动态规划_最优二分检索树
首先总的纲领就是最优决策原理:
过程的最优决策序列具有如下性质:无论过程的初始状态和初始决策是什么,其余的决策都必须相对于初始决策所产生的状态构成一个最优决策序列。
下面逐步的来讲解怎么样通过动态决策构建最优二分检索树,首先一步一步的来:
前奏:
二分检索树(Binary Search Tree)的定义:
二分检索树是一棵二元树,它或者为空,或者其每个结点的数据元素都可以比较大小,且满足下面性质:
(1)T的左子树中的所有元素都比根结点中的元素小。
(2)T的右子树中的所有元素都比根结点中的元素大。
(3)T的左子树和右子树也是二分检索树。
注:Binary Search Tree要求树中的结点元素值互异。
对于一个给定的标识符集合,可能有若干个不同的二分检索树。不同的二分检索树对标示符的检索性能是不同的。
例如标志符集合{a1,a2,a3,a4,a5}=(for,if,loop,repeat,while),如果以字典顺序定义字符串大小,则可能构建的二分检索树如下:
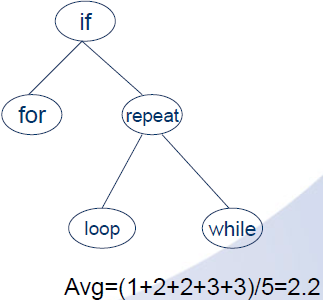
可以看出他们成功检索的平均比较次数是不同的。
二分检索树的检索性能特征:
(1)成功检索:
X恰好为标识符集合中的一个元素,成功检索共有n中情况,分别代表n个标识符。每个标识符都有自己的检索频率,也就是检索概率,记为:Pi(i=1,2,...,n)。
(2)不成功检索:
X不是标识符集合中的任何元素,不成功检索的情况有n+1种,同样的记不成功检索的概率为Qi(i=0,1,2,...,n)。
注:不成功检索的情况包括第一个元素的左边,和最后一个元素的右边,所以有n+1中情况。
同时,如果搜索一个元素,整个事件的概率空间为:{找到了,没找到},所以有:
标识符检索所需要的次数:
成功检索:等于结点的级数(或结点到根的距离+1)。
不成功检索:在二分检索树中引入外部结点,外部结点作为“内部结点树”的“叶子结点”,每个外部结点代表一种不成功的检索的情况。不成功检索时比较的次数等于外部结点的级数-1(外部结点到树根的距离)。
例如:
(1) (2)
(2)
(1)AVG成功=(1+2+2+3+4)/5=2.4
AVG不成功=(2+2+2+3+4+4)/6=2.83
AVG=[(1+2+2+3+4)+(2+2+2+3+4+4)]/11=2.64
(2)略.
通过上面的两棵二分检索树可以看出,不同形态的二分检索树的检索性能是不同的。所以就要构建最优二分检索树(Optimal—Binary Search Tree),使检索成本最小。
二分检索树的预期成本:
平均检索成本=Σ每种情况出现的概率×该情况下所需的比较次数。
平均检索成本的构成:成功检索成本+不成功检索成本。
成功检索成本:ΣP(i)*level(ai))(i=1,2,...,n)。
不成功检索成本:ΣQ(i)*(level(Ei)-1)(i=0,1,2,...,n)。其中Ei是不成功检索的等价类,共有n+1个等价类Ei(0≤i≤n)。
预期总的成本公式如下:![]()
求最优二分检索树的问题,就是求解一个预期成本最小的二分检索树。
求解最优二分检索树的方法有两种:
(1)枚举法
(2)动态规划策略
正题:
用动态规划策略构建一棵最优二分检索树。
首先回顾一下动态规划的相关知识:
动态规划是通过组合子问题的解而解决整个问题的,不同于分治算法的是动态规划适用于子问题不是独立的情况。动态规划算法对每个子子问题只求解一次,将其结果保存在一张表中。
把构造二分检索树看成一系列的决策过程,首先决策树根,如果ak是该树的根,那么内结点a1,a2,...a(k-1)和外部结点E0,E1,...E(k-1)将位于ak的左子树中;其余的结点位于右子树中。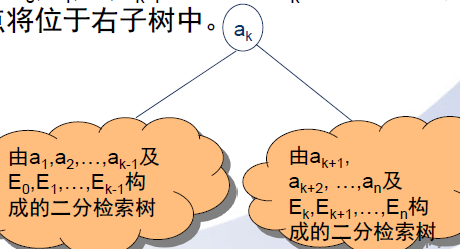
这样我们很容易计算出两个子树的根本:
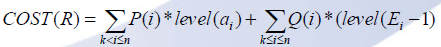
注意:左、右子树中所有结点的级数是相对于这棵子树的根测定。这样的话,比相对于原树的根的测定值少1。为什么这么计算?因为动态规划是把大的问题分解为性质形同的小的问题,只不过这些问题不是独立的。这样的话,每次的决策都要补左子树和右子树的成本差额![]()
