
识别猫的单隐藏层神经网络(我的第一个模型)
摘要:算法详解;代码;可视化查看超参数影响
目标:识别一张图是不是猫
数据集:训练数据209张64*64
测试数据50张 64*64
方案:二分分类法
算法:logistic回归 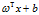 ,限定了你的输入(X),和做优化时,需要优化哪些量(W,b)
,限定了你的输入(X),和做优化时,需要优化哪些量(W,b)
激活函数:sigmod 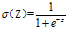
sigmod函数图像:
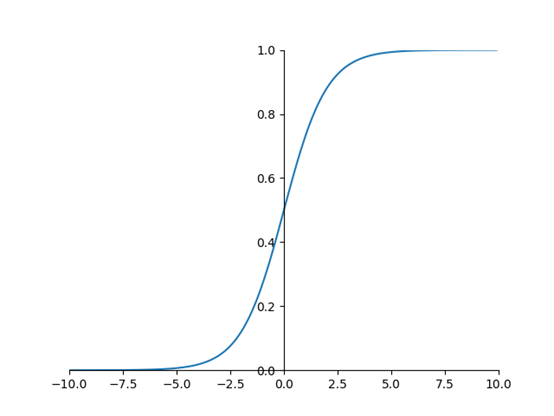
特点:所有输出y值都落在0-1之间
ps:logistic回归是算法,但其激活函数取sigmod,是因为,你想得到一个在(0-1)之间的值,所以,这才用到了sigmod函数。
损失函数: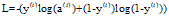
成本函数: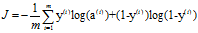
成本函数的由来:假设第1张图真实值是1(第一张图本来就是猫),
预测时,认为
它是猫的概率是0.8,体现在sigmod函数输出0.8,(a=0.8)
则正确率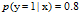
同理,如果假设某图不是只猫,其y=0,
其正确率 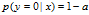
合并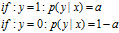
得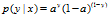
log是一个单调递增的函数,可以变成一个凸函数,便于使用梯度下降进行优化
把上式log化
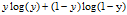
上式还不是成本函数,因为,上式值越大表明,越准确
按照习惯来说,需要成本函数越小,预测值与真实值越接近,越准确
所以,直接加个负号就行了
所以,成本函数就是
计算图
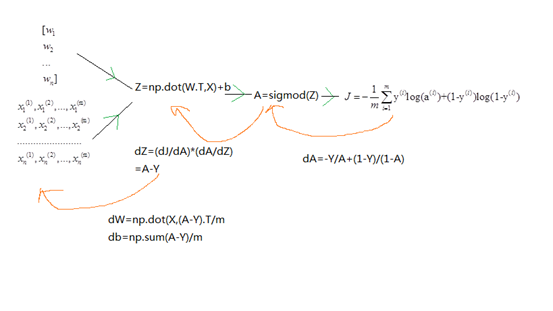
代码:
- 载入数据
- 处理数据(/255),缩小数据,因为1比255更好计算
- 初始化(w,b),w是一个n维列向量,b=0
- 建立sigmod函数
- 利用训练数据集 建立正反向传播函数,如计算图,并求梯度,以便使用梯度下降
- 建立优化(梯度下降)函数,利用好梯度,选取下降方向,另需选取学习率
 ,迭代次数。这两个选取与过拟合,欠拟合息息相关
,迭代次数。这两个选取与过拟合,欠拟合息息相关
- 利用迭代num_iterations次后,出来的w,b。组装好sigmod函数,预测,测试集数据
- 测试/训练集 正确率输出,利于判断
- 可视化输出,比较出一个好的学习率
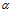 ,和迭代次数。(超参数选择,一个无法学习的东西
,和迭代次数。(超参数选择,一个无法学习的东西
- import numpy as np
- import matplotlib.pyplot as plt
- import h5py
- import sys
- sys.path.append(r'F:\study\assignment2')
- from lr_utils import load_dataset
- '''''
- 数据读取与标准化
- 读取的x数据是(209,64,64,3)的格式
- 需要将其平铺成(64*64*3,209)
- '''
- train_x_orig,train_y_orig,test_x_orig,test_y_orig,classes=load_dataset()
- train_x_flatten=train_x_orig.reshape(train_x_orig.shape[0],-1).T
- test_x_flatten=test_x_orig.reshape(test_x_orig.shape[0],-1).T
- #上面一定要记得转置,因为reshape成了(m,n)的形式
- #-1,是不用去考虑到底要转换成多少列了,只要是负数就行
- #然后是将数据缩小,便于计算,因为1比255更好计算,反正也不影响计算机结果
- #标准化数据 rgb值都小于255的
- train_x=train_x_flatten / 255
- test_x=test_x_flatten / 255
- train_y=train_y_orig
- test_y=test_y_orig
- #上面就把数据整理好了
- '''''
- 下面开始写函数了
- '''
- #建立sigmod函数
- def sigmod(x):
- return (1/(1+np.exp(-x)))
- #初始化w,b, ps:w是一个列向量
- def initialize(n_x):
- w=np.zeros(shape=(n_x,1))
- b=0
- return(w,b)
- #建立正反向传播函数
- def propagate(w,b,X,Y):
- """
- 正向传播
- """
- A=sigmod(np.dot(w.T,X)+b)
- m=X.shape[1]
- cost=(-1/m)*np.sum(Y * np.log(A)+(1-Y) * np.log(1-A))
- ''''' ps:尼玛不知道为什这个三点冒号也要按照缩进格式来
- 反向传播
- '''
- dw=np.dot(X,(A-Y).T)/m
- db=np.sum(A-Y)/m
- '''''
- 组装数据
- '''
- grads={'dw':dw,'db':db}
- return (grads,cost)
- #建立优化函数
- def optimize(w,b,X,Y,num_iterations,learning_rate,print_cost):
- costs=[]
- for i in range(num_iterations):
- grads,cost=propagate(w,b,X,Y)
- dw=grads['dw']
- db=grads['db']
- w=w-learning_rate*dw
- b=b-learning_rate*db
- #记录误差
- if i % 100==0:
- costs.append(cost)
