cluster
- vi config.ini
- config.ini文件应类似于:
- # Options affecting ndbd processes on all data nodes:
- [NDBD DEFAULT]
- NoOfReplicas=2 # Number of replicas
- DataMemory=80M # How much memory to allocate for data storage
- IndexMemory=18M # How much memory to allocate for index storage
- # For DataMemory and IndexMemory, we have used the
- # default values. Since the "world" database takes up
- # only about 500KB, this should be more than enough for
- # this example Cluster setup.
- # TCP/IP options:
- [TCP DEFAULT]
- portnumber=2202 # This the default; however, you can use any
- # port that is free for all the hosts in cluster
- # Note: It is recommended beginning with MySQL 5.0 that
- # you do not specify the portnumber at all and simply allow
- # the default value to be used instead
- # Management process options:
- [NDB_MGMD]
- hostname=198.168.0.111 # Hostname or IP address of MGM node
- datadir=/var/lib/mysql-cluster # Directory for MGM node logfiles
- # Options for data node "A":
- [NDBD]
- # (one [NDBD] section per data node)
- hostname=198.168.0.112 # Hostname or IP address
- datadir=/usr/local/mysql/data # Directory for this data node's datafiles
- # Options for data node "B":
- [NDBD]
- hostname=198.168.0.113 # Hostname or IP address
- datadir=/usr/local/mysql/data # Directory for this data node's datafiles
- # SQL node options:
- [MYSQLD]
- hostname=198.168.0.110 # Hostname or IP address
- # (additional mysqld connections can be
- # specified for this node for various
- # purposes such as running ndb_restore)
三、首次启动节点
1、启动管理节点
- /usr/local/mysql/bin/ndb_mgmd --configdir=/var/lib/mysql-cluster -f /var/lib/mysql-cluster/config.ini
2、启动数据节点
首次启动需要--initial参数初始化,下一次启动就不需要了。
- /usr/local/mysql/bin/ndbd --initial
3、启动SQL节点
- /usr/local/mysql/bin/mysqld_safe &
4、检查状态
如果一切正常,执行命令 /usr/local/mysql/bin/ndb_mgm -e show应该会输出类似信息:
[root@localhost mysql-cluster]# /usr/local/mysql/bin/ndb_mgm -e show
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @192.168.0.112 (mysql-5.5.27 ndb-7.2.8, Nodegroup: 0, Master)
id=3 @192.168.0.113 (mysql-5.5.27 ndb-7.2.8, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @192.168.0.111 (mysql-5.5.27 ndb-7.2.8)
[mysqld(API)] 1 node(s)
id=4 @192.168.0.110 (mysql-5.5.27 ndb-7.2.8)
四、测试服务是否正常
在SQL节点上执行如下数据库操作:
- /usr/local/mysql/bin/mysql -uroot -p
- mysql> create database clusterdb;use clusterdb;
- mysql> create table simples (id int not null primary key) engine=ndb;
- mysql> insert into simples values (1),(2),(3),(4);
- mysql> select * from simples;
如果出现:
+----+
| id |
+----+
| 1 |
| 2 |
| 4 |
| 3 |
+----+
则表示工作正常。
五、安全关闭和重启
1、关闭mysql集群,可在管理节点在执行如下命令:
- /usr/local/mysql/bin/ndb_mgm -e shutdown
2、重启管理节点
- /usr/local/mysql/bin/ndb_mgmd --configdir=/var/lib/mysql-cluster -f /var/lib/mysql-cluster/config.ini
3、重启数据节点
- /usr/local/mysql/bin/ndbd
.........................
http://www.searchtb.com/2012/07/mysql-cluster.html
简介
MySQL集群是一种在无共享架构(SNA,Share Nothing Architecture)系统里应用内存数据库集群的技术。这种无共享的架构可以使得系统使用低廉的硬件获取高的可扩展性。
MySQL集群是一种分布式设计,目标是要达到没有任何单点故障点。因此,任何组成部分都应该拥有自己的内存和磁盘。任何共享存储方案如网络共享,网络文件系统和SAN设备是不推荐或不支持的。通过这种冗余设计,MySQL声称数据的可用度可以达到99.999%。
实际上,MySQL集群是把一个叫做NDB的内存集群存储引擎集成与标准的MySQL服务器集成。它包含一组计算机,每个都跑一个或者多个进程,这可能包括一个MySQL服务器,一个数据节点,一个管理服务器和一个专有的一个数据访问程序。它们之间的关系如下图所示:
存储引擎
MySQL Cluster 使用了一个专用的基于内存的存储引擎,这样做的好处是速度快, 没有磁盘I/O的瓶颈,但是由于是基于内存的,所以数据库的规模受系统总内存的限制, 如果运行NDB的MySQL服务器一定要内存够大,比如4G, 8G, 甚至16G。NDB引擎是分布式的,它可以配置在多台服务器上来实现数据的可靠性和扩展性,理论上 通过配置2台NDB的存储节点就能实现整个数据库集群的冗余性和解决单点故障问题。
该存储引擎有下列弊端:
- 基于内存,数据库的规模受集群总内存的大小限制
- 基于内存,断电后数据可能会有数据丢失,这点还需要通过测试验证。
- 多个节点通过网络实现通讯和数据同步、查询等操作,因此整体性受网络速度影响,
- 因此速度也比较慢
当然也有它的优点:
- 多个节点之间可以分布在不同的地理位置,因此也是一个实现分布式数据库的方案。
- 扩展性很好,增加节点即可实现数据库集群的扩展。
- 冗余性很好,多个节点上都有完整的数据库数据,因此任何一个节点宕机都不会造成服务中断。
- 实现高可用性的成本比较低,不象传统的高可用方案一样需要共享的存储设备和专用的软件才能实现,NDB 只要有足够的内存就能实现。
体系结构
MySQL Cluster 由3个不同功能的服务构成,每个服务由一个专用的守护进程提供,一项 服务也叫做一个节点,下面来介绍每个节点的功能。
The management (MGM) node
管理节点,用来实现整个集群的管理,理论上一般只启动一个,而且宕机也不影响 cluster 的服务,这个进程只在cluster 启动以及节点加入集群时起作用, 所以这个节点不是很需要冗余,理论上通过一台服务器提供服务就可以了。
通过 ndb_mgmd 命令启动,使用 config.ini 配置文件
The storage or database (DB) node:
数据库节点,用来存储数据,可以和管理节点(MGM) , 用户端节点(API) 可以处在 不同的机器上,也可以在同一个机器上面,集群中至少要有一个DB节点,2个以上 时就能实现集群的高可用保证,DB节点增加时,集群的处理速度会变慢。
通过 ndbd 命令启动,第一次创建好cluster DB 节点时,需要使用 –init参数初始化。
例如: bin/ndbd –ndb-connectstring=ndb_mgmd.mysqlcluster.net –initial
The client (API) node:
客户端节点,通过他实现 cluster DB 的访问,这个节点也就是普通的 mysqld 进程, 需要在配置文件中配置ndbcluster 指令打开 NDB Cluster storage engine 存储引擎,增加 API 节点会提高整个集群的并发访问速度和整体的吞吐量,该节点 可以部署在Web应用服务器上,也可以部署在专用的服务器上,也开以和DB部署在 同一台服务器上。
通过 mysqld_safe 命令启动,
这3类节点可以分布在不同的主机上,比如 DB 可以是多台专用的服务器,也可以 每个DB都有一个API,当然也可以把API分布在Web前端的服务器上去,通常来说, API越多cluster的性能会越好。
Mysql集群探索与实践
1. 准备好3台机器,从官网下载最新的mysql集群版本,此处用到mysql-cluster-gpl-7.1.5.tar.gz源码包, 配置并安装,记得加上
–with-plugins=innobase,ndbcluster (innobase可选)
3台机器分别是192.168.207.153,192.168.208.3,192.168.208.9,具体分配如下
管理节点(ndb_mgmd):192.168.207.153
数据节点(ndbd): 192.168.208.3
数据节点(ndbd): 192.168.208.9
SQL节点(mysqld): 192.168.208.3
SQL节点(mysqld): 192.168.208.9
2. 在mysql目录下新建mysql-cluster文件夹,切换到mysql-cluster,新建config.ini
[NDBD DEFAULT] NoOfReplicas=2 #备份,副本,这样的话2台数据节点的数据就会同步 DataMemory=200M IndexMemory=100M [TCP DEFAULT] portnumber=2202 [NDB_MGMD] #管理节点 id=1 hostname=192.168.207.153 datadir=/home/taozi/mysql/mysql-cluster [NDBD] #数据节点 id=2 hostname=192.168.208.3 datadir=/home/taozi/mysql/data [NDBD] #数据节点 id=3 hostname=192.168.208.9 datadir=/home/taozi/mysql/data [MySQLD] #sql节点 id=4 hostname=192.168.208.3 [MySQLD] #sql节点 id=5 hostname=192.168.208.9 [MySQLD] #sql节点 id=6
3. 在管理节点服务器上启动管理节点服务 (如果不存在ndb_mgmd那么要从libexec下面复制过来)
~/mysql/bin/ndb_mgmd -f ~/mysql/mysql-cluster/config.ini
4. 进入2台数据节点服务器,分别启动数据节点服务
~/mysql/bin/ndbd (第一次启动使用 ~/mysql/bin/ndbd --initial)
5. 最后分别进入sql节点服务器,修改my.cnf,加入
[MYSQL_CLUSTER] ndb-connectstring=192.168.207.153 [MYSQLD] ndbcluster ndb-connectstring=192.168.207.153
启动mysql服务
/home/taozi/mysql/bin/mysqld_safe --ledir=/home/taozi/mysql/bin / --log-error=/home/taozi/mysql/data/t.err --datadir=/home/taozi/mysql/data / --socket=/home/taozi/mysql/tmp/mysql.sock --pid-file=/home/taozi/mysql/data/mysqld.pid &
6. 此时回到管理节点
~/mysql/bin/ndb_mgm -e show
可以看到显示如下
[taozi@search153 mysql]$ ./show.sh Connected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.208.3 (mysql-5.1.47 ndb-7.1.5, Nodegroup: 0, Master) id=3 @192.168.208.9 (mysql-5.1.47 ndb-7.1.5, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.207.153 (mysql-5.1.47 ndb-7.1.5) [mysqld(API)] 3 node(s) id=4 @192.168.208.3 (mysql-5.1.47 ndb-7.1.5) id=5 @192.168.208.9 (mysql-5.1.47 ndb-7.1.5) id=6 (not connected, accepting connect from any host)
7. 进入sql节点,在test数据库创建表
CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`) ) ENGINE=ndbcluster DEFAULT CHARSET=gbk
切换到2台数据节点服务器~/mysql/data/ndb_2_fs和~/mysql/data/ndb_3_fs看看,
或者直接去数据库查,数据已经同步了!
8. 关闭集群服务
关闭sql节点等同于停止mysql服务,此时外界数据不将再进来。然后关闭管理节点
~/mysql/bin/ndb_mgm -e shutdown rm ~/mysql/mysql-cluster/ndb_1_config.bin.1 #不是必须的,如果config.ini有改动则要加上
这样操作后,管理节点和数据节点都将停止服务
Notes:
1:如果发现关闭一台机器的ndbd进程,另一台机器的ndbd的进程也关闭,则需要修改参数NoOfReplicas。 2:./ndbd --initial 不能同时在所有数据节点机器上执行,如执行,会删除所有数据 3:可以像操作非簇类型的数据库那样,操作mysqld节点 4:每次修改config.ini文件,重启ndb_mgmd时,需要删除mysql-cluster文件下的ndb_1_config.bin.1文件, 因为他默认调用此文件 5:NDB 簇不支持自动发现数据库的功能,这点很重要,一旦在一个数据节点上创建了世界(world)数据库和它的表, 在簇中的每个SQL节点上还需要发出命令 CREATE DATABASE world,后跟FLUSH TABLES。这样,节点就能 识别数据库并读取其表定义。(在本版本MySQL Cluster 7.1.5下数据库也会自动同步的) 6:如果在相关节点服务器启动时,注意查看~/mysql/mysql-cluster目录内的相关日志文件以获取错误信息. 7:在管理节点的配置文件里各[mysqld],[ndbd]和[ndb_mgmd]配置的选项值顺序应该如下: [mysqld] Id=4 HostName=192.168.208.3 Id在顶端紧跟其后的是HostName,如果顺序错了,当SQL或数据节点连接管理节点时,管理节点无法正确的定位 到其对应的节点配置上. 因为无法定位到对应的节点配置,当没有剩余的[空节点]时,客户端节点启动时(./mysqld or ./ndbd) 还会报: Configuration error: Error : Could not alloc node id at 192.168.0.231 port 1186: No free node id found for mysqld (API).Failed to initialize consumers 8:[空节点]是没有指定HostName选项的节点配置均为空节点,空节点可以用来动态配置一些动态IP的节点, 一般管理节点的 配置文件要预留3个以上的空节点,因为备份时需要连接一个节点,如下: [mysqld] Id=6
https://www.howtoforge.com/loadbalanced_mysql_cluster_debian
How To Set Up A Load-Balanced MySQL Cluster
Version 1.0
Author: Falko Timme
Last edited 03/27/2006
This tutorial shows how to configure a MySQL 5 cluster with three nodes: two storage nodes and one management node. This cluster is load-balanced by a high-availability load balancer that in fact has two nodes that use the Ultra Monkey package which provides heartbeat (for checking if the other node is still alive) and ldirectord (to split up the requests to the nodes of the MySQL cluster).
In this document I use Debian Sarge for all nodes. Therefore the setup might differ a bit for other distributions. The MySQL version I use in this setup is 5.0.19. If you do not want to use MySQL 5, you can use MySQL 4.1 as well, although I haven't tested it.
This howto is meant as a practical guide; it does not cover the theoretical backgrounds. They are treated in a lot of other documents in the web.
This document comes without warranty of any kind! I want to say that this is not the only way of setting up such a system. There are many ways of achieving this goal but this is the way I take. I do not issue any guarantee that this will work for you!
1 My Servers
I use the following Debian servers that are all in the same network (192.168.0.x in this example):
- sql1.example.com: 192.168.0.101 MySQL cluster node 1
- sql2.example.com: 192.168.0.102 MySQL cluster node 2
- loadb1.example.com: 192.168.0.103 Load Balancer 1 / MySQL cluster management server
- loadb2.example.com: 192.168.0.104 Load Balancer 2
In addition to that we need a virtual IP address : 192.168.0.105. It will be assigned to the MySQL cluster by the load balancer so that applications have a single IP address to access the cluster.
Although we want to have two MySQL cluster nodes in our MySQL cluster, we still need a third node, the MySQL cluster management server, for mainly one reason: if one of the two MySQL cluster nodes fails, and the management server is not running, then the data on the two cluster nodes will become inconsistent ("split brain"). We also need it for configuring the MySQL cluster.
So normally we would need five machines for our setup:
2 MySQL cluster nodes + 1 cluster management server + 2 Load Balancers = 5
As the MySQL cluster management server does not use many resources, and the system would just sit there doing nothing, we can put our first load balancer on the same machine, which saves us one machine, so we end up with four machines.
2 Set Up The MySQL Cluster Management Server
First we have to download MySQL 5.0.19 (the max version!) and install the cluster management server (ndb_mgmd) and the cluster management client (ndb_mgm - it can be used to monitor what's going on in the cluster). The following steps are carried out on loadb1.example.com (192.168.0.103):
loadb1.example.com:
mkdir /usr/src/mysql-mgm
cd /usr/src/mysql-mgm
wget http://dev.mysql.com/get/Downloads/MySQL-5.0/mysql-max-5.0.19-linux-i686-\
glibc23.tar.gz/from/http://www.mirrorservice.org/sites/ftp.mysql.com/
tar xvfz mysql-max-5.0.19-linux-i686-glibc23.tar.gz
cd mysql-max-5.0.19-linux-i686-glibc23
mv bin/ndb_mgm /usr/bin
mv bin/ndb_mgmd /usr/bin
chmod 755 /usr/bin/ndb_mg*
cd /usr/src
rm -rf /usr/src/mysql-mgm
Next, we must create the cluster configuration file, /var/lib/mysql-cluster/config.ini:
loadb1.example.com:
mkdir /var/lib/mysql-cluster
cd /var/lib/mysql-cluster
vi config.ini
[NDBD DEFAULT] |
Please replace the IP addresses in the file appropriately.
Then we start the cluster management server:
loadb1.example.com:
ndb_mgmd -f /var/lib/mysql-cluster/config.ini
It makes sense to automatically start the management server at system boot time, so we create a very simple init script and the appropriate startup links:
loadb1.example.com:
echo 'ndb_mgmd -f /var/lib/mysql-cluster/config.ini' > /etc/init.d/ndb_mgmd
chmod 755 /etc/init.d/ndb_mgmd
update-rc.d ndb_mgmd defaults
3 Set Up The MySQL Cluster Nodes (Storage Nodes)
Now we install mysql-max-5.0.19 on both sql1.example.com and sql2.example.com:
sql1.example.com / sql2.example.com:
groupadd mysql
useradd -g mysql mysql
cd /usr/local/
wget http://dev.mysql.com/get/Downloads/MySQL-5.0/mysql-max-5.0.19-linux-i686-\
glibc23.tar.gz/from/http://www.mirrorservice.org/sites/ftp.mysql.com/
tar xvfz mysql-max-5.0.19-linux-i686-glibc23.tar.gz
ln -s mysql-max-5.0.19-linux-i686-glibc23 mysql
cd mysql
scripts/mysql_install_db --user=mysql
chown -R root:mysql .
chown -R mysql data
cp support-files/mysql.server /etc/init.d/
chmod 755 /etc/init.d/mysql.server
update-rc.d mysql.server defaults
cd /usr/local/mysql/bin
mv * /usr/bin
cd ../
rm -fr /usr/local/mysql/bin
ln -s /usr/bin /usr/local/mysql/bin
Then we create the MySQL configuration file /etc/my.cnf on both nodes:
sql1.example.com / sql2.example.com:
vi /etc/my.cnf
[mysqld] |
Make sure you fill in the correct IP address of the MySQL cluster management server.
