
《渲染管线研究》:1.渲染管线示意图
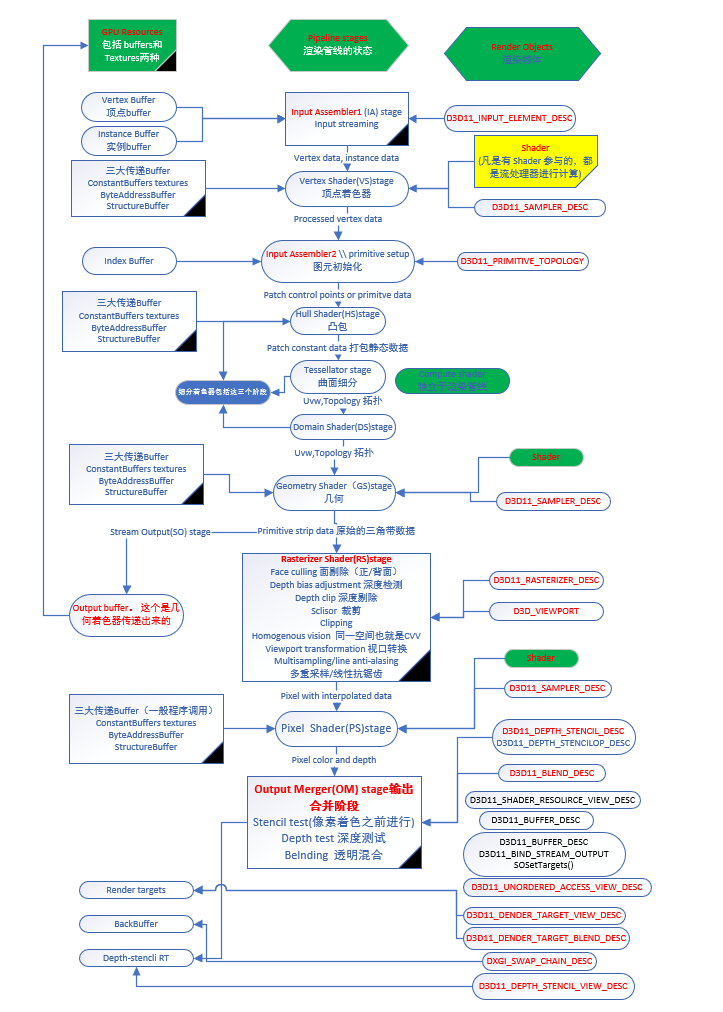
一、 3D图形渲染(Rendering)
渲染:就是将三维物体或三维场景的描述转化为一幅二维图像,生成的二维图像能很好的反应三维物体或三维场景。过程:几何变换、光栅化、着色。
顶点渲染单元(Vertex Shader):根据描述3D图形外观的三角形顶点数据确定3D图形的形状及位置关系; 作几何变换、生成3D图像的骨架。
光栅化:显示的图像是由像素组成的,我们需要将描述3D图像骨架的一系列三角形通过一定的算法转换到相应屏幕上的像素点。把一个矢量图形转换为一系列像素点的过程就称为光栅化。例如,一条数学表示的斜线段,最终被转化成阶梯状的连续像素点。
像素渲染(Pixel Shader):光照、光线追踪、纹理帖图、像素着色。 也就是对每个像素进行计算,从而确定每个像素的最终颜色。最后由ROP(光栅化引擎)完成像素的输出,1帧渲染完毕后,被送到显存帧缓冲区;然后经由D/A转换输出到显示器上。
纹理帖图:所有3D场景的对象都是由顶点形成。一个顶点是X、Y、Z坐标形成的3D空间中的一点,多个顶点聚在一起可形成一个多边形,如三角形、立方体或更复杂的形状,将材质贴在其上可使该组件(或几个排好的组件)看起来更真实。纹理映射(texture mapping)工作由TMU(Texture mapping unit)单元完成对多边形表面的帖图。
顶点光照:在vetext shader中计算光照颜色,该过程将为每个顶点计算一次光照颜色,然后在通过顶点在多边形所覆盖的区域对像素颜色进行线性插值。现实中,光照值取决于光线角度,表面法线,和观察点。
逐像素光照:是对所有光照元素进行单独插值,简单地说就是在pixel shader中计算颜色。
光线追踪技术:现在游戏基本都没有应用光线追踪技术,光线都是由你能看到的亮光的物体自身发出的。电脑只是通过演算物体阴影和控制光线的强弱来“模拟”人眼看到的真实情况。尽管现在很多采用了HDR(高动态范围)效果的游戏都有很不错的光影效果,但是那远非真实的光影效果。如果,视角前面有一个类似镜子的物体,该物体的多个三角形镜面反映的是背面的景象;就像汽车的后视镜;但背面的物体GPU已经裁掉了。还有,像水面的物体倒影等;必须采用光线追踪技术。由于从光源发出的光线有无穷多条,使得直接从光源出发对光线进行跟踪变得非常困难。实际上,从光源发出的光线只有少数经由场景的反射和透射(折射)后到达观察者的眼中。为此标准光线跟踪算法采用逆向跟踪技术完成整个场景的绘制;这便在最大程度上节省了计算资源。要想用光线追踪算法渲染出达到现代游戏的画面质量,同时跑出可流畅运行的帧数,每秒需要计算大概10亿束光线。这包括每帧每像素大概需要30束不同 的光线用以分别计算着色、光照与其他特效。按这个公式推算,入门级的1024×768分辨率一共有786432个像素,乘以每像素30束光线以及每秒60帧,我们就需要每秒能计算14.1亿束光线的硬件。而Intel双路四核心处理器每秒也不过只能处理830万束光线。如果将分辨率提升为现在主流的1920×1080,那所需要的运算量将不可想象。APO支持电影模式8192×4096,那就更不用活了。所以,必须有新的算法与硬件。
光线追踪运算中会大量用到递归算法,如有时会出现这样的情况:对每个光源射出一条光线来检测是否处在阴影中,如果表面是反射面,生成反射光,将会运用递归继续跟踪;如果表面透明,生成折射光,还是运用递归继续跟踪。当前交点所在的物体表面为理想漫射面,跟踪结束。递归算法是把问题转化为规模缩小了的同类问题的子问题。然后递归调用函数(或过程)来表示问题的解。光线追踪算法需要双精度浮点运算的支持?不太了解。
二、流处理器SP(Stream Processor,就是可编程流式并行运算单元ALU)
ALU(逻辑算术单元,顾名思义,可以进行加、减、乘、除、乘加、开方、倒数,平方根倒数,log2, exp2,sin,cos等算术运算)。在APO中,SP的最小单元是管线,一个管线是一个ALU单元支持32位单精度浮点数的运算。双精度浮点数的运算则需要2根管线,一条管道有8根管线,管道内是SIMD架构。每条管线都支持1D、2D、3D、4D到nD的向量和矩阵的单精度浮点数运算。数据的基本单元是Scalar(标量),就是指一个单独的值,SP的ALU进行一次这种变量操作,被称做1D标量。每条管线都可以按照动态流模式控制,智能的执行各种4D/3D/2D/1D指令,无论什么类型的指令执行效率都能接近于100%。SP有256条管道,多个管道单元都是根据不同的控制流程执行不同的操作,处理不同的数据,因此,SP是多指令流多数据流处理器,即管道间MIMD(Multiple Instruction Stream Multiple Data Stream,简称)架构,管道内部的8根管线是SIMD架构。一根管线的1D乘法、除法、开方、加、减运算速度是2G/S。4D向量与变换矩阵的乘加速度是0.125G/S,一条管道的速度是1G/S;一个SP(256条管道)全用来作矩阵变换的速度是256G/S。APO支持电影模式8192×4096,颜色是64位。有32M个像素,即使所有三角形都是最小的,对应变换后的像素只是3个顶点;那一个视锥体最多有32M/3个三角形。那6个方向,360度场景最多有6*32M/3 = 64M个三角形。APO支持28位表示的将近3亿的三角形数场景。通常要处理的顶点数会小于1M个;如果一条管道的流水深度是1K个顶点,那么APO需要4次批数据存储传输,几何变换时间是:60帧*4*1K/1G/S = 0.24mS。APO中,当打开场景文件时,空间管理者CPU的SP就已经帮处理好几何变换形成有序的文件给显示管理者。显示管理者CPU的SP只是多了光栅化单元、纹理单元等功能吧。其实,光照、光线跟踪、像素着色等也可在APO的其它CPU部件进行。光栅化只能在显示管理者的SP进行。当然,可编程的SP你可以有一部分管道做VS的功能,另一部分管道做PS的功能。3D图形生成就是一个运算过程! 在3D图形进行渲染时,其实就是改变RGBA四个通道或者XYZW四个坐标的数值。GS(几何着色器Geometry Shader)、PS(像素着色器Pixel Shader)、VS(顶点着色器Vertex Shader)都是1D—4D的流运算吧。每个像素可以提供多种数据的像素着色器,由你的顶点着色器生成并由光栅化成线性插值。这允许你的像素着色器依照光照条件调整像素的颜色,添加反射,执行凹凸贴图和纹理采样等。你也可以用像素着色器应用后处理效果在整个要渲染的场景, 像亮度,色彩增强,饱和度和模糊。额外的,像素着色器可以改变像素深度。这个深度用在输出合并时决定哪个像素被绘制哪个不被绘制。这个深度指示原始三角形离相机有多远。但是,如果你想影响输出合并的决定,你可以自己指定这个值。传统的一条渲染管线是由包括Pixel Shader Unit(像素着色单元)+ TMU(纹理贴图单元) + ROP(光栅化引擎)三部分组成的。用公式表达可以简单写作:PS = PSU+TMU+ROP 。从功能上看,PSU完成像素处理,TMU负责纹理渲染,而ROP则负责像素的最终输出。所以,一条完整的像素管线意味着在一个时钟周期完成至少进行1个PS运算,并输出一次纹理。顶点着色器,取代固定渲染管线中的变换和光照部分,程序员可以自己控制顶点变换、光照等。
