
基于数组的无锁队列(译)
1 引言
最近对于注重性能的应用程序,我们有了一种能显著提高程序性能的选择:多线程.线程的概念实际上已经存在了很长时间.在过去,多数计算机只有一个处理器,线程主要用于将一个大的任务拆分成一系列更小的执行单元.以使得当其中某些执行单元因为等待资源而被阻塞的时候剩余的执行单元能继续执行。举个示例,一个网络应用程序,它监听一个TCP端口,当有外部请求到达时,处理请求.对于一个单线程的应用程序来说,只能在处理完一个请求之后再处理另外的请求,显然这个应用程序对用户非常不友好,它为一个用户服务的时候别的用户就只能干等.而对于多线程解决方案,我们可以让另外的线程来处理接收到的请求,主线程继续等待在服务端口上接受新的请求.
在只有一个处理器的机器上,一个多线程应用程序可能无法达到我们对它的预期.因为所有的线程都要争抢处理器以获得执行机会.而它的性能说不定比一个用单线程方式去解决同样问题的程序还要差,因为线程之间的通讯和数据共享也有不小的开销.
而在一个对称多处理器机器上(SMP),一个多线程应用可以真正的实现多任务并行执行.每个线程都可以拥有单独的处理器以获得执行的机会,不需要再像单处理器一样,必须要等到处理器空闲才能获得执行机会.对一个有N个处理器的SMP系统来说,理论上一个N线程的应用程序只需要它的单线程版本的1/N的时间就可以完成相同的任务(实际上这个理论值是无法达到的,因为线程之间的通讯和数据共享有不小的开销).
SMP的机器在过去是非常昂贵的,只有一些大公司和组织才能负担得起.而现今,多核心处理器已经相当廉价(现今市场上的pc处理器至少都拥有一个以上的核心),所以让应用程序并行化以提高性能现在已经变得非常流行.
但是编写多线程应用程序显然不是一件简单的事.线程之间需要共享数据,互相通信,很快你就会发现又要面对以前就遇到过的老问题:死锁, 对共享数据的非法访问,多线程动态分配/释放内存等.如果你足够幸运,参与到一个对性能有极高要求的项目中,你将会遇到更多导致性能不达标的问题:
- Cache颠簸(Cache trashing)
- 在同步机制上的争抢.队列
- 动态内存分配
本文主要介绍一种基于数组实现的无锁队列用于解决上述三个性能问题,特别是动态内存分配,因为此无锁队列最初的设计目的就是为了解决这个问题.
2 线程同步如何导致性能下降
2.1 Cache颠簸
线程是(wikipedia):"操作系统可以调度运行的最小的执行单元".每种操作系统都有不同的线程实现方式,基本来说,进程拥有一组指令集(代码)和一段内存,线程执行一个代码片段但与包含它的进程共享内存空间.对Linux来说,线程是另一种"执行上下文", 它没有线程的念.Linux通过标准的进程来实现线程.Linux内核没有提供特殊的调度语义或数据结构用于表示线程.线程只是一个与其它进程共享某些资源的普通进程[1].
每一个运行中的任务/线程或成为执行上下文,使用了一组CPU寄存器,包含各种内部状态的数据,如当前正在执行的指令所在的内存地址,当前正在执行操作的操作数和/或操作结果,栈指针等等.所有的这些信息被统称为"上下文".任何抢占式操作系统(几乎所有现代操作系统都是抢占式的)都必须具备几乎在任何时刻停止一个正在运行的任务并在将来将它恢复运行的能力(有些例外情况,例如一个进程声明它在某一段时间内是不可被抢占的).一但任务恢复执行,它会从上次停止的地方继续执行,就好像从来没被打断过一样.这是一件好事,所有的任务共享处理器,当一个任务在等待I/O时,它被其它任务抢占.即使一个单处理的系统也表现得与多处理系统一样,但是如在现实生活中一样,没有免费的午餐:因为处理器被共享,每次任务抢占都有额外的开销用于保存被抢占任务的上下文,将获得运行权的任务的上下文恢复.
在保存和恢复上下文的过程中还隐藏了额外的开销:Cache中的数据会失效,因为它缓存的是将被换出任务的数据,这些数据对于新换进的任务是没用的.处理器的运行速度比主存快N倍,所以大量的处理器时间被浪费在处理器与主存的数据传输上.这就是在处理器和主存之间引入Cache的原因.Cache是一种速度更快但容量更小的内存(也更加昂贵),当处理器要访问主存中的数据时,这些数据首先被拷贝到Cache中,因为这些数据在不久的将来可能又会被处理器访问.Cache misses对性能有非常大的影响,因为处理器访问Cache中的数据将比直接访问主存快得多.
因此每当一个任务被抢占,Cache中的内容都需要被接下来获得运行权的进程覆盖,这意味着,接下来运行的进程需要花费一定的时间来将Cache预热才能达到良好的运行效率(某些操作系统,例如Linux,尝试将进任务恢复到它被抢占时运行的处理器上以减缓这个预热的开销).当然这并不意味任务抢占是坏事,抢占机制使得操作系统得以正常的工作.但对某些系统而言,线程被频繁抢占产生的Cache颠簸将导致应用程序性能下降.
一个运行中的任务在什么情况下会被抢占?这依赖于你所使用的操作系统,但一般来说,中断处理,定时器超时,执行系统调等,有极大的可能导致操作系统考虑将处理器的使用权交给系统中的其它进程.这实际上是操作系统要处理的一个难题,一方面,没人愿意有进程因为无法获得处理器而长期处于饥饿状态.另一方面,有些系统调用是阻塞的,这意味着一个任务向操作系统请求某些资源,这个任务要等待请求的资源被准备好,因为它需要这些资源以执行后续的操作.这是任务抢占的一个正面的例子,因为在资源被准备好之前那个任务将无所事事,操作系统可以将它投入到等待状态,将处理器让给其它任务运行.