Next we create the data directories and start the MySQL server on both cluster nodes:
sql1.example.com / sql2.example.com:
mkdir /var/lib/mysql-cluster
cd /var/lib/mysql-cluster
ndbd --initial
/etc/init.d/mysql.server start
(Please note: we have to run ndbd --initial only when the start MySQL for the first time, and if/var/lib/mysql-cluster/config.ini on loadb1.example.com changes.)
Now is a good time to set a password for the MySQL root user:
sql1.example.com / sql2.example.com:
mysqladmin -u root password yourrootsqlpassword
We want to start the cluster nodes at boot time, so we create an ndbd init script and the appropriate system startup links:
sql1.example.com / sql2.example.com:
echo 'ndbd' > /etc/init.d/ndbd
chmod 755 /etc/init.d/ndbd
update-rc.d ndbd defaults
http://blog.rimuhosting.com/2011/07/06/building-database-clusters-with-mysql/
Building database clusters with MySQL
MySQL is a mainstay of many web based applications, and is popular with lots of our customers. There does comes a time when a single database server is not enough. To enhance redundancy MySQL has a couple of options. You can add more servers with vanilla replication enabled. Or you can look at setting up MySQL Cluster. The documentation has this to say...
MySQL Cluster is designed not to have any single point of failure.
Sounds pretty good right? Lets take a look at an example setup.
Setup Overview
MySQL Cluster has one or more of several major components. Typically each component will have its own server (a node). Those components are
- sql node(front-end)
- data node (back-end)
- management node (central config,meta-data and etc)
Generally speaking, application requests are sent to the sql nodes, which then talk to the data nodes and coordinates each other via management node(s) to actually recover the content you want. MySQL Cluster documentation also says... "Although a MySQL Cluster SQL node uses the mysqld server daemon, it differs in a number of critical respects from the mysqld binary ... and the two versions ofmysqld are not interchangeable."
The mysql cluster package that will be installed is not part of any standard Linux distribution package and it's outside from any of the official Linux distribution repository, the reason is that this approach reduces version and dependency conflicts of the installed stock mysql packages on the server and any existing mysql data directory commonly /var/lib/mysql will also not be touched. The binary packages we used from MySQL downloads generally runs on most major Linux distributions so this approach should work on most linux servers.
Physical Setup
Nodes of each type need to be as similar as possible, including the physical architecture and distribution setup. This makes the cluster behave more predictably and insures that kernel level settings are the same. Also...
- two different configuration files are used. The well known my.cnf and config.ini, however in this setup we will create /etc/mysqld-cluster.cf so as not to touch existing /etc/my.cnf or /etc/mysql/my.cnf (debian/ubuntu), which is required by manager nodes. Refer to MySQL Cluster Configuration Files
- all cluster nodes in this setup is using Ubuntu 11.04 32bit
- we will be using 1 management node, 4 data nodes and 4 sql nodes.
Server Details:
- management node: hostname: mgr1, private IP: 192.168.0.100, tcp port: 2205
- sql node: hostname: dbsrv1, private IP: 192.168.0.21
- sql node: hostname: dbsrv2, private IP: 192.168.0.22
- sql node: hostname: dbsrv3, private IP: 192.168.0.23
- sql node: hostname: dbsrv4, private IP: 192.168.0.24
- data node: hostname: ndb1, private IP: 192.168.0.11
- data node: hostname: ndb2, private IP: 192.168.0.12
- data node: hostname: ndb3, private IP: 192.168.0.13
- data node: hostname: ndb4, private IP: 192.168.0.14
Logon to management node server mgr1 as root using an ssh session and download the latest mysql cluster installer with the following commands, as of this writing it's version 7.1.14.
cd wget http://dev.mysql.com/get/Downloads/MySQL-Cluster-7.1/mysql-cluster-gpl-7.1.14-linux-i686-glibc23.tar.gz/from/ftp://mirror.anl.gov/pub/mysql/ |
If there's already mysql user and group it's safe to ignore errors from adduser and groupadd
adduser mysql groupadd mysql cd /usr/local tar zxvf ~/mysql-cluster-gpl-7.1.14-linux-i686-glibc23.tar.gz ln -s mysql-cluster-gpl-7.1.14-linux-i686-glibc23 mysql-cluster cd mysql-cluster chown -R mysql:mysql /usr/local/mysql-cluster/ mkdir -p /var/lib/mysql-mgmd-config-cache mkdir -p /var/lib/mysql-mgmd-data |
This is the minimum config.ini settings on management node. Refer MySQL Cluster Management Node Configuration Parameters and MySQL Cluster Data Node Configuration Parameters.
Important
Setting NoOfReplicas to 1 means that there is only a single copy of all Cluster data; in this case, the loss of a single data node causes the cluster to fail because there are no additional copies of the data stored by that node.
The maximum possible value is 4; currently, only the values 1 and 2 are actually supported.
cat >> /var/lib/mysql-mgmd-data/config.ini << EOF [ndbd default] NoOfReplicas = 2 DataDir= /var/lib/mysql-ndb-data DataMemory = 64M IndexMemory = 128M [ndb_mgmd] # Management process options: DataDir = /var/lib/mysql-mgmd-data PortNumber = 2205 HostName = 192.168.0.100 [ndbd] # Options for data node ndb1 hostname = 192.168.0.11 [ndbd] # Options for data node ndb2 hostname = 192.168.0.12 [ndbd] # Options for data node ndb3 hostname = 192.168.0.13 [ndbd] # Options for data node ndb4 hostname = 192.168.0.14 [mysqld] # SQL node options for dbsrv1 hostname = 192.168.0.21 [mysqld] # SQL node options for dbsrv2 hostname = 192.168.0.22 [mysqld] # SQL node options for dbsrv3 hostname = 192.168.0.23 [mysqld] # SQL node options for dbsrv4 hostname = 192.168.0.24 EOF cd /usr/local/mysql-cluster/bin ./ndb_mgmd --initial --configdir=/var/lib/mysql-mgmd-config-cache --config-file=/var/lib/mysql-mgmd-data/config.ini |
That's it! you're done on management node. Grab a coffee if you can, the next steps will just be more on hopping to sql node and data node servers. For each data node server, logon to each and perform the commands below. Assuming this is on ssh console connection, first logon to ndb1.
cd wget http://dev.mysql.com/get/Downloads/MySQL-Cluster-7.1/mysql-cluster-gpl-7.1.14-linux-i686-glibc23.tar.gz/from/ftp://mirror.anl.gov/pub/mysql/ adduser mysql groupadd mysql cd /usr/local tar zxvf ~/mysql-cluster-gpl-7.1.14-linux-i686-glibc23.tar.gz ln -s mysql-cluster-gpl-7.1.14-linux-i686-glibc23 mysql-cluster cd mysql-cluster chown -R mysql:mysql /usr/local/mysql-cluster/ scripts/mysql_install_db --user=mysql --datadir=/var/lib/mysql-ndb-data bin/ndbd --ndb-connectstring=192.168.0.100:2205 |
Repeat the commands above on ndb2,ndb3 and ndb4 data node servers.
You can now login to mgr1 node via ssh console and check the status of the nodes...
cd /usr/local/mysql-cluster bin/ndb_mgm --ndb-connectstring=192.168.0.100:2205 show |
For each sql node servers dbsrv1, dbsrv2, dbsrv3 and dbsrv4 run the commands below
cd wget http://dev.mysql.com/get/Downloads/MySQL-Cluster-7.1/mysql-cluster-gpl-7.1.14-linux-i686-glibc23.tar.gz/from/ftp://mirror.anl.gov/pub/mysql/ adduser mysql groupadd mysql cd /usr/local tar zxvf ~/mysql-cluster-gpl-7.1.14-linux-i686-glibc23.tar.gz ln -s mysql-cluster-gpl-7.1.14-linux-i686-glibc23 mysql-cluster cd mysql-cluster chown -R mysql:mysql /usr/local/mysql-cluster/ scripts/mysql_install_db --user=mysql --datadir=/var/lib/mysql-node-data --basedir=/usr/local/mysql-cluster apt-get install libaio1 cat >> /etc/mysqld-cluster.cf <<EOF [mysqld] ndbcluster ndb-connectstring=192.168.0.100:2205 EOF bin/mysqld_safe --defaults-extra-file=/etc/mysqld-cluster.cf --user=mysql --datadir=/var/lib/mysql-node-data --basedir=/usr/local/mysql-cluster & |
Now on mgr1 node check the status of the nodes
cd /usr/local/mysql-cluster bin/ndb_mgm --ndb-connectstring=192.168.0.100:2205 show |
ndb_mgm output from show command with all data nodes and sql nodes up and running.
root@mgr1:/usr/local/mysql-cluster# bin/ndb_mgm --ndb-connectstring=192.168.0.100:2205 -- NDB Cluster -- Management Client -- ndb_mgm> show Connected to Management Server at: 192.168.0.100:2205 Cluster Configuration --------------------- [ndbd(NDB)] 4 node(s) id=2 @192.168.0.11 (mysql-5.1.56 ndb-7.1.14, Nodegroup: 0) id=3 @192.168.0.12 (mysql-5.1.56 ndb-7.1.14, Nodegroup: 0, Master) id=4 @192.168.0.13 (mysql-5.1.56 ndb-7.1.14, Nodegroup: 1) id=5 @192.168.0.14 (mysql-5.1.56 ndb-7.1.14, Nodegroup: 1) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.100 (mysql-5.1.56 ndb-7.1.14) [mysqld(API)] 4 node(s) id=6 @192.168.0.21 (mysql-5.1.56 ndb-7.1.14) id=7 @192.168.0.22 (mysql-5.1.56 ndb-7.1.14) id=8 @192.168.0.23 (mysql-5.1.56 ndb-7.1.14) id=9 @192.168.0.24 (mysql-5.1.56 ndb-7.1.14) |
To test the setup we can use the sample world database from mysql's site. Login to any of the sql nodes, in this example dbsrv1 is used and execute the commands below assuming you're on ssh console connection.
cd wget http://downloads.mysql.com/docs/world_innodb.sql.gz gunzip world_innodb.sql.gz cat world_innodb.sql | sed 's/InnoDB/NDBCLUSTER/g' > world_ndb.sql cd /usr/local/mysql-cluster bin/mysql -uroot -e 'create database world' bin/mysql -uroot world < /root/world_ndb.sql |
Optionally run on each of the sql nodes to check if it created the world db successfully for all sql nodes.
bin/mysql -uroot -e 'show databases' |
actual mysql command line session in ssh console from dbsrv1 and dbsrv2 sql nodes
root@dbsrv1:~# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.1.56-ndb-7.1.14-cluster-gpl MySQL Cluster Server (GPL) Copyright (c) 2000, 2010, Oracle and/or its affiliates. All rights reserved. This software comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to modify and redistribute it under the GPL v2 license Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | ndbinfo | | test | | world | +--------------------+ 5 rows in set (0.00 sec) mysql> use world; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +-----------------+ | Tables_in_world | +-----------------+ | City | | Country | | CountryLanguage | +-----------------+ 3 rows in set (0.00 sec) mysql> select * from City limit 5; +------+----------------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+----------------+-------------+--------------+------------+ | 2519 | Nezahualcóyotl | MEX | México | 1224924 | | 1101 | Akola | IND | Maharashtra | 328034 | | 1726 | Ebina | JPN | Kanagawa | 115571 | | 1616 | Fukui | JPN | Fukui | 254818 | | 715 | Port Elizabeth | ZAF | Eastern Cape | 752319 | +------+----------------+-------------+--------------+------------+ 5 rows in set (0.01 sec) root@dbsrv2:/usr/local/mysql-cluster# mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 5 Server version: 5.1.56-ndb-7.1.14-cluster-gpl MySQL Cluster Server (GPL) Copyright (c) 2000, 2010, Oracle and/or its affiliates. All rights reserved. This software comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to modify and redistribute it under the GPL v2 license Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> use world Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select * from City limit 5; +------+----------------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+----------------+-------------+--------------+------------+ | 2519 | Nezahualcóyotl | MEX | México | 1224924 | | 1101 | Akola | IND | Maharashtra | 328034 | | 1726 | Ebina | JPN | Kanagawa | 115571 | | 1616 | Fukui | JPN | Fukui | 254818 | | 715 | Port Elizabeth | ZAF | Eastern Cape | 752319 | +------+----------------+-------------+--------------+------------+ 5 rows in set (0.00 sec) |
FAQ
Is there a reason why the test setup needs 4 nodes?- Answer: From
Important
It is not realistic to expect to employ a three-node setup in a production environment. Such a configuration provides no redundancy;to benefit from MySQL Cluster's high-availability features, you must use multiple data and SQL nodes. The use of multiple management nodes is also highly recommended.
Can we describe an example with two or three for a bit more simplicity?
Answer:
A simplier example is to have 2 data nodes, 1 sql node and 1 management node. This is the most minimal setup.
The whole steps above can still be followed but only setup ndb1 and ndb2 data nodes then only setup dbsrv1 a single sql node.
The rest of the steps for setting up of mgr1 management node can still be followed but a simpler config.ini can be used. Here's a trim down version.
cat >> /var/lib/mysql-mgmd-data/config.ini << EOF [ndbd default] NoOfReplicas = 2 DataDir= /var/lib/mysql-ndb-data DataMemory = 64M IndexMemory = 128M [ndb_mgmd] # Management process options: DataDir = /var/lib/mysql-mgmd-data PortNumber = 2205 HostName = 192.168.0.100 [ndbd] # Options for data node ndb1 hostname = 192.168.0.11 [ndbd] # Options for data node ndb2 hostname = 192.168.0.12 [mysqld] # SQL node options for dbsrv1 hostname = 192.168.0.21 EOF |
Does the number of nodes (odd or even) affect ease of management?
Answer:
Yes it affects the ease of management, increasing number of nodes means increasing numbers of servers to maintain and total number of data nodes must be in even number.
From the manual Defining MySQL Cluster Data Nodes
The value for this parameter must divide evenly into the number of data nodes in the cluster. For example, if there are two data nodes, then NoOfReplicas must be equal to either 1 or 2, since 2/3 and 2/4 both yield fractional values; if there are four data nodes, then NoOfReplicas must be equal to 1, 2, or 4.
moreover from the manual MySQL Cluster Core Concepts
There are as many data nodes as there are replicas, times the number of fragments For example, with two replicas, each having two fragments, you need four data nodes. One replica is sufficient for data storage, but provides no redundancy; therefore, it is recommended to have 2 (or more) replicas to provide redundancy, and thus high availability
OK, my mysql cluster is working so how can I use it on my existing app?
Answer:
Connect to any of the sql node on the cluster and create a table with engine type ndbcluster, for example.
