python并发编程-进程间通信-Queue队列使用-生产者消费者模型-线程理论-创建及对象属性方法-线程互斥锁-守护线程-02
进程补充
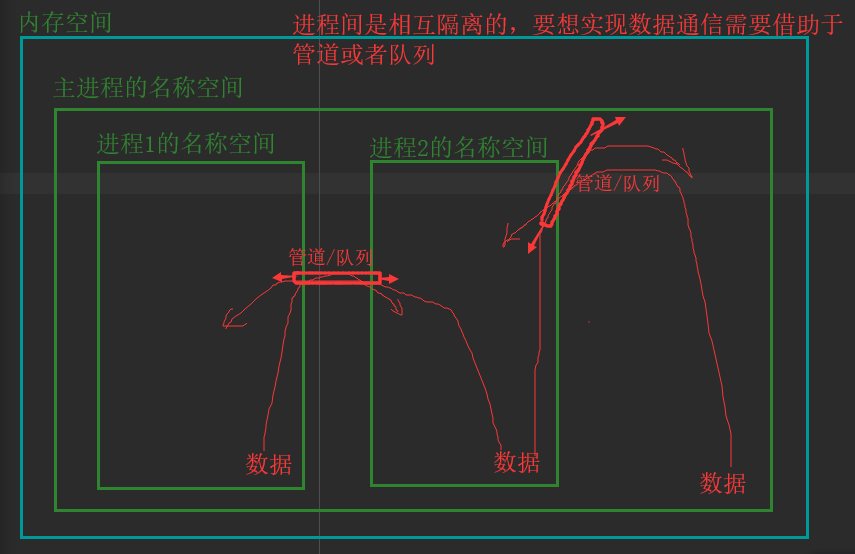
进程通信前言
要想实现进程间通信,可以用管道或者队列
队列比管道更好用(队列自带管道和锁)
队列特点:先进先出
堆栈特点:先进后出
我们采用队列来实现进程间数据通信,下面先介绍一下队列
Queue队列的基本使用
基本方法:q.put(元素) q.get() q.get_nowait() q.full() q.empty()
from multiprocessing import Process, Queue
q = Queue(5) # 实例化出一个对象
# --------------------------------------
# q.put(元素) 往队列里放东西
# 如果队列满了还往里面放,就会等在这里
# --------------------------------------
# q.put(1)
# q.put(2)
# q.put(3)
# --------------------------------------
# # q.full() 判断队列有没有满
# --------------------------------------
# print(q.full()) # q.full 判断队列有没有满
# # False
# q.put(4)
# q.put(5)
# # q.put(6) # 如果队列满了还往里面放,就会等在这里
# print(q.full())
# # True
for i in range(5):
q.put(i)
print(q.full())
# True
# --------------------------------------
# q.get() 从队列头取一个值
# 如果队列空了,就会等在这里,等数据过来
# --------------------------------------
print(q.get())
print(q.full())
# 0
# False
print(q.get())
print(q.get())
# print(q.get())
# --------------------------------------
# q.get_nowait() 从队列头取一个值
# 在队列有数据的情况下,与get取值一样
# 当队列没有值的情况下,取值直接报错
# --------------------------------------
print(q.get_nowait()) # 在队列有数据的情况下,与get取值一样,当队列没有值的情况下,取值直接报错
# --------------------------------------
# q.empty() 判断队列是否为空
# 在并发的情况下,这个方法不准确
# --------------------------------------
print(q.empty()) # 判断队列是否为空,需要注意的是在并发的情况下,这个方法不准确
print(q.get())
# 1
# 2
# 3
# False
# 4
# print(q.get()) # 如果队列空了,就会等在这里,等数据过来
print(q.empty())
# True
# print(q.get_nowait())
# 直接报错 queue.Empty
通过Queue队列实现进程间通信(IPC机制)
数据的互通,可实现主进程与子进程之间的互通,子进程与子进程之间的互通
数据只有一份,取完就没了,无法重复获取同一份数据
from multiprocessing import Queue, Process
def producer(q):
q.put('hello baby.')
