
Google分析language垃圾信息
最近一段时间,我在Google Analytics(以下简称GA)中查看网站数据时,发现一个非常可疑的信息:
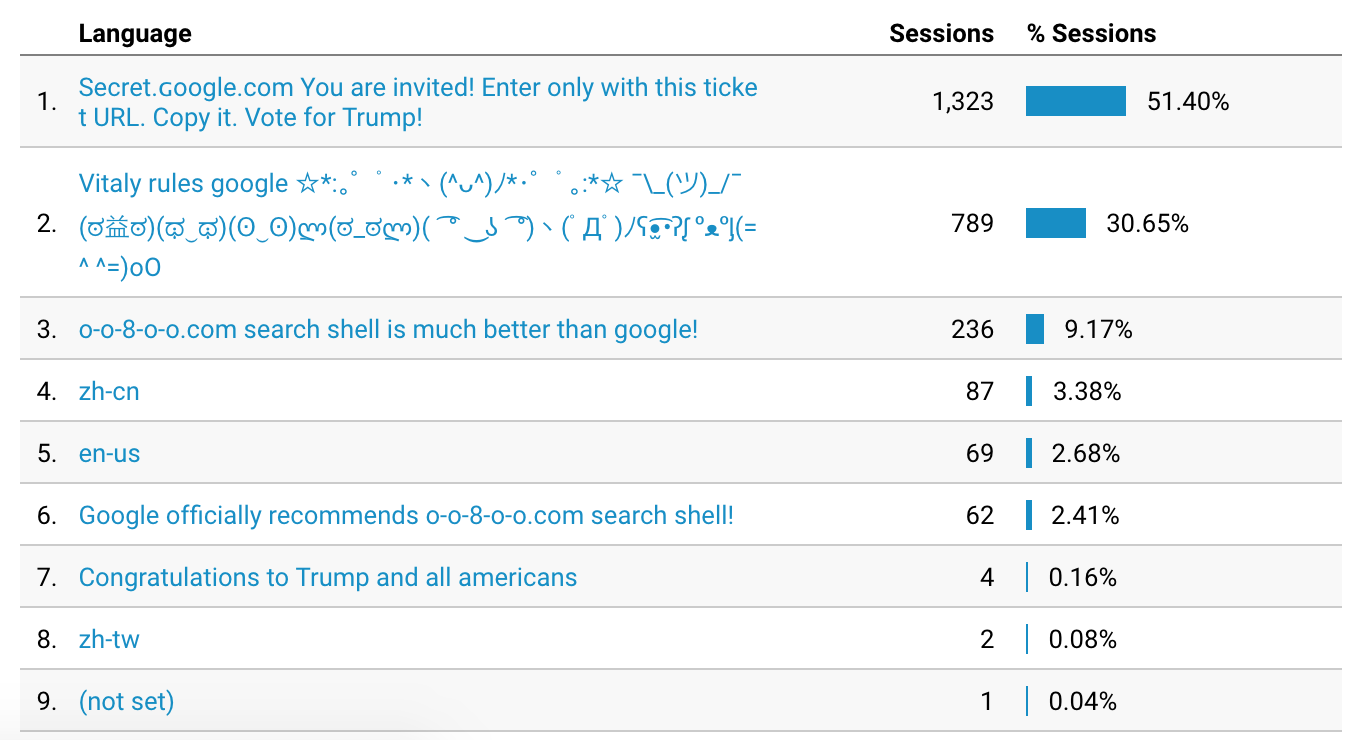
这什么鬼?
“language”这一项一般是 “zh-tw”, “zh-cn”, “en-us”, “es”, “fr”等,它是由用户浏览器设定的。但用户浏览器不可能把语言项设置为这些:
Secret.ɢoogle.com You are invited! Enter only with this ticket URL. Copy it. Vote for Trump!
o-o-8-o-o.com search shell is much better than google!
