
前端知识杂烩(Javascript篇)
2.JavaScript的数据类型都有什么?
3.请描述一下 cookies,sessionStorage 和 localStorage 的区别?
4.webSocket如何兼容低浏览器?(阿里)
5.this和它声明环境无关,而完全取决于他的执行环境
6.JavaScript异步编程常用的四种方法
7、在严格模式('use strict')下进行 JavaScript 开发有神马好处?
8、神马是 NaN,它的类型是神马?怎么测试一个值是否等于 NaN?
9、解释一下下面代码的输出
10、实现函数 isInteger(x) 来判断 x 是否是整数
11.前端模块化-AMD(异步模块定义)规范与CMD(通用模块定义)规范(期待ES6模块一统天下)
12.JS跨域汇总
13.两张图让你看懂“==”与if()
14.JS中创建对象的几种方式(此处只列举,详情见红宝书《JS高级程序设计》)
15.JS中实现继承的几种方式(此处只列举,详情见红宝书《JS高级程序设计》)
16.JS中函数的几种创建形式。
17.call与apply的异同?
18.JavaScript中常见的内存泄漏及解决方案
19.原生的ajax请求处理流程
20.闭包的应用场景(草稿-非正式)
21.使用JS事件委托的优点和缺点
22.前端模块化开发作用及基本原理(部分可参考第11题)
23.Js中访问对象属性用点和用中括号有什么不同
24.Javascript垃圾回收方法
25.说说你对闭包的理解
26.DOM操作——怎样添加、移除、移动、复制、创建和查找节点。
1. JavaScript是一门什么样的语言,它有什么特点?
JavaScript 是一种脚本语言,官方名称为 ECMAScript(因定义语言的标准为 ECMA-262)。JS 的主要特点:1. 语法类似于常见的高级语言,如 C 和 Java;2. 脚本语言,不需要编译就可以由解释器直接运行;3. 变量松散定义,属于弱类型语言;4. 面向对象的。 JS 最初是为网页设计而开发的,现在也是 Web 开发的重要语言。它支持对浏览器(浏览器对象模型,BOM)和 HTML 文档(文档对象模型,DOM)进行操作,而使网页呈现动态的交互特性。 严格的说,JS 只是 ECMAScript 的一种实现,是 ECMAScript 和 BOM、DOM 组成的一种 Web 开发技术。
2.JavaScript的数据类型都有什么?
基本数据类型:String,Boolean,Number,Undefined, Null
引用数据类型:Object(Array,Date,RegExp,Function)
那么问题来了,如何判断某变量是否为数组数据类型?
- 方法一.判断其是否具有“数组性质”,如slice()方法。可自己给该变量定义slice方法,故有时会失效
- 方法二.obj instanceof Array 在某些IE版本中不正确
- 方法三.方法一二皆有漏洞,在ECMA Script5中定义了新方法Array.isArray(), 保证其兼容性,最好的方法如下:
function isArray(value){return Object.prototype.toString.call(value) == "[object Array]";}
3.请描述一下 cookies,sessionStorage 和 localStorage 的区别?
cookie是网站为了标示用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。cookie数据始终在同源的http请求中携带(即使不需要),记会在浏览器和服务器间来回传递。sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存。
- 存储大小:
(1) cookie数据大小不能超过4k。
(2)sessionStorage和localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大。 - 有期时间:
(1) localStorage存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;
(2)sessionStorage 数据在当前浏览器窗口关闭后自动删除。
(3) cookie设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭
4.webSocket如何兼容低浏览器?(阿里)
- Adobe Flash Socket 、
- ActiveX HTMLFile (IE) 、
- 基于 multipart 编码发送 XHR 、
- 基于长轮询的 XHR
5.this和它声明环境无关,而完全取决于他的执行环境
var name = ‘罗恩’;var aaa = {name: ‘哈利’,say: function () {console.log(this.name);}}var bbb = {name: ‘赫敏’,say: aaa.say}var ccc = aaa.say;aaa.say(); //哈利bbb.say(); //赫敏ccc(); //罗恩
6.JavaScript异步编程常用的四种方法
- 1.回调函数
f1(f2);
回调函数是异步编程的基本方法。其优点是易编写、易理解和易部署;缺点是不利于代码的阅读和维护,各个部分之间高度耦合 (Coupling),流程比较混乱,而且每个任务只能指定一个回调函数。 - 2.事件监听
f1.on('done',f2);
事件监听即采用事件驱动模式,任务的执行不取决于代码的顺序,而取决于某个事件是否发生。其优点是易理解,可以绑定多个事件,每个事件可以指定多个回调函数,可以去耦合, 有利于实现模块化;缺点是整个程序都要变成事件驱动型,运行流程会变得不清晰。 - 3.发布/订阅
f1: jQuery.publish("done");
f2: jQuery.subscribe("done", f2);
假定存在一个"信号中心",某个任务执行完成,就向信号中心"发布"(publish)一个信号,其他任务可以向信号中心"订阅"(subscribe)这个信号,从而知道什么时候自己可以开始执行,这就叫做 "发布/订阅模式" (publish-subscribe pattern),又称 "观察者模式" (observer pattern)。该 方法的性质与"事件监听"类似,但其优势在于可以 通过查看"消息中心",了解存在多少信号、每个信号有多少订阅者,从而监控程序的运行。 - 4.promise对象
f1().then(f2);
Promises对象是CommonJS工作组提出的一种规范,目的是为异步编程提供 统一接口 ;思想是, 每一个异步任务返回一个Promise对象,该对象有一个then方法,允许指定回调函数。其优点是回调函数是链式写法,程序的流程非常清晰,而且有一整套的配套方法, 可以实现许多强大的功能,如指定多个回调函数、指定发生错误时的回调函数, 如果一个任务已经完成,再添加回调函数,该回调函数会立即执行,所以不用担心是否错过了某个事件或信号;缺点就是编写和理解相对比较难。
7、在严格模式('use strict')下进行 JavaScript 开发有神马好处?