create table mytable(col1 int not null primary key auto_increment, col2 varchar(100)) engine=NDBCLUSTER;
Where to from here
- If you have enough time please read the official MySQL Cluster Manual
- It is worth taking into account that Cluster nodes do not make use of the MySQL privilege system when accessing one another. Setting or changing MySQL user accounts (including the root account) effects only applications that access the SQL node, not interaction between node. Refer to MySQL Cluster Example with Tables and Data
- Though not required but for production mysql cluster setup it's best to have two network adapters on each server. Refer to MySQL Cluster Hardware,Software and Networking Requirements
http://www.clusterdb.com/mysql-cluster/creating-a-simple-cluster-on-a-single-linux-host
Creating a simple Cluster on a single LINUX host
It isn’t necessarily immediately obvious how to set up a Cluster on LINUX; this post attempts to show how to get a simple Cluster up and running. For simplicity, all of the nodes will run on a single host – a subsequent post will take the subsequent steps of moving some of them to a second host. As with my Windows post the Cluster will contain the following nodes:
- 1 Management node (ndb_mgmd)
- 2 Data nodes (ndbd)
- 3 MySQL Server (API) nodes (mysqld)
Downloading and installing
Browse to the MySQL Cluster LINUX download page at mysql.com and download the correct version (32 or 64 bit) and store it in the desired directory (in my case, /home/billy/mysql) and then extract and rename the new folder to something easier to work with…
[billy@ws1 mysql]$ tar xvf mysql-cluster-gpl-7.0.6-linux-x86_64-glibc23.tar.gz [billy@ws1 mysql]$ mv mysql-cluster-gpl-7.0.6-linux-x86_64-glibc23 7_0_6
Create 3 data folders (one for each of the MySQL API – mysqld – processes) and setup the files that will be needed for them to run correctly…
[billy@ws1 mysql]$ cd 7_0_6/data [billy@ws1 data]$ mkdir data1 data2 data3 [billy@ws1 data]$ mkdir data1/mysql data1/test data2/mysql data2/test data3/mysql data3/test [billy@ws1 7_0_6]$ cd .. [billy@ws1 7_0_6]$ scripts/mysql_install_db --basedir=/home/billy/mysql/7_0_6 --datadir=/home/billy/mysql/7_0_6/data/data1 [billy@ws1 7_0_6]$ scripts/mysql_install_db --basedir=/home/billy/mysql/7_0_6 --datadir=/home/billy/mysql/7_0_6/data/data2 [billy@ws1 7_0_6]$ scripts/mysql_install_db --basedir=/home/billy/mysql/7_0_6 --datadir=/home/billy/mysql/7_0_6/data/data3
Configure and run the Cluster
Create a sub-directory called “conf” and create the following 4 files there:
config.ini
[ndbd default] noofreplicas=2 [ndbd] hostname=localhost id=2 [ndbd] hostname=localhost id=3 [ndb_mgmd] id = 1 hostname=localhost [mysqld] id=4 hostname=localhost [mysqld] id=5 hostname=localhost [mysqld] id=6 hostname=localhost
my.1.conf
[mysqld] ndb-nodeid=4 ndbcluster datadir=/home/billy/mysql/7_0_6/data/data1 basedir=/home/billy/mysql/7_0_6 port=3306 server-id=1 log-bin
my.2.conf
[mysqld] ndb-nodeid=5 ndbcluster datadir=/home/billy/mysql/7_0_6/data/data2 basedir=/home/billy/mysql/7_0_6 port=3307 server-id=2 log-bin
my.3.conf
[mysqld] ndb-nodeid=6 ndbcluster datadir=/home/billy/mysql/7_0_6/data/data3 basedir=/home/billy/mysql/7_0_6 port=3308 server-id=3 log-bin
Those files configure the nodes that make up the Cluster. From a command prompt window, launch the management node:
[billy@ws1 7_0_6]$ bin/ndb_mgmd --initial -f conf/config.ini --configdir=/home/billy/mysql/7_0_6/conf 2009-06-17 13:00:08 [MgmSrvr] INFO -- NDB Cluster Management Server. mysql-5.1.34 ndb-7.0.6 2009-06-17 13:00:08 [MgmSrvr] INFO -- Reading cluster configuration from 'conf/config.ini'
Check that the management node is up and running:
[billy@ws1 7_0_6]$ bin/ndb_mgm ndb_mgm> show Connected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 (not connected, accepting connect from localhost) id=3 (not connected, accepting connect from localhost) [ndb_mgmd(MGM)] 1 node(s) id=1 @localhost (mysql-5.1.34 ndb-7.0.6) [mysqld(API)] 3 node(s) id=4 (not connected, accepting connect from localhost) id=5 (not connected, accepting connect from localhost) id=6 (not connected, accepting connect from localhost) ndb_mgm> quit
and then start the 2 data nodes (ndbd) and 3 MySQL API/Server nodes (ndbd) and then check that they’re all up and running:
[billy@ws1 7_0_6]$ bin/ndbd --initial -c localhost:1186 2009-06-17 13:05:47 [ndbd] INFO -- Configuration fetched from 'localhost:1186', generation: 1 [billy@ws1 7_0_6]$ bin/ndbd --initial -c localhost:1186 2009-06-17 13:05:51 [ndbd] INFO -- Configuration fetched from 'localhost:1186', generation: 1 [billy@ws1 7_0_6]$ bin/mysqld --defaults-file=conf/my.1.conf& [billy@ws1 7_0_6]$ bin/mysqld --defaults-file=conf/my.2.conf& [billy@ws1 7_0_6]$ bin/mysqld --defaults-file=conf/my.3.conf& [billy@ws1 7_0_6]$ bin/ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm> show Connected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @127.0.0.1 (mysql-5.1.34 ndb-7.0.6, Nodegroup: 0, Master) id=3 @127.0.0.1 (mysql-5.1.34 ndb-7.0.6, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @127.0.0.1 (mysql-5.1.34 ndb-7.0.6) [mysqld(API)] 3 node(s) id=4 @127.0.0.1 (mysql-5.1.34 ndb-7.0.6) id=5 @127.0.0.1 (mysql-5.1.34 ndb-7.0.6) id=6 @127.0.0.1 (mysql-5.1.34 ndb-7.0.6) ndb_mgm> quit
Using the Cluster
There are now 3 API nodes/MySQL Servers/mysqlds running; all accessing the same data. Each of those nodes can be accessed by the mysql client using the ports that were configured in the my.X.cnf files. For example, we can access the first of those nodes (node 4) in the following way (each API node is accessed using the port number in its associate my.X.cnf file:
[billy@ws1 7_0_6]$ bin/mysql -h localhost -P 3306
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 4
Server version: 5.1.34-ndb-7.0.6-cluster-gpl-log MySQL Cluster Server (GPL)
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql> use test;
Database changed
mysql> create table assets (name varchar(30) not null primary key,
-> value int) engine=ndb;
090617 13:21:36 [Note] NDB Binlog: CREATE TABLE Event: REPL$test/assets
090617 13:21:36 [Note] NDB Binlog: logging ./test/assets (UPDATED,USE_WRITE)
090617 13:21:37 [Note] NDB Binlog: DISCOVER TABLE Event: REPL$test/assets
090617 13:21:37 [Note] NDB Binlog: DISCOVER TABLE Event: REPL$test/assets
090617 13:21:37 [Note] NDB Binlog: logging ./test/assets (UPDATED,USE_WRITE)
090617 13:21:37 [Note] NDB Binlog: logging ./test/assets (UPDATED,USE_WRITE)
Query OK, 0 rows affected (0.99 sec)
mysql> insert into assets values ('Car','1900');
Query OK, 1 row affected (0.03 sec)
mysql> select * from assets;
+------+-------+
| name | value |
+------+-------+
| Car | 1900 |
+------+-------+
1 row in set (0.00 sec)
mysql> quit
Bye
Note that as this table is using the ndb (MySQL Cluster) storage engine, the data is actually held in the data nodes rather than in the SQL node and so we can access the exact same data from either of the other 2 SQL nodes:
[billy@ws1 7_0_6]$ bin/mysql -h localhost -P 3307 Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 5 Server version: 5.1.34-ndb-7.0.6-cluster-gpl-log MySQL Cluster Server (GPL) type 'help;' or 'h' for help. Type 'c' to clear the current input statement. mysql> use test; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select * from assets; +------+-------+ | name | value | +------+-------+ | Car | 1900 | +------+-------+ 1 row in set (0.00 sec) mysql> quit Bye
Your next steps
This is a very simple, contrived set up – in any sensible deployment, the nodes would be spread across multiple physical hosts in the interests of performance and redundancy (take a look at the new article (Deploying MySQL Cluster over multiple host) to see how to do that). You’d also set several more variables in the configuration files in order to size and tune your Cluster.
=====================================================
http://www.open-open.com/lib/view/open1409629668338.html








tar xvf mysql-utilities-1.4.4.tgzcd mysql-utilities-1.4.4python setup.py install
# mysql -uroot -h172.17.0.49 -pMySQL [(none)]> grant all on fabric.* to fabric@'172.17.42.1' identified by 'fabric@123';
# mysql -uroot -h172.17.0.50 -padmin@123MySQL [(none)]> grant all on *.* to fabric@'172.17.42.1' identified by 'fabric@456';# mysql -uroot -h172.17.0.47 -padmin@123MySQL [(none)]> grant all on *.* to fabric@'172.17.42.1' identified by 'fabric@456';Query OK, 0 rows affected (0.00 sec)# mysql -uroot -h172.17.0.48 -padmin@123MySQL [(none)]> grant all on *.* to fabric@'172.17.42.1' identified by 'fabric@456';Query OK, 0 rows affected (0.00 sec)
# cat /etc/mysql/fabric.cfg[DEFAULT] #如果请求的选项没有在命令行指定,或没有在配置文件找到,Fabric将查看该段的信息prefix =sysconfdir = /etc #配置文件存放目录logdir = /var/log #日志文件存储位置,绝对路径,由守护进程创建[storage] #配置backing store相关的选项address = 172.17.0.49:3306 #指定state store的mysql实例地址和端口user = fabric #连接到mysql实例的用户名password = fabric@123 #认证密码,也能设置空密码database = fabric #存储Fabric表的数据库auth_plugin = mysql_native_password #设置使用的认证插件connection_timeout = 6 #中断请求之前等待的最大时间,单位秒connection_attempts = 6 #创建连接的最大尝试次数connection_delay = 1 #连续尝试创建连接之间的延时时间,默认1s[servers]user = fabricpassword =[protocol.xmlrpc] #该段定义Fabric接收通过XML-RPC协议的请求address = 0.0.0.0:32274 #标识Fabric使用的主机和端口,接收XML-RPC请求threads = 5 #XML-RPC会话线程的并发创建数,决定多少并发请求Fabric能接受user = admin #用户名,认证命令行请求password = #用户密码,认证命令行请求disable_authentication = no #是否启用命令行请求需要认证,默认要认证realm = MySQL Fabricssl_ca = #使用ssl认证方式,指定PEM格式文件,包含信任SSL证书的列表ssl_cert = #SSL认证文件,用于创建安全的连接ssl_key = #SSL key文件[executor] #通过XML-RPC接收到的请求,映射到程序能立即执行或通过队列执行者,保证冲突的请求处理按序执行。 通常读操作立即执行通过XML-RPC会话线程,写操作通过执行者executors = 5 #多少线程用于执行者[logging] #设置Fabric日志信息记录到哪里,如果不是开启为后台进程,将打印日志到标准输出level = INFO #日志级别,支持DEBUG,INFO,WARNING,ERROR,CRITICALurl = file:///var/log/fabric.log #存储日志的文件,能为绝对或相对路径(如是相对路径,将参照default段logdir参数指定的日志目录)[sharding] #Fabric使用mysqldump和mysql客户端程序,执行移动和分离shards,指定程序的路径mysqldump_program = /usr/bin/mysqldumpmysqlclient_program = /usr/bin/mysql[statistics]prune_time = 3600 #删除大于1h的条目[failure_tracking] #连接器和其他外部实体能报告错误,fabric保持跟踪服务器健康状态和采取相应的行为, 如提升一个新的master,如果一个服务器时不稳定的,但不是master,将简单的标记为错误。notifications = 300 #多少次报告错误后,将标志服务器不可用notification_clients = 50 #多少不同源报告错误notification_interval = 60 #评估错误数的统计时间failover_interval = 0 #为了避免整个系统不可用,自上次提升间隔多少秒后,新master才能选取detections = 3 #为了缓解fabric,提供内建的错误检查,如果错误检查启动监控一个组, 需要连续尝试3(默认)次访问当前master都错误后,才能提升新master,detection_interval = 6 #连续检查之间的间隔时间detection_timeout = 1 #错误检查程序尝试连接到一个组中服务器的超时时间prune_time = 3600 #在错误日志中保留多久的错误信息[connector] #Fabric-aware连接器连接到Fabric,获取组、shards、服务器的信息,缓存结果到本地的时长,以提高性能。ttl = 1 #缓存生存时间,单位s,决定多长时间,连接器考虑一个信息从Fabric获取是有效的[client]password =
# mysqlfabric manage setup --param=storage.user=fabric --param=storage.password=fabric@123[INFO] 1409095183.577010 - MainThread - Initializing persister: user (fabric), server (172.17.0.49:3306), database (fabric).Finishing initial setup=======================Password for admin user is not yet set.Password for admin/xmlrpc:Repeat Password:Password set.
# mysql -ufabric -h172.17.0.49 -pfabric@123 -e "show tables from fabric";+-------------------+| Tables_in_fabric |+-------------------+| checkpoints | #存储程序执行信息,在crash后,能安全的恢复执行程序| error_log | #服务器错误报告信息| group_replication | #定义复制,global groups和分片组,主要用于shard splitting,moving和global updates| group_view || groups | #包含管理组信息| log || permissions | #包含权限信息,访问到不同fabric子系统,当前仅仅定义了core子系统| proc_view || role_permissions | #表关联的角色和权限| roles | #包含用户角色的信息| servers | #包含fabric管理的所有服务器信息| shard_maps | #包含名字和分片属性的映射| shard_ranges | #分片索引和使用映射分片key到分片| shard_tables | #所有分片的表| shards | #存储每个分片标识| user_roles || users | #标识用户有什么权限访问到不同子系统的功能+-------------------+
# mysqlfabric manage start[INFO] 1409095475.657850 - MainThread - Initializing persister: user (fabric), server (172.17.0.49:3306), database (fabric).[INFO] 1409095475.661201 - MainThread - Loading Services.[INFO] 1409095475.672051 - MainThread - Fabric node starting.[INFO] 1409095475.731098 - MainThread - Starting Executor.[INFO] 1409095475.731155 - MainThread - Setting 5 executor(s).[INFO] 1409095475.731395 - Executor-0 - Started.[INFO] 1409095475.731866 - Executor-1 - Started.[INFO] 1409095475.732208 - Executor-2 - Started.[INFO] 1409095475.732892 - Executor-3 - Started.[INFO] 1409095475.733379 - Executor-4 - Started.[INFO] 1409095475.733472 - MainThread - Executor started.[INFO] 1409095475.738050 - MainThread - Starting failure detector.[INFO] 1409095475.738533 - XML-RPC-Server - XML-RPC protocol server ('0.0.0.0', 32274) started.[INFO] 1409095475.738774 - XML-RPC-Server - Setting 5 XML-RPC session(s).[INFO] 1409095475.739004 - XML-RPC-Session-0 - Started XML-RPC-Session.[INFO] 1409095475.739263 - XML-RPC-Session-1 - Started XML-RPC-Session.[INFO] 1409095475.739442 - XML-RPC-Session-2 - Started XML-RPC-Session.[INFO] 1409095475.739922 - XML-RPC-Session-3 - Started XML-RPC-Session.[INFO] 1409095475.740434 - XML-RPC-Session-4 - Started XML-RPC-Session.