- if print_cost and i%100==0:
- print('迭代次数:%i.误差值:%f' %(i,cost))
- #组装数据
- params={'w':w,'b':b}
- return (params,costs)
- #建立预测函数
- def predict(w,b,X):
- value=sigmod(np.dot(w.T,X)+b)
- Y_prediction=(value>0.5)+0
- '''''
- 对于上一代码详解
- value>0.5是个判断语句,>0.5会返回True
- +0.是让布尔值转化成数字,1
- '''
- return Y_prediction
- #下面是整合所有函数了
- def model(X_train,Y_train,X_test,Y_test,num_iterations=2000,learning_rate=0.01,print_cost=False):
- #先调用X_train,Y_train,来训练处w,b
- m=X_train.shape[1]
- w,b=initialize(X_train.shape[0])
- params,costs=optimize(w,b,X_train,Y_train,num_iterations,learning_rate,print_cost)
- w,b=params['w'],params['b']
- #计算预测值
- Y_prediction_train=predict(w,b,X_train)
- Y_prediction_test=predict(w,b,X_test)
- #比较
- print('TrainRightRate:',format(100-np.mean(np.abs(Y_prediction_train-Y_train))*100),'%')
- print('TestRightRate:',format(100-np.mean(np.abs(Y_prediction_test-Y_test))*100),'%')
- '''''
- 上面代码详解
- abs(Y_p-T_r),此处两相比较,相同,预测对了,则详减为0,预测错了,则为1或者-1
- abs,全部取正
- mean,平均值,即有多少个+-1在所有数据中,即在所有数据中错误的个数/总数据
- 我要的是正确率,所以前面要用100来减
- '''
- #数据组装
- d={
- 'costs':costs,
- 'Y_prediction_train':Y_prediction_train,
- 'Y_prediction_test':Y_prediction_test,
- 'w':w,
- 'b':b,
- 'learning_rate':learning_rate,
- 'num_iterations':num_iterations}
- return d
- #d=model(train_x,train_y,test_x,test_y,num_iterations=2000,learning_rate=0.005,print_cost=True)
- '''''
- 上面就算是整个模型搭建完了,下面是可视化
- 表示迭代次数,学习率,与成本函数的关系
- '''
- learning_rate=[0.01,0.001,0.0001]
- models={}
- for i in learning_rate:
- print ("learning rate is: " + str(i))
- models[str(i)]=model(train_x,train_y,test_x,test_y,num_iterations=500,learning_rate=i)
- print ('\n' + "-------------------------------------------------------" + '\n')
- for i in learning_rate:
- plt.plot(np.squeeze(models[str(i)]['costs']),label=str(models[str(i)]["learning_rate"]))
- plt.ylabel('cost')
- plt.xlabel('iterations')
- legend = plt.legend(loc='upper center', shadow=True)
- frame = legend.get_frame()
- frame.set_facecolor('0.90')
- plt.show()
代码笔记
- 从另外一个文件中导入py文件中的某个函数
import sys
sys.path.append(r'path')
from lr_utils import load_datasert
- 记住X要组装成(n,m)矩阵,w是一个(n,1)的列向量
有利于记住使用np.dot()时,哪个放前面,哪个放后面,也 有利于广播时是否需要转置的判断
- 数据处理
本例子中是将每个元/255,让[0,255],的数据计算,变成了[0,1]的数据计算,加快计算
还有很多其他的数据处理方式,还没学到,多做多学
- np.reshape(a,-1)中-1的妙用,只要把一个数组的行写出来了,列向量可以使用-1,让计算机自动计算分配,只要是负值就行
- w-=learning_rate*dw 不知道为什么不能使用,需要常规操作,w=w-learning_rate*dw
- A and B,两个判断,只要有一个是False,那整个语句就是错的,本例子,使用and来控制是否输出迭代次数与误差
- 布尔值转数字 让布尔值'+0'就行了,numpy对于判断语句,也是并行运行的
- 对于同类型的数据,多用字典dict组装,如梯度,初始值
- np.squeeze()函数,将(5,1,1)转换成(5,)降维处理,有利于运行,也是可视化操作时,作为输入时,不可缺少的操作
>>> a=np.random.randn(10000,1,1,1,1)
>>> sys.getsizeof(a)
80160
>>> b=np.random.randn(10000)
>>> sys.getsizeof(b)
80096
- 可视化操作中,参数解释:loc:选择把线型说明放在哪个地方,shadow,是否加营养
frame.set_facecolor('0.9'),给说明的地方加了框之后,再选择填充框的透明度
- 使用'''作解释时,也需要遵循Python的缩进格式,否则会报错
- 空一行 print('\n')