- 消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的Javascript做好铺垫。
8、神马是 NaN,它的类型是神马?怎么测试一个值是否等于 NaN?
NaN 是 Not a Number 的缩写,JavaScript 的一种特殊数值,其类型是 Number,可以通过 isNaN(param) 来判断一个值是否是 NaN:
console.log(isNaN(NaN)); //trueconsole.log(isNaN(23)); //falseconsole.log(isNaN('ds')); //trueconsole.log(isNaN('32131sdasd')); //trueconsole.log(NaN === NaN); //falseconsole.log(NaN === undefined); //falseconsole.log(typeof NaN); //numberconsole.log(Object.prototype.toString.call(NaN)); //[object Number]
ES6 中,isNaN() 成为了 Number 的静态方法:Number.isNaN()
9、解释一下下面代码的输出
console.log(0.1 + 0.2); //0.30000000000000004console.log(0.1 + 0.2 == 0.3); //false
JavaScript 中的 number 类型就是浮点型,JavaScript 中的浮点数采用IEEE-754 格式的规定,这是一种二进制表示法,可以精确地表示分数,比如1/2,1/8,1/1024,每个浮点数占64位。但是,二进制浮点数表示法并不能精确的表示类似0.1这样 的简单的数字,会有舍入误差。
由于采用二进制,JavaScript 也不能有限表示 1/10、1/2 等这样的分数。在二进制中,1/10(0.1)被表示为0.00110011001100110011…… 注意 0011 是无限重复的,这是舍入误差造成的,所以对于 0.1 + 0.2 这样的运算,操作数会先被转成二进制,然后再计算:
0.1 => 0.0001 1001 1001 1001…(无限循环)0.2 => 0.0011 0011 0011 0011…(无限循环)
双精度浮点数的小数部分最多支持 52 位,所以两者相加之后得到这么一串 0.0100110011001100110011001100110011001100…因浮点数小数位的限制而截断的二进制数字,这时候,再把它转换为十进制,就成了 0.30000000000000004。
对于保证浮点数计算的正确性,有两种常见方式。
- 一是先升幂再降幂:
function add(num1, num2){let r1, r2, m;r1 = (''+num1).split('.')[1].length;r2 = (''+num2).split('.')[1].length;m = Math.pow(10,Math.max(r1,r2));return (num1 * m + num2 * m) / m;}console.log(add(0.1,0.2)); //0.3console.log(add(0.15,0.2256)); //0.3756
- 二是是使用内置的
toPrecision()和toFixed()方法,**注意,方法的返回值字符串。
function add(x, y) {return x.toPrecision() + y.toPrecision()}console.log(add(0.1,0.2)); //"0.10.2"
10、实现函数 isInteger(x) 来判断 x 是否是整数
可以将 x 转换成10进制,判断和本身是不是相等即可:
function isInteger(x) {return parseInt(x, 10) === x;}
ES6 对数值进行了扩展,提供了静态方法 isInteger() 来判断参数是否是整数:
Number.isInteger(25) // trueNumber.isInteger(25.0) // trueNumber.isInteger(25.1) // falseNumber.isInteger("15") // falseNumber.isInteger(true) // false
JavaScript能够准确表示的整数范围在 -2^53 到 2^53 之间(不含两个端点),超过这个范围,无法精确表示这个值。ES6 引入了Number.MAX_SAFE_INTEGER 和 Number.MIN_SAFE_INTEGER这两个常量,用来表示这个范围的上下限,并提供了 Number.isSafeInteger() 来判断整数是否是安全型整数。
11.前端模块化-AMD(异步模块定义)规范与CMD(通用模块定义)规范(期待ES6模块一统天下)
AMD 是 RequireJS 在推广过程中对模块定义的规范化产出。CMD 是 SeaJS 在推广过程中对模块定义的规范化产出。主要区别是
- 1. 对于依赖的模块,AMD 是提前执行,CMD 是延迟执行。不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)。CMD 推崇 as lazy as possible.