三、 三角形调整引擎
软件实现还是硬件实现在考虑中。当一个物体模型,可见面有几千个三角形描述时;如果,被置于远景,可能几个三角形就可表述了;则应做三角形合并,从而剔除了几千个顶点。反之,在近景时,就要做细分曲面(Tessellation)。在 DirectX中,还包含了其他着色器,如Hull Shader,Domain Shader(域着色器)用于曲面细分(有些地方叫做镶嵌tessellation),Compute Shader用于计算。Hull Shader主要负责定义细分等级(LOD)和相关控制点在细分中的“形变”趋势,需要说明的是这种形变仅仅是类似于曲率改变等小幅度的变化,而非大幅度的多边形位移;Tessellator则负责根据Hull Shader传输下来的信息,通过“暴力”增加多边形去实现Hull Shader的要求;Domain Shader负责的最重要的功能就是通过贴图控制的方式,实现模型的形变。如果,一个由三个顶点组成的三角形占据整个屏幕,因此需要生成上百万的片段;如果不拆分为多个三角形;光栅化单元就会从并行化变为串行化,效率大为降低。
三角形调整位于几何变换阶段之后,剔除与裁剪阶段之前。三角形调整阶段结束后,便将一个新顶点数据组传递给顶点渲染器,顶点可能包含位置、纹理坐标、顶点颜色、法线等数据。顶点渲染器不能创建或删除顶点,它处理结束后至少要输出顶点中的位置数据。
face culling: 根据triangle的两边向量叉乘得到的面法线方向来确定是顺时针还是逆时针,从而达到裁剪。背面剔除。
user clip planes:除了使用投影矩阵定义出的6个clipplane之外我们也可以额外自己定义对应的clipplane来剪裁。
frustum culling:视锥裁剪。
CVV culling:规范立方体(Canonical view volume,CVV)。CVV 的近平面(梯形体较小的矩形面)的X、Y 坐标对应屏幕像素坐标(左下角是0、0),Z 坐标则是代表画面像素深度。多边形裁剪就是CVV 中完成的。所以,从视点坐标空间到屏幕坐标空间(screen coordinate space)事实上是由三步组成:
1. 用透视变换矩阵把顶点从视锥体中变换到裁剪空间的 CVV 中;
2. 在 CVV 进行三角形裁剪;
3. 屏幕映射:将经过前述过程得到的坐标映射到屏幕坐标系上。
法向量从object space 到world space 的转换矩阵是world matrix 的转置矩阵的逆矩阵。
所有的裁剪剔除计算都是为了减少需要绘制的顶点个数。处理三角形的过程被称为Triangle Setup。到目前位置,我们得到了一堆在屏幕坐标上的三角面片,这些面片是用于做光栅化的(Rasterizing)。Z buffer又称为depth buffer,即深度缓冲区,其中存放的是视点到每个像素所对应的空间点的距离衡量,称之为Z 值或者深度值。可见物体的Z 值范围位于【0,1】区间,默认情况下,最接近眼睛的顶点(近裁减面上)其Z 值为0.0,离眼睛最远的顶点(远裁减面上)其Z值为1.0。使用z buffer 可以用来判断空间点的遮挡关系,著名的深度缓冲区算法(depth-buffer method,又称Z 缓冲区算法)就是对投影平面上每个像素所对应的Z 值进行比较的。Z 值并非真正的笛卡儿空间坐标系中的欧几里德距离(Euclidean distance),而是一种“顶点到视点距离”的相对度量。所谓相对度量,即这个值保留了与其他同类型值的相对大小关系。 