# netstat -ntlp|grep pythontcp 0 0 0.0.0.0:32274 0.0.0.0:* LISTEN 15713/python
# mysqlfabric manage stopPassword for admin: #输入xmlrpc的密码Command :{ success = Truereturn = Trueactivities =}
=======================================================
http://www.open-open.com/lib/view/open1427182819481.html#_label7
引子
最近在研究Web服务端负载均衡方面的技术,参考网上资料,总体思路可以分为如下几类:
1.应用服务器集群,典型的代表就是Nginx+Tomcat实现负载均衡;
2.数据库集群。
本文主要关注数据库集群。
实现思路
1.应用层解决方案
通过应用层对数据源做路由来实现读写分离,项目是SpringMVC+myBatis,SQL路由交给Spring,通过AOP或者Annotation由代码显示的控制Datasource。
优点是路由策略的扩展性和可控性较强。
缺点是耦合到Spring;需要加入控制代码。
2.中间件解决方案
通过mysql中间件做主从集群,Mysql Proxy、Amoeba、Atlas等中间件貌似都能符合需求。
优点是与应用层解耦。
缺点是增加一个服务维护的风险点,性能及稳定性待测试,需要支持代码强制主从和事务。
3.驱动解决方案
Mysql自带的ReplicationDriver提供主从库访问的驱动,是通过保持多个数据源的链接并根据ReadOnly True/False来选择数据源。相当于应用层解决方案的一个现有实现,扩展性更弱。并且貌似不能使用其他驱动。由于耦合较高暂不考虑。
三种实现思路关键技术
1.在应用层使用Spring对数据源做路由,关键字:Spring AOP;
2.增加中间代理层,Amoeba就属于这种情况,此外还有Mysql官方提供的Mysql Proxy;
3.在驱动层使用Mysql提供的主从库访问驱动,直接与数据库连接驱动耦合,扩展性弱,目前还未做原型尝试。
综合上述分析,考虑到需要与应用层解耦,现采用中间件解决方案,使用Amoeba做SQL路由,实现数据库读写分离。
既然选择使用Amoeba,让我们先了解什么是Amoeba?它能做什么?要怎么做?最后再看看它不能做什么。
Amoeba
Amoeba是什么
Amoeba(变形虫)项目,该开源框架于2008年开始发布一款Amoeba for Mysql软件。详细资料可参阅Amoeba官方文档(需FQ)。
Amoeba能做什么
Amoeba致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当SQL路由功能,专注于分布式数据库代理层 (Database Proxy)开发。座落与 Client、DB Server(s)之间,对客户端透明。具有负载均衡、高可用性、SQL过滤、读写分离、可路由相关的到目标数据库、可并发请求多台数据库合并结果。 通过Amoeba你能够完成多数据源的高可用、负载均衡、数据切片的功能。
Amoeba不能做什么
既然知道Amoeba能为我们解决什么问题,也要做到Amoeba不擅长的事情。这样在具体项目技术方案选择时,方能权衡考虑。Amoeba对于以下几点暂时无能为力:
1.目前还不支持事务;
2.暂时不支持存储过程,官方说近期会支持;
3.不适合从Amoeba导数据的场景或者对大数据量查询的query并不合适,比如一次请求返回10w以上甚至更多数据的场合;
4.暂时不支持分库分表,amoeba目前只做到分数据库实例,每个被切分的节点需要保持库表结构一致。
若实际项目中所需要的功能正式Amoeba的短板,建议使用Mysql Proxy作为中间件,或者在应用层通过程序控制数据源,手动实现数据库读写分离。
原型环境
1.服务器A
IP: 1XX.XX.XX.181
运行Mysql主数据库和Amoeba。
2.服务器B
IP: 1XX.XX.XX.182
运行Mysql从数据库。
3.服务器C
IP: 1XX.XX.XX.183
运行Mysql从数据库。
OS版本。
|
1
2
|
[root@chenllcentos ~]# cat /etc/redhat-release CentOS release 6.5 (Final) |
具体实现
Mysql数据库读写分离的具体实现主要包括两个部分配置,即数据主从复制和Amoeba代理,现分别进行介绍。
主从复制
为什么要进行主从复制呢,其实很容易理解,因为数据要同步啊。
查看服务器A是否已经安装Mysql数据库。
|
1
|
[root@chenllcentos ~]# rpm -aq | grep mysql |
若无消息显示,则进行Mysql安装,否则跳过此步骤。
|
1
|
yum install -y mysql-server mysql mysql-devel mysql-libs |
Mysql安装完毕,默认开机不启动Mysql服务。
|
1
2
|
[root@chenllcentos ~]# chkconfig --list | grep mysqldmysqld 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭 |
现在我们更改下配置,让Mysql开机启动。
|
1
2
3
|
[root@chenllcentos ~]# chkconfig mysqld on[root@chenllcentos ~]# chkconfig --list | grep mysqldmysqld 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭 |
接下来,设置Mysql账户密码。
|
1
|
[root@chenllcentos ~]# mysqladmin -u root password 'yourpassword' |
此时,可以用刚才设置的账户密码登陆数据库。
|
1
|
[root@chenllcentos ~]# mysql -uroot -pyourpassword |
至此,Mysql数据库安装成功。同样的,对服务器B和服务器C安装Mysql数据库,此处略去。接下来,开始进行数据库主从复制的配置。
1.主数据库配置
修改主数据库配置文件my.cnf。
|
1
|
[root@chenllcentos ~]# vi /etc/my.cnf |
新增如下标注内容:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
[mysqld]max_connections=1000binlog-ignore-db=mysql #新增binlog-ignore-db=information_schema #新增log-bin=mysql-bin #新增server-id=1 #新增datadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.sockuser=mysql# Disabling symbolic-links is recommended to prevent assorted security riskssymbolic-links=0[mysqld_safe]log-error=/var/log/mysqld.logpid-file=/var/run/mysqld/mysqld.pid |
关于新增的几项配置,有什么作用呢?其中binlog-ignore-db用来指定忽略同步的数据库,未指定的默认都进行主从复制。log-bin 指定数据库操作日志,主从复制的过程本质就是从数据库在主数据库读取该日志文件,并且再执行一次。server-id只要满足在数据库集群中不重复即可。
保存退出,重启Mysqld服务,使配置生效。额外提个原则,凡是修改到配置文件,最好都重启该配置相关的程序或服务。
|
1
2
3
|
[root@chenllcentos ~]# service mysqld restart停止 mysqld: [确定]正在启动 mysqld: [确定] |
登陆主数据库。
|
1
|
[root@chenllcentos ~]# mysql -uroot -pyourpassword |
查看主数据库master状态。
|
1
2
3
4
5
6
|
mysql> show master status\G*************************** 1. row *************************** File: mysql-bin.000015 Position: 106 Binlog_Do_DB: Binlog_Ignore_DB: mysql,information_schema |
可以看出,Binlog_Ignore_DB显示的信息就是刚才我们在配置文件所配置的信息。此外,还有两个重要的参数需要记下:mysql-bin.000015和106。从数据库就是根据这两个参数,完成主从复制,以达到数据同步的效果。
从数据库要读取主数据库日志文件,需要主数据开放授权用户。
|
1
2
|
mysql> GRANT REPLICATION SLAVE ON *.* to 'slave'@'1XX.XX.XX.182' identified by 'root'mysql> GRANT REPLICATION SLAVE ON *.* to 'slave1'@'1XX.XX.XX.183' identified by 'root' |
进行从数据库配置时,将使用到这两个授权用户。
出于数据安全性考虑,Mysql提供访问权限控制,若以主机的方式远程访问数据库,需要开启相应权限。
|
1
2
3
4
5
6
|
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'1XX.XX.XX.181' IDENTIFIED BY 'root' WITH GRANT OPTION;mysql> FLUSH PRIVILEGES;mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'1XX.XX.XX.182' IDENTIFIED BY 'root' WITH GRANT OPTION;mysql> FLUSH PRIVILEGES;mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'1XX.XX.XX.183' IDENTIFIED BY 'root' WITH GRANT OPTION;mysql> FLUSH PRIVILEGES; |
最后,还需要修改iptables,对数据库端口3306放行。
|
1
|
[root@chenllcentos ~]# vi /etc/sysconfig/iptables |
新增如下语句:
|
1
2
|
# 放行Mysql端口-A INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT |
至此,完成主数据库配置。接下来,让我们进行从数据库配置。
2.从数据库配置
从数据库配置相对主数据配置相对简单,主要包括配置文件修改和主从复制设置。现以服务器B为例进行说明。
修改从数据库配置文件。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[mysqld]max_connections=1000server-id=2 #新增datadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.sockuser=mysql# Disabling symbolic-links is recommended to prevent assorted security riskssymbolic-links=0[mysqld_safe]log-error=/var/log/mysqld.logpid-file=/var/run/mysqld/mysqld.pid |
设置主从数据库同步点。
|
1
|
mysql> change master to master_host='1XX.XX.XX.181',master_user='slave',master_password='root',master_log_file='mysql-bin.000015',master_log_pos=106; |
还记得mysql-bin.000015和106这两个参数吗?没错,就是我们在主数据库查看master状态所显示的信息。
启动主从复制。
|
1
|
mysql> slave start; |
查询slave状态。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
mysql> show slave status\G*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 1XX.XX.XX.181 Master_User: slave Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000015 Read_Master_Log_Pos: 106 Relay_Log_File: mysqld-relay-bin.000005 Relay_Log_Pos: 251 Relay_Master_Log_File: mysql-bin.000015 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 106 Relay_Log_Space: 758 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: |
只有当Slave_IO_Running和Slave_SQL_Running都显示Yes时,才表示主从复制配置成功。否则失败,检查上述配置过程。
服务器C从数据库的配置过程类似,此处略去。
主从复制验证
首先,在主数据建立一个demo数据库,看两个从数据库是否会自动进行复制。
在服务器A登录主数据库,查看现有数据库。
|
1
2
3
4
5
6
7
8
|
mysql> show databases;+--------------------+| Database |+--------------------+| information_schema || mysql || test |+--------------------+ |
现在,新增一个测试数据库demo。
|
1
|
mysql> create database demo; |
接下来,分别登录服务器B和服务器C的从数据库,查询数据库。
|
1
2
3
4
5
6
7
8
9
|
mysql> show databases;+--------------------+| Database |+--------------------+| information_schema || demo || mysql || test |+--------------------+ |
可以发现,当主数据库发生改动,从数据库会相应同步,并且同步的过程是异步进行的。因此,可以验证我们配置的主从复制已经生效。
Amoeba数据库代理
Amoeba作为数据库代理,以中间件的形式存在,拓扑图如下所示:
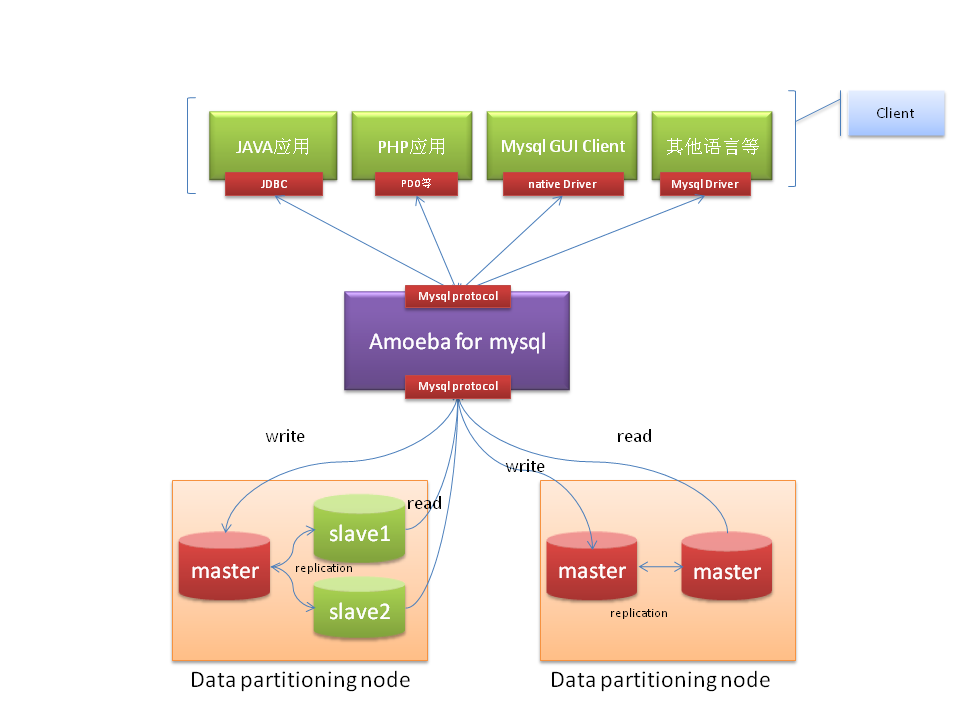 图片来源于Amoeba官网。
图片来源于Amoeba官网。
目前Amoeba for Mysql最新版本为amoeba-mysql-3.0.5-RC-distribution.zip。
安装过程很简单,只需要将zip压缩包解压至/usr/local/即可。若没有安装zip和unzip,可以通过centOS yum安装。
|
1
|
[root@chenllcentos ~]# yum -y install zip unzip |
接下来,解压Amoeba压缩包。
|
1
2
|
[root@chenllcentos ~]# unzip amoeba-mysql-3.0.5-RC-distribution.zip[root@chenllcentos ~]# cp -rf amoeba-mysql-3.0.5-RC /usr/local |
启动Amoeba。
|
1
|
[root@chenllcentos ~]# /usr/local/amoeba-mysql-3.0.5-RC/bin/launcher |
但是提示出现fatal exception:
|
1
2
3
|
The stack size specified is too small, Specify at least 228kError: Could not create the Java Virtual Machine.Error: A fatal exception has occurred. Program will exit. |
从错误文字上看,应该是由于stack size太小,导致JVM启动失败,要如何修改呢?
其实Amoeba已经考虑到这个问题,并将JVM参数配置写在属性文件里。现在,让我们通过该属性文件修改JVM参数。
修改jvm.properties文件JVM_OPTIONS参数。
|
1
|
[root@chenllcentos ~]# vi /usr/local/amoeba-mysql-3.0.5-RC/jvm.properties |
将内容:
|
1
|
JVM_OPTIONS="-server -Xms256m -Xmx1024m -Xss196k -XX:PermSize=16m -XX:MaxPermSize=96m" |
替换为:
|
1
|
JVM_OPTIONS="-server -Xms1024m -Xmx1024m -Xss256k -XX:PermSize=16m -XX:MaxPermSize=96m" |
再次启动Amoeba。
|
1
|
[root@chenllcentos ~]# /usr/local/amoeba-mysql-3.0.5-RC/bin/launcher |
若使用Amoeba完成读写分离,需要分别对dbServers.xml和amoeba.xml两个配置文件进行配置。与在应用层实现读写分离不同,使用Amoeba实现读写分离只需要修改配置文件,并不会产生硬编码耦合,有利于系统扩展和维护。
首先是配置dbServers.xml,主要是配置真实Mysql数据库连接信息。
|
1
|
<?xml version="1.0" encoding="gbk"?> |
<!DOCTYPE amoeba:dbServers SYSTEM “dbserver.dtd”> <amoeba:dbServers xmlns:amoeba=“http://amoeba.meidusa.com/”>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
<!-- Each dbServer needs to be configured into a Pool, If you need to configure multiple dbServer with load balancing that can be simplified by the following configuration: add attribute with name virtual = "true" in dbServer, but the configuration does not allow the element with name factoryConfig such as 'multiPool' dbServer --><!-- 该dbServer节点abstractive="true",包含Mysql的公共配置信息,其他dbServer节点都继承该节点 --><!-- 设置节点配置的继承结构,可以避免重复配置相同信息,减少配置文件冗余 --><dbServer name="abstractServer" abstractive="true"> <factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory"> <property name="connectionManager">${defaultManager}</property> <property name="sendBufferSize">64</property> <property name="receiveBufferSize">128</property> <!-- mysql port --> <!-- Mysql默认端口 --> <property name="port">3306</property> <!-- mysql schema --> <!-- 默认连接的数据库,若不存在需要事先创建,否则Amoeba启动报错 --> <property name="schema">test</property> <!-- mysql user --> <property name="user">root</property> <property name="password">root</property> </factoryConfig> <poolConfig class="com.meidusa.toolkit.common.poolable.PoolableObjectPool"> <property name="maxActive">500</property> <property name="maxIdle">500</property> <property name="minIdle">1</property> <property name="minEvictableIdleTimeMillis">600000</property> <property name="timeBetweenEvictionRunsMillis">600000</property> <property name="testOnBorrow">true</property> <property name="testOnReturn">true</property> <property name="testWhileIdle">true</property> </poolConfig></dbServer><!-- master节点继承abstractServer --><dbServer name="master" parent="abstractServer"> <factoryConfig> <!-- mysql ip --> <!-- master数据库主机地址 --> <property name="ipAddress">1XX.XX.XX.181</property> </factoryConfig></dbServer><!-- slave节点继承abstractServer --><dbServer name="slave" parent="abstractServer"> <factoryConfig> <!-- mysql ip --> <!-- slave数据库主机地址 --> <property name="ipAddress">1XX.XX.XX.182</property> </factoryConfig></dbServer><!-- slave1节点继承abstractServer --><dbServer name="slave1" parent="abstractServer"> <factoryConfig> <!-- mysql ip --> <!-- slave1数据库主机地址 --> <property name="ipAddress">1XX.XX.XX.183</property> </factoryConfig> </dbServer> |
1XX.XX.XX.181
1XX.XX.XX.185
|
1
2
3
4
5
6
7
8
9
10
|
<!-- 配置数据库读取连接池 --><dbServer name="readPool" virtual="true"> <poolConfig class="com.meidusa.amoeba.server.MultipleServerPool"> <!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA--> <property name="loadbalance">1</property> <!-- Separated by commas,such as: server1,server2,server1 --> <property name="poolNames">slave,slave1</property> </poolConfig></dbServer> |
</amoeba:dbServers>
可以看出,对dbServers.xml文件的配置,主要就是对dbServer节点的配置。其中,readPool节点需要特别注意,因为Amoeba实现读写分离就是根据它来实现。
接下来是amoeba.xml,主要是配置代理数据库连接信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
<?xml version="1.0" encoding="gbk"?><!DOCTYPE amoeba:configuration SYSTEM "amoeba.dtd"><amoeba:configuration xmlns:amoeba="http://amoeba.meidusa.com/"> <proxy> <!-- service class must implements com.meidusa.amoeba.service.Service --> <service name="Amoeba for Mysql" class="com.meidusa.amoeba.mysql.server.MySQLService"> <!-- port --> <property name="port">8066</property> <!-- bind ipAddress --> <!-- <property name="ipAddress">1XX.XX.XX.181</property> --> <property name="connectionFactory"> <bean class="com.meidusa.amoeba.mysql.net.MysqlClientConnectionFactory"> <property name="sendBufferSize">128</property> <property name="receiveBufferSize">64</property> </bean> </property> <property name="authenticateProvider"> <bean class="com.meidusa.amoeba.mysql.server.MysqlClientAuthenticator"> <property name="user">root</property> <property name="password">aroot</property> <property name="filter"> <bean class="com.meidusa.toolkit.net.authenticate.server.IPAccessController"> <property name="ipFile">${amoeba.home}/conf/access_list.conf</property> </bean> </property> </bean> </property> </service> <runtime class="com.meidusa.amoeba.mysql.context.MysqlRuntimeContext"> <!-- proxy server client process thread size --> <property name="executeThreadSize">128</property> <!-- per connection cache prepared statement size --> <property name="statementCacheSize">500</property> <!-- default charset --> <property name="serverCharset">utf8</property> <!-- query timeout( default: 60 second , TimeUnit:second) --> <property name="queryTimeout">60</property> </runtime> </proxy> <!-- Each ConnectionManager will start as thread manager responsible for the Connection IO read , Death Detection --> <connectionManagerList> <connectionManager name="defaultManager" class="com.meidusa.toolkit.net.MultiConnectionManagerWrapper"> <property name="subManagerClassName">com.meidusa.toolkit.net.AuthingableConnectionManager</property> </connectionManager> </connectionManagerList> <!-- default using file loader --> <dbServerLoader class="com.meidusa.amoeba.context.DBServerConfigFileLoader"> <property name="configFile">${amoeba.home}/conf/dbServers.xml</property> </dbServerLoader> <queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter"> <property name="ruleLoader"> <bean class="com.meidusa.amoeba.route.TableRuleFileLoader"> <property name="ruleFile">${amoeba.home}/conf/rule.xml</property> <property name="functionFile">${amoeba.home}/conf/ruleFunctionMap.xml</property> </bean> </property> <property name="sqlFunctionFile">${amoeba.home}/conf/functionMap.xml</property> <property name="LRUMapSize">1500</property> <property name="defaultPool">master</property> <property name="writePool">master</property> <property name="readPool">readPool</property> <property name="needParse">true</property> </queryRouter></amoeba:configuration> |
在amoeba.xml中,主要完成连接信息和SQL路由配置。在queryRouter节点中,通过配置writePool和readPool可以实现读写分离。
配置完成后,重启Amoeba。
|
1
2
|
[root@chenllcentos ~]# /usr/local/amoeba-mysql-3.0.5-RC/bin/shutdown[root@chenllcentos ~]# /usr/local/amoeba-mysql-3.0.5-RC/bin/launcher |
至此,Mysql主从复制和使用Amoeba实现数据库读写分离全部配置完成。
读写分离验证
接下来,进行简单测试,验证以上配置是否能够正确运行。
登录master主数据库。
|
1
|
[root@chenllcentos ~]# mysql -uroot -pyourpassword -h1XX.XX.XX.181 -P8066 |
额外说明下,此处的yourpassword是连接Amoeba的密码,也就是在amoeba.xml配置文件中配置的密码,与Mysql密码不同,需要注意。
登陆后,此时会提示以下信息。
|
1
|
Server version: 5.1.45-mysql-amoeba-proxy-3.0.4-BETA Source distribution |
说明已经成功连接Mysql代理Amoeba。
为了验证Amoeba读写分离配置是否生效,我们做一个简单的测试。
先在181服务器master服务器上创建一个表。
|
1
|
mysql> create table sxit (id int(10) ,name varchar(10)); |
而后,分别停止服务器B和服务器C两个从数据库的主从复制,便于数据库操作观察。
登陆服务器B从数据库。
|
1
|
[root@chenllcentos ~]# mysql -uroot -pyourpassword |
停止从数据库主从复制。
|
1
|
mysql> slave stop; |
登陆服务器C从数据库。
|
1
|
[root@chenllcentos ~]# mysql -uroot -pyourpassword |
停止从数据库主从复制。
|
1
|
mysql> slave stop; |
在主数据库插入。
|
1
|
mysql> insert into sxit values('1','zhangsan'); |
在从数据库B插入。
|
1
|
mysql> insert into sxit values('2','lisi'); |
在从数据库C插入。
|
1
|
mysql> insert into sxit values('3','john'); |
登陆到amoeba服务器,进行读写分离的测试:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@chenllcentos ~]# mysql -uroot -pyourpassword -h1XX.XX.XX.181 -P8066mysql> use test;mysql> select * from sxit;+------+------+| id | name |+------+------+| 2 | lisi |+------+------+mysql> select * from sxit;+------+------+| id | name |+------+------+| 3 | john |+------+------+ |
重复执行多次,发现始终只显示从数据库的数据,说明如果进行数据库读操作,Amoeba只将读数据SQL命令路由至从数据库。
登录主数据库。
|
1
2
3
4
5
6
7
8
|
[root@chenllcentos ~]# mysql -uroot -pyourpassword mysql> use test;mysql> select * from sxit;+------+----------+| id | name |+------+----------+| 1 | zhangsan |+------+----------+ |
可以验证,使用Amoeba对Mysql读写分离成功。若此时开启从数据库主从复制,则可以进行Mysql集群和负载均衡。
小结
使用Amoeba做数据库代理,对于应用层来说是透明的。所谓透明,可以这么简单理解,是否使用代理,在应用层编码上是没有任何区别的,即使用代理的情况下,应用层和数据层能够保持高度解耦。
用Amoeba构架MySQL分布式数据库环境
2009年01月16日
Amoeba是一个类似MySQL Proxy的分布式数据库中间代理层软件,是由陈思儒开发的一个开源的java项目。其主要功能包括读写分离,垂直分库,水平分库等,经过测试,发现其功能和稳定性都非常的不错,如果需要构架分布式数据库环境,采用Amoeba是一个不错的方案。目前Amoeba一共包括For aladdin,For MySQL和For Oracle三个版本,本文主要关注For MySQL版本的一个读写分离实现。实际上垂直切分和水平切分的架构也相差不大,改动几个配置就可以轻松实现。
下图是一个采用Amoeba的读写分离技术结合MySQL的Master-Slave Replication的一个分布式系统的架构:
Amoeba处于在应用和数据库之间,扮演一个中介的角色,将应用传递过来的SQL语句经过分析后,将写的语句交给Master库执行,将读的语句路由到Slave库执行(当然也可以到Master读,这个完全看配置)。Amoeba实现了简单的负载均衡(采用轮询算法)和Failover。如果配置了多个读的库,则任何一个读的库出现宕机,不会导致整个系统故障,Amoeba能自动将读请求路由到其他可用的库上,当然,写还是单点的依赖于Master数据库的,这个需要通过数据库的切换,或者水平分割等技术来提升Master库的可用性。
Amoeba可以在不同机器上启动多个,并且做同样的配置来进行水平扩展,以分担压力和提升可用性,可以将Amoeba和MySQL装在同一台机器,也可以装在不同的机器上,Amoeba本身不做数据缓存,所以对于内存消耗很少,主要是CPU占用。对于应用来说,图中的三个Amoeba就是三台一模一样的MySQL数据库,连接其中任何一台都是可以的,所以需要在应用端有一个Load balance和Failover的机制,需要连接数据库时从三台中随机挑选一台即可,如果其他任何一台出现故障,则可以自动Failover到剩余的可用机器上。MySQL的JDBC驱动从connector-j 3.17版本起已经提供了这样的负载均衡和故障切换的功能,那么剩下的事情对于应用来说就很简单了,不需要做太多的改动就能搭建一套高可用的MySQL分布式数据库环境,何乐而不为?