def consumer(q):
print(q.get())
if __name__ == '__main__':
q = Queue() # 生成一个队列对象
p1 = Process(target=producer, args=(q,))
c1 = Process(target=consumer, args=(q,))
p1.start()
c1.start() # 子进程获取到了另一个子进程的数据
# hello baby.
# print(q.get()) # 主进程获取到了子进程的数据
# hello baby.
生产者消费者模型
生产者:生产/制造数据的
消费者:消费/处理数据的
例子:做包子的,卖包子的
1.做的包子远比买包子的多
2.做的包子远比买包子的少
--> 供需不平衡
用处:解决供需不平衡的问题
以做包子买包子为例实现当包子卖完了停止消费行为
方式一
from multiprocessing import Process, Queue
import time
import random
def producer(name, food, q: Queue):
for i in range(10):
data = f'{name} 生产了 {food}{i}'
time.sleep(random.random())
q.put(data)
print(data)
def consumer(name, q):
while True:
res = q.get()
if not res: # 已经把生产者做的东西全部吃完了,那么本消费者也结束食用
break
data = res.split(' ')[2]
data = f'{name} 吃了 {data}'
print(data)
time.sleep(random.random())
if __name__ == '__main__':
q = Queue()
p = Process(target=producer, args=('大厨egon', '馒头', q))
p2 = Process(target=producer, args=('跟班tank', '生蚝', q))
c = Process(target=consumer, args=('jason', q))
c2 = Process(target=consumer, args=('吃货kevin', q))
p.start()
p2.start()
c.start()
c2.start()
# 不知道什么时候生产者什么时候生成完
p.join()
p2.join()
q.put(None) # 通过 None来标志生产者已生产完成
q.put(None)
# 可以实现,但是不好
方式二
改用JoinableQueue模块的队列与守护进程来实现
from multiprocessing import Process, JoinableQueue
import time
import random
def producer(name, food, q: JoinableQueue):
for i in range(10):
data = f'{name} 生产了 {food}{i}'
time.sleep(random.random())
q.put(data)
print(data)
def consumer(name, q):
while True:
res = q.get()
if not res:
break
data = res.split(' ')[2]
data = f'{name} 吃了 {data}'
print(data)
time.sleep(random.random())
q.task_done() # 告诉队列,你已经从队列中取出了一个数据,并且处理完毕了
if __name__ == '__main__':
q = JoinableQueue()
p = Process(target=producer, args=('大厨egon', '馒头', q))
p2 = Process(target=producer, args=('跟班tank', '生蚝', q))
c = Process(target=consumer, args=('jason', q))
c2 = Process(target=consumer, args=('吃货kevin', q))
p.start()
p2.start()
c.daemon = True # 配合join,结束程序消费者也结束(注意join是主进程的最后一句代码)
c.start()
c2.daemon = True
c2.start()
# 不知道什么时候生产者什么时候生成完
p.join()
p2.join()
q.join() # 等待队列中数据全部取出,执行完了这句话,也就意味着队列中没有数据了(消费者那里还是会卡住,get不到东西等待)