大多数人所忽略的是,z buffer 中存放的z 值不一定是线性变化的。在正投影中同一图元相邻像素的Z 值是线性关系的,但在透视投影中却不是的。在透视投影中这种关系是非线性的,而且非线性的程度随着空间点到视点的距离增加而越发明显。当3D 图形处理器将基础图元(点、线、面)渲染到屏幕上时,需要以逐行扫描的方式进行光栅化。图元顶点位置信息是在应用程序中指定的(顶点模型坐标),然后通过一系列的过程变换到屏幕空间,但是图元内部点的屏幕坐标必须由已知的顶点信息插值而来。例如,当画三角形的一条扫描线时,扫描线上的每个像素的信息,是对扫描线左右端点处已知信息值进行插值运算得到的,所以内部点的Z 值也是插值计算得到的。同一图元相邻像素点是线性关系(像素点是均匀分布的,所以一定是线性关系),但对应到空间线段上则存在非线性的情况,投影面上相等的步长,在空间中对应的步长会随着离视点距离的增加而变长。所以如果对内部像素点的Z 值进行线性插值,得到的Z 值并不能反应真实的空间点的深度关系。Z 值的不准确,会导致物Z 精度之所以重要,是因为Z 值决定了物体之间的相互遮挡关系,如果没有足够的精度,则两个相距很近的物体将会出现随机遮挡的现象,这种现象通常称为“flimmering”或”Z-fighting”。
四. 顶点变换(Vertex Transformation):
顶点变换是图形硬件渲染管线种的第一个处理阶段。顶点变换在每个顶点上执行一系列的数学操作。这些操作包括把顶点位置变换到屏幕位置以便光栅器使用,为贴图产生纹理坐标,以及照亮顶点以决定它的颜色。顶点变换中的一些坐标:
物体空间:
应用程序在一个被称为物体空间(也叫模型空间)的坐标系统里指定顶点位置。当一个美工人员创建了一个物体的三维模型的时候,他选择了一个方便的方向、比例和位置来放置模型的组成顶点。一个物体的物体空间可以与其它物体的物体空间没有任何关系。
世界空间:
一个物体的物体空间和其它对象没有空间上的关系。世界空间的目的是为在你的场景中的所有物体提供一个绝对的参考。一个世界空间坐标系如何建立可以任意选择。例如:你可以决定世界空间的原点是你房间的中心。然户,房间里的物体就可以相对房间的中心和某个比例和某个方向放置了。
建模变换:
在物体空间中指定的物体被放置到世界空间的方法要依靠建模变换。例如:你也许需要旋转、平移和缩放一个椅子的三维模型,以使椅子可以正确地放置在你的房间 的世界坐标系统里。在同一个房间中的两把椅子可以使用同样的三维椅子模型,但使用不同的建模变换,以使每把椅子放在房间中不同的位置。
眼空间:
最后,你要从一个特殊的视点(“眼睛”)观看你的场景。在称为眼空间(或视觉空间)的坐标系统里,眼睛位于坐标系统的原点。朝“上”的方向通常是轴正方向。遵循标准惯例,你可以确定场景的方向使眼睛是从z轴向下看。
视变换:
从世界空间位置到眼空间位置的变换时为视变换。典型的视变换结合了一个平移把眼睛在世界空间的位置移到眼空间的原点,然后适当地旋转眼睛。通过这样做,视变换定义了视点的位置和方向。我们通常把分别代表建模和视变换的两个矩阵结合在一起,组成一个单独的被称为modelview的矩阵。你可以通过简单地用建模矩阵乘以视矩阵把它们结合在一起。
剪裁空间:
当位置在眼空间以后,下一步是决定什么位置是在你最终要渲染的图像中可见的。在眼空间之后的坐标系统被称为剪裁空间,在这个空间中的坐标系统称为剪裁坐标。
投影变换:
从眼空间坐标到剪裁空间的变换被称为投影变换。投影变换定义了一个事先平截体(view frustum),代表了眼空间中物体的可见区域。只有在视线平截体中的多边形、线段和点背光栅化到一幅图形中时,才潜在的有可能被看得见。