http://www.cnblogs.com/oshine/archive/2015/01/20/4235610.html
Cobar分布式数据库的应用与实践
最新文章:看我如何快速学习.Net(高可用数据采集平台)、高并发数据采集的架构应用(Redis的应用)
问题点:
随着项目的增长,数据和数据表也成倍的增长,普通的单点数据库已经无法满足日常的增长的需要。为了能够给开发者提供透明化的数据库应用,也为了有益于项目的扩展、维护和应用,迫切需要分布式数据库的解决方案。
解决方案:
1. Mysql Cluster :Mysql官方提供分布式集群的解决方案之一、具有较强的权威性。
2. Cobar: Taobao提供的分布式数据库的解决方案,经过一定的实践证明、简单易用,并且可以自定义分割算法。
3. 爱可生: MySQL分布式集群服务框架, 国内领先的开源数据库软件、数据平台整体解决方案和服务提供商。
4. Percona XtraDB Cluster 5.6: Percona提供,基于Mysql的另一分支优化过的数据库集群的解决方案。
5. 以及其它分布式数据库解决方案: 新浪、MySQL federated 引擎、Amoeba等。
基于以上较多的分布式解决方案,还是选择了淘宝的Cobar、开源而且经过实践证明已经足够满足日常的需要。
配置和应用:
1.下载 :https://github.com/alibaba/cobar/wiki
2. 安装:1). Cobar是基于Java开发的分布式数据库应用,所以安装Cobar首先要安装JAVA JRE。
2). 解压,拷贝过去,运行startup.sh即可。
3.配置:
1)Server.xml 服务器配置
<user name="mysql"> <property name="password">mysql</property> <property name="schemas">data_acquisition_server</property> </user>连接用户名、密码配置,客户端连接登入验证。schemas 主要对应schema.xml的定义。
2) Schema.xml 数据节点、数据表拆分配置
<!-- schema定义 --> <schema name="data_acquisition_server" dataNode="dnDataAcquisitionMaster"> <table name="task" dataNode="dnDataAcquisitionChunk1,dnDataAcquisitionChunk2" rule="rule1" /> <table name="task_upload" dataNode="dnDataAcquisitionChunk1,dnDataAcquisitionChunk2" rule="rule1" /> <table name="task_source" dataNode="dnDataAcquisitionChunk1,dnDataAcquisitionChunk2" rule="rule1" /> </schema> <!-- 数据节点定义,数据节点由数据源和其他一些参数组织而成。--> <dataNode name="dnDataAcquisitionMaster"> <property name="dataSource"> <dataSourceRef>dsServer[0]</dataSourceRef> </property> </dataNode> <dataNode name="dnDataAcquisitionChunk1"> <property name="dataSource"> <dataSourceRef>dsServer[1]</dataSourceRef> </property> </dataNode> <dataNode name="dnDataAcquisitionChunk2"> <property name="dataSource"> <dataSourceRef>dsServer[2]</dataSourceRef> </property> </dataNode> <!-- 数据源定义,数据源是一个具体的后端数据连接的表示。--> <dataSource name="dsServer" type="mysql"> <property name="location"> <location>127.0.0.1:3306/db_data_acquisition_master</location> <location>127.0.0.1:3306/db_data_acquisition_chunk1</location> <location>127.0.0.1:3306/db_data_acquisition_chunk2</location> </property> <property name="user">root</property> <property name="password">123456</property> <property name="sqlMode">STRICT_TRANS_TABLES</property> </dataSource>3) Rule.xml 数据拆分算法配置
<!-- 路由规则定义,定义什么表,什么字段,采用什么路由算法 --> <tableRule name="rule1"> <rule> <columns>id</columns> <algorithm><![CDATA[ func1(${id}) ]]></algorithm> </rule> </tableRule> <!-- 路由函数定义 --> <function name="func1" class="com.alibaba.cobar.route.function.PartitionByLong"> <property name="partitionCount">2</property> <property name="partitionLength">512</property> </function>
4) 数据表创建
数据库:db_data_acquisition_master、db_data_acquisition_chunk1、db_data_acquisition_chunk2
数据表:1)db_data_acquisition_chunk1:task、task_source、task_upload
2)db_data_acquisition_chunk2:task、task_source、task_upload
当前的拆分规则、所有的表必需要有id但不能是自增长的。
4 客户端连接
可以使用任一Mysql连接工具进行连接,端口号为:8066

总结:
现在的技术感觉越做越薄,多关注开源的解决方案,却成为必要的一项工作技能了。
出处:http://www.cnblogs.com/oshine/
本作品由oShine.Q 创作, 欢迎转载,但任何转载必须保留完整文章,在显要地方显示署名以及原文链接。如您有任何疑问,请给我留言。
Galera replication for MySQL
这篇文章总结了之前对Galera replication的调研,内容包括Galera特性,原理,Galera cluster配置,参数及性能等
Galera replication是什么
MySQL DBA及开发应该都知道MySQL源生复制及semi-sync半同步复制,它们都基于MySQL binlog,原生复制是完全异步的,master不需要保证slave接收并执行了binlog,能够保证master最大性能,但是slave可能存在延迟,主备数据无法保证一致性,在不停服务的前提下如果master宕机让slave顶上,就会丢失数据,semi-sync在异步复制基础上增加了数据保护的考虑,master必须确认slave收到binlog后(但不保证slave执行了事务)才能最终提交事务,在没有退化(延迟较大时可能发生)成异步复制之前可以保证数据安全,此时master挂掉之后,slave可以在apply完所有relay log后切换成master提供读写服务
Galera replication是codership提供的MySQL数据同步方案,具有高可用,易于扩展等特点,它将多个MySQL节点组织成一个cluster
Galera replication特性
1. 同步复制,主备无延迟
2. 支持多主同时读写,保证数据一致性
3. 集群中各节点保存全量数据
4. 节点添加/删除,自动检测和配置
5. 行级别并行复制
6. 不需要写binlog
相对于MySQL源生复制和semi-sync,Galera replication比较有吸引力的特性:
1. 同步复制,主备无延迟,master宕机后slave可以立即顶上并提供服务(semi-sync需要apply完所有relay log)
2. 事务冲突检测保证数据一致性,多个节点可以同时读写数据,可以极大简化数据访问
3. 行级别并行复制,MySQL 5.6之前slave sql线程只有一个,这个长期饱受诟病,是导致slave落后master的主要原因
Galera replicateion限制
1. 集群至少3个节点(2个节点也可以运行)
2. 存储引擎:Innodb / XtraDB / Maria
3. 不支持的SQL:LOCK / UNLOCK TABLES / GET_LOCK(), RELEASE_LOCK()…
4. 不支持XA Transaction
目前可用的产品:MariaDB Galera Cluster 和 Percona XtraDB Cluster
Galera replication原理
Galera replication是一种Certification based replication,保证one-copy serializability,理论基于这两篇论文:Don’t be lazy, be consistent 和 Database State Machine Approach
算法示意图
图片来自上面两篇论文
算法伪代码(Certification包含了后续流程,来自上面两篇论文)

事务执行协议
遵守deferred update replication,事务在commit时才复制到其他节点,执行过程分为4个阶段:
1.Local read phase
a) 本地(client连接到的节点)执行事务Ti,但不真正提交,真正提交之前进入Send phase
2.Send phase
a) 若事务只读,直接提交,结束(多版本,只读事务不加锁)
b) 将事务的写操作封装成WS(Write Set,基于行),广播到所有节点(包括自身)
3.Lock / Certificaion phase
a) 对收到的WS中的每个WSi(X)
i. 若X没有被加锁,对X加锁
ii. 若X已被Tj加锁且Tj处于Local read phase/Send phase,回滚Tj,对X加锁
iii. Certification based conflict detect
4.Write phase
a) 若检测出冲突,回滚Ti
b) 否则,执行WS,提交事务后释放锁资源
c) 对于源节点,提交事务并向client返回结果
|
客户端/Galera节点信息交互图
Galera replication采取的是乐观策略,即事务在一个节点提交时,被认为与其他节点上的事务没有冲突,首先在本地“执行”(之所以带引号,是因为事务没有执行完)后再发送到所有节点做冲突检测,存在两种情况下需要回滚事务:
1. WS复制到其它节点,被加到每个节点的slave trx queue中,与queue中前面的trxs在做certification test时发现冲突
2. WS通过了certification test后被保证一定会执行,在它执行过程中,如果该节点上有与其冲突的local trxs(Local phase),回滚local trxs
Galera提供了两个状态参数记录冲突:
wsrep_local_cert_failures:certification test中未通过的trx数目
wsrep_local_bf_aborts:apply trxs(已经通过certification test)时,回滚的local trxs(open but not commit)数目
因此事务在commit节点广播后,节点之间不交换“是否冲突”的信息,各个节点独立异步的处理该事务,certification based replication协议保证:
1. 事务在所有节点上要么都commit,要么都rollback/abort
2. 事务在所有节点的执行顺序一致
Certification based replication所依赖的基础技术:
Group Communication System
1) Atomic delivery (事务传输要么成功传给了所有节点,要么都失败)
2) Total order (事务在所有节点中的顺序一致)
3) Group maintenance (每个节点知道所有节点的状态)
传统的2PC(两阶段提交)做法
1. 2PC 事务结束时,所有节点数据达到一致
2. 协调者与参与者之间通信,参与者之间无连接
3. 受网络状态影响较大
4. 两次通信,需要得到每个参与者的反馈后才能决定是否提交事务
因此Galera replicateion相对于2PC减少了网络传输次数,消除了等待节点返回“决定是否冲突”的时间,从而可以提高了性能
Galera replication原理总结
1. 事务在本地节点执行时采取乐观策略,成功广播到所有节点后再做冲突检测
2. 检测出冲突时,本地事务优先被回滚
3. 每个节点独立、异步执行队列中的WS
4. 事务T在A节点执行成功返回客户端后,其他节点保证T一定会被执行,因此有可能存在延迟,即虚拟同步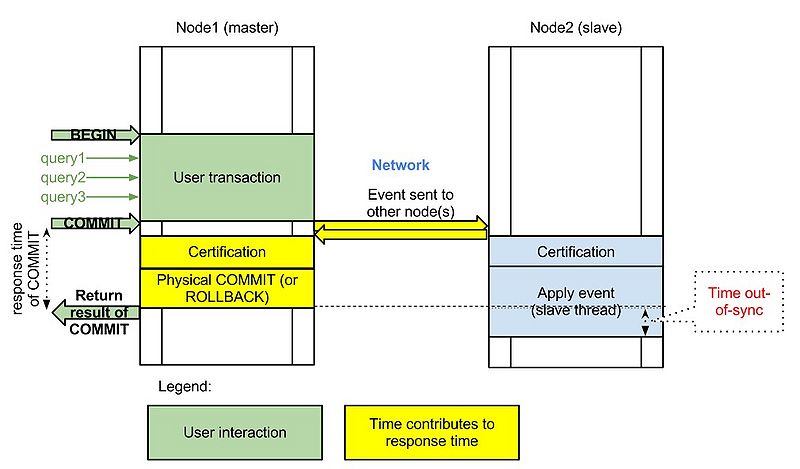
Galera flow control
galera是同步复制(虚拟同步)方案,事务在本地节点(客户端提交事务的节点)上提交成功时,其它节点保证执行该事务。在提交事务时,本地节点把事务复制到所有节点后,之后各个节点独立异步地进行certification test、事务插入待执行队列、执行事务。然而由于不同节点之间执行事务的速度不一样,长时间运行后,慢节点的待执行队列可能会越积越长,最终可能导致事务丢失。
galera内部实现了flow control,作用就是协调各个节点,保证所有节点执行事务的速度大于队列增长速度,从而避免丢失事务。实现原理和简单:整个galera cluster中,同时只有一个节点可以广播消息(数据),每个节点都会获得广播消息的机会(获得机会后也可以不广播),当慢节点的待执行队列超过一定长度后,它会广播一个FC_PAUSE消息,所以节点收到消息后都会暂缓广播消息,直到该慢节点的待执行队列长度减小到一定长度后,galera cluster数据同步又开始恢复
flow control相关参数:
gcs.fc_limit:待执行队列长度超过该值时,flow control被触发,对于Master-Slave模式(只在一个节点写)的galera cluster,可以配置一个较大的值,对启动多写的galera cluster,较小的值比较合适,因为较大待执行队列长度意味着更大的冲突,默认值16
gcs.fc_factor:当待执行队列长度开始小于(gcs.fc_factor*gcs.fc_limit)时,数据同步恢复,默认0.5
gcs.fc_master_slave:galera cluster是否为Master-Slave模式,默认
安装MariaDB Galera Cluster
安装准备:
1. MariaDB Galera Cluster 5.5.28a RC
1) https://downloads.mariadb.org/mariadb-galera/5.5.28a/
2) patched MariaDB 5.5.28,代码中增加了Galera Library API(wsrep API),并在事务、锁、handler等模块添加/修改了调用逻辑
2. Galera wsrep provider
1) https://launchpad.net/galera/+download
2) Galera Library的实现,其中实现了group communication system, certification
编译安装
1. MariaDB Galera Cluster 5.5.28a RC
1) 与MariaDB基本相同,cmake时增加两项:-DWITH_WSREP=ON , -DWITH_INNODB_DISALLOW_WRITES=1.