# 配合上 守护进程 来实现....
线程
什么是线程
进程和线程其实都是虚拟单位,都是用来帮助我们形象的描述某种事物
进程:资源单位(一块独立的内存空间)
线程:执行单位
将内存比喻成工厂,那么进程就相当于工厂里的车间,而你的线程就相当于是车间里面的流水线
CPU其实运行的其实是线程,进程只是资源单位
线程执行时需要的资源单位都跟进程要
ps:每个进程都自带一个线程,线程才是真正的执行单位,进程只是在线程运行过程中提供代码运行所需要的资源
每个进程都会自带一个线程
线程没有主次之分,只不过我们默认就把主进程自带的那个线程叫做主线程
为什么要有线程
开进程
- 申请内存空间 ---> 耗资源
- “拷贝代码” ---> 耗资源
开线程
- 一个进程内可以起多个线程,并且线程与线程之间数据是共享的
ps:开启线程的开销要远远小于开启进程的开销(可能刚执行完创建线程的代码线程就创建好了)
开启线程的两种方式
方式一
from threading import Thread
import time
def task(name):
print(f"{name} is running")
time.sleep(3)
print(f"{name} is over")
t = Thread(target=task, args=('egon', )) # 开线程不需要在 __main__ 代码块内,但是习惯性的还是写在 __main__ 内
t.start() # 告诉操作系统开启一个线程
# 线程的开销远远小于进程,小到以至于可以代码执行完,线程就已经开启了
print("主") # 线程没有主次之分,都在同一个进程的名称空间里,只是人为把进程自带的线程叫做主线程
# egon is running
# 主线程 # 进程的时候这个主线程可能会是最先打印的
# egon is over
方式二
from threading import Thread
import time
class MyThread(Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print(f"{self.name} is running")
time.sleep(1)
print(f"{self.name} is over")
if __name__ == '__main__':
t = MyThread('jason')
t.start() # 开启线程的速度非常快,几乎代码执行完线程就已经开启
print("主")
# jason is running
# 主
# jason is over
线程之间数据共享
from threading import Thread
money = 666
def task():
global money
money = 999
t = Thread(target=task)
t.start()
t.join() # 确保是线程运行结束后
print(money)
# 999 # 主线程与子线程之间数据是通用的
线程间想要实现数据通信,不需要借助于队列(线程间支持数据通信)
线程对象的其他属性和方法
import time
from threading import Thread, active_count, current_thread
import os
def task(name):
print(f"{name} is running {os.getpid()}")
# # ------------------------------------------------
# # current_thread().name current_thread().getname() 当前线程名
# # 记得导入模块
# # ------------------------------------------------
# print(f"current_thread().name:{current_thread().name}")
# current_thread().name:Thread-1
time.sleep(1)
print(f"{name} is over")
# t = Thread(target=task, args=('jason', ))
# t.start()
# # ------------------------------------------------
# # os.getpid() os.getppid() 获取进程号 父进程号
# # 多个线程属于同一进程
# # ------------------------------------------------
# print(f"pid {os.getpid()}")
# # jason is running 5572
# # pid 5572
# # jason is over
t = Thread(target=task, args=('jason', ))
t.start()
# ------------------------------------------------
# active_count() 统计当前存活的线程数
# 记得导入模块
# ------------------------------------------------
print(active_count())
print(f"pid {os.getpid()}")
# jason is running 5728
# 2
# pid 5728
print(f"主 current_thread().name:{current_thread().name}")
# 主 current_thread().name:MainThread
t.join() # 主线程等待子线程运行结束
# jason is over
print("主 active_count", active_count()) # 可能会有问题,多线程是异步,可能join的线程结束了,其他线程也正好结束了(多个线程时)
# 主 active_count 1
# Thread.join(t) # 可以考虑用类调用对象方法,传入对象来在循环里对线程对象进行操作
守护线程
主线程要等待所有非守护线程结束后才会结束(不是主线程的代码执行完了就立马结束了)
主线程结束后,守护(子)线程也会立即结束
主线程运行结束之后为什么需要等待子线程结束才能结束呢?
主线程的结束也就意味着进程的结束
主线程必须等待其他非守护线程的结束才能结束
因为子线程在运行的时候需要使用进程中的资源,而主线程一旦结束了,资源也就销毁了
# from threading import Thread, current_thread
# import time
#
#
# def task(i):
# print(f"{current_thread().name}")
# time.sleep(i)
# print("GG")
#
#
# for i in range(3):
# t = Thread(target=task, args=(i, ))
# t.start()
#
#
# print("主")
# # 循环的时候就已经打印了部分数据了(异步)
# # Thread-1
# # GG
# # Thread-2
# # Thread-3
# # 主
# # GG
# # GG
# 主线程运行结束之后为什么需要等待子线程结束才能结束呢?
'''
主线程的结束也就意味着进程的结束
主线程必须等待其他非守护线程的结束才能结束
因为子线程在运行的时候需要使用进程中的资源,而主线程一旦结束了,资源也就销毁了
'''
from threading import Thread, current_thread
import time
def task(i):
print(f"{current_thread().name}")
time.sleep(i)
print("GG")
for i in range(3):
t = Thread(target=task, args=(i,))
t.daemon = True
t.start()
print("主")
# Thread-1
# GG
# Thread-2
# Thread-3
# 主
测试
下面程序的执行结果是什么?