Vitaly rules google ☆:。゜゚・ヽ(^ᴗ^)ノ・゜゚。:☆ ¯_(ツ)/¯(ಠ益ಠ)(ಥ‿ಥ)(ʘ‿ʘ)ლ(ಠಠლ)( ͡° ͜ʖ ͡°)ヽ(゚Д゚)ノʕ•̫͡•ʔᶘ ᵒᴥᵒᶅ(=^ ^=)oO
Congratulations to Trump and all americans
分析请求
很明显,这是一种新的 spam(垃圾信息),希望吸引目标人群(可能就是我们这样的网络管理员)的注意力。
仔细地观察这些请求,会发现几个特点:
- 请求数有明显的波峰,在几天内会达到高峰,然后又降下去
- New Sessions 的比例非常高,达到了86%以上
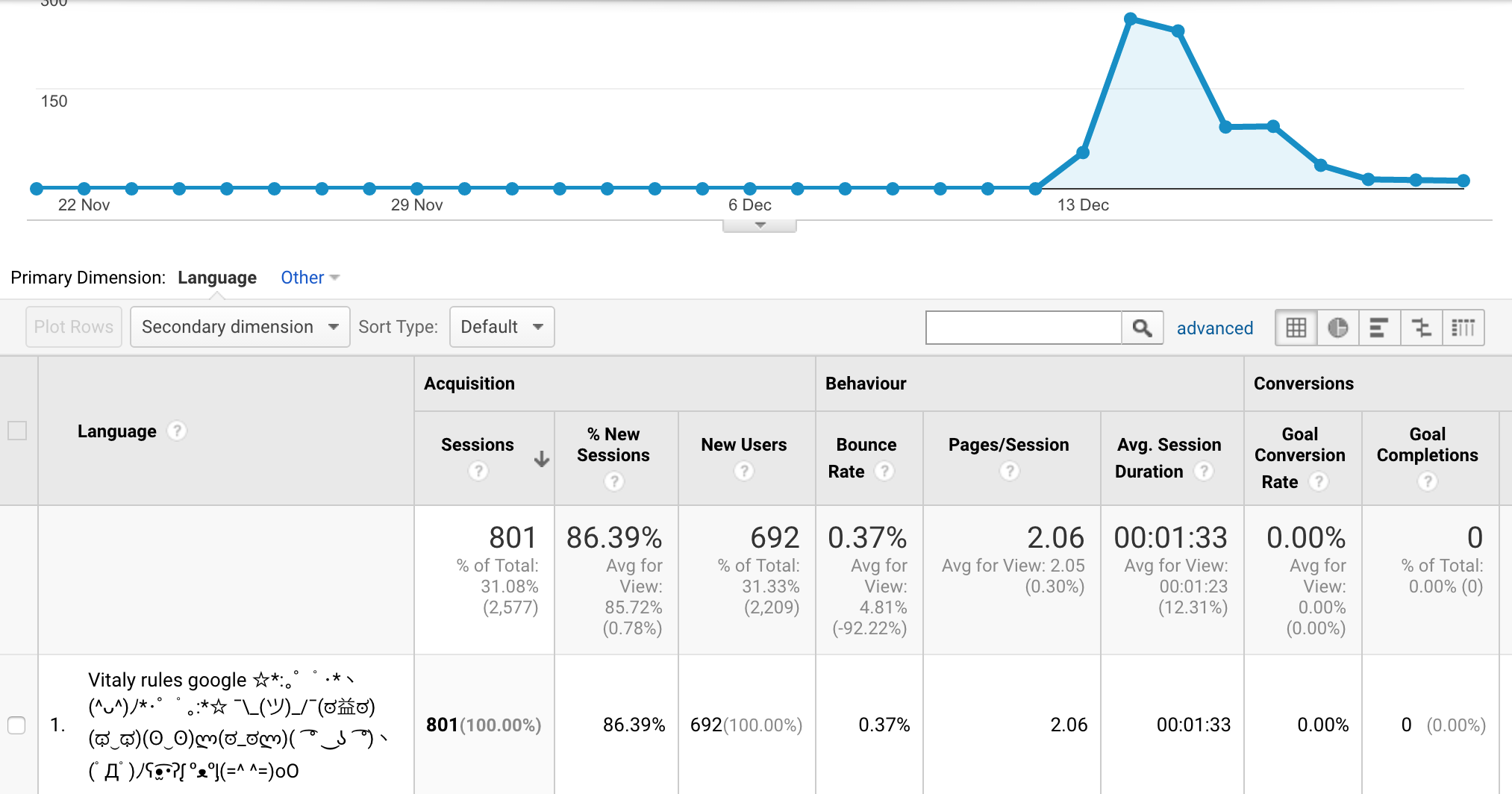
分析其它受攻击的栏目
仔细查看 GA 统计项目的这些请求,发现 referrer 一栏也比较可疑地出现了这些:
motherboard.vice.com addons.mozilla.org webmasters.stackexchange.com blackhatworld.com thenextweb.com abc.xyz lifehacĸer.com ...