2. Galera wsrep provider: 源码编译后得到libgalera_smm.so(需要用到scons)
参数配置(每个节点)
wsrep_provider = /path/to/libgalera_smm.so
wsrep_cluster_address = cluster connection URL(后面详细介绍)
binlog_format = ROW
default_storage_engine = INNODB
innodb_autoinc_lock_mode = 2
innodb_locks_unsafe_for_binlog = 1
选配:(可以提高性能,galera保证不丢数据)
innodb_flush_log_at_trx_commit = 2
构建集群(三个节点)
| 节点名称 | IP地址 |
|---|---|
| galera_node1 | 10.0.0.11 |
| galera_node2 | 10.0.0.22 |
| galera_node3 | 10.0.0.33 |
新建Galera Cluster
以galera_node1作为第一个节点新建集群,在my.cnf中配置参数:
wsrep_cluster_address = gcomm:// wsrep_cluster_name = galera_cluster wsrep_node_address = 10.0.0.11 wsrep_node_name = galera_node1 wsrep_sst_method = rsync |
添加galera_node2节点
在my.cnf中配置wsrep_cluster_address为node1的ip或者hostname
wsrep_cluster_address = gcomm://10.0.0.11 wsrep_cluster_name = galera_cluster wsrep_node_address = 10.0.0.22 wsrep_node_name = galera_node2 wsrep_sst_method = rsync |
添加galera_node3节点
在my.cnf中配置wsrep_cluster_address为node1的ip或者hostname
wsrep_cluster_address = gcomm://10.0.0.11 wsrep_cluster_name = galera_cluster wsrep_node_address = 10.0.0.33 wsrep_node_name = galera_node3 wsrep_sst_method = rsync |
多实例配置
因为测试机器资源有限,需要在同一台机器上启动多个mysqld实例,为每个mysqld配置两个端口号(一个是mysql server端口号,默认3306;另外一个是wsrep端口号,默认4567),并修改部分wsrep配置参数,例如:
| 节点名称 | IP地址 | SERVER PORT | WSREP PORT | WSREP配置 |
|---|---|---|---|---|
| galera_node1 | 127.0.0.1 | 3306 | 4405 | wsrep_cluster_address=gcomm:// wsrep_node_address=127.0.0.1:4405 port=3306 |
| galera_node2 | 127.0.0.1 | 3307 | 4407 | wsrep_cluster_address=gcomm://127.0.0.1:4405 wsrep_node_address=127.0.0.1:4407 port=3307 |
| galera_node3 | 127.0.0.1 | 308 | 4409 | wsrep_cluster_addres=gcomm:// 127.0.0.1:4405 wsrep_node_address=127.0.0.1:4409 port=3308 |
启动后在每个节点执行:
mysql> show status like ‘wsrep%’; |
当看到下述状态时:
wsrep_connected=ON wsrep_ready=ON wsrep_cluster_status =Primary wsrep_cluster_size=3(节点个数) |
则galera集群建立成功,如下图所示:
说明:
1. MariaDB Galera Cluster 5.5.28a RC源码安装,在编译时若没有打开-DWITH_WSREP=ON, -DWITH_INNODB_DISALLOW_WRITES=1,或者没有配置任何wsrep相关参数,它运行时就是一个普通的mysqld实例
2. Galera cluster复制不依赖于binlog文件,因此mysql-binlog和log-slave-updates都可以不配置,当然如果需要记录binlog,也可以打开
3. 需要以wsrep_cluster_address = gcomm://启动第一个节点后,才能相继添加其他节点
Galera相关参数配置
InnoDB 相关参数
galera补丁版的mysql在cmake时需要指定:
-DWITH_WSREP=ON , -DWITH_INNODB_DISALLOW_WRITES=1
galera 目前只支持Innodb/xtradb/mariad存储引擎
default_storage_engine = INNODB
为了降低冲突,下列两项需要设置
innodb_autoinc_lock_mode = 2
innodb_locks_unsafe_for_binlog = 1(gap不加锁)
选配:(可以提高性能,galera保证不丢数据)
innodb_flush_log_at_trx_commit = 2
选配:galera可以不写binlog,注释binlog路径理论上可以提高性能
#log-bin
#log-slave-updates=1
wsrep 相关参数
wsrep参数都是以wsrep_开头的(30+个),其中有一个字符串参数(wsrep_provider_options)可以配置50+个更底层的参数。
可以通过“show variables like wsrep%”查看,wsrep_开头参数,点击查看详情
列举几个重要的参数:
wsrep_auto_increment_control:控制auto_increment_increment=#nodes和auto_increment_offset=#node_id,默认ON wsrep_causal_reads:默认是在本地节点读,读到的可能不是最新数据,开启后将读到最新数据,但会增加响应时间,默认OFF wsrep_certify_nonPK:为没有显示申明主键的表生成一个用于certification test的主键,默认ON wsrep_cluster_address: 启动节点时需要指定galera cluster的地址,作为cluster中第一个启动的节点,wsrep_cluster_address=gcomm://,对于后续启动的节点,wsrep_cluster_address=gcomm://node1,node2,node3 wsrep_cluster_name: 所有node必须一样, 默认my_test_cluster wsrep_convert_LOCK_to_trx:将LOCK/UNLOCK TABLES转换成BEGIN/COMMIT,默认OFF wsrep_data_home_dir:galera会生成一些文件,默认使用mysql_data_dir,默认mysql_data_dir wsrep_node_name:节点名称 wsrep_on:session/global,设置为OFF时,事务将不会复制到其他节点,默认ON wsrep_OSU_method:Online Schema Update设置,TOI/RSU(MySQL >= 5.5.17),默认TOI wsrep_provider:libgalera_smm.so的路径,若没有配置,galera复制不会启动,默认none wsrep_provider_options:很长的字符串变量,可以配置很多group communication system相关参数,很长很长... wsrep_retry_autocommit:事务在冲突时重新尝试的次数,默认1 wsrep_slave_threads:并行复制的slave线程数,默认4 wsrep_sst_method:Snapshot State Transter方法:mysqldump/rsync/xt,默认mysqldump |
wsrep_provider_options
该参数是一个字符串,包含了group communication system中很多参数设置,配置时使用分号隔开:
wsrep_provider_options=”key_a=value_a;key_b=value_b;key_c=value_c”,点击查看详情
列举其中部分重要参数:
evs.send_window:节点一次可以发送的消息数目,默认4 evs.user_send_window:其与evs.send_window之间的差别类似于max_connections与max_user_connection,默认2 gcs.fc_factor:flow control参数,默认0.5 gcs.fc_limit:flow control参数,默认16 gcs.fc_master_slave:flow control参数,默认NO gcs.recv_q_hard_limit:接收队列的占用的最大内存,默认LLONG_MAX gcs.recv_q_soft_limit:当接收队列占用内存超过(gcs.recv_q_hard_limit*gcs.recv_q_soft_limit),复制被延迟,默认0.25 gmcast.listen_addr:节点用于接收其它节点消息的地址,默认tcp://0.0.0.0:4567 pc.checksum:是否对发送的消息做checksum,默认true pc.ignore_sb:是否忽略split brain,默认false |
一个例子
binlog_format=row default-storage-engine = INNODB innodb_autoinc_lock_mode = 2 innodb_locks_unsafe_for_binlog = 1 wsrep_provider = /u01/mariadb-galera/lib/libgalera_smm.so wsrep_cluster_address = "gcomm://192.168.xxx.01" wsrep_cluster_name = galera wsrep_node_address = 192.168.xxx.xxx wsrep_node_name = slave wsrep_sst_method = rsync wsrep_slave_threads = 16 wsrep_provider_options="gcache.page_size=128M;gcache.size=2G;gcs.fc_limit=512;gcs.fc_factor=0.9;evs.send_window=256;evs.user_send_window=128" |
Galera status variables
Galera提供了很多以wsrep_开头状态参数监控mysql状态,通过show status like ‘wsrep%’可以查看:
wsrep_local_state_uuid:应该与wsrep_cluster_state_uuid一致,如363acc29-9160-11e2-0800-4316271a76e4 wsrep_last_committed:已经提交事务数目,所有节点之间相差不大,可以用来计算延迟 wsrep_replicated:从本地节点复制出去的write set数目 wsrep_replicated_bytes:从本地节点复制出去的write set的总共字节数 wsrep_received:本地节点接收来自其他节点的write set数目 wsrep_received_bytes:本地节点接收来自其他节点的write set的总共字节数 wsrep_local_commits:从本地节点发出的write set被提交的数目,不超过wsrep_replicated wsrep_local_cert_failures:certification test失败的数目 wsrep_local_bf_aborts:certification test通过的write set执行过程中回滚的与其冲突的本地事务 wsrep_local_replays:事务被回滚(bf abort)重做的数目 wsrep_local_send_queue:发送队列的长度 wsrep_local_send_queue_avg:从上次查询状态到目前发送队列的平均长度,>0.0意味着复制过程被节流了 wsrep_local_recv_queue:接收队列的长度 wsrep_local_recv_queue_avg:从上次查询状态到目前接收队列的平均长度,>0.0意味着执行速度小于接收速度 wsrep_flow_control_paused:从上次查询状态到目前处于flow control的时间占比,如0.388129 wsrep_flow_control_sent:从上次查询状态到目前节点发送出的FC_PAUSE消息数目,如1 wsrep_flow_control_recv:从上次查询状态到目前及节点接收的FC_PAUSE消息数目,如1 wsrep_cert_deps_distance:可以并行执行的write set的最大seqno与最小seqno之间的平均差值,如1851.825751 wsrep_apply_oooe:队列中事务并发执行占比,值越高意味着效率越高 wsrep_commit_window:平均并发提交窗口大小 wsrep_local_state:节点的状态,取值1-6 wsrep_local_state_comment:节点的状态描述,比如Synced wsrep_incoming_addresses:集群中其它节点的地址,多个地址之间用逗号分隔 wsrep_cluster_conf_id:集群节点关系改变的次数(每次增加/删除都会+1) wsrep_cluster_size:集群节点个数 wsrep_cluster_state_uuid:集群uuid,所有节点应该一样,如:363acc29-9160-11e2-0800-4316271a76e4 wsrep_cluster_status:集群的目前状态,取值:PRIMARY(正常)/NON_PRIMARY(不一致) wsrep_connected:节点是否连接到集群,取值:ON/OFF wsrep_local_index:节点id wsrep_provider_name:默认Galera wsrep_provider_vendor:默认Codership Oy <info@codership.com> wsrep_provider_version:wsrep版本,如:2.2(rXXXX) wsrep_ready:节点是否可以接受查询了,取值:ON/OFF |
一个截图:
如何检查节点是否加入到集群
1. wsrep_cluster_state_uuid应该与其它所有节点相同
2. wsrep_cluster_conf_id应该与其它所有节点相同
3. wsrep_cluster_size应该是所有节点的数目
4. wsrep_cluster_status取值应该是:Primary
5. wsrep_ready取值应该是ON
6. wsrep_connected取值应该是ON
判断复制过程是否出现问题
wsrep_flow_control_paused,正常情况下,其取值应该接近于0.0,大于0.0意味着有‘慢节点’影响了集群的速度,可以尝试通过增大wsrep_slave_threads来解决
找出最慢的节点
wsrep_flow_control_sent,wsrep_local_recv_queue_avg两个值最大的节点
参考:galera status,galera monitoring
性能测试
由于galera同步复制在每个写事务提交时都增加了replicate trx和certification test的开销,因此性能远远低于异步MySQL实例
测试场景
使用TPCC进行测试,包含3组数据:
1、normal mysql: baseline,单个mysql server
2、galera (RTT: 0.5ms): 2-nodes galera cluster,单节点读写
3、galera (RTT: 15.2ms): 2-nodes galera cluster,单节点读写
tpmC结果: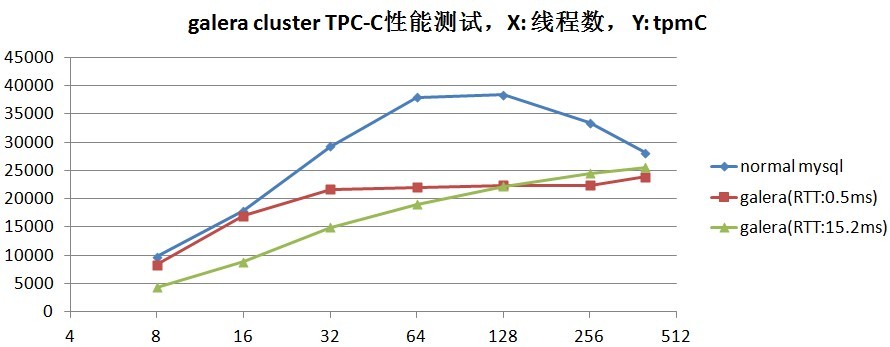
TPS结果: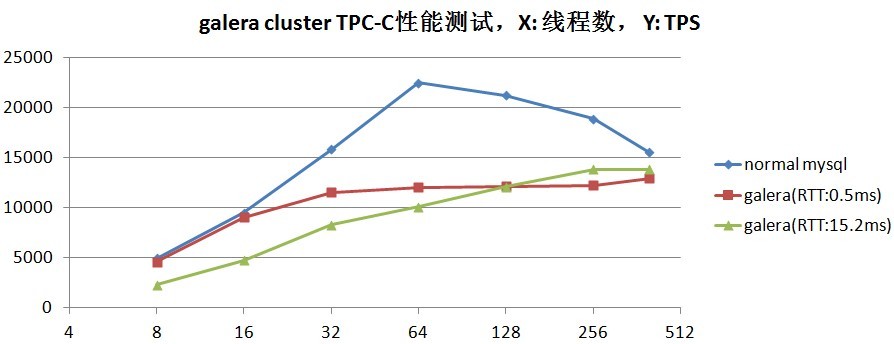
测试结论:
1. 相对于异步MySQL实例,Galera replication性能下降约50% ~ 60%左右
2. Galera最大性能不受RTT影响,RTT 较小时(0.5ms),在达到最大性能之前(32并发),性能下降并不明显 (32并发下降25%,16并发性能下降更低),RTT较大时(15.2ms),在达到最大性能之前(64并发),相对于norml mysq性能下降一直到很明显,当压力逐渐增大,由于group io的原因,galera性能在达到最大时还会提高
Galera replication for MySQL学习资料
1. codership官网
2. mysqlperformanceblog搜索中PXC(Percona XtraDB Cluster)
percona XtraDB Cluster介绍及使用(一)
http://www.percona.com/software/percona-xtradb-cluster #software
http://www.percona.com/doc/percona-xtradb-cluster/5.6/ #refernce page
http://dev.mysql.com/doc/relnotes/mysql/5.6/en/index.html #5.6 relaese notes
https://launchpad.net/percona-xtradb-cluster #bug跟踪
http://galeracluster.com/documentation-webpages/index.html #galera cluster ref doc.
http://galeracluster.com/documentation-webpages/limitations.html #与MySQL Server的不同
FAQ:
1.为什么使用xtradb cluster?
node节点之间数据强同步,不用做后期的数据校验;内置故障切换功能,可以逐步摆脱mha相关的第三方工具依赖;由于数据强一致性的保证,业务不适合做写敏感的架构, 少写多读会得到很好的扩展;公网+encrption可以做到多数据中心的数据同步,适合后期业务的多节点部署;
2.为什么使用5.6版本?
oracle官方在5.5系列中做出了很大的代价来保证基础功能的稳定,5.6逐步增加许多额外的扩展功能,如slave自动同步,buffer pool dump/restore, 内置memcache,fulltext等。 使用5.6可以做到最终业务的版本统一。
3.xtradb cluster和Oracle MySQL有什么不同?
全部兼容MySQL Server,也可以从Percona MySQL Server升级到Xtradb cluster。两个鲜明的特征包括数据同步和故障恢复。
xtradb cluster主要不同于MySQL包括以下几方面:
1. 节点之间的复制(replication)仅支持InnoDB引擎, 其它类型的write不会复制(包括mysql.*表),DDL语句以statement级别复制,即意味着create user ... 和 grant ...可以复制,但是insert into mysql.user .... 不会被复制。 2. 没有主键的表在各节点可能以不同的顺序显示出来,比如select ... limit..., DELETE操作在没有主键的表中不被支持。不要使用没有主键的表(也可能基于row格式的复制) 3. 不要开启 query cache(默认关闭); 4. 由于commit的时候可能会回滚(rollback), 不支持XA事务; 5. 事务大小, Galera Cluster没有限制事务大小, 为了避免大事务(比如LOAD DATA)对节点的影响, wsrep_max_ws_rows和wsrep_max_ws_size限制了事务行数为128K,事务大小1GB。 6. 基于集群级别的并发控制, 一个事务的提交可能会被取消掉。 7. 不支持Windows系统. 8. 不要使用binlog-do-db和binlog-ignore-db, 这些选项仅支持DML语句, 不支持DDL语句, 使用这些选项可能会引起数据的错乱。 9. 如果选择rsync方式传输, 就不要指定character_set_server为utf16, utf32或ucs2字符集, Server可能会崩溃.
一. percona XtraDB Cluster 术语说明
LSN: 每个InnoDB page(通常16kb大小)含有一个日志序列(log sequence number),称作LSN。LSN是整个database的系统版本号。每个page的LSN表示了最近该页的变动(change)。
GTID: Global transaction id. 在XtraDB中GTID由UUID和一个用来标识顺序更改的序列数字组成.
UUID: 全局唯一标识,唯一标识了状态和节点的序列改变.
HAProxy: 一个基于TCP和HTTP协议的应用,用来提供快速,稳定的高可用服务,包括负载均衡,代理协议等。
Primary Component: 如果一个单节点失效, cluster可能会因为网络的原因分裂成多个部分。在这种状况下,仅有一个部分可以持续修改数据库的状态以避免引起分歧,该部分则成为Primary Component(PC),
SST: State Snapshot Transfer. 状态(数据)快照传输,全量的从一个node传输到另一个node. 当一个新node加入Cluster的时候, 必须从已有的node传输数据到新node. SST传输方式有三种: mysqldump, rsync, xtrabackup.前两种传输时会锁表, xtrabackup仅在传输系统表的时候锁表.
