摘要:
在python的多继承中,父类的初始化顺序遵循所谓方法解析顺序(Method Resolution Order,MRO)的机制。python使用C3线性化算法来确定多继承类的MRO: 1. 目标:创建一个一致的线性继承顺序,同时保持父类的相对顺序和子类优先原则。 2. 子类优先:子类总是在其父类之前 阅读全文
摘要:
以下 import filecmp, os def compare_folders(folder1, folder2): dcmp = filecmp.dircmp(folder1, folder2) for name in dcmp.left_only: print(f"{folder1}单独存在 阅读全文
摘要:
一种方法 https://unix.stackexchange.com/questions/116191/give-server-access-to-internet-via-client-connecting-by-ssh 以上方法在我这里不太行。尝试了另一种方式,连上了: 1、远端服务器需要能p 阅读全文
摘要:
python模块可以相对导入和绝对导入,但这两者是不能随意替换使用的。本文主要讨论工作目录下模块之间的导入规则。其中相对导入前面有一个'.',表示从该脚本所在目录开始索引,而绝对导入前面没有'.',表示从根目录开始索引。首先明确一点,python认为的根目录为当前运行的脚本所在的目录,而不是vsco 阅读全文
摘要:
训练神经网络模型有时需要观察模型内部模块的输入输出,或是期望在不修改原始模块结构的情况下调整中间模块的输出,pytorch可以用hook回调函数来实现这一功能。主要使用四个hook注册函数:register_forward_hook、register_forward_pre_hook、registe 阅读全文
摘要:
奇异值分解(Singular Value Decomposition, SVD)可以被看做是方阵特征值分解的推广,适用于任意形状的矩阵。 对于矩阵$A\in \R^{m\times n}$,不失一般性,假设$m\geq n$,奇异值分解期望实现: $A=U\Sigma V^T$ 其中$U,V$分别为 阅读全文
摘要:
Transformers是著名的深度学习预训练模型集成库,包含NLP模型最多,CV等其他领域也有,支持预训练模型的快速使用和魔改,并且模型可以快速在不同的深度学习框架间(Pytorch/Tensorflow/Jax)无缝转移。以下记录基于HuggingFace官网教程:https://github. 阅读全文
摘要:
Docker方便一键构建项目所需的运行环境:首先构建镜像(Image)。然后镜像实例化成为容器(Container),构成项目的运行环境。最后Vscode连接容器,方便我们在本地进行开发。下面以一个简单的例子介绍在win10中实现:Docker安装、构建镜像、创建容器、Vscode连接使用。 Doc 阅读全文
摘要:
github上的项目总喜欢使用argparse + bash来运行,这对于快速运行一个项目来说可能有好处,但在debug的时候是很难受的。因为我们需要在.sh文件中修改传入参数,并且不能使用jupyter。 以下是把parser转换成显式class命名空间的一个代码示例: #%% import ar 阅读全文
摘要:
定义 子模 (Submodular)、超模 (Supermodular)和模(Modular)函数是组合优化中用到的集合函数概念。函数定义域为某个有限集$\Omega$的幂集$2^\Omega$,值域通常为$R$,即$f:2^\Omega\to R$。 子模函数:对于集合$A\subseteq B\ 阅读全文
摘要:
机器学习希望最小化模型的期望(泛化)误差$L$,即模型在整个数据分布上的平均误差。然而我们只能在训练集上最小化经验误差$\hat{L}$,我们期望通过最小化经验误差来最小化泛化误差。但是训练数据和数据真实分布之间是有差异的,又根据奥卡姆剃刀原理,在训练误差相同的情况下,模型复杂度越小,泛化性能越好, 阅读全文
摘要:
核技巧使用核函数直接计算两个向量映射到高维后的内积,从而避免了高维映射这一步。本文用矩阵的概念介绍核函数$K(x,y)$的充分必要条件:对称(半)正定。 对称正定看起来像是矩阵的条件。实际上,对于函数$K(x,y):\R^n\times \R^m\rightarrow \R$,将向量$x\in \R 阅读全文
摘要: 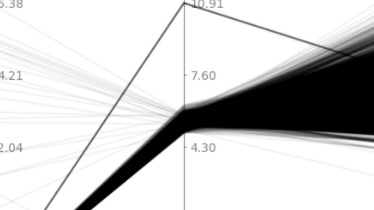 参考自《数据挖掘概念与技术》。 对于有$m$个特征,$n$个样本的数据,平行坐标可视化图中,横轴均匀列出$m$个特征,每个特征生成一个纵轴,其中每个样本就表示为穿越这些纵轴的折线。实现代码如下: import numpy as np import matplotlib.pyplot as plt d 阅读全文
参考自《数据挖掘概念与技术》。 对于有$m$个特征,$n$个样本的数据,平行坐标可视化图中,横轴均匀列出$m$个特征,每个特征生成一个纵轴,其中每个样本就表示为穿越这些纵轴的折线。实现代码如下: import numpy as np import matplotlib.pyplot as plt d 阅读全文
参考自《数据挖掘概念与技术》。 对于有$m$个特征,$n$个样本的数据,平行坐标可视化图中,横轴均匀列出$m$个特征,每个特征生成一个纵轴,其中每个样本就表示为穿越这些纵轴的折线。实现代码如下: import numpy as np import matplotlib.pyplot as plt d 阅读全文
摘要:  $\Gamma$函数 $\Gamma$函数(Gamma函数)是阶乘函数在实数和复数域的扩展。对于正整数$n$,阶乘函数表示为$n! = 1 \times 2 \times ... \times n$。然而,这个定义仅适用于正整数。Gamma函数的目的是将阶乘扩展到实数和复数域,从而计算实数和复数的“ 阅读全文
$\Gamma$函数 $\Gamma$函数(Gamma函数)是阶乘函数在实数和复数域的扩展。对于正整数$n$,阶乘函数表示为$n! = 1 \times 2 \times ... \times n$。然而,这个定义仅适用于正整数。Gamma函数的目的是将阶乘扩展到实数和复数域,从而计算实数和复数的“ 阅读全文
$\Gamma$函数 $\Gamma$函数(Gamma函数)是阶乘函数在实数和复数域的扩展。对于正整数$n$,阶乘函数表示为$n! = 1 \times 2 \times ... \times n$。然而,这个定义仅适用于正整数。Gamma函数的目的是将阶乘扩展到实数和复数域,从而计算实数和复数的“ 阅读全文
摘要:
ADMM(Alternating Direction Method of Multipliers,交替方向乘子法)是一种优化算法,主要用于解决分布式、大规模和非光滑的凸优化问题。ADMM通过将原始问题分解为多个易于处理的子问题来实现优化。它结合了两种经典优化方法:梯度下降法(gradient des 阅读全文
摘要:  孤立森林(Isolation Forest)是经典的异常检测算法(论文网址)。本文用python对其进行实现,以及与常用的异常检测包PyOD进行效果对比。 简单来说,孤立森林(IForest)中包含若干孤立树(ITree),每颗树的创建是独立的,与其它树无关。假设数据集包含$n$个样本,每个样本都包 阅读全文
孤立森林(Isolation Forest)是经典的异常检测算法(论文网址)。本文用python对其进行实现,以及与常用的异常检测包PyOD进行效果对比。 简单来说,孤立森林(IForest)中包含若干孤立树(ITree),每颗树的创建是独立的,与其它树无关。假设数据集包含$n$个样本,每个样本都包 阅读全文
孤立森林(Isolation Forest)是经典的异常检测算法(论文网址)。本文用python对其进行实现,以及与常用的异常检测包PyOD进行效果对比。 简单来说,孤立森林(IForest)中包含若干孤立树(ITree),每颗树的创建是独立的,与其它树无关。假设数据集包含$n$个样本,每个样本都包 阅读全文
摘要:
找张量积概念的时候,被各种野路子博客引入的各种“积”搞混了,下面仅以Wikipedia为标准记录各种积的概念。 点积(Dot product) https://en.wikipedia.org/wiki/Dot_product 在数学中,点积(Dot product)或标量积(scalar prod 阅读全文
摘要:  局部异常因子(Local Outlier Factor, LOF)通过计算样本点的局部相对密度来衡量这个样本点的异常情况,可以算是一类无监督学习算法。下面首先对算法的进行介绍,然后进行实验。 LOF算法 下面介绍LOF算法的每个概念,以样本点集合中的样本点$P$为例。下面的概念名称中都加了一个k-, 阅读全文
局部异常因子(Local Outlier Factor, LOF)通过计算样本点的局部相对密度来衡量这个样本点的异常情况,可以算是一类无监督学习算法。下面首先对算法的进行介绍,然后进行实验。 LOF算法 下面介绍LOF算法的每个概念,以样本点集合中的样本点$P$为例。下面的概念名称中都加了一个k-, 阅读全文
局部异常因子(Local Outlier Factor, LOF)通过计算样本点的局部相对密度来衡量这个样本点的异常情况,可以算是一类无监督学习算法。下面首先对算法的进行介绍,然后进行实验。 LOF算法 下面介绍LOF算法的每个概念,以样本点集合中的样本点$P$为例。下面的概念名称中都加了一个k-, 阅读全文
摘要:
图神经网络(GNN)目前的主流实现方式就是节点之间的信息汇聚,也就是类似于卷积网络的邻域加权和,比如图卷积网络(GCN)、图注意力网络(GAT)等。下面根据GCN的实现原理使用Pytorch张量,和调用torch_geometric包,分别对Cora数据集进行节点分类实验。 Cora是关于科学文献之 阅读全文
摘要:
论文网址:https://dl.acm.org/doi/10.1145/3404835.3462961 Arxiv:https://arxiv.org/abs/2104.08419 论文提出一种用增量学习思想做时序知识图谱补全(Temporal Knowledge Graph Completion, 阅读全文
摘要:
小样本知识图补全——关系学习。论文利用三元组的邻域信息,提升模型的关系表示学习,来实现小样本的链接预测。主要应用的思想和模型包括:GAT(图注意力神经网络)、TransH、SLTM、Model-Agnostic Meta-Learning (MAML)。 论文地址:https://arxiv.org 阅读全文
摘要:
模型不可知元学习(Model-Agnostic Meta-Learning, MAML)的目标是使模型每次的梯度更新更有效、提升模型的学习效率、泛化能力等,它可以被看做一种对模型进行预训练的方法,适用于小样本学习。 原文:http://proceedings.mlr.press/v70/finn17 阅读全文
摘要:
深度学习中,当一块GPU不够用时,我们就需要使用多卡进行并行训练。其中多卡并行可分为数据并行和模型并行。具体区别如下图所示: 由于模型并行比较少用,这里只对数据并行进行记录。对于pytorch,有两种方式可以进行数据并行:数据并行(DataParallel, DP)和分布式数据并行(Distribu 阅读全文
摘要:
NLTK和SpaCy是NLP的Python应用,提供了一些现成的处理工具和数据接口。下面介绍它们的一些常用功能和特性,便于对NLP研究的组成形式有一个基本的了解。 NLTK Natural Language Toolkit (NLTK) 由宾夕法尼亚大学开发,提供了超过50种语料库,以及一些常用的文 阅读全文
摘要:
STATA是一个数据统计软件,正如它的名字一样,STATA=statistic+data。STATA软件的功能和matlab类似,也可以用代码实现数据的统计与可视化。但几乎只能进行整行整列的数据处理,且每次只能加载处理一个数据矩阵,灵活性和全面性比不过matlab。那我为什么要用STATA呢?这是因 阅读全文
摘要:
不同的自然语言有不同的语法结构,因此需要对语言数据进行语法解析,才能让机器更准确地学到相应的模式。而语言不同于图像,数据标注工作需要有一定的语言学知识,因此数据的整理也相对更困难。下面以英语为例(别的咱也看不懂),对NLP研究中常见的基本语言学概念进行记录。 词性(Part Of Speech) 词 阅读全文
摘要:
两个正整数的最大公约数(Greatest Common Divisor,GCD)在计算机中通常使用辗转相除法计算,最小公倍数(Least Common Multiple, LCM)可以使用GCD来计算。下面首先介绍GCD和LCM。然后介绍辗转相除法的计算形式,并证明为什么可以得出GCD。 最大公约数 阅读全文
摘要:
遗传算法是一种通用的最优化方法,具体原理可以看:遗传算法详解与实验。下面记录在Matlab中如何使用遗传算法来做优化。 用法 调用方式如下: 1 x = ga(fun,nvars) 2 x = ga(fun,nvars,A,b) 3 x = ga(fun,nvars,A,b,Aeq,beq) 4 x 阅读全文
摘要:
要用TPU训练tensorflow模型,只能使用静态图。也就是要先通过keras的sequential或者函数式定义模型,而不能直接使用重写的Model类。例子如下,其中包含层的自定义,以及子像素卷积。需要注意的是,tensorflow的子pixel_shuffle通道顺序与pytorch不同,具体 阅读全文
摘要:
搞科研的小伙伴总是会被期刊严苛的引用文献格式搞的很头疼。虽然常用的文献软件可以一键导出BibTex,但由于很多论文在投稿之前都会先发上Arxiv占坑,软件就很可能会把文献引出为来自Arxiv。我用的是Zotero,就有这个毛病。 因此,如果是IEEE的期刊,最好是直接去IEEE官网搜索并导出引用,否 阅读全文
摘要:
Pyecharts是百度开源的移植到Python上的可视化工具,里面方法调用起来像是标记性语言,因此代码的可读性很强,一目了然。下面是一个绘制散点图的例子: #%% import pyecharts.options as opts from pyecharts.charts import Scatt 阅读全文
摘要:
PIL全称Python Image Library,是python官方的图像处理库,包含各种图像处理模块。Pillow是PIL的一个派生分支,包含与PIL相同的功能,并且更灵活。python3.0之后,PIL不再更新,pillow代替了它原有的地位。Pillow的官方文档: https://pill 阅读全文
摘要:
在炼丹时,数据的读取与预处理是关键一步。不同的模型所需要的数据以及预处理方式各不相同,如果每个轮子都我们自己写的话,是很浪费时间和精力的。Pytorch帮我们实现了方便的数据读取与预处理方法,下面记录两个DEMO,便于加快以后的代码效率。 根据数据是否一次性读取完,将DEMO分为: 1、串行式读取。 阅读全文
摘要:
由于论文中常见很多种颜色空间,各种颜色空间的通道都有特殊的用处,下面对常见的颜色通道进行总结。 RGB RGB(Red红 Green绿 Blue蓝)是最常用的颜色空间,模拟光的混合原理。三个通道的取值范围都为$[0,255]$,共有$256^3 = 16777216$种色彩表示。三个通道的叠加与红绿 阅读全文
摘要:
经典超分辨率重建论文,基于稀疏表示。下面首先介绍稀疏表示,然后介绍论文的基本思想和算法优化过程,最后使用python进行实验。 稀疏表示 稀疏表示是指,使用过完备字典中少量向量的线性组合来表示某个元素。过完备字典是一个列数大于行数的行满秩矩阵,也就是说,它的列向量有无数种线性组合来表达列向量空间中的 阅读全文
摘要:
反向投影法是用已知图像的某些特征来突出其它图像中此类特征的一种方法,基于直方图。 主要步骤如下: 1、统计已知图像某个特征的色度直方图,通常用色度-饱和度(Hue-Saturation)来统计二维直方图,并把直方图表示为概率的形式。 2、选取测试图像,对于图像中的每一个像素,查看它的色度在已统计直方 阅读全文
摘要:
分组卷积 之间看分组卷积示意图。 不分组: 分两组: 分四组: 以此类推。当然,以上都是均匀分组的,不均分也是可以的。至于分组卷积有什么好处,很明显,可以节省参数量。假设不使用分组时,卷积核的参数量为: $n = k^2c_1c_2$ 其中$k,c_1,c_2$分别表示卷积核宽度,输入通道数,输出通 阅读全文
摘要:
变分自动编码器的大致概念已经理解了快一年多了,但是其中的数学原理还是没有搞懂,在看到相关的变体时,总会被数学公式卡住。下决心搞懂后,在此记录下我的理解。 公式推导——变分下界 这篇文章提出一种拟合数据集分布的方法,拟合分布最常见的应用就是生成模型。该方法遵循极大似然策略,即对于数据集$X = \{x 阅读全文
摘要:
对于显存不充足的炼丹研究者来说,弄清楚Pytorch显存的分配机制是很有必要的。下面直接通过实验来推出Pytorch显存的分配过程。 实验实验代码如下: import torch from torch import cuda x = torch.zeros([3,1024,1024,256],req 阅读全文
摘要:
在命令行中运行python代码是很常见的,下面介绍如何定义命令后面跟的参数。 常规用法 Python代码中主要使用下面几行代码来定义并获取需要在命令行中赋值的参数: import argparse parser = argparse.ArgumentParser("Description.") # 阅读全文