这其中有一些非常正规的域名。比如abc.xyz是Google的母公司alphabet的官网,thenextweb.com也是一个开发者媒体。
这些网站本身没有问题,但其实该网站上并没有任何一个链接指向我的博客,更谈不上我的访客“来自”(referral)该网站了。当我访问回去,发现并没有实际上的链接,只是广告,倒也罢了,更可怕的是可能会有钓鱼、病毒等。
综上,这是一波二维攻击(假的语言项和假的 referral 项),目的是吸引你的注意力。
分析攻击怎么产生的
总的来说,这种垃圾信息有两种攻击方式。一种是真正会访问你的网站的网络爬虫;另一种是不访问你的网站,而是将假冒的“点击”事件直接发送到GA服务器。事实上,第二种攻击方式由于成本低,因而更加常见。
GA 的统计逻辑是,当用户访问你的网站,会在前端运行一段 JavaScript 代码,然后把用户的一些访问情况通过 HTTP 请求发送给 GA 服务器,告诉 GA 发生了一次“访问”。而这个 HTTP 请求可以很容易地被伪造,所以垃圾信息发送者无需真的访问你的站点,它直接发送大量 HTTP 请求即可达到目的。
除了 HTTP 请求,GA 还支持更方便的Measurement Protocol ,开发者可以发送一个原始数据(raw data)给GA,来一次性传输大量用户行为。这个协议的初衷是让开发者可以统计所有环境下的用户行为,比如开发者可以将离线状态下的用户行为记录下来,当在线时一次性发送。或者当内网不支持外部访问时,先记录下用户行为,随后再定时一次性发送到 GA。
初衷是好的,不幸的是,这个过程仍然是无需认证身份,所以更方便了垃圾信息发送者。垃圾信息发送者可以通过一次请求即发送大量假数据,他只需要得到你的 UA-ID(UA-XXXXXXX-XX)即可。
在这个原始数据包中,一切皆可伪造。Hostname?没问题!Referral?全改了!URL path?当然也可以改……
如何避免