IST: Incremental State Transfer. 用来替代SST传输数据的方式, 只有在写集(writeset)还存在于donor的writeset cache中时,IST才可以抓取批量收到的writeset.
donor node: 被选举为提供状态传输(SST或IST)的节点。
Xtrabackup: 支持MySQL热备的开源工具, 备份InnoDB期间不会加锁, 该工具由percona公司开发。
cluster replication: 为cluster members提供的正常replication, 能以单播或多播的方式进行加密。
joiner node: 要加入到cluster中的node, 通常也是状态传输的目标。
node:一个集群的节点就是一个处于集群中的MySQL实例。
quorum: 多数节点( > 50%), 在一个网络区域中, 只有cluster保持有quorum, 并且quorum中的node默认处于Primary状态。
primary cluster: 一个持有quorum的cluster. 一个non-primary集群不会允许任何操作,并且任何试图read或write的client端都会返回’Unknown command error’错误。
split brain: 当集群中的两部分(part)不能连接,一部分(one part)确信另一个部分(the other part)不在运行的时候则发生分裂(splite brain), 这种情况会造成数据不一致。
.opt: MySQL在每个database中都有一个.opt后缀的文件保存该database的选项信息(比如charset, collation).
二. percona XtraDB Cluster生成文件说明
GRA_x.log:在row格式下执行失败的事务(比如drop一个不存在的表等),这些文件保存了这些事务的binlog events。该功能禁止了slave thread应用这些执行失败的事务。warning或error信息会在mysql error log中显示。比如在一个node中drop不存在的表, 其他node会生成GRA_x.log文件,error log中也会显示一下信息:
Jun 5 11:34:42 cz-test2 mysqld-3321: 2014-06-05 11:34:42 26423 [ERROR] Slave SQL: Error 'Unknown table 'percona.list'' on query. Default database: 'percona'. Query: 'drop table list', Error_code: 1051
galera.cache: 该文件存储主要的写集(writeset), 被实现为一个永久的环路缓冲区(ring-buffer),在node初始化的时候,它被用来在磁盘上预分配空间,默认128M, 这个值过大的话,更多的写集会被缓冲, 而且重新加入的的节点(rejoining node)更倾向于采用IST来取代SST传输数据。
grastate.dat:保存了Galera的状态信息。
三. Percona XtraDB Cluster 如何保证写一致性(consistency of writes)
所有的query在本地node执行, 并且仅在commit存在特殊的处理。当commit有问题时, 事务必须在所有node验证, 没有验证通过则返回error信息. 随后,事务被应用到本地node。
commit响应时间包括:
网络轮询时间; 验证时间; 本地应用;(远程apply事务不影响commit响应时间)。
两个重要的特性:
1. 控制wsrep_slave_threads参数来实现多并发replication. 2. 一些其它因素,比如master的性能更好,执行事件要比slave快,这就造成了短暂的同步不一致(out-of-sync),这时候读取slave结果就为空, wsrep_causal_reads参数用来控制读取slave的行为,它使得操作一直等待直到事件被执行;
四. 监控
1. cluster完整性检测
status 变量:
wsrep_cluster_state_uuid: cluster中的所有node的该变量的值必须一样, 不一样表示node没有连接到cluster。
wsrep_cluster_conf_id: 次变量用来表示node是否在它相应的cluster中。cluster中所有node的该变量值应该一样, 不一样则表示nodes被分隔开了, node恢复的时候该变量也会恢复。
wsrep_cluster_size: 表示cluster中有多少node节点, 等于预期的数量则表示所有node连接到了cluster。
wsrep_cluster_status: 正常情况下值为Primary, 如果不为Primay,则该node当前不能操作(归咎于多成员关系的改变和quorum的缺失), 同时也可能满足split-brain的条件。
如果cluster中没有node 连接上(connected) PC(就是所有node属于同一部分,但是node都是non-primary状态), 可以参考http://galeracluster.com/documentation-webpages/quorumreset.html#id1 来操作Reset quorum。
如果不能Reset quorum, cluster则必须手动进行重引导(rebootstrapped),如下:
1. 关闭所有node节点; 2. 从最近更新(most advanced node)的node节点开始重启所有的nodes(检查 wsrep_last_committed状态变量找到最近更新的node节点)。
2. 节点状态检查
wsrep_ready: 该状态变量为On(Ture)时, 该node可以接受SQL,否则所有sql query返回’Unknown Command Error’,并且需要检查wsrep_connected和wsrep_local_state_comment,在一个PC中wsrep_local_state_comment变量的值通常包括Joining, Waiting for SST, Joined, Synced或者Donor。在wsrep_ready = OFF时, 且wsrep_local_state_comment为Joining, Waiting for SST,或者Joined时,该node仍然在和cluster同步(syncing);在non-primay部分里,节点的wsrep_local_state_comment状态应该是Initialized。
wsrep_connected: 值为OFF,表示该node没有连接到任何cluster 部分。
3. 复制健康检查
wsrep_flow_control_paused: 如果该变量值的范围是0.0 ~ 1.0, 表示复制从上次 show status命令后停止的时间。1.0为完全停止(complete stop). 该变量的值应该接近0.0。保证该值的主要方式包括增加wsrep_slave_threads的数量和从cluster移除执行慢的节点。
wsrep_cert_deps_distance: 该变量表示平均有多少事务可以并发的执行。wsrep_slave_threads的值不应该超过该变量的值。
4. 检测网络延迟问题
如果网络中存在延迟现象, 检查以下变量的值:
wsrep_local_send_queue_avg: 该变量的值较高的话, 网络链接可能存在延迟。如果是这个原因,原因可能分布在多层,包括从物理到系统方面的层次。
五. cluster故障恢复
当nodes连接到一个cluster后,该node即成为cluster的成员; 没有相关配置来明确定义所有可能cluster node的列表。因此,在一个节点加入cluster的时候,cluster的大小就增加,反之减小。cluster的大小用来实现quorum的选举。当一个或多个node没有响应(被怀疑已经不是cluster的一部分)的时候,则完成quorum的选举。响应超时由evs.suspect_timeout(default 5 s)指定,当然在一个node关闭的时候,写操作可能会被blocked,blocked的时间可能超过timeout时间。
一旦一个node或多个node断开连接, 剩下的node则会进行quorum的选举操作; 在断开之前,如果总nodes里的多数node保持连接,则保留分区。对于网络分区(network partition) 一些node可能在非连接(network disconnect)区域内继续存活(alive and active),这种状况下只有quorum是一直运行的,没有quorum运行的分区中的节点则会进入non-primary状态。
鉴于以上的原因,在2个node的集群中做自动故障恢复几乎是不可能的, 因为失败的node节点会使得剩下的node进入non-primary状态(只有一个node没法做quorum)。更多的,在网络不连通的时候,不同交换机下的两个node可能会有一点满足分裂(split brain)条件的可能性,这时候不会保留quorum,并且两个node都会进入non-primary状态。所以对自动故障恢复来说,以下的’3 原则’值得推荐:
单交换机下的cluster至少应该有3个node; 分布不同交换机下的cluster, 应该至少跨越3个交换机; 分布不同网络(子网)下的cluster, 应该至少3个网络; 分布于不同数据中心下的cluster, 应该至少3个数据中心;
以上是在预防自动故障恢复工作过程中的防止分裂的方法。当然出于成本的考虑,增加交换机、数据中心等在很多情况下是不太现实的,Galera arbitrator(仲裁)是个可选的方式,它可以参与到quorum的选举,以组织split brain发生,但是它不会保留任何数据,也不会启动mysqld服务, 它是一个独立的deamon程序,详见http://galeracluster.com/documentation-webpages/arbitrator.html
关于quorum举例如下:
假如我们有3个nodes的cluser, 如果手工隔离1个node,则现在2个node可以互相通信,1个node只能看到它自己,这个时候2个node部分进行quorum计算,达到了2/3(66%),1个node则只达到1/3(33%),这种情况下一个node部分就会停止服务(因为quorum没有达到50%)。quorum算法有助于选举一个Primary组件(Primary Component)并且保证了cluster中没有多个PC(primary component)。如果增加了pc.ignore_quorum, 停掉的node也可以继续接受queries, 单会引起两边数据的不一致,在cluster各节点恢复的时候, 会引起错误,设置了pc.ignore_quorum的node所作的更新会重新被覆盖(SST)。
2 nodes cluster配置(pc.ignore_quorum 和 pc.ignore_sb): http://www.mysqlperformanceblog.com/2012/07/25/percona-xtradb-cluster-failure-scenarios-with-only-2-nodes/
重置quorum: http://galeracluster.com/documentation-webpages/quorumreset.html
一、MariaDB Galera Cluster概要:
1.简述:
MariaDB Galera Cluster 是一套在mysql innodb存储引擎上面实现multi-master及数据实时同步的系统架构,业务层面无需做读写分离工作,数据库读写压力都能按照既定的规则分发到 各个节点上去。在数据方面完全兼容 MariaDB 和 MySQL。
2.特性:
(1).同步复制 Synchronous replication
(2).Active-active multi-master 拓扑逻辑
(3).可对集群中任一节点进行数据读写
(4).自动成员控制,故障节点自动从集群中移除
(5).自动节点加入
(6).真正并行的复制,基于行级
(7).直接客户端连接,原生的 MySQL 接口
(8).每个节点都包含完整的数据副本
(9).多台数据库中数据同步由 wsrep 接口实现
3.局限性
(1).目前的复制仅仅支持InnoDB存储引擎,任何写入其他引擎的表,包括mysql.*表将不会复制,但是DDL语句会被复制的,因此创建用户将会被复制,但是insert into mysql.user…将不会被复制的.
(2).DELETE操作不支持没有主键的表,没有主键的表在不同的节点顺序将不同,如果执行SELECT…LIMIT… 将出现不同的结果集.
(3).在多主环境下LOCK/UNLOCK TABLES不支持,以及锁函数GET_LOCK(), RELEASE_LOCK()…
(4).查询日志不能保存在表中。如果开启查询日志,只能保存到文件中。
(5).允许最大的事务大小由wsrep_max_ws_rows和wsrep_max_ws_size定义。任何大型操作将被拒绝。如大型的LOAD DATA操作。
(6).由于集群是乐观的并发控制,事务commit可能在该阶段中止。如果有两个事务向在集群中不同的节点向同一行写入并提交,失败的节点将中止。对 于集群级别的中止,集群返回死锁错误代码(Error: 1213 SQLSTATE: 40001 (ER_LOCK_DEADLOCK)).
(7).XA事务不支持,由于在提交上可能回滚。
(8).整个集群的写入吞吐量是由最弱的节点限制,如果有一个节点变得缓慢,那么整个集群将是缓慢的。为了稳定的高性能要求,所有的节点应使用统一的硬件。
(9).集群节点建议最少3个。
(10).如果DDL语句有问题将破坏集群。
二、MariaDB Galera Cluster搭建演示
1.环境描述
OS: red hat linux 6.0 64bit
| MariaDB server1: | 192.168.1.137 |
| MariaDB server2: | 192.168.1.138 |
| MariaDB server3: | 192.168.1.139 |
| Galera SST user: | sst |
| Galera SST password: | sstpass123 |
| MySQL root password: | kongzhong |
2. 配置mariadb的yum源
[root@client137 ~]# vim /etc/yum.repos.d/mariadb.repo
[root@client138 ~]# vim /etc/yum.repos.d/mariadb.repo
[root@client139 ~]# vim /etc/yum.repos.d/mariadb.repo
# yum源的内容如下:
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/5.5/rhel6-amd64
enabled = 1
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
[root@client137 ~]# yum makecache
[root@client138 ~]# yum makecache
[root@client139 ~]# yum makecache
3.安装 MariaDB-Galera-server galera MariaDB-client
[root@client137 ~]# yum -y install MariaDB-Galera-server galera MariaDB-client
[root@client138 ~]# yum -y install MariaDB-Galera-server galera MariaDB-client
[root@client139 ~]# yum -y install MariaDB-Galera-server galera MariaDB-client
4.编辑每台机器的hosts文件,添加如下内容
[root@client137 ~]# vim /etc/hosts
192.168.1.137 client137.kongzhong.com client137
192.168.1.138 client138.kongzhong.com client138
192.168.1.139 client139.kongzhong.com client139
# 启动测试一下
[root@client137 ~]# /etc/init.d/mysql start
Starting MySQL.... SUCCESS!
[root@client137 ~]# chkconfig mysql on
5.设置MariaDB的root密码,并做安全加固
[root@client137 ~]# /usr/bin/mysql_secure_installation
[root@client137 ~]# /usr/bin/mysql_secure_installation
# 登陆数据库,授权用于集群同步的用户和密码
[root@client137 ~]# mysql -uroot -pkongzhong
mysql> GRANT USAGE ON *.* to sst@'%' IDENTIFIED BY 'sstpass123';
mysql> GRANT ALL PRIVILEGES on *.* to sst@'%';
mysql> FLUSH PRIVILEGES;
mysql> quit
# 创建并配置wsrep.cnf文件
[root@client137 ~]# cp /usr/share/mysql/wsrep.cnf /etc/my.cnf.d/
[root@client137 ~]# vim /etc/my.cnf.d/wsrep.cnf
# 只需要修改如下4行:
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address="gcomm://"
wsrep_sst_auth=sst:sstpass123
wsrep_sst_method=rsync
# 注意:
# "gcomm://" 是特殊的地址,仅仅是Galera cluster初始化启动时候使用。
# 如果集群启动以后,我们关闭了第一个节点,那么再次启动的时候必须先修改,"gcomm://"为其他节点的集群地址,例如wsrep_cluster_address="gcomm://192.168.1.138:4567"
6.确认本机防火墙上开放了所需TCP 3306和TCP 4567的端口[也可以关闭防火墙]
[root@client137 ~]# iptables -A INPUT -i eth0 -p tcp --dport 3306 -j ACCEPT
[root@client137 ~]# iptables -A INPUT -i eth0 -p tcp --dport 4567 -j ACCEPT
# 启动mariadb,查看3306和4567端口是否被监听
[root@client137 ~]# /etc/init.d/mysql restart
[root@client137 ~]# netstat -tulpn |grep -e 4567 -e 3306
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 32363/mysqld
tcp 0 0 0.0.0.0:4567 0.0.0.0:* LISTEN 32363/mysqld
# 这样一个节点就已经配置完成,其他节点的配置先给个思路,如下注释部分:
# ********************* #
构造新节点的操作步骤如下:
1.按照上述1-6的步骤安装MariaDB和Galera library
2.除了第5步wsrep_cluster_address的配置稍有不同:
wsrep_cluster_address="gcomm://Node-A-IP:4567" # 这里指向是指上一层的集群地址
3.重起MariaDB
# ********************* #
7.新添加节点的配置如下:
# 构建192.168.1.138节点
[root@client138 ~]# /etc/init.d/mysql start
Starting MySQL.... SUCCESS!
[root@client138 ~]# /usr/bin/mysql_secure_installation
[root@client138 ~]# mysql -uroot -pkongzhong
mysql> GRANT USAGE ON *.* to sst@'%' IDENTIFIED BY 'sstpass123';
mysql> GRANT ALL PRIVILEGES on *.* to sst@'%';
mysql> FLUSH PRIVILEGES;
mysql> quit
[root@client138 ~]# cp /usr/share/mysql/wsrep.cnf /etc/my.cnf.d/
[root@client138 ~]# vim /etc/my.cnf.d/wsrep.cnf
# 只需要修改如下4行:
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
# 这里指定上一个集群节点的IP地址
wsrep_cluster_address="gcomm://192.168.1.137:4567"
# 指定用于同步的账号和密码
wsrep_sst_auth=sst:sstpass123
wsrep_sst_method=rsync
# 确认本机防火墙上开放了所需TCP 3306和TCP 4567的端口
[root@client138 ~]# iptables -A INPUT -i eth0 -p tcp --dport 3306 -j ACCEPT
[root@client138 ~]# iptables -A INPUT -i eth0 -p tcp --dport 4567 -j ACCEPT
# 启动,监听
[root@client138 ~]# /etc/init.d/mysql restart
[root@client138 ~]# netstat -tulpn |grep -e 4567 -e 3306
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 32363/mysqld
tcp 0 0 0.0.0.0:4567 0.0.0.0:* LISTEN 32363/mysqld
# 构建192.168.1.139节点
[root@client139 ~]# /etc/init.d/mysql start
Starting MySQL.... SUCCESS!