标准化的设备坐标:
剪裁坐标是齐次形式的,但我们需要计算一个二维位置(一对x和y)和一个深度值(深度值是为了进行深度缓冲)。
透视除法:
用w除x,y和z能完成这项工作。生成的结果坐标被称为标准化的设备坐标。现在所有的几何数据都标准化为[-1,1]之间。
窗口坐标:
最后一步是取每个顶点的标准化的设备坐标,然后把它们转换为使用像素度量x和x的最后的坐标系统。这一步骤命名为视图变换,它为图形处理器的光栅器提供数据。然后光栅器从顶点组成点、线段或多边形,并生成决定最后图像的片段。另一个被称为深度范围变换的变换,缩放顶点的z值到在深度缓冲中使用的深度缓存的 范围内。
五. 图元装配(Primitive Assembly)和光栅化(Rasterization)
经过变换的顶点流按照顺序被送到下一个被称为图元装配和光栅化的 阶段。首先,在图元装配阶段根据伴随顶点序列的几何图元分类信息把顶点装配成几何图元。这将产生一序列的三角形、线段和点。这些图元需要经过裁剪到可视平截体(三维空间中一个可见的区域)和任何有效地应用程序指定的裁剪平面。光栅器还可以根据多边形的朝前或朝后来丢弃一些多边形。这个过程被称为挑选 (culling)。 经过裁剪和挑选剩下的多边形必须被光栅化。光栅化是一个决定哪些像素被几何图元覆盖的过程。多边形、线段和点根据为每种图元指定的规则分别被光栅化。光栅化的结果是像素位置的集合和片段的集合。当光栅化后,一个图元拥有的顶点数目和产生的片段之间没有任何关系。例如,一个由三个顶点组成的三角形占据整个屏幕,因此需要生成上百万的片段。
片段和像素之间的区别变得非常重要。术语像素(Pixel)是图像元素的简称。一个像素代表帧缓存中某个指定位置的内容,例如颜色,深度和其它与这个位置相关联的值。一个片段(Fragment)是更新一个特定像素潜在需要的一个状态。
之所以术语片段是因为光栅化会把每个几何图元(例如三角形)所覆盖的像素分解成像素大小的片段。一个片段有一个与之相关联的像素位置、深度值和经过插值的参数,例如颜色,第二(反射)颜色和一个或多个纹理坐标集。这些 各种各样的经过插值的参数是来自变换过的顶点,这些顶点组成了某个用来生成片段的几何图元。你可以把片段看成是潜在的像素。如果一个片段通过了各种各样的光栅化测试,这个片段将被用于更新帧缓存中的像素。
六. 插值、贴图和着色
当 一个图元被光栅化为一堆零个或多个片段的时候,插值、贴图和着色阶段就在片段属性需要的时候插值,执行一系列的贴图和数学操作,然后为每个片段确定一个最终的颜色。除了确定片段的最终颜色,这个阶段还确定一个新的深度,或者甚至丢弃这个片段以避免更新帧缓存对应的像素。允许这个阶段可能丢弃片段,这个阶段 为它接收到的每个输入片段产生一个或不产生着过色的片段。
七.光栅操作(Raster Operations)
光栅操作阶段在最后更新帧缓存之前,执行最后一系列的针对每个片段的操作。在这个阶段,隐藏面通过一个被称为深度测试的过程而消除。其它一些效果,例如混合和基于模板的阴影也发生在这个阶段。
光栅操作阶段根据许多测试来检查每个片段,这些测试包括剪切、alpha、模板和深度等测试。这些测试涉及了片段最后的颜色或深度,像素的位置和一些像素值(像素的深度值和模板值)。如果任何一项测试失败了,片段就 会在这个阶段被丢弃,而更新像素的颜色值(虽然一个模板写入的操作也许会发生)。通过了深度测试就可以用片段的深度值代替像素深度值了。在这些测试之后, 一个混合操作将把片段的最后颜色和对应像素的颜色结合在一起。最后,一个帧缓存写操作用混合的颜色代替像素的颜色。