AMD和CMD最大的区别是对依赖模块的执行时机处理不同,注意不是加载的时机或者方式不同
很多人说requireJS是异步加载模块,SeaJS是同步加载模块,这么理解实际上是不准确的,其实加载模块都是异步的,只不过AMD依赖前置,js可以方便知道依赖模块是谁,立即加载,而CMD就近依赖,需要使用把模块变为字符串解析一遍才知道依赖了那些模块,这也是很多人诟病CMD的一点,牺牲性能来带来开发的便利性,实际上解析模块用的时间短到可以忽略
为什么我们说两个的区别是依赖模块执行时机不同,为什么很多人认为AMD是异步的,CMD是同步的(除了名字的原因。。。)
同样都是异步加载模块,AMD在加载模块完成后就会执行改模块,所有模块都加载执行完后会进入require的回调函数,执行主逻辑,这样的效果就是依赖模块的执行顺序和书写顺序不一定一致,看网络速度,哪个先下载下来,哪个先执行,但是主逻辑一定在所有依赖加载完成后才执行
CMD加载完某个依赖模块后并不执行,只是下载而已,在所有依赖模块加载完成后进入主逻辑,遇到require语句的时候才执行对应的模块,这样模块的执行顺序和书写顺序是完全一致的
这也是很多人说AMD用户体验好,因为没有延迟,依赖模块提前执行了,CMD性能好,因为只有用户需要的时候才执行的原因 - 2. CMD 推崇依赖就近,只有在用到某个模块的时候再去require;AMD 推崇依赖前置在定义模块的时候就要声明其依赖的模块。看代码:
- 3.
AMD推荐的风格通过返回一个对象做为模块对象,CommonJS的风格通过对module.exports或exports的属性赋值来达到暴露模块对象的目的。顺便提一下:CommonJS是适用于服务器端的规范,NodeJS即是它的一种实现,CommonJS定义的模块分为:{模块引用(require)} {模块定义(exports)} {模块标识(module)}。 require()用来引入外部模块;exports对象用于导出当前模块的方法或变量,唯一的导出口;module对象就代表模块本身。
//CommonJS规范写法//sum.jsexports.sum = function(){//做加操作};//calculate.jsvar math = require('sum');exports.add = function(n){return math.sum(val,n);};
// CMDdefine(function(require, exports, module) {var a = require('./a')a.doSomething()// 此处略去 100 行var b = require('./b') // 依赖可以就近书写b.doSomething();//本模块的导出接口exports.each = function (arr) {// 实现代码};exports.log = function (str) {// 实现代码};})
// AMD就只有一个接口:define(id?,dependencies?,factory);define(['./a', './b'], function(a, b) { // 依赖必须一开始就写好a.doSomething()// 此处略去 100 行b.doSomething();//返回本模块的导出接口var myModule = {doStuff:function(){console.log('Yay! Stuff');}}return myModule;...})//AMD还有一个require方法主要用来在顶层 JavaScript 文件中或须要动态读取依赖时加载代码require(['foo', 'bar'], function ( foo, bar ) {// 这里写其余的代码foo.doSomething();//返回本模块的导出接口var myModule = {doStuff:function(){console.log('Yay! Stuff');}}return myModule;});
12.JS跨域汇总
1.通过jsonp跨域
- 只能使用 GET 方法发起请求,这是由于
script标签自身的限制决定的。 - 不能很好的发现错误,并进行处理。与 Ajax 对比,由于不是通过 XmlHttpRequest 进行传输,所以不能注册 success、 error 等事件监听函数。
2.通过修改document.domain来跨子域(iframe)
3.隐藏的iframe+window.name跨域
4.iframe+跨文档消息传递(XDM)
5.跨域资源共享 CORS