资源一般来说指的是在内存,磁盘,网络或外设中的数据,但一些会导致阻塞的同步机制,例如信号量和互斥锁也可以被认为是资源.当一个任务请求获得一个已经被其它任务持有的互斥锁,它将被抢占,直到那个请求的互斥锁被释放,它才会被重新投入到可运行任务队列中.所以如果你担心你的进程被过于频繁的抢占,你应该尽量避免使用会导致阻塞的同步机制.
但是,显然一切没那么简单.如果你使用多于物理处理器数量的线程来执行计算密集型的任务,并且不使用任何会导致阻塞的同步机制,你的系统的响应及时性将变差(操作延时加大).因为操作系统切换任务的次数越少意味着当前处于非运行状态的进程需要等待更长的时间,直到有一个空闲的处理器使得它能恢复执行.而你的应用程序很可能也会受到影响,因为它可能在等待某个线程执行完一些计算才能进行下一步的处理,而那个线程却无法获得处理器来完成它的计算,导致所有其它的线程都在等待它.没有通用的方法解决所有这些问题,这通常依赖于你的应用程序,机器和操作系统.例如对一个实时的计算密集型应用程序,我会选择避免使用导致阻塞的同步机制,同时使用更少的线程.而对于那些需要花费大量时间等待外部(例如网络)数据到来的应用程序,使用非阻塞同步机制可能会杀死你.每种方法都有自己的优点和缺点,一切皆取决于你是如何使用的.
2.2 在同步机制上的争抢.队列
队列可被应用到大多数多线程解决方案中.如果两个或更多的线程需要通过有序事件来进行交流,我脑子里第一个跳出来的就是队列.简单易懂,使用方便,被良好的测试.世界上任何一个程序员都要面对队列.它们无处不在.
队列对一个单线程应用程序来说,使用非常简便,对它做一些简单的处理就可以适用于多线程的应用.你所需要的只是一个非线程安全的队列(例如C++的std::queue)和一种阻塞的同步机制(例如互斥锁和条件变量).我随本文一起附上一个用glib编写的简单的阻塞队列.虽然没有任何必要去重复发明轮子,glib中已经包含了一个线程安全的队列GAsyncQueue[7],但这段代码展示了如何将一个标准队列转换成线程安全的队列.
让我们来看一下这个队列中最常用的几个方法的实现:IsEmpty, Push和Pop.最基本的存储队列使用的是std::queue它被声明为成员变量,std::queue m_theQueue.我使用glib的互斥锁和条件变更量的封装来作为同步机制(GMutex* m_mutex和Cond* m_cond).可以与本文一起被下载的队列实现中还包括了TryPush和TryPop两个方法,它们在队列已满或为空的时候不会阻塞调用线程.
template <typename T>
bool BlockingQueue<T>::IsEmpty()
{
bool rv;
g_mutex_lock(m_mutex);
rv = m_theQueue.empty();
g_mutex_unlock(m_mutex);
return rv;
}
当队列中没有元素的时候IsEmpty返回true,在任何线程可以访问到不安全的队列实现之前,必须首先获得互斥锁.这意味着调用线程会被阻塞直到互斥锁被释放.
template <typename T>
bool BlockingQueue<T>::Push(const T &a_elem)
{
g_mutex_lock(m_mutex);
while (m_theQueue.size() >= m_maximumSize)
{
g_cond_wait(m_cond, m_mutex);
}
bool queueEmpty = m_theQueue.empty();
m_theQueue.push(a_elem);
if (queueEmpty)
{
// wake up threads waiting for stuff
g_cond_broadcast(m_cond);
}
g_mutex_unlock(m_mutex);
return true;
}
Push将一个元素插入队列尾部.调用线程将会阻塞,如果有其它线程持有互斥锁.如果队列已满调用线程也会阻塞直到有一个线程从队列中Pop一个元素出列.
template <typename T>
void BlockingQueue<T>::Pop(T &out_data)
{
g_mutex_lock(m_mutex);
while (m_theQueue.empty())
{
g_cond_wait(m_cond, m_mutex);
}
bool queueFull = (m_theQueue.size() >= m_maximumSize) ? true : false;
out_data = m_theQueue.front();
m_theQueue.pop();
if (queueFull)
{
// wake up threads waiting for stuff
g_cond_broadcast(m_cond);
}
g_mutex_unlock(m_mutex);
}
Pop将队首元素出列,调用线程将会阻塞,如果有其它线程持有互斥锁.如果队列已满调用线程也会阻塞直到有一个线程Push一个元素到队列中.
如我在前面的章节中解释过的,阻塞不是微不足道的操作.它导致操作系统暂停当前的任务或使其进入睡眠状态(等待,不占用任何的处理器).直到资源(例如互斥锁)可用,被阻塞的任务才可以解除阻塞状态(唤醒).在一个负载较重的应用程序中使用这样的阻塞队列来在线程之间传递消息会导致严重的争用问题.也就是说,任务将大量的时间(睡眠,等待,唤醒)浪费在获得保护队列数据的互斥锁,而不是处理队列中的数据上.
在最简单的情形下,只有一个线程向队列插入数据(生产者),也只有一个线程从队列中提取数据(消费者),这两个线程争用保护队列的互斥锁.我们也可以把我们的实现从只使用一个互斥锁改为使用两个,一个用于插入数据一个用于提取数据.使用这种方式则只有在队列为空或满的时候才会发生争抢.但是如果有多于一个线程插入数据和提取数据,那么我们的问题又回来了.生产者们和消费者们还是需要继续争抢各自互斥锁.
这种情况下,非阻塞机制大展伸手的机会到了.任务之间不争抢任何资源,在队列中预定一个位置,然后在这个位置上插入或提取数据.这中机制使用了一种被称之为CAS(比较和交换)的特殊操作,这个特殊操作是一种特殊的指令,它可以原子的完成以下操作:它需要3个操作数m,A,B,其中m是一个内存地址,操作将m指向的内存中的内容与A比较,如果相等则将B写入到m指向的内存中并返回true,如果不相等则什么也不做返回false.例如:
volatile int a;
a = 1;
// this will loop while 'a' is not equal to 1. If it is equal to 1 the operation will atomically
// set a to 2 and return true
while (!CAS(&a, 1, 2))
{
;
}
使用CAS实现无锁队列已经不是什么新鲜事物了.有很多实现的方案,但大多数都是使用链表的实现.有兴趣的读者可以查看[2][3]或[4].