from threading import Thread
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
t1 = Thread(target=foo)
t2 = Thread(target=bar)
t1.daemon = True
t1.start()
t2.start()
print("main-------")
# 123
# 456
# main-------
# end123
# end456
线程互斥锁
从线程间通信那里的案例可以看出,线程间数据是相通的,那么多个线程对同一份数据进行操作会产生问题
下面同样模拟一个网络延迟来对数据进行操作(确保所有线程都执行完的操作可以记一下)
不加锁遇到延迟的情况
# 模拟网络延迟的现象
# 多个线程操作同一个数据,也会造成数据不安全
import time
from threading import Thread
n = 10
def task():
global n
tmp = n
time.sleep(1)
n = tmp - 1
# -------------------------------
t_list = []
for i in range(10):
t = Thread(target=task)
t.start()
t_list.append(t)
# 确保其他线程都执行完了之后再打印
for t in t_list:
t.join()
# -------------------------------
print(n)
# 9
加锁后遇到延迟
# 加锁解决问题
import time
from threading import Thread, Lock
n = 10
def task(mutex):
mutex.acquire() # 抢锁
global n
tmp = n
time.sleep(1)
n = tmp - 1
mutex.release() # 释放锁
t_list = []
mutex = Lock()
for i in range(10):
t = Thread(target=task, args=(mutex, ))
t.start()
t_list.append(t)
# 确保其他线程都执行完了之后再打印
for t in t_list:
t.join()
print(n)
# 0 # 等10s多点 后打印出结果,数据未受延迟影响,保证了数据安全
为什么用互斥锁不用 线程/进程对象.join()
虽然互斥锁也是将并发改成串行,牺牲效率来保证数据安全,这一点
线程对象.join()也可以实现将并发改成串行,同样保证数据安全,但线程对象.join()是将每一个线程的运行都变成串行的,对比互斥锁的只将数据操作部分编程串行消耗的时间要多得多,若果线程耗时长,执行效率就会低的可怕
# # 不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全
# from threading import current_thread, Thread, Lock
# import os
# import time
#
#
# def task():
# # 未加锁的代码并发运行
# time.sleep(3)
# print('%s start to run' % current_thread().getName())
# global n
# # 加锁的代码串行运行
# lock.acquire()
# temp = n
# time.sleep(0.5)
# n = temp - 1
# lock.release()
#
#
# if __name__ == '__main__':
# n = 100
# lock = Lock()
# threads = []
# start_time = time.time()
# for i in range(100):
# t = Thread(target=task)
# threads.append(t)
# t.start()
# for t in threads:
# t.join()
# stop_time = time.time()
# print('主:%s n:%s' % (stop_time - start_time, n))
#
# '''
# Thread-3 start to run
# Thread-1 start to run
# ......
# Thread-100 start to run
# Thread-96 start to run
# 主:53.06105661392212 n:0
# '''
# 利用 join 保证数据安全
from threading import current_thread, Thread, Lock
import os
import time
def task():
time.sleep(3)
print('%s start to run' % current_thread().getName())
global n
temp = n
time.sleep(0.5)
n = temp - 1
if __name__ == '__main__':
n = 100
lock = Lock()
start_time = time.time()
for i in range(100):
t = Thread(target=task)
t.start()
t.join()
stop_time = time.time()
print('主:%s n:%s' % (stop_time - start_time, n))
'''
Thread-1 start to run
Thread-2 start to run
......
Thread-100 start to run
主:350.1616487503052 n:0 # 耗时是多么的恐怖
'''
线程和进程的用户大同小异,可以对比着来记
后续可以画图或表格用对比的方式来整理一下,方便记忆~