- CORS 除了 GET 方法外,也支持其它的 HTTP 请求方法如 POST、 PUT 等。
- CORS 可以使用 XmlHttpRequest 进行传输,所以它的错误处理方式比 JSONP 好。
- JSONP 可以在不支持 CORS 的老旧浏览器上运作。
6.Web Sockets
跨域请求并非是浏览器限制了发起跨站请求,而是请求可以正常发起,到达服务器端,但是服务器返回的结果会被浏览器拦截。
13.两张图让你看懂“==”与if()
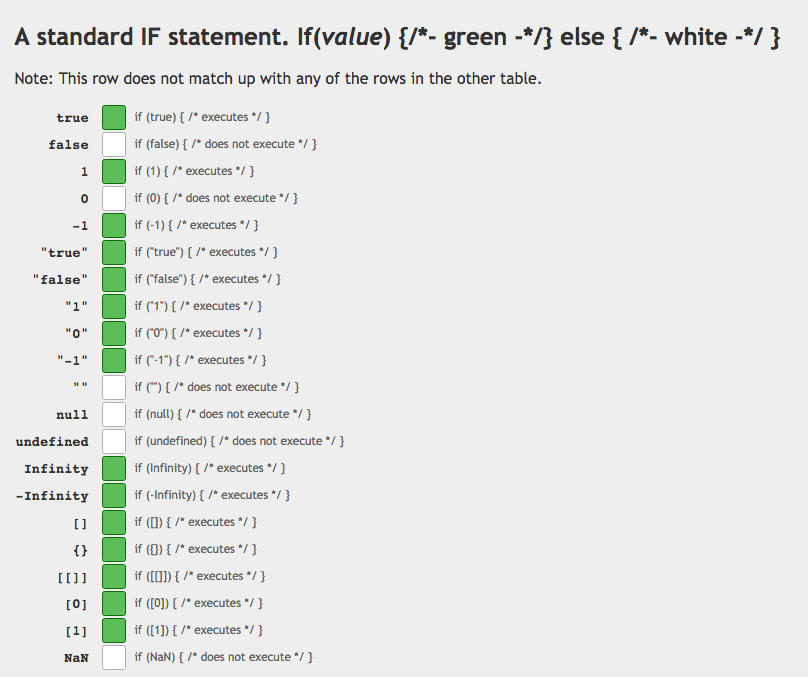
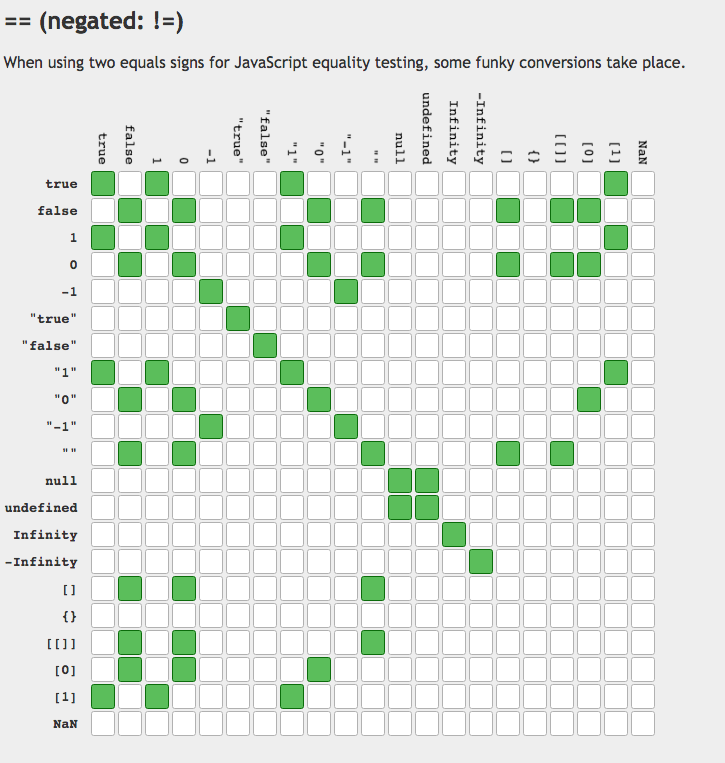
14.JS中创建对象的几种方式(此处只列举,详情见红宝书《JS高级程序设计》)
- 创建对象
具体参考:在这个看脸的世界,该如何优雅的创建JS对象
1.对象字面量
2.Object构造函数
mygirl=new Object();
ES5新方法构建对象,再添加属性
3.工厂模式
工厂模式虽然解决了创建多个相似对象的问题,但却没有解决对象识别的问题(即怎样知道一个对象的类型)。
4.构造函数模式
使用构造函数的主要问题,就是每个方法都要在每个实例上重新创建一遍。
5.原型模式
function Girl(){
}
在Girl.prototype上添加属性和方法
var mygirl=new Girl();
特点:原型中所有属性是被所有实例共享的,这种共享对于函数非常合适,但是对于基本属性就显得不是很合适,尤其是对于组合使用原型模式和构造函数创建对象包含引用类型值的属性来说,问题就比较突出了。
6.组合使用原型模式和构造函数创建对象(推荐)
创建自定义类型的最常见方式,就是组合使用构造函数模式与原型模式。构造函数模式用于定义实例属性,而原型模式用于定义方法和共享的属性。
7.动态原型模式
相对于组合模式,就是把原型上添加方法的步骤放在构造函数中,然后根据构造函数中是否已经存在该方法来决定添不添加
8.寄生构造函数模式
相对于工厂模式就是把函数当做构造函数调用
9.稳妥构造函数模式
15.JS中实现继承的几种方式(此处只列举,详情见红宝书《JS高级程序设计》)
1.借助原型链
function SuperType(){this.colors = ["red", "blue", "green"];}function SubType(){}//继承了 SuperTypeSubType.prototype = new SuperType();
使用原型链会出现两个问题,一是如果原型中包含引用类型值,子类所有实例会共享这个引用类型;二是没有办法在不影响所有对象实例的情况下,给超类型的构造函数传递参数。
2.借助构造函数
function SuperType(name){this.name = name;}function SubType(){//继承了 SuperType,同时还传递了参数SuperType.call(this, "Nicholas");//实例属性this.age = 29;}
能够解决第一种方法原型中包含引用类型值所带来问题,也能向超类型构造函数传递参数。问题是如果仅仅是借用构造函数,那么也将无法避免构造函数模式存在的问题——方法都在构造函数中定义,因此函数复用就无从谈起了。
3.组合继承(推荐)
组合继承( combination inheritance),有时候也叫做伪经典继承,指的是将原型链和借用构造函数的技术组合到一块,从而发挥二者之长的一种继承模式。其背后的思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有它自己的属性。下面来看一个例子。
function SuperType(name){this.name = name;this.colors = ["red", "blue", "green"];}SuperType.prototype.sayName = function(){alert(this.name);};function SubType(name, age){//继承属性SuperType.call(this, name);this.age = age;}//继承方法SubType.prototype = new SuperType();SubType.prototype.constructor = SubType;SubType.prototype.sayAge = function(){alert(this.age);};var instance1 = new SubType("Nicholas", 29);instance1.colors.push("black");alert(instance1.colors); //"red,blue,green,black"instance1.sayName(); //"Nicholas";instance1.sayAge(); //29var instance2 = new SubType("Greg", 27);alert(instance2.colors); //"red,blue,green"instance2.sayName(); //"Greg";instance2.sayAge(); //27