虽然本文的目的不是描述这种实现,但做一个简单的介绍还是有必要的:
- 向队列中插入一个元素会动态分配一个新的节点,通过CAS操作将这个节点插入到队列中
- 移除元素首先通过CAS操作移动链表的指针将节点出列,然后再访问那个出列节点中的数据.
下面是一个简单的基于链表实现的无锁队列(从[2]中拷贝过来的,它的实现基于[5])
typedef struct _Node Node;
typedef struct _Queue Queue;
struct _Node {
void *data;
Node *next;
};
struct _Queue {
Node *head;
Node *tail;
};
Queue*
queue_new(void)
{
Queue *q = g_slice_new(sizeof(Queue));
q->head = q->tail = g_slice_new0(sizeof(Node));
return q;
}
void
queue_enqueue(Queue *q, gpointer data)
{
Node *node, *tail, *next;
node = g_slice_new(Node);
node->data = data;
node->next = NULL;
while (TRUE) {
tail = q->tail;
next = tail->next;
if (tail != q->tail)
continue;
if (next != NULL) {
CAS(&q->tail, tail, next);
continue;
}
if (CAS(&tail->next, null, node)
break;
}
CAS(&q->tail, tail, node);
}
gpointer
queue_dequeue(Queue *q)
{
Node *node, *tail, *next;
while (TRUE) {
head = q->head;
tail = q->tail;
next = head->next;
if (head != q->head)
continue;
if (next == NULL)
return NULL; // Empty
if (head == tail) {
CAS(&q->tail, tail, next);
continue;
}
data = next->data;
if (CAS(&q->head, head, next))
break;
}
g_slice_free(Node, head); // This isn't safe
return data;
}
在不支持垃圾回收的编程语言中,最后的g_slice_free调用是不安全的,具体原因可以参看ABA问题:
首先假设队列中只有一个节点,q->head = N1,q->tail = N2,其中N1是哨兵节点
- 1 线程T1在执行完
data = next->data;之后被暂停.此时next = N2,head = N1 - 2 线程T2执行
queue_dequeue将节点(N1)出列,并将节点(N1)的内存释放,操作完成后,q->head = N2,q->tail = N2,N2是哨兵节点 - 3 线程T2执行
queue_enqueue,产生的节点(N3)与(N1)内存地址一致(内存被重用),操作完成后,q->head = N2,q->tail = N3 = N1 - 4 线程T2再次执行
queue_dequeue,操作完成后q->head = q->tail = N3 = N1,N1重新变会哨兵节点 - 4 T1恢复执行,接下来执行CAS成功(head = q->head = N1).而实际上此时队列已经为空,没有元素可供出列.
ABA问题可以通过给每个节点增加引用计数来解决.在执行CAS操作之前首先要检查计数值以确定操作的是一个正确的节点.好消息是本文提供的这个无锁链表队列实现没有ABA问题,因为它没有使用动态内存分配.
2.3 动态内存分配
在多线程系统中,需要仔细的考虑动态内存分配.当一个任务从堆中分配内存时,标准的内存分配机制会阻塞所有与这个任务共享地址空间的其它任务(进程中的所有线程).这样做的原因是让处理更简单,且它工作得很好.两个线程不会被分配到一块相同的地址的内存,因为它们没办法同时执行分配请求.显然线程频繁分配内存会导致应用程序性能下降(必须注意,向标准队列或map插入数据的时候都会导致堆上的动态内存分配)
存在一些非标准库,提供了无锁内存分配机制,以减少多线程对堆的争抢,例如libhoard[6].除此之外还有更多的其它选择,你可以将标准的C++分配器替换成这些无锁内存分配器,它们可能会大大的提高你的应用程序的性能.
3 基于循环数组的无锁队列
终于到了本文的重点部分,基于循环数组的无锁队列解决了上一节中提到的3个问题,首先概括一下基于循环数组的无锁队列的特性:
- 作为一种无锁同步机制,它显著降低了任务抢占的频率,因此有效减缓了cache颠簸.
- 如所有其它无锁队列一样,线程之间的争抢显著降低,因为它不需要锁去保护任何数据结构:线程所要做的就是索要一块空间,然后将数据写进去.
- 队列的操作不会导致动态内存分配
- 没有ABA问题,只是在数组处理上需要一些额外的开销.
3.1 它是如何工作的?
队列的实现使用了一个数组和3个作用不同的下标:
- writeIndex:新元素入列时存放位置在数组中的下标
- readIndex:下一个出列元素在数组中的下标
- maximumReadIndex:最后一个已经完成入列操作的元素在数组中的下标.如果它的值跟writeIndex不一致,表明有写请求尚未完成.这意味着,有写请求成功申请了空间但数据还没完全写进队列.所以如果有线程要读取,必须要等到写线程将数完全据写入到队列之后.
必须指明的是使用3种不同的下标都是必须的,因为队列允许任意数量的生产者和消费者围绕着它工作.已经存在一种基于循环数组的无锁队列,使得唯一的生产者和唯一的消费者可以良好的工作[11].它的实现相当简洁非常值得阅读.
3.1.1 CAS操作
此无锁队列基于CAS指令,CAS操作在GCC4.1.1中被包含进来.因为我使用GCC 4.4进行编译,所以我使用了GCC内置的CAS操作__sync_bool_compare_and_swap.为了支持更多的平台和其它不同的编译器,我在atomic_ops.h中用宏将它映射到名字CAS上.
/// @brief Compare And Swap
/// If the current value of *a_ptr is a_oldVal, then write a_newVal into *a_ptr
/// @return true if the comparison is successful and a_newVal was written
#define CAS(a_ptr, a_oldVal, a_newVal) __sync_bool_compare_and_swap(a_ptr, a_oldVal, a_newVal)
如果你打算在不同的编译器上编译这个队列,你所要做的就是实现一个在你的编译器上可以使用的CAS函数.你的实现必须符合以下接口:
- 参数1是要被修改的变量的地址
- 参数2是要被修改变量的老值
- 参数3是要被修改成的新值
- 如果修改成功返回true,否则返回false
3.1.2 向队列插入元素
以下代码用于向队列插入元素:
/* ... */
template <typename ELEM_T, uint32_t Q_SIZE>
inline
uint32_t ArrayLockFreeQueue<ELEM_T, Q_SIZE>::countToIndex(uint32_t a_count)
{
return (a_count % Q_SIZE);
}
/* ... */
template <typename ELEM_T>
bool ArrayLockFreeQueue<ELEM_T>::push(const ELEM_T &a_data)
{
uint32_t currentReadIndex;
uint32_t currentWriteIndex;
do
{
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if (countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
// the queue is full
return false;
}
} while (!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex + 1)));
// We know now that this index is reserved for us. Use it to save the data
m_theQueue[countToIndex(currentWriteIndex)] = a_data;
// update the maximum read index after saving the data. It wouldn't fail if there is only one thread
// inserting in the queue. It might fail if there are more than 1 producer threads because this
// operation has to be done in the same order as the previous CAS
while (!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1)))
{
// this is a good place to yield the thread in case there are more
// software threads than hardware processors and you have more
// than 1 producer thread
// have a look at sched_yield (POSIX.1b)
sched_yield();
}
return true;
}
以下插图展示了对队列执行操作时各下标是如何变化的.如果一个位置被标记为X,标识这个位置里存放了数据.空白表示位置时空的.对于下图的情况,队列中存放了两个元素.WriteIndex指示的位置是新元素将会被插入的位置.ReadIndex指向的位置中的元素将会在下一次pop操作中被弹出.
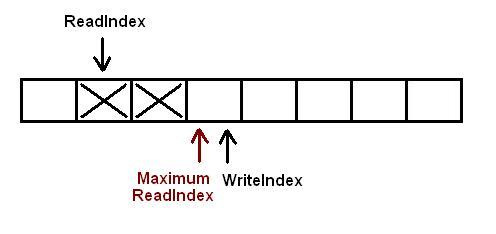
当生产者准备将数据插入到队列中,它首先通过增加WriteIndex的值来申请空间.MaximumReadIndex指向最后一个存放有效数据的位置(也就是实际的队列尾).
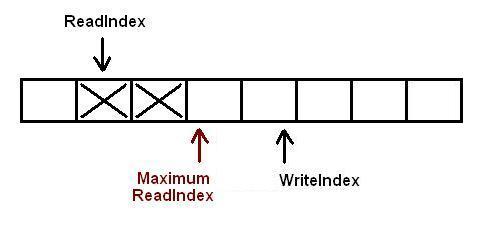
一旦空间的申请完成,生产者就可以将数据拷贝到刚刚申请到的位置中.完成之后增加MaximumReadIndex使得它与WriteIndex的一致.
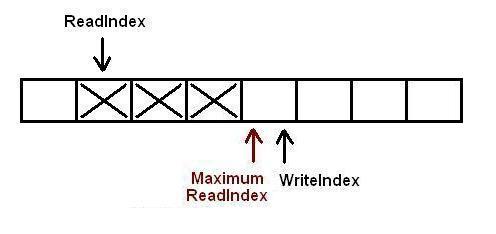
现在队列中有3个元素,接着又有一个生产者尝试向队列中插入元素.
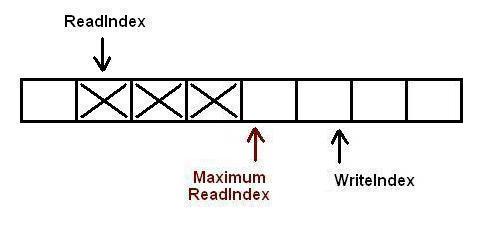
在第一个生产者完成数据拷贝之前,又有另外一个生产者申请了一个新的空间准备拷贝数据.现在有两个生产者同时向队列插入数据.
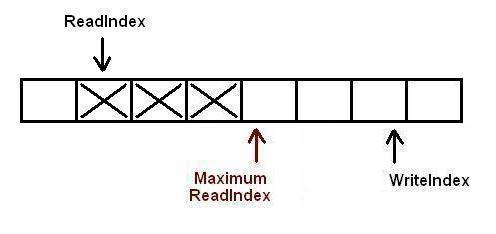
现在生产者开始拷贝数据,在完成拷贝之后,对MaximumReadIndex的递增操作必须严格遵循一个顺序:第一个生产者线程首先递增MaximumReadIndex,接着才轮到第二个生产者.这个顺序必须被严格遵守的原因是,我们必须保证数据被完全拷贝到队列之后才允许消费者线程将其出列.
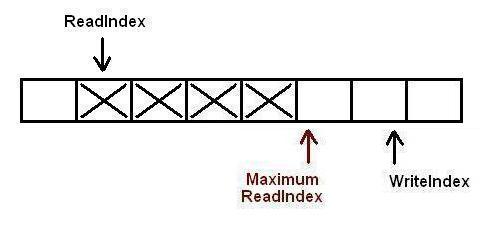
第一个生产者完成了数据拷贝,并对MaximumReadIndex完成了递增,现在第二个生产者可以递增MaximumReadIndex了
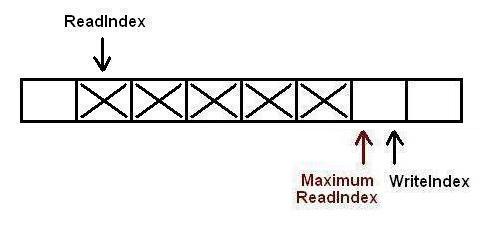
第二个生产者完成了对MaximumReadIndex的递增,现在队列中有5个元素.
3.1.3 从队列中移除元素
以下代码用于从队列中移除元素:
/* ... */
template <typename ELEM_T>
bool ArrayLockFreeQueue<ELEM_T>::pop(ELEM_T &a_data)
{
uint32_t currentMaximumReadIndex;
uint32_t currentReadIndex;
do
{
// to ensure thread-safety when there is more than 1 producer thread
// a second index is defined (m_maximumReadIndex)
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
if (countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex))
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_theQueue[countToIndex(currentReadIndex)];
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if (CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
return true;
}
// it failed retrieving the element off the queue. Someone else must
// have read the element stored at countToIndex(currentReadIndex)
// before we could perform the CAS operation
} while(1); // keep looping to try again!
// Something went wrong. it shouldn't be possible to reach here
assert(0);
// Add this return statement to avoid compiler warnings
return false;
}
以下插图展示了元素出列的时候各种下标是如何变化的,队列中初始有2个元素.WriteIndex指示的位置是新元素将会被插入的位置.ReadIndex指向的位置中的元素将会在下一次pop操作中被弹出.
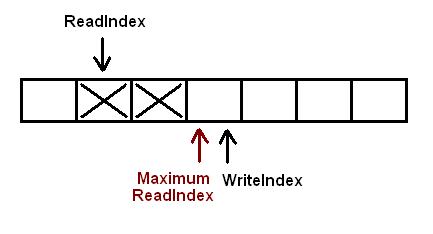
消费者线程拷贝数组ReadIndex位置的元素,然后尝试用CAS操作将ReadIndex加1.如果操作成功消费者成功的将数据出列.因为CAS操作是原子的,所以只有唯一的线程可以在同一时刻更新ReadIndex的值.如果操作失败,读取新的ReadIndex值,比重复以上操作(copy数据,CAS).
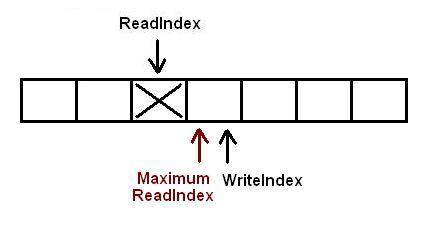
现在又有一个消费者将元素出列,队列变成空.
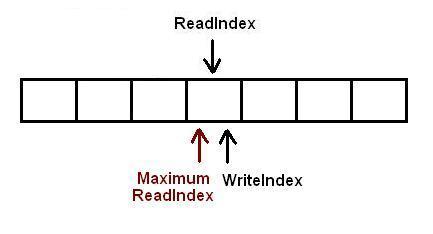
现在有一个生产者正在向队列中添加元素.它已经成功的申请了空间,但尚未完成数据拷贝.任何其它企图从队列中移除元素的消费者都会发现队列非空(因为writeIndex不等于readIndex).但它不能读取readIndex所指向位置中的数据,因为readIndex与MaximumReadIndex相等.消费者将会在do循环中不断的反复尝试,直到生产者完成数据拷贝增加MaximumReadIndex的值,或者队列变成空(这在多个消费者的场景下会发生).
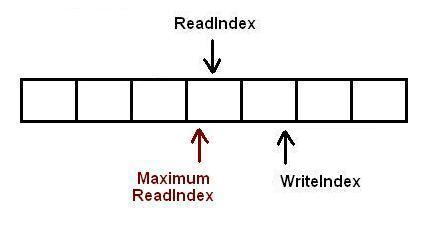
当生产者完成数据拷贝,队列的大小是1,消费者线程可以读取这个数据了.
3.1.4 在多于一个生产者线程的情况下yielding处理器的必要性
读者可能注意到了push函数中使用了sched_yield()来主动的让出处理器,对于一个声称无锁的算法而言,这个调用看起来有点奇怪.正如我在文章开始的部分解释过的,多线程环境下影响性能的其中一个因素就是Cache颠簸.而产生Cache颠簸的一种情况就是一个线程被抢占,操作系统需要保存被抢占线程的上下文,然后将被选中作为下一个调度线程的上下文载入.此时Cache中缓存的数据都会失效,因为它是被抢占线程的数据而不是新线程的数据.
所以,当此算法调用sched_yield()意味着告诉操作系统:"我要把处理器时间让给其它线程,因为我要等待某件事情的发生".无锁算法和通过阻塞机制同步的算法的一个主要区别在于无锁算法不会阻塞在线程同步上,那么为什么在这里我们要主动请求操作系统抢占自己呢?这个问题的答案没那么简单.它与有多少个生产者线程在并发的往队列中存放数据有关:每个生产者线程所执行的CAS操作都必须严格遵循FIFO次序,一个用于申请空间,另一个用于通知消费者数据已经写入完成可以被读取了.
如果我们的应用程序只有唯一的生产者操作这个队列,sche_yield()将永远没有机会被调用,第2个CAS操作永远不会失败.因为在一个生产者的情况下没有人能破坏生产者执行这两个CAS操作的FIFO顺序.
而当多于一个生产者线程往队列中存放数据的时候,问题就出现了.存放数据的完整过程可以参看3.1.1小节,概括来说,一个生产者通过第1个CAS操作申请空间,然后将数据写入到申请到的空间中,然后执行第2个CAS操作通知消费者数据准备完毕可供读取了.这第2个CAS操作必须遵循FIFO顺序,也就是说,如果A线程第首先执行完第一个CAS操作,那么它也要第1个执行完第2个CAS操作,如果A线程在执行完第一个CAS操作之后停止,然后B线程执行完第1个CAS操作,那么B线程将无法完成第2个CAS操作,因为它要等待A先完成第2个CAS操作.而这就是问题产生的根源.让我们考虑如下场景,3个消费者线程和1个消费者线程:
- 线程1,2,3按顺序调用第1个CAS操作申请了空间.那么它们完成第2个CAS操作的顺序也应该与这个顺序一致,1,2,3.
- 线程2首先尝试执行第2个CAS,但它会失败,因为线程1还没完成它的第2此CAS操作呢.同样对于线程3也是一样的.
- 线程2和3将会不断的调用它们的第2个CAS操作,直到线程1完成它的第2个CAS操作为止.
- 线程1最终完成了它的第2个CAS,现在线程3必须等线程2先完成它的第2个CAS.
- 线程2也完成了,最终线程3也完成.
在上面的场景中,生产者可能会在第2个CAS操作上自旋一段时间,用于等待先于它执行第1个CAS操作的线程完成它的第2次CAS操作.在一个物理处理器数量大于操作队列线程数量的系统上,这不会有太严重的问题:因为每个线程都可以分配在自己的处理器上执行,它们最终都会很快完成各自的第2次CAS操作.虽然算法导致线程处理忙等状态,但这正是我们所期望的,因为这使得操作更快的完成.也就是说在这种情况下我们是不需要sche_yield()的,它完全可以从代码中删除.
但是,在一个物理处理器数量少于线程数量的系统上,sche_yield()就变得至关重要了.让我们再次考查上面3个线程的场景,当线程3准备向队列中插入数据:如果线程1在执行完第1个CAS操作,在执行第2个CAS操作之前被抢占,那么线程2,3就会一直在它们的第2个CAS操作上忙等(它们忙等,不让出处理器,线程1也就没机会执行,它们就只能继续忙等),直到线程1重新被唤醒,完成它的第2个CAS操作.这就是需要sche_yield()的场合了,操作系统应该避免让线程2,3处于忙等状态.它们应该尽快的让出处理器让线程1执行,使得线程1可以把它的第2个CAS操作完成.这样线程2和3才能继续完成它们的操作.
4 已知的问题
这个无锁队列的设计目标就是实现一个无须动态内存分配的无锁队列.显然这个目标已经达到了,但是这个算法也存在一些缺点,在将此队列用于生产环境之前你必须仔细考虑这些缺点会不会对你的应用程序造成什么问题.
4.1 多于一个生产者线程
这个问题我们在3.1.4小节已经详细的讨论过了.如果有多于一个的生产者线程,那么将它们很可能花费大量的时间用于等待更新MaximumReadIndex(第2个CAS).这个队列最初的设计场景是满足单一消费者,所以不用怀疑在多生产者的情形下会比单一生产者有大幅的性能下降.
另外如果你只打算将此队列用于单一生产者的场合,那么第2个CAS操作可以去除.同样m_maximumReadIndex也可以一同被移除了,所有对m_maximumReadIndex的引用都改成m_writeIndex.所以,在这样的场合下push和pop可以被改写如下:
template <typename ELEM_T>
bool ArrayLockFreeQueue<ELEM_T>::push(const ELEM_T &a_data)
{
uint32_t currentReadIndex;
uint32_t currentWriteIndex;
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if (countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
// the queue is full
return false;
}
// save the date into the q
m_theQueue[countToIndex(currentWriteIndex)] = a_data;
// increment atomically write index. Now a consumer thread can read
// the piece of data that was just stored
AtomicAdd(&m_writeIndex, 1);
return true;
}
template <typename ELEM_T>
bool ArrayLockFreeQueue<ELEM_T>::pop(ELEM_T &a_data)
{
uint32_t currentMaximumReadIndex;
uint32_t currentReadIndex;
do
{
// m_maximumReadIndex doesn't exist when the queue is set up as
// single-producer. The maximum read index is described by the current
// write index
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_writeIndex;
if (countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex))
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_theQueue[countToIndex(currentReadIndex)];
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if (CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
return true;
}
// it failed retrieving the element off the queue. Someone else must
// have read the element stored at countToIndex(currentReadIndex)
// before we could perform the CAS operation
} while(1); // keep looping to try again!
// Something went wrong. it shouldn't be possible to reach here
assert(0);
// Add this return statement to avoid compiler warnings
return false;
}
如果你打算将此队列用于单一生产者和单一消费者的场合,那么阅读[11]将是十分有价值的,因为它的设计目标就是针对这种场合的.
4.2 与智能指针一起使用队列
如果你打算用这个队列来存放智能指针对象.需要注意,将一个智能指针存入队列之后,如果它所占用的位置没有被另一个智能指针覆盖,那么它所指向的内存是无法被释放的(因为它的引用计数器无法下降为0).这对于一个操作频繁的队列来说没有什么问题,但是程序员需要注意的是,一旦队列被填满过一次那么应用程序所占用的内存就不会下降,即使队列被清空.
4.3 计算队列的大小
size函数可能会返回一个不正确的值,size的实现如下:
template <typename ELEM_T>
inline uint32_t ArrayLockFreeQueue<ELEM_T>::size()
{
uint32_t currentWriteIndex = m_writeIndex;
uint32_t currentReadIndex = m_readIndex;
if (currentWriteIndex >= currentReadIndex)
{
return (currentWriteIndex - currentReadIndex);
}
else
{
return (m_totalSize + currentWriteIndex - currentReadIndex);
}
}
下面的场景描述了size为何会返回一个不正确的值:
- 1 当
currentWriteIndex = m_writeIndex执行之后,m_writeIndex=3,m_readIndex = 2那么实际size是1 - 2 之后操作线程被抢占,且在它停止运行的这段时间内,有2个元素被插入和从队列中移除.所以
m_writeIndex=5,m_readIndex = 4,而size还是1 - 3 现在被抢占的线程恢复执行,读取m_readIndex值,这个时候
currentReadIndex=4,currentWriteIndex=3. - 4
currentReadIndex > currentWriteIndex'所以m_totalSize + currentWriteIndex - currentReadIndex`被返回,这个值意味着队列几乎是满的,而实际上队列几乎是空的
与本文一起上传的代码中包含了处理这个问题的解决方案.添加一个用于保存队列中元素数量的成员count,这个成员可以通过AtomicAdd/AtomicSub来实现原子的递增和递减.
但需要注意的是这增加了一定开销,因为原子递增,递减操作比较昂贵也很难被编译器优化.
例如,在core 2 duo E6400 2.13 Ghz 的机器上,单生产者单消费者,队列数组的初始大小是1000,测试执行10,000k次的插入,没有count成员的版本用时2.64秒,而维护了count成员的版本用时3.42秒.而对于2消费者,1生产者的情况,没有count成员的版本用时3.98秒,维护count的版本用时5.15秒.
这也就是为什么我把是否启用此成员变量的选择交给实际的使用者.使用者可以根据自己的使用场合选择是否承受额外的运行时开销.
在array_lock_free_queue.h中有一个名为ARRAY_LOCK_FREE_Q_KEEP_REAL_SIZE的宏变量,如果它被定义那么将启用count变量,否则将size函数将有可能返回不正确的值.
5 编译代码
本文中的无锁队列和Glib阻塞队列都是用模板实现的C++类型.模板代码放在头文件中,所以如果没在.cpp文件中引用到相关的模板类型它是不会被编译的.
我制作了一个.zip文件,里面每种队列都有一个对应的测试文件用于展示队列的使用和相应的多线程测试用例.
测试代码是用gomp编写的,它是一个GNU实现的OpenMP应用程序接口,用于C/C++多平台共享内存模式并行程序的开发[9].OpenMP是一个种简单灵活的编程接口,
专门用于不同平台的并行程序开发,使用它可以方便快捷的编写出多线程代码.
本文附带的代码分成3部分,每一部分都有不同的需求:
1.基于数组的无锁队列:
-
有两个版本的无锁队列.一个用于任意多线程,一个用于单一生产者.它们分别在array_lock_free_queue.h和array_lock_free_queue_single_producer.h
-
GCC的版本号必须大于等于4.1.0(CAS, AtomicAdd和AtomicSub).如果使用其它的编译器,你需要在atomic_ops.h自己定义CAS实现.(这通常依赖于你的编译器或平台或者两者)
-
如果在你的stdint.h中没有定义
uint32_t,那么你必须自己定义,定义方式如下:typedef unsigned int uint32_t; // int is (normally) 32bit in both 32 and 64bit machines另外一个必须注意的是这个队列没有在64位环境下测试过.如果不支持64位的原子操作,GCC可能会抛出编译时错误.这也就是为何选择用32位的变量来实现这个队列(在一个32位的机器上可能不支持64位的原子操作).如果你的机器可以支持64位原子操作,我没发现队列有什么地方会因为操作64位索引而导致错误的地方.
-
对任意多线程的队列版本(在push中执行2个CAS操作),还依赖于sched_yield().这个函数是POSIX[10]的一部分,所以任何兼容POSIX的操作系统都应该可以成功编译.
2.基于Glib的阻塞队列:
-
首先你的系统中必须安装了glib.对于GNU-Linux而言这个条件必然是满足的.对于其它系统,可以从下面下载一个完整的GTK+库, 它在GNU-Linux,Windows,OSX下都可以良好的工作:http://www.gtk.org/download.html
-
使用到了glib实现的互斥锁和条件变量,它们是gthread库的一部分.所以你必须把这个库链接到你编译的程序中.
- 测试程序:
-
满足上面所提到的需求
-
使用GNU make处理makefile,你可以向编译器提供一些编译时选项,例如:
make N_PRODUCERS=1 N_CONSUMERS=1 N_ITERATIONS=10000000 QUEUE_SIZE=1000其中:
- N_PRODUCERS是生产者线程的数量
- N_CONSUMERS是消费者线程的数量
- N_ITERATIONS对队列执行的插入和移除次数
- QUEUE_SIZE队列的数组大小
-
GCC版本号大于4.2,用于编译Gomp
-
在运行测试程序之前在命令行添加
OMP_NESTED=TRUE参数.例如:OMP_NESTED=TRUE ./test_lock_free_q
6 一些图片
下面的对比图展示了测试程序在2核心的机器上,不同设置和不同线程配置的测试数据.
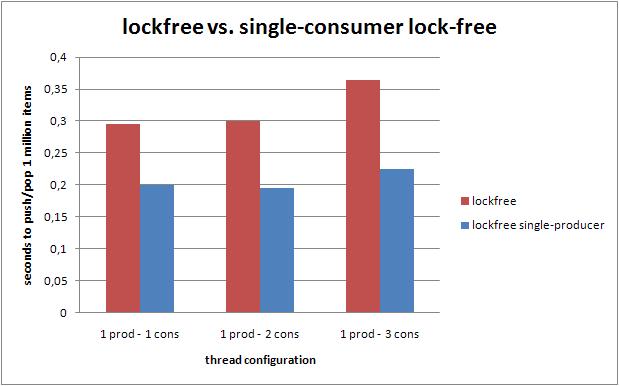
6.1 第2个CAS操作对性能造成的影响
一个已知道的问题是在单一生产者的情况下,第2个CAS将对性能产生影响.下图对比了单生产者优化的队列和任意生产者队列(值越小越好).从对比图可以看出,单生产者优化的版本有30%的性能提升.
6.2 无锁 vs 阻塞队列
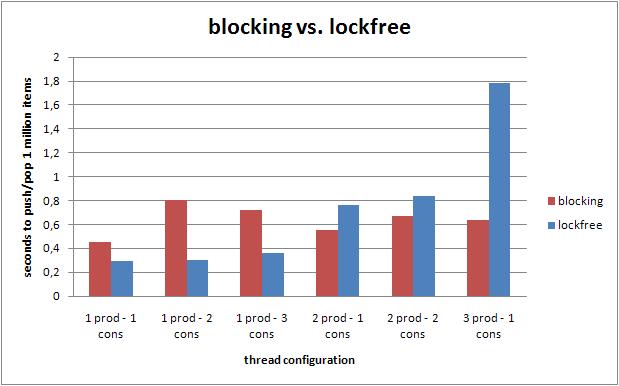
下图的测试是在各种线程配置下,并发的插入和移除100W元素所花费的时间(越小越好,队列的数组大小初始为16384).
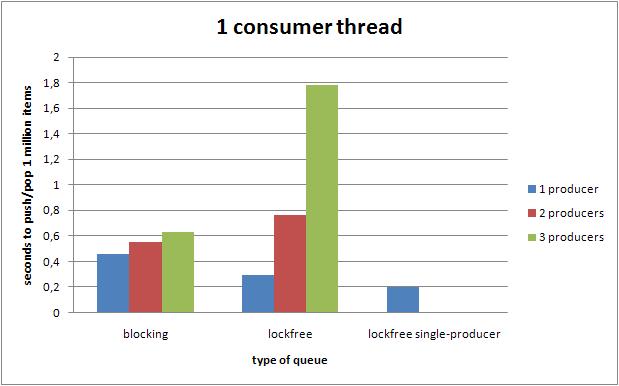
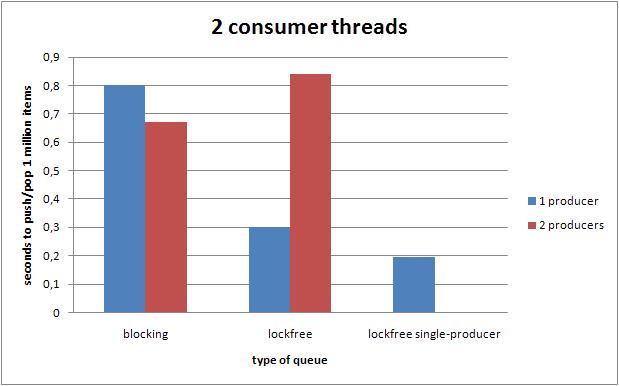
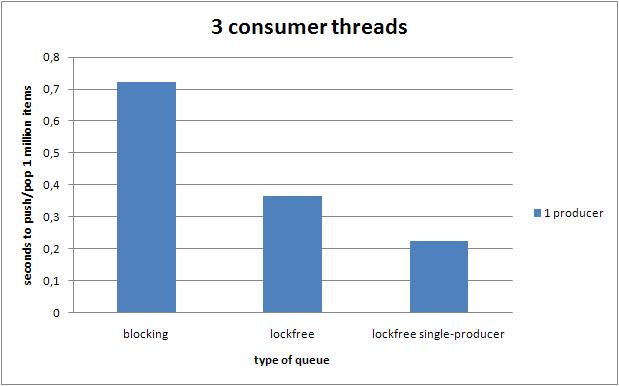
在单生产者的情况下,无锁队列战胜了阻塞队列.而随着生产者数量的增加,无锁队列的效率迅速下降.
6.3 4线程的效率
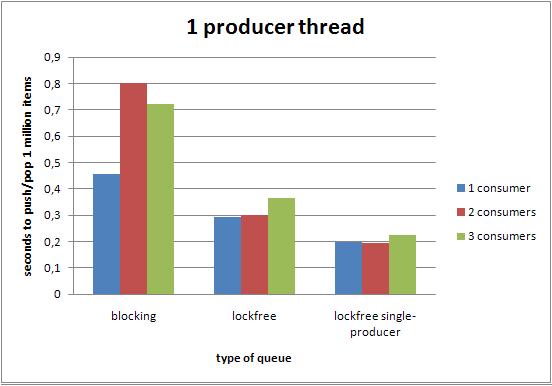
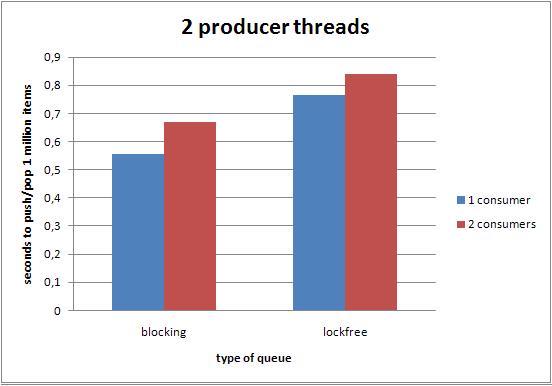
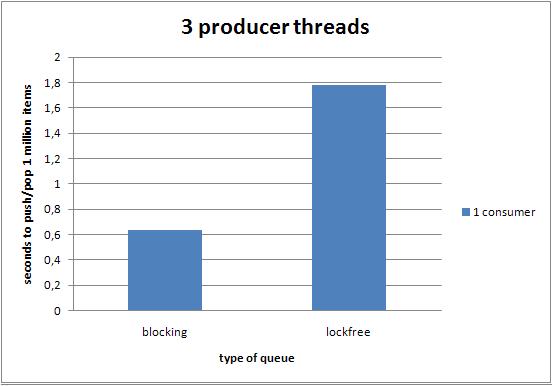
下面的图,展示了在不同线程数量的配置下,不同的队列执行100W次push和pop操作的性能对比.
6.3.1 一个生产者线程
6.3.2 两个生产者线程
6.3.3 三个生产者线程
6.3.1 一个消费者线程
6.3.2 两个消费者线程
6.3.3 三个消费者线程
6.4 使用一台4核心的机器
强烈推荐你在一台拥有4个核心的机器上执行上述测试.这样你就可以观察sched_yield()对性能产生的影响.
7 结论
基于数组的无锁队列的两个版本已经被证明可以正常的工作,一个版本是多生产者线程安全的,另一个版本是单生产者但可以有多消费者.两个版本的队列都可以安全的作为多线程应用程序的同步机制使用,因为:
- CAS操作是原子的,线程并行执行push/pop不会导致死锁
- 多生产者同时向队列push数据的时候不会将数据写入到同一个位置,产生数据覆盖
- 多消费者同时执行pop不会导致一个元素被出列多于1次
- 线程不能将数据push进已经满的队列中,不能从空的队列中pop元素
- push和pop都没有ABA问题
但是,虽然这个队列是线程安全的,但是在多生产者线程的环境下它的性能还是不如阻塞队列.因此,在符合下述条件的情况下可以考虑使用这个队列来代替阻塞队列:
- 只有一个生产者线程
- 只有一个频繁操作队列的生产者,但偶尔会有其它生产者向队列push数据
8 历史
4rd January 2011: Initial version
27th April 2011: Highlighting of some key words. Removed unnecesary uploaded file. A few typos fixed
9 参考
[1] Love, Robert: "Linux Kernel Development Second Edition", Novell Press, 2005
[2] Introduction to lock-free/wait-free and the ABA problem
[3] Lock Free Queue implementation in C++ and C#
[4] High performance computing: Writing Lock-Free Code
[5] M.M. Michael and M.L. Scott, "Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms," Proc. 15th Ann. ACM Symp. Principles of Distributed Computing, pp. 267-275, May 1996.
[6] The Hoard Memory Allocator
[8] boost::shared_ptr documentation
[10] sched_yield documentation
[11] lock-free single producer - single consumer circular queue