[root@client139 ~]# /usr/bin/mysql_secure_installation
[root@client139 ~]# mysql -uroot -pkongzhong
mysql> GRANT USAGE ON *.* to sst@'%' IDENTIFIED BY 'sstpass123';
mysql> GRANT ALL PRIVILEGES on *.* to sst@'%';
mysql> FLUSH PRIVILEGES;
mysql> quit
[root@client139 ~]# cp /usr/share/mysql/wsrep.cnf /etc/my.cnf.d/
[root@client139 ~]# vim /etc/my.cnf.d/wsrep.cnf
# 只需要修改如下4行:
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
# 这里指定上一个集群节点的IP地址
wsrep_cluster_address="gcomm://192.168.1.138:4567"
# 指定用于同步的账号和密码
wsrep_sst_method=rsync
# 确认本机防火墙上开放了所需TCP 3306和TCP 4567的端口
[root@client139 ~]# iptables -A INPUT -i eth0 -p tcp --dport 3306 -j ACCEPT
[root@client139 ~]# iptables -A INPUT -i eth0 -p tcp --dport 4567 -j ACCEPT
# 启动,并查看监听
[root@client139 ~]# /etc/init.d/mysql restart
[root@client139 ~]# netstat -tulpn |grep -e 4567 -e 3306
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 32363/mysqld
tcp 0 0 0.0.0.0:4567 0.0.0.0:* LISTEN 32363/mysqld
8.以上配置完成后,
对于只有2个节点的Galera Cluster和其他集群软件一样,需要面对极端情况下的"脑裂"状态。
为了避免这种问题,Galera引入了"arbitrator(仲裁人)"。
"仲裁人"节点上没有数据,它在集群中的作用就是在集群发生分裂时进行仲裁,集群中可以有多个"仲裁人"节点。
"仲裁人"节点加入集群的方法如下:
[root@client137 ~]# garbd -a gcomm://192.168.1.137:4567 -g my_wsrep_cluster -d
# 注释:参数说明 :
-d:以daemon模式运行
-a:集群地址
-g: 集群名称
9.测试集群是否配置好参数:
登陆数据库:
查看如下几个参数:
# 下面这个参数的显示是初始化数据库显示的情况
MariaDB [(none)]> SHOW VARIABLES LIKE 'wsrep_cluster_address';
+-----------------------+----------+
| Variable_name | Value |
+-----------------------+----------+
| wsrep_cluster_address | gcomm:// |
+-----------------------+----------+
1 row in set (0.00 sec)
# 如果配置了指向集群地址,上面那个参数值,应该是你指定集群的IP地址
MariaDB [kz]> SHOW VARIABLES LIKE 'wsrep_cluster_address';
+-----------------------+----------------------------+
| Variable_name | Value |
+-----------------------+----------------------------+
| wsrep_cluster_address | gcomm://192.168.1.139:4567 |
+-----------------------+----------------------------+
1 row in set (0.00 sec)
# 此参数查看是否开启
MariaDB [kz]> show status like 'wsrep_ready';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wsrep_ready | ON |
+---------------+-------+
1 row in set (0.00 sec)
# 这个查看wsrep的相关参数
MariaDB [terry]> show status like 'wsrep%';
+----------------------------+--------------------------------------+
| Variable_name | Value |
+----------------------------+--------------------------------------+
| wsrep_local_state_uuid | bb5b9e17-66c8-11e3-86ba-96854521d205 | uuid 集群唯一标记
| wsrep_protocol_version | 4 |
| wsrep_last_committed | 16 | sql 提交记录
| wsrep_replicated | 4 | 随着复制发出的次数
| wsrep_replicated_bytes | 692 | 数据复制发出的字节数
| wsrep_received | 18 | 数据复制接收次数
| wsrep_received_bytes | 3070 | 数据复制接收的字节数
| wsrep_local_commits | 4 | 本地执行的 sql
| wsrep_local_cert_failures | 0 | 本地失败事务
| wsrep_local_bf_aborts | 0 |从执行事务过程被本地中断
| wsrep_local_replays | 0 |
| wsrep_local_send_queue | 0 | 本地发出的队列
| wsrep_local_send_queue_avg | 0.142857 | 队列平均时间间隔
| wsrep_local_recv_queue | 0 | 本地接收队列
| wsrep_local_recv_queue_avg | 0.000000 | 本地接收时间间隔
| wsrep_flow_control_paused | 0.000000 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 0 |
| wsrep_cert_deps_distance | 0.000000 | 并发数量
| wsrep_apply_oooe | 0.000000 |
| wsrep_apply_oool | 0.000000 |
| wsrep_apply_window | 1.000000 |
| wsrep_commit_oooe | 0.000000 |
| wsrep_commit_oool | 0.000000 |
| wsrep_commit_window | 1.000000 |
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| wsrep_cert_index_size | 0 |
| wsrep_causal_reads | 0 |
| wsrep_incoming_addresses | 192.168.1.137:3306 | 连接中的数据库
| wsrep_cluster_conf_id | 18 |
| wsrep_cluster_size | 2 | 集群成员个数
| wsrep_cluster_state_uuid | bb5b9e17-66c8-11e3-86ba-96854521d205 | 集群 ID
| wsrep_cluster_status | Primary | 主服务器
| wsrep_connected | ON | 当前是否连接中
| wsrep_local_index | 1 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy <info@codership.com> |
| wsrep_provider_version | 2.7(rXXXX) |
| wsrep_ready | ON | 插件是否应用中
+----------------------------+--------------------------------------+
40 rows in set (0.05 sec)
#以上详细参数注释:
监控状态参数说明:
(1).集群完整性检查:
wsrep_cluster_state_uuid:在集群所有节点的值应该是相同的,有不同值的节点,说明其没有连接入集群.
wsrep_cluster_conf_id:正常情况下所有节点上该值是一样的.如果值不同,说明该节点被临时"分区"了.当节点之间网络连接恢复的时候应该会恢复一样的值.
wsrep_cluster_size:如果这个值跟预期的节点数一致,则所有的集群节点已经连接.
wsrep_cluster_status:集群组成的状态.如果不为"Primary",说明出现"分区"或是"split-brain"状况.
(2).节点状态检查:
wsrep_ready: 该值为ON,则说明可以接受SQL负载.如果为Off,则需要检查wsrep_connected.
wsrep_connected: 如果该值为Off,且wsrep_ready的值也为Off,则说明该节点没有连接到集群.
wsrep_local_state_comment:如果wsrep_connected为On,但wsrep_ready为OFF,则可以从该项查看原因.
(3).复制健康检查:
wsrep_flow_control_paused:表示复制停止了多长时间.即表明集群因为Slave延迟而慢的程度.值为0~1,越靠近0越好,值为1表示复制完全停止.可优化wsrep_slave_threads的值来改善.
wsrep_cert_deps_distance:有多少事务可以并行应用处理.wsrep_slave_threads设置的值不应该高出该值太多.
wsrep_flow_control_sent:表示该节点已经停止复制了多少次.
wsrep_local_recv_queue_avg:表示slave事务队列的平均长度.slave瓶颈的预兆.
最慢的节点的wsrep_flow_control_sent和wsrep_local_recv_queue_avg这两个值最高.这两个值较低的话,相对更好.
(4).检测慢网络问题:
wsrep_local_send_queue_avg:网络瓶颈的预兆.如果这个值比较高的话,可能存在网络瓶
(5).冲突或死锁的数目:
wsrep_last_committed:最后提交的事务数目
wsrep_local_cert_failures和wsrep_local_bf_aborts:回滚,检测到的冲突数目
10.测试数据同步,一致等问题,这个测试不演示,概述一下大概思路:
(1).创建一个数据库,看是否同步
(2).数据库里分别创建一个innodb和myisam引擎的表,看是否同步
(3).分别往这两张表里插入数据,看是否同步,除innodb引擎数据可以同步,其余引擎是不同步
(4).在任意一节点插入,删除数据,看是否同步
11.在上面galera集群搭建完成后,我们可以借助于haproxy和lvs来实现mysql数据库集群之间的负载
这里就不演示,可以自己配置试试!
============================================
http://en.wikipedia.org/wiki/MySQL_Cluster
MySQL Cluster
|
|
This article relies too much on references to primary sources. |
 |
|
| Developer(s) | Oracle |
|---|---|
| Initial release | November 2004 |
| Stable release | 7.3.7 / October 7, 2014 |
| Operating system | Cross-platform |
| Available in | English |
| Type | RDBMS |
| License | GNU General Public License (version 2, withlinking exception) or commercial EULA |
| Website | [1] |
MySQL Cluster is a technology providing shared-nothing clustering and auto-sharding for the MySQL database management system. It is designed to provide high availability and high throughput with low latency, while allowing for near linear scalability.[2] MySQL Cluster is implemented through the NDB or NDBCLUSTER storage engine for MySQL ("NDB" stands for Network Database).
Contents
[hide]
Architecture[edit]
MySQL Cluster is designed around a distributed, multi-master ACID compliant architecture with no single point of failure. MySQL Cluster uses automatic sharding (partitioning) to scale out read and write operations on commodity hardware and can be accessed via SQL and Non-SQL (NoSQL) APIs
Replication[edit]
Internally MySQL Cluster uses synchronous replication through a two-phase commit mechanism in order to guarantee that data is written to multiple nodes upon committing the data. (This is in contrast to what is usually referred to as "MySQL Replication", which is asynchronous.) Two copies (known as replicas) of the data are required to guarantee availability. MySQL Cluster automatically creates “node groups” from the number of replicas and data nodes specified by the user. Updates are synchronously replicated between members of the node group to protect against data loss and support fast failover between nodes.
It is also possible to replicate asynchronously between clusters; this is sometimes referred to as "MySQL Cluster Replication" or "geographical replication". This is typically used to replicate clusters between data centers for Disaster recovery or to reduce the effects of network latency by locating data physically closer to a set of users. Unlike standard MySQL replication, MySQL Cluster's geographic replication uses optimistic concurrency control and the concept of Epochs to provide a mechanism for conflict detection and resolution,[3] enabling active/active clustering between data centers.
Starting with MySQL Cluster 7.2, support for synchronous replication between data centers was supported with the Multi-Site Clustering feature.[4]
Horizontal data partitioning (Auto-Sharding)[edit]
MySQL Cluster is implemented as a fully distributed multi-master database ensuring updates made by any application or SQL node are instantly available to all of the other nodes accessing the cluster, and each data node can accept write operations.
Data within MySQL Cluster (NDB) tables is automatically partitioned across all of the data nodes in the system. This is done based on a hashing algorithm based on the PRIMARY KEY on thetable, and is transparent to the end application. Clients can connect to any node in the cluster and have queries automatically access the correct shards needed to satisfy a query or commit a transaction. MySQL Cluster is able to support cross-shard queries and transactions.
Users can define their own partitioning schemes. This allows developers to add “distribution awareness” to applications by partitioning based on a sub-key that is common to all rows being accessed by high running transactions. This ensures that data used to complete transactions is localized on the same shard, thereby reducing network hops.
Hybrid Storage[edit]
MySQL Cluster allows datasets larger than the capacity of a single machine to be stored and accessed across multiple machines.
MySQL Cluster maintains all indexed columns in distributed memory. Non-indexed columns can also be maintained in distributed memory or can be maintained on disk with an in-memory page cache. Storing non-indexed columns on disk allows MySQL Cluster to store datasets larger than the aggregate memory of the clustered machines.
MySQL Cluster writes Redo logs to disk for all data changes as well as check pointing data to disk regularly. This allows the cluster to consistently recover from disk after a full cluster outage. As the Redo logs are written asynchronously with respect to transaction commit, some small number of transactions can be lost if the full cluster fails, however this can be mitigated by using geographic replication or multi-site cluster discussed above. The current default asynchronous write delay is 2 seconds, and is configurable. Normal single point of failure scenarios do not result in any data loss due to the synchronous data replication within the cluster.
When a MySQL Cluster table is maintained in memory, the cluster will only access disk storage to write Redo records and checkpoints. As these writes are sequential and limited random access patterns are involved, MySQL Cluster can achieve higher write throughput rates with limited disk hardware compared to a traditional disk-based caching RDBMS. This checkpointing to disk of in-memory table data can be disabled (on a per-table basis) if disk-based persistence isn't needed.
MySQL Cluster is designed to have no single point of failure. Provided that the cluster is set up correctly, any single node, system, or piece of hardware can fail without the entire cluster failing. Shared disk (SAN) is not required. The interconnects between nodes can be standard Ethernet. Gigabit Ethernet, InfiniBand and SCI interconnects are also supported.
SQL and NoSQL APIs[edit]
As MySQL Cluster stores tables in data nodes, rather than in the MySQL Server, there are multiple interfaces available to access the database:
- SQL access via the MySQL Server
- NoSQL APIs where MySQL Cluster libraries can be embedded into an application to provide direct access to the data nodes without passing through a SQL layer. These include:
MySQL Cluster Manager[edit]
Part of the commercial MySQL Cluster CGE, MySQL Cluster Manager is a tool designed to simplify the creation and administration of the MySQL Cluster CGE database by automating common management tasks, including on-line scaling, upgrades, backup/restore and reconfiguration. MySQL Cluster Manager also monitors and automatically recovers MySQL Server application nodes and management nodes, as well as the MySQL Cluster data nodes.
Implementation[edit]
MySQL Cluster uses three different types of nodes (processes) :
- Data node (ndbd/ndbmtd process): These nodes store the data. Tables are automatically sharded across the data nodes which also transparently handle load balancing, replication, failover and self-healing.
- Management node (ndb_mgmd process): Used for configuration and monitoring of the cluster. They are required only to start or restart a cluster node. They can also be configured as arbitrators, but this is not mandatory (MySQL Servers can be configured as arbitrators instead).[5]
- Application node or SQL node (mysqld process): A MySQL server (mysqld) that connects to all of the data nodes in order to perform data storage and retrieval. This node type is optional; it is possible to query data nodes directly via the NDB API, either natively using the C++ API or one of the additional NoSQL APIs described above.
Generally, it is expected that each node will run on a separate physical host, VM or cloud instance (although it is very common to co-locate Management Nodes with MySQL Servers). For best practice, it is recommended not to co-locate nodes within the same node group on a single physical host (as that would represent a single point of failure).
Versions[edit]
MySQL Cluster version numbers are no longer tied to that of MySQL Server - for example, the most recent version is MySQL Cluster 7.3 even though it is based on/contains the server component from MySQL 5.5.
Higher versions of MySQL Cluster include all of the features of lower versions, plus some new features. Currently available versions:
- Ndb included in MySQL 5.1.X source tree
- This is old and not maintained. Do not use
- MySQL Cluster 6.2 based on MySQL 5.1.A
- First 'telco' or 'carrier grade edition' release. Supports 255 nodes, online table alter, replication latency and throughput enhancements etc.
- MySQL Cluster 6.3 based on MySQL 5.1.B
- Includes compressed backup + LCP, circular replication support, conflict detection/resolution, table optimization etc.
- MySQL Cluster 7.0 based on MySQL 5.1.C
- Includes multi-threaded data nodes (ndbmtd), Transactional DDL, Windows support.
- MySQL Cluster 7.1 based on MySQL 5.1.D
- Includes ClusterJ and ClusterJPA connectors
- MySQL Cluster 7.2 based on MySQL 5.5
- Includes Adaptive Query Localization (pushes JOIN operations down to the data nodes), Memcached API, simplified Active/Active Geographic replication, multi-site clustering, data node scalability enhancements, consolidated user privileges.[6]
- MySQL Cluster 7.3 based on MySQL 5.6
- Includes support for foreign key constraints, Node.js / JavaScript API and an auto-installer.[7]
Requirements[edit]
For evaluation purposes, it is possible to run MySQL Cluster on a single physical server. For production deployments, the minimum system requirements are for 3 x instances / hosts:
- 2 × Data Nodes
- 1 × Application / Management Node
or
- 2 × Data Node + Application
- 1 × Management Node
Configurations as follows:
- OS: Linux, Solaris, Windows. OS X (for development only)
- CPU: Intel/AMD x86/x86-64, UltraSPARC
- Memory: 1GB
- HDD: 3GB
- Network: 1+ nodes (Standard Ethernet - TCP/IP)
Tips and recommendations on deploying highly performant, production grade clusters can be found in the MySQL Cluster Evaluation Guide and the Guide to Optimizing Performance of the MySQL Cluster Database.
History[edit]
MySQL AB acquired the technology behind MySQL Cluster from Alzato, a small venture company started by Ericsson. NDB was originally designed for the telecom market, with its High availability and high performance requirements.[8]
MySQL Cluster based on the NDB storage engine has since been integrated into the MySQL product, with its first release being in MySQL 4.1.
Competitors[edit]
Codership provides Galera, a multi-master extension for MySQL that enables multiple MySQL nodes to handle reads and writes, synchronizing the writes on each node simultaneously. Galera is also available through Percona called variously "Percona Cluster" and "XtraDB Cluster". Galera leverages a fork of the InnoDB storage engine and custom replication plug-ins. MariaDB, a MySQL fork, now ships MariaDB Galera Cluster as its cluster solution too.
ScaleBase is a database software company located in Newton, Massachusetts, that works with next-gen apps to scale out relational databases by virtualizing(auto-sharding) a distributed database environment.
Support[edit]
MySQL Cluster is licensed under the GPLv2 license. Commercial support is available as part of MySQL Cluster CGE, which also includes non-open source addons such as MySQL Cluster Manager, MySQL Enterprise Monitor, in addition to MySQL Enterprise Security and MySQL Enterprise Audit
References[edit]
- Jump up^ Cluster CGE. MySQL. Retrieved on 2013-09-18.
- Jump up^ Oracle Corporation. "MySQL Cluster Benchmarks: Oracle and Intel Achieve 1 Billion Writes per Minute". mysql.com. Retrieved 24 June 2013.
- Jump up^ MySQL :: MySQL 5.6 Reference Manual :: 17.6.11 MySQL Cluster Replication Conflict Resolution. Dev.mysql.com. Retrieved on 2013-09-18.
- Jump up^ Synchronously Replicating Databases Across Data Centers – Are you Insane? (Oracle's MySQL Blog). Blogs.oracle.com (2011-10-03). Retrieved on 2013-09-18.
- Jump up^ Jon Stephens, Mike Kruckenberg, Roland Bouman (2007): "MySQL 5.1 Cluster DBA Certification Study Guide", pp. 86
- Jump up^ New features of MySQL Cluster 7.2, MySQL Developer Zone
- Jump up^ MySQL Cluster 7.3 is now Generally Available – an overview, MySQL Cluster 7.3 Summary
- Jump up^ Todd R. Weiss (2003-10-14). "MySQL acquiring data management system vendor Alzato". Computerworld.com. Retrieved 2012-11-05.
External links[edit]
MySQL[edit]
- Official MySQL Cluster Documentation
- MySQL Cluster API Developers' Guide
- MySQL Cluster Demonstration
- MySQL Cluster Datasheet
- MySQL Cluster FAQ
- MySQL Cluster Auto-Installer Tutorial
- MySQL Cluster Blog
- Getting Started with MySQL Cluster
- MySQL Cluster Whitepapers and Guides
- MySQL Cluster Community Forum
Other[edit]
- Design and Modelling of a Parallel Data Server for Telecom Applications (1997) Original MySQL Cluster design motivation.


User Comments