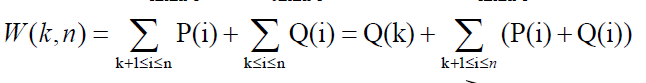
这样的话原二分检索树的预期成本可以表示为: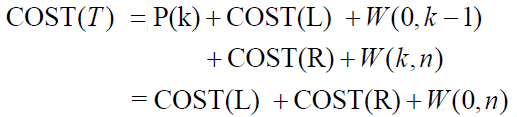
这个公式就是我们用动态规划构建最优二分检索树的基本,也就是把一个原本的二分检索树的成本,划分成了它的左子树和右子树的成本,加上一个差值。当我们从最小的子树加上来,能够使得COST(T)最小的那个树就是最优二分检索树。
引入一个记号:记由ai+1,ai+2,…,aj和Ei,Ei+1,…,Ej构成的最优二分检索树的预期成本为C(i, j),并不知道谁是根结点。
如果二分检索树以ak为根,则:
COST(L)=C(0,k-1)因为左子树是:a1,...,a(k-1)和E0,...E(k-1)。
COST(R)=C(k,n)因为右子树是:a(k+1),...an和Ek,...En。
所以:
![]()
这个公式的含义就是让这n个字符轮流做根结点,最后的最优二分检索树的根就是产生最小成本的那个根结点,依次的迭代下去。
其中W(0,n)=P(K)+W(0,k-1)+W(k,n)。
推而广之:对于任意的i,j。我们有:
那么我们用动态规划构建最优二分检索树的思想基础就构建起来了:
动态规划的最优性原理是这样的:
过程的最优决策序列有这样的性质,无论过程的初始状态和初始决策是什么,其他的决策都必须相对于初始决策所产生的状态构成一个最优决策序列。
也就是说,我们要找一个字符集的整个的过程的最优决策序列,那么这个最优决策序列一定包含了许多小的最优决策序列。说白了就是,5个字符的最优决策序列一定包含4个字符、3个字符、2个字符、1个字符的最优决策序列。
所以我们在求C(i,j)的过程中,先令j-i=1,找到一个字符的最优决策序列,然后令j-i=2,找到两个字符的最优决策序列,扩展开来就能找到n个字符的最优决策序列。求解的初始值:

我们在构建最优二分检索树的时候,不仅要计算出他的最小成本,还要知道这棵最优二分检索树的形态。在计算C(i, j)的过程中,记下使之取得最小值的k值,即树Tij的根,记为R(i, j),从而能推导出这个树的形态。
综上所述,构建一个最优二分检索树的递推公式为:

实例
设n=4,且(a1,a2,a3,a4)=(do if read while)。P[1:4] = (3, 3, 1, 1),Q[0:4] = (2, 3, 1, 1, 1),构造最优二分检索树。
提示:
初始 W(i, i)=Q(i)
C(i, i)=0
R(i, i)=0
且有,W(i, j)=P(j)+Q(j)+W(i,j-1)
构造的结果: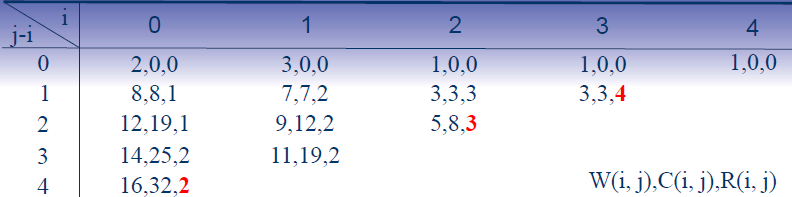
说明:j-i依次等于0,1,2,3,4表明先构造含有一个字符的最优二分检索树,然后依次构造含有2个字符,3个字符,4个字符的最优二分检索树。i从0变化的4表明当j-1的值固定后,也就是字符的个数确定了,依次实验不同的字符找到产生最小成本的字符段。R(i,j)表示在a(i+1)到aj的字符段中,选哪个能够产生最小成本,它用来构建最后的最优二分检索树。
最后的结果:C(0,4)=32表示最优二分检索树的成本为32,通过R(i,j)构建最优二分检索树:
T04=2 =>T01(左子树),T24(右子树)(在0~4这段字符集中,第2个作为根能最优,一下解释类似)
T01=1 =>T00(左子树),T11(右子树)
T24=3 =>T22(左子树),T34(右子树)
T34=4 =>T33(左子树),T44(右子树)
所以最后的树为:
在程序实现之前,分析一下它的时间复杂度:
对于j-i=m的情况下,有n-m+1个C(i, j)要计算。
C(i,j)的计算:O(m)。每个C(i, j)要求找出m个量中的最小值。
则,n-m+1个C(i, j)的计算时间:
O(nm-m2)
对所有可能的m,则总的时间复杂度为:
上面看到,计算C(i,j)的时间复杂度为O(m),引入克努特方法,最优的k∈[R(i, j-1),R(i+1, j)]。能在几乎O(1)的时间复杂度内找到k,所以C(i,j)的计算时间复杂度为O(1)。这样的话,构造最优二分检索树的时间复杂度为O(n^2)。
代码:

