全文检索-Elasticsearch (一) 安装与基础概念
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
Elasticsearch由java开发,所以在搭建时,需先安装java JDK
几个基本概念
- 索引(Index)
一个索引就是含有相似结构或性质特性的文档的集合,例如用户信息数据可以作为一个索引,文章信息也可应作为另一个索引。
- 文档(Document)
文档是索引的基本单元,可以理解成关系数据库表中的一条记录,包含了一组属性信息,同时包含一个唯一标识这一组属性值的ID,通过该ID可以更新一个文档,也可以删除一个文档。
- 分片(Shards)和副本(Replicas)
一个索引进行分割,分成多个片段,每一个片段称为一个分片,这样划分可以很好地管理索引,跨节点存储, 每个分片本身是一个全功能的完全独立的“索引”,它可以部署在集群中的任何节点;副本是为了保证一个分片的可用性,冗余复制存储,当一个分片对应的数据无法读取时,可以读取其副本,正常提供搜索服务。
副本根据官方文档有以下两个重要作用
- 高可用。它提供了高可用来以防分片或节点宕机。为此,一个非常重要的注意点是绝对不要将一个分片的拷贝放在跟这个分片相同的机器上。
- 高并发。它允许你的分片可以提供超出自身吞吐量的搜索服务,搜索行为可以在分片所有的副本中并行执行。
- 集群(cluster)
一个集群是由一个或多个节点(服务器)组成的,通过所有的节点一起保存你的全部数据并且提供联合索引和搜索功能的节点集合。每个集群有一个唯一的名称标识,默认是“elasticsearch”。这个名称非常重要,因为一个节点(Node)只有设置了这个名称才能加入集群,成为集群的一部分。
- 节点(Node)
一个节点是一个单一的服务器,是集群的一部分,存储数据,并且参与集群的索引和搜索功能。跟集群一样,节点在启动时也会被分配一个唯一的标识名称,这个名称默认是一个随机的UUID(Universally Unique IDentifier)。如果你不想用默认的名称,你可以自己定义节点的名称。这个名称对于管理集群节点,识别哪台服务器对应集群中的哪个节点有重要的作用。
安装-搭建集群
准备三台服务器搭建三个集群节点:
192.168.0.101
192.168.0.102
192.168.0.103
之后在官网下载ES,分别为三台服务器装上Elasticsearch
对于windows服务器,在官网有两种格式下载: ZIP和MSI,可以任选
- ZIP格式安装:
下载解压后,直接在bin文件中执行elasticsearch.bat即可运行Elasticsearch,
或是执行elasticsearch-service.bat安装成服务即可
- MSI格式安装:
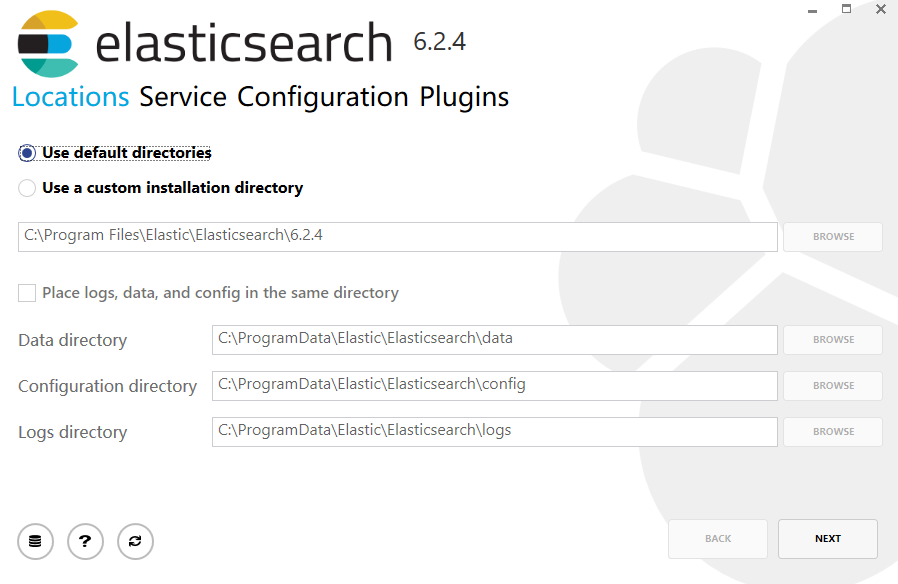
1.运行elasticsearch-6.2.4.msi;出现如图以下界面,默认目录或是选择目录安装,下一步
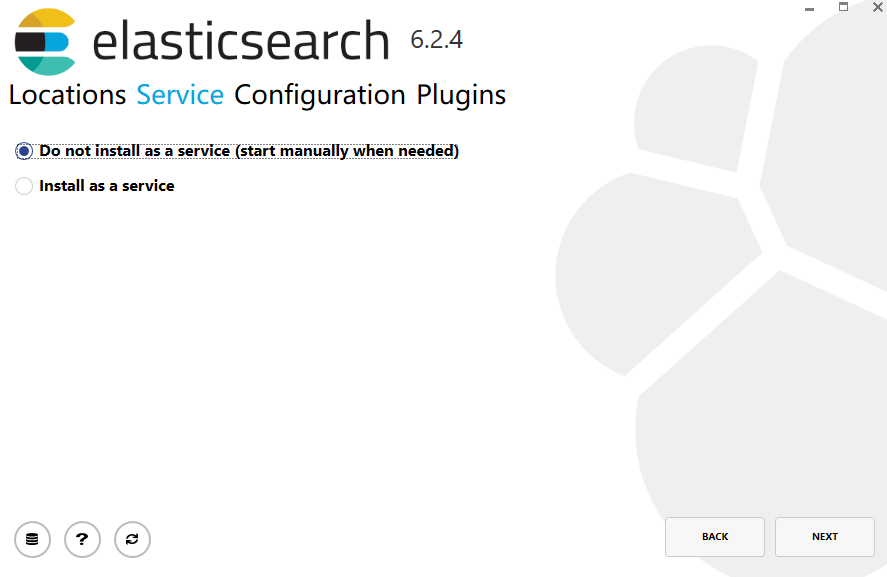
2.可以选择是否安装成windows服务,这边先不选择,改为手动开启
3.进行基本配置。下一步
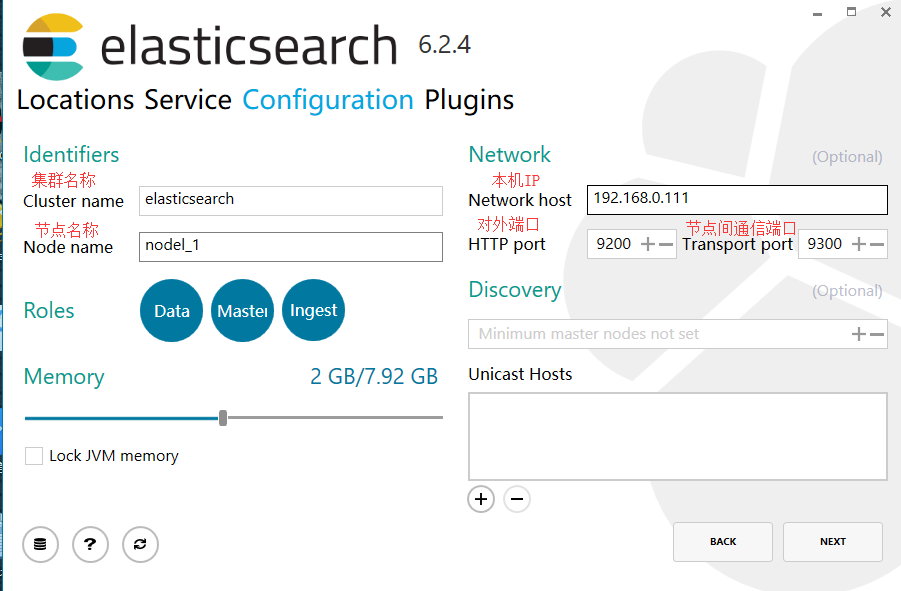
4.先不选任何插件或是分词器,之后安装即可
- 不管是哪种安装方式,想搭建集群,每个节点还需进入ElasticSearch安装目录下config文件夹中,打开elasticsearch.yml进行配置
节点一配置信息:
bootstrap.memory_lock: false cluster.name: elasticsearch #集群名称,所有节点必须一致,才能自动加入集群 http.port: 9200 #对外通信端口 network.host: 192.168.0.101 #本机IP node.data: true #是否为数据节点 node.ingest: true node.master: true #是否为候选主节点 node.name: node-1 #节点名称 path.data: C:\Elasticsearch\data #索引数据保存目录 path.logs: C:\Elasticsearch\logs #日记保存目录 transport.tcp.port: 9300 #节点间通信端口
discovery.zen.ping.unicast.hosts: ["192.168.0.102:9300", "192.168.0.103:9300"] #设置集群自动发现机器ip集合 ,
discovery.zen.minimum_master_nodes: 2 #一般用node数/2 + 1。node数不能为偶数 防止脑裂现象
节点二配置信息
bootstrap.memory_lock: false
cluster.name: elasticsearch #集群名称,所有节点必须一致,才能自动加入集群
http.port: 9200 #对外通信端口
network.host: 192.168.0.102 #本机IP
node.data: true #是否为数据节点
node.ingest: true
node.master: true #是否为候选主节点
node.name: node-2 #节点名称
path.data: C:\Elasticsearch\data #索引数据保存目录
path.logs: C:\Elasticsearch\logs #日记保存目录
transport.tcp.port: 9300 #节点间通信端口
discovery.zen.ping.unicast.hosts: ["192.168.0.101:9300", "192.168.0.103:9300"] #设置集群自动发现机器ip集合 ,
discovery.zen.minimum_master_nodes: 2 #一般用node数/2 + 1。node数不能为偶数 防止脑裂现象
节点三配置信息
bootstrap.memory_lock: false cluster.name: elasticsearch #集群名称,所有节点必须一致,才能自动加入集群 http.port: 9200 #对外通信端口 network.host: 192.168.0.103 #本机IP node.data: true #是否为数据节点 node.ingest: true node.master: true #是否为候选主节点 node.name: node-3 #节点名称 path.data: C:\Elasticsearch\data #索引数据保存目录 path.logs: C:\Elasticsearch\logs #日记保存目录 transport.tcp.port: 9300 #节点间通信端口
discovery.zen.ping.unicast.hosts: ["192.168.0.101:9300", "192.168.0.102:9300"] #设置集群自动发现机器ip集合 ,
discovery.zen.minimum_master_nodes: 2 #一般用node数/2 + 1。node数不能为偶数 防止脑裂现象
- 分别运行elasticsearch,直接通过chrom应用安装elasticsearch-head浏览器插件,elasticsearch-head可以查看es集群的运行状态以及数据
结果如下(还未加入任何索引):
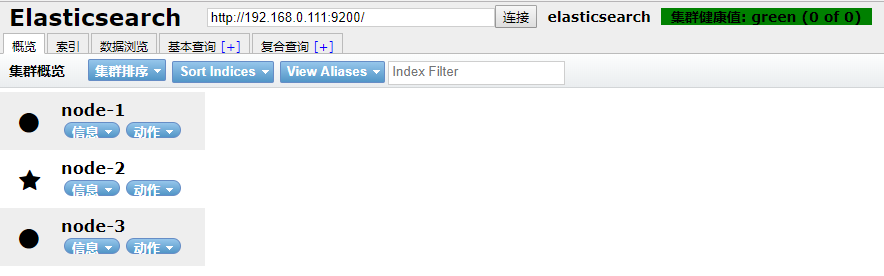
集群健康值说明:
- 绿色:所有的主分片和副本分片都正常可用;
- 黄色:所有的主分片可用,但是部分副本分片不可用
- 红色:部分主分片不可用