4.原型式继承
function object(o){function F(){}F.prototype = o;return new F();}
在 object() 函数内部,先创建了一个临时性的构造函数,然后将传入的对象作为这个构造函数的原型,最后返回了这个临时类型的一个新实例。ECMAScript 5 通过新增 Object.create() 方法规范化了原型式继承。
var person = {name: "Nicholas",friends: ["Shelby", "Court", "Van"]};var anotherPerson = Object.create(person);anotherPerson.name = "Greg";anotherPerson.friends.push("Rob");alert(person.friends); //"Shelby,Court,Van,Rob"
在没有必要兴师动众地创建构造函数,而只想让一个对象与另一个对象保持类似的情况下,原型式继承是完全可以胜任的。不过别忘了,包含引用类型值的属性始终都会共享相应的值,就像使用原型模式一样。
5.寄生式继承
function createAnother(original){var clone = object(original); //通过调用函数创建一个新对象,也可以使用其他类似的方法clone.sayHi = function(){ //以某种方式来增强这个对象alert("hi");};return clone; //返回这个对象}
6.寄生组合式继承
function inheritPrototype(subType, superType){var prototype = object(superType.prototype); //创建对象prototype.constructor = subType; //增强对象subType.prototype = prototype; //指定对象}
16.JS中函数的几种创建形式。
1、声明函数
最普通最标准的声明函数方法,包括函数名及函数体。
function fn1(){}
2、创建匿名函数表达式
创建一个变量,这个变量的内容为一个函数
var fn1=function (){}
注意采用这种方法创建的函数为匿名函数,即没有函数name
3、创建具名函数表达式
创建一个变量,内容为一个带有名称的函数
var fn1=function xxcanghai(){};
注意:具名函数表达式的函数名只能在创建函数内部使用
4、Function构造函数
可以给 Function 构造函数传一个函数字符串,返回包含这个字符串命令的函数,此种方法创建的是匿名函数。

5、自执行函数
(function(){alert(1);})();
(function fn1(){alert(1);})();
自执行函数属于上述的“函数表达式”,规则相同
参考:http://www.cnblogs.com/xxcanghai/p/4991870.html
17.call与apply的异同?
call方法与apply方法的作用是一样的,都是为了改变函数内部的this指向。区别仅在于传入的参数形式的不同。
apply函数接受两个参数,第一个参数指定了函数体内this对象的指向,第二个参数为一个可以下标访问的集合,这个集合可以使数组,也可以是类数组,apply方法把这个集合中的元素作为参数传递给被调用的函数。
call方法传入的参数数量是不固定的,跟apply相同的是,第一个参数也是代表函数体内this对象的指向,从第二个参数开始往后,是一组参数序列,每个参数被依次传入函数。
Notes
- call方法不是说不能接受数组做参数,而是将数组参数当做一个整体,作为参数序列的一部分,而apply方法是将数组中的元素当做参数
- call和apply第一个参数为null时,函数体内的this指向宿主对象,浏览器中则为window,在严格模式下,仍为null.
18.JavaScript中常见的内存泄漏及解决方案
现代的浏览器大多采用标记清除的方法来进行垃圾回收,其基本步骤如下:
- 垃圾回收器创建了一个“roots”列表。Roots 通常是代码中全局变量的引用。JavaScript 中,“window” 对象是一个全局变量,被当作 root 。window 对象总是存在,因此垃圾回收器可以检查它和它的所有子对象是否存在(即不是垃圾);
- 所有的 roots 被检查和标记为激活(即不是垃圾)。所有的子对象也被递归地检查。从 root 开始的所有对象如果是可达的,它就不被当作垃圾。
- 所有未被标记的内存会被当做垃圾,收集器现在可以释放内存,归还给操作系统了。
内存泄漏主因是不需要的引用未被及时清除。下列列举几种常见的内存泄漏及其解决方案
- 意外的全局变量
尤其当全局变量用于临时存储和处理大量信息时,需要多加小心。如果必须使用全局变量存储大量数据时,确保用完以后把它设置为 null 或者重新定义。与全局变量相关的增加内存消耗的一个主因是缓存。缓存数据是为了重用,缓存必须有一个大小上限才有用。高内存消耗导致缓存突破上限,因为缓存内容无法被回收。另外启用严格模式解析JavaScript,也可以避免意外的全局变量。 - 循环引用
循环引用很常见且大部分情况下是无害的,但当参与循环引用的对象中有DOM对象或者ActiveX对象时,循环引用将导致内存泄露。老版本的 IE 是无法检测 DOM 节点与 JavaScript 代码之间的循环引用,会导致内存泄漏,。如今,现代的浏览器(包括 IE 和 Microsoft Edge)使用了更先进的垃圾回收算法,已经可以正确检测和处理循环引用了。 - 循环引用和闭包
function bindEvent(){var obj=document.createElement("XXX");obj.onclick=function(){//Even if it's a empty function}}
函数将间接引用所有它能访问的对象。obj.onclick这个函数中 可以访问外部的变量obj 所以他引用了obj,而obj又引用了它,因此这个事件绑定将会造成内存泄露.解决办法是可以把函数卸载外面。
function bindEvent(){var obj=document.createElement("XXX");obj.onclick=onclickHandler;}function onclickHandler(){//do something}
另外对于事件应该在unload中解除循环引用的属性置为null
- 某些DOM操作
从外到内执行appendChild。这时即使调用removeChild也无法释放。范例:
var parentDiv = document.createElement("div");var childDiv = document.createElement("div");document.body.appendChild(parentDiv);parentDiv.appendChild(childDiv);
解决方法:
从内到外执行appendChild:
var parentDiv = document.createElement("div");var childDiv = document.createElement("div");parentDiv.appendChild(childDiv);document.body.appendChild(parentDiv);
- 被遗忘的计时器或回调函数
在 JavaScript 中使用 setInterval 非常平常。一段常见的代码:
var someResource = getData();setInterval(function() {var node = document.getElementById('Node');if(node) {// 处理 node 和 someResourcenode.innerHTML = JSON.stringify(someResource));}}, 1000);
此例说明了什么:与节点或数据关联的计时器不再需要,node 对象可以删除,整个回调函数也不需要了。可是,计时器回调函数仍然没被回收(计时器停止才会被回收)。同时,someResource 如果存储了大量的数据,也是无法被回收的。
参考:
Javascript内存泄漏
4类 JavaScript 内存泄漏及如何避免
如何检测浏览器内存泄漏
Chrome 提供了一套很棒的检测 JavaScript内存占用的工具。与内存相关的两个重要的工具:timeline 和 profiles。具体参考Chrome开发者工具之JavaScript内存分析
19.原生的ajax请求处理流程
Ajax 的全称是Asynchronous JavaScript and XML,其中,Asynchronous 是异步的意思,它有别于传统web开发中采用的同步的方式。
Ajax的原理简单来说通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据,然后用javascript来操作DOM而更新页面。
XMLHttpRequest是ajax的核心机制,它是在IE5中首先引入的,是一种支持异步请求的技术。简单的说,也就是javascript可以及时向服务器提出请求和处理响应,而不阻塞用户。达到无刷新的效果。
XMLHttpRequest这个对象的属性有:
- onreadystatechang 每次状态改变所触发事件的事件处理程序。
- responseText 从服务器进程返回数据的字符串形式。
- responseXML 从服务器进程返回的DOM兼容的文档数据对象。
- status 从服务器返回的数字代码,比如常见的404(未找到)和200(已就绪)
- status Text 伴随状态码的字符串信息
- readyState 对象状态值
- 0 (未初始化) 对象已建立,但是尚未初始化(尚未调用open方法)
- 1 (初始化) 对象已建立,尚未调用send方法
- 2 (发送数据) send方法已调用,但是当前的状态及http头未知
- 3 (数据传送中) 已接收部分数据,因为响应及http头不全,这时通过responseBody和responseText获取部分数据会出现错误,
- 4 (完成) 数据接收完毕,此时可以通过通过responseXml和responseText获取完整的回应数据
function createXHR() {if (XMLHttpRequest) {return new XMLHttpRequest();}else if (ActiveObject) {var versions=["MSXML2.XMLHttp.6.0","MSXML2.XMLHttp.3.0","MSXML2.XMLHttp"];for (var i = 0,len=versions.length; i < len; i++) {try{var xhr=new ActiveObject(versions[i]);if (xhr) {return xhr;}}catch(e){return false;}}}else{throw new Error("No XHR object available.");}}var xhr=createXHR();xhr.onreadystatechange=function(){if (xhr.readyState===4) {if ((xhr.status>=200 && xhr.status<300)||xhr.status===304) {console.log(xhr.responseText);}else{console.log("Request was unsuccessful:"+xhr.status);}}};/*Get请求数据键值需要使用encodeURIComponent编码*/xhr.open("get","example.txt?name1=value1&name2=value2",true);//true表示异步xhr.setRequestHeader("Myheader","Myvaule");//在open方法之后,send方法之前设置请求头xhr.send(null);/*POST请求数据键值需要使用encodeURIComponent编码*/xhr.open("post","example.php",true);//true表示异步xhr.setRequestHeader("Myheader","Myvaule");//在open方法之后,send方法之前设置请求头/*send方法的参数为要发送的数据,格式为name1=value1&name2=value2;如果想模拟表单,可以添加请求头Content-type:application/x-www-form-urlencoded*/xhr.send(data);
20.闭包的应用场景(草稿-非正式)
1.使用闭包代替小范围使用全局变量
2.函数外或在其他函数中访问某一函数内部的参数
3.在函数执行之前为要执行的函数提供具体参数
如:setTimeOut
setInterval
xhr.addEventListener("load",functionName, false);
如果functionName需要参数 怎么办呢
function functionNameFnc(a){ return function(){//做functionName该做的事情 已经可以用参数了 a } } xhr.addEventListener("load",functionNameFnc(a), false);
4.为节点循环绑定click事件,在事件函数中使用当次循环的值或节点,而不是最后一次循环的值或节点
4.封装私有变量
红宝书中提供:
1.使用闭包可以在JavaScript中模拟块级作用域
2.闭包可以用于在对象中创建私有变量;
函数绑定、函数柯里化
21.使用JS事件委托的优点和缺点
什么???不知道事件委托,呵呵!!自行百度或者查阅红宝书
优点
- 1.管理的函数变少了。不需要为每个元素都添加监听函数。对于同一个父节点下面类似的子元素,可以通过委托给父元素的监听函数来处理事件。
- 2.可以方便地动态添加和修改元素,不需要因为元素的改动而修改事件绑定。
- 3.JavaScript和DOM节点之间的关联变少了,这样也就减少了因循环引用而带来的内存泄漏发生的概率。
缺点
- 1.事件管理代码有成为性能瓶颈的风险,所以尽量使它能够短小精悍;
- 2.不是所有的事件都能冒泡的。blur、focus、load和unload不能像其它事件一样冒泡。事实上blur和focus可以用事件捕获而非事件冒泡的方法获得(在IE之外的其它浏览器中);
- 3.在管理鼠标事件的时候有些需要注意,如果处理mousemove这样的事件的话遇上性能瓶颈的风险就很大,因为mousemove事件触发非常频繁,而且mouseout则因为其怪异的表现而变得很难用事件代理来管理。
- 4.如果把所有事件都用代理就可能会出现事件误判,即本不该绑定事件的元素被绑上了事件。
22.前端模块化开发作用及基本原理(部分可参考第11题)
前端模块化开发的作用
- 提高可维护性。模块化可以让每个文件的职责单一,非常有利于代码的维护
- 解决变量污染、命名空间问题
以前一般定义一个全局的对象来包裹所有的变量和方法var Util = {}; - 解决文件依赖问题
比如下面的一个例子,在dialog.js里需要用到util.js里的函数就必须在dialog.js之前引入util.js,使用模块化加载可以在dialog.js模块里引入util.js
<script src="util.js"></script><script src="dialog.js"></script>
使用requireJS加载模块的简要流程(网上找的,叙述的不是很好,大概那个意思)
1.我们在使用requireJS时,都会把所有的js交给requireJS来管理,也就是我们的页面上只引入一个require.js,把data-main指向我们的main.js。
2.通过我们在main.js里面定义的require方法或者define方法,requireJS会把这些依赖和回调方法都用一个数据结构保存起来。
3.当页面加载时,requireJS会根据这些依赖预先把需要的js通过document.createElement的方法引入到dom中,这样,被引入dom中的script便会运行。
4.由于我们依赖的js也是要按照requireJS的规范来写的,所以他们也会有define或者require方法,同样类似第二步这样循环向上查找依赖,同样会把他们村起来。
5.当我们的js里需要用到依赖所返回的结果时(通常是一个key value类型的object),requireJS便会把之前那个保存回调方法的数据结构里面的方法拿出来并且运行,然后把结果给需要依赖的方法。
模块加载基本原理
- 1.路径分析:id即路径原则。
通常我们的入口是这样的: require( [ 'a', 'b' ], callback ) 。这里的 'a'、'b' 都是 ModuleId。通过 id 和路径的对应原则,加载器才能知道需要加载的 js 的路径。在这个例子里,就是 baseUrl + 'a.js' 和 baseUrl + 'b.js'。但 id 和 path 的对应关系并不是永远那么简单,比如在 AMD 规范里就可以通过配置 Paths 来给特定的 id 指配 path。 - 2.加载脚本内容:createElement('script') & appendChild
知道路径之后,就需要去请求。一般是通过 createElement('script') & appendChild 去请求。这个大家都知道,不多说。对于同源的文件模块,有的加载器也会通过 AJAX 去请求脚本内容。
一般来说,需要给<script>设置一个属性用来标识模块 id, 作用后面会提到。 3.获取当前文件路径:document.currentScript
获取到正确的文件路径,才能正确判断依赖文件路径
a.js 里可能是 define( id, factory ) 或者是 define( factory ),后者被称为匿名模块。那么当 define(factory) 被执行的时候,我们怎么知道当前被定义的是哪个模块呢,具体地说,这个匿名模块的实际模块 id 是什么? 答案是通过 document.currentScript 获取当前执行的<script>,然后通过上面给 script 设置的属性来得到模块 id。需要注意的是,低级浏览器是不支持 currentScript 的,这里需要进行浏览器兼容。还可以通过 script.onload 将script.src带过去来处理这个事情。4.依赖分析
在继续讲之前,需要先简单介绍下模块的生命周期。模块在被 Define 之后并不是马上可以用了,在你执行它的 factory 方法来生产出最终的 export 之前,你需要保证它的依赖是可用的。那么首先就要先把依赖分析出来。简单来说,就是通过 toString 这个方法得到 factory 的内容,然后用正则去匹配其中的 require( 'moduleId' )。当然也可以不用正则。5.递归加载
在分析出模块的依赖之后,我们需要递归去加载依赖模块。用伪代码来表达大概是这样的:
Module.prototype.load = function () {var deps = this.getDeps();for (var i = 0; i < deps.length; i++) {var m = deps[i];if (m.state < STATUS.LOADED) {m.load();}}this.state = STATUS.LOADED;}
参考:https://www.zhihu.com/question/21157540/answer/33583597
23.Js中访问对象属性用点和用中括号有什么不同
- 中括号运算符总是能代替点运算符。但点运算符却不一定能全部代替中括号运算符。
- 中括号运算符可以用字符串变量的内容作为属性名。点运算符不能。
- 中括号运算符可以用纯数字为属性名。点运算符不能。
- 中括号运算符可以用js的关键字和保留字作为属性名。点运算符不能
var foo = {name: 'kitten'}foo.name; // kittenfoo['name']; // kittenvar get = 'name';foo[get]; // kittenfoo.1234; // SyntaxErrorfoo['1234']; // works
24.Javascript垃圾回收方法
- 标记清除(mark and sweep)
这是JavaScript最常见的垃圾回收方式,当变量进入执行环境的时候,比如函数中声明一个变量,垃圾回收器将其标记为“进入环境”,当变量离开环境的时候(函数执行结束)将其标记为“离开环境”。
垃圾回收器会在运行的时候给存储在内存中的所有变量加上标记,然后去掉环境中的变量以及被环境中变量所引用的变量(闭包),在这些完成之后仍存在标记的就是要删除的变量了 - 引用计数(reference counting)
在低版本IE中经常会出现内存泄露,很多时候就是因为其采用引用计数方式进行垃圾回收。引用计数的策略是跟踪记录每个值被使用的次数,当声明了一个 变量并将一个引用类型赋值给该变量的时候这个值的引用次数就加1,如果该变量的值变成了另外一个,则这个值得引用次数减1,当这个值的引用次数变为0的时 候,说明没有变量在使用,这个值没法被访问了,因此可以将其占用的空间回收,这样垃圾回收器会在运行的时候清理掉引用次数为0的值占用的空间。
在IE中虽然JavaScript对象通过标记清除的方式进行垃圾回收,但BOM与DOM对象却是通过引用计数回收垃圾的, 也就是说只要涉及BOM及DOM就会出现循环引用问题。
25.说说你对闭包的理解
使用闭包主要是为了设计私有的方法和变量。闭包的优点是可以避免全局变量的污染,缺点是闭包会常驻内存,会增大内存使用量,使用不当很容易造成内存泄露。在js中,函数即闭包,只有函数才会产生作用域的概念
闭包有三个特性:
1.函数嵌套函数
2.函数内部可以引用外部的参数和变量
3.参数和变量不会被垃圾回收机制回收
26.DOM操作——怎样添加、移除、移动、复制、创建和查找节点。
- 创建新节点
createDocumentFragment() //创建一个DOM片段createElement() //创建一个具体的元素createTextNode() //创建一个文本节点
- 添加、移除、替换、插入
操作的都是子节点,调用时要先取父节点(parentNode)
appendChild()removeChild()replaceChild()insertBefore() //并没有insertAfter()
可以自己编写一个insertAfter函数
function insertAfter(newElement,targetElement){var parent=targetElemnt.parentNode;if(parent.lastChild==targetElement){parent.appendChild(newElement)}else{parent.insertBefore(newElement,targetElement.nextSlibing)}}
其他方法
cloneNode()//一个参数,为true时,深赋值,复制节点及其整个子节点树,为false时只复制节点本身normalize()//删除空文本节点或者合并相邻文本节点
- 查找
getElementsByTagName() //通过标签名称getElementsByName() //通过元素的Name属性的值(IE容错能力较强,会得到一个数组,其中包括id等于name值的)getElementById() //通过元素Id,唯一性getElementByClassName()//html5querySelector()querySelectorAll()