对网站主来说,这种垃圾信息有几点危害:1、浪费时间,就像传统垃圾邮件一样。2、干扰 GA 状态栏,特别是如果网站流量不是很大(比如我)。3、传播病毒。
所以,有没有完美的解决方法呢?实际上,没有。
要知道,数据一旦录入到 GA,就没有办法删掉了。能做的只有两件事,一是阻止垃圾信息进一步加入到 GA,二是在视图中过滤掉已经添加进来的垃圾信息,眼不见为净。
第一步:使用过滤器阻止未来的垃圾信息
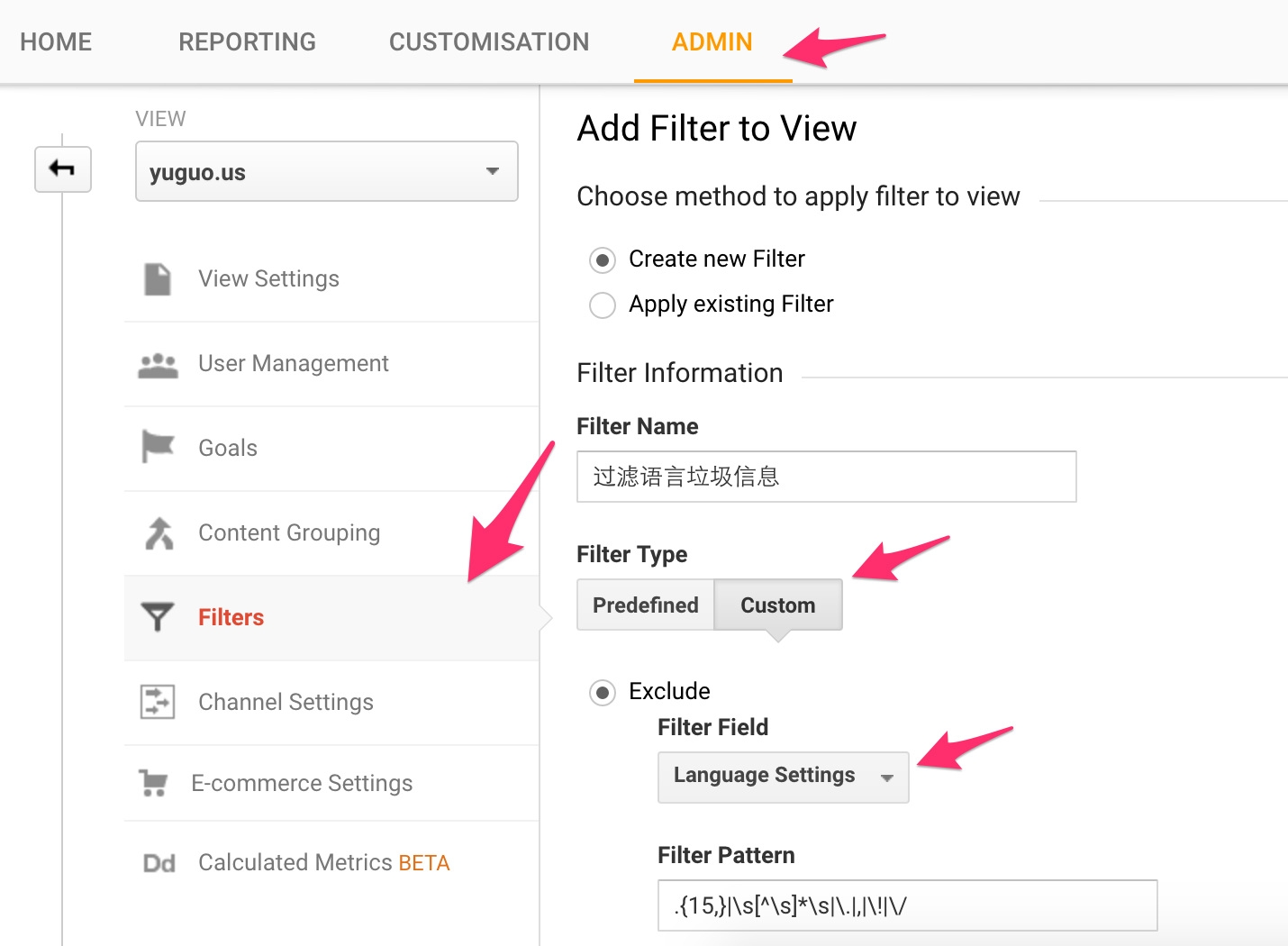
在语言项中,一般字符数是5-6个,很少有超过10个的,所以我们可以认为语言项超过15个字符的就一定是垃圾信息。
此外,有一些字符是不可能出现在合法的语言项中,但垃圾信息会利用这些字符来组成URL,比如: “secret google com”, “secret,google,com”, “secret!google!com”,所以我们也一并排除空格、点号、逗号、惊叹号。
.{15,}|\s[^\s]*\s|\.|,|\!|\/
在admin中选择Filter,然后新增一个如图所示的过滤器即可。
设置好了之后,可以验证一下是否会拦截掉我们想拦截的内容:

没有问题,未来的语言项垃圾信息会直接被拦截掉。
第二步:通过Segment净化已有数据
过滤器从你开始设置时生效,而历史信息无法修改。不过 GA 提供了 custom segment 功能,在生成报告时,选择性过滤掉一些数据。
Segment 就是数据片段,指的是在完整的数据中取出我们需要的片段进行分析。比如我们可以单独取出24岁以下的用户的行为,对比24岁以上的用户行为有何不同。而这个功能正好可以让我们把“语言”不规范的数据过滤掉。
如下图,在All Users的旁边有一个 + Add Segment 的按钮,点击之后就可以配置我们的 segment。
一定要注意是选择“does not match regex”,里面填上之前的正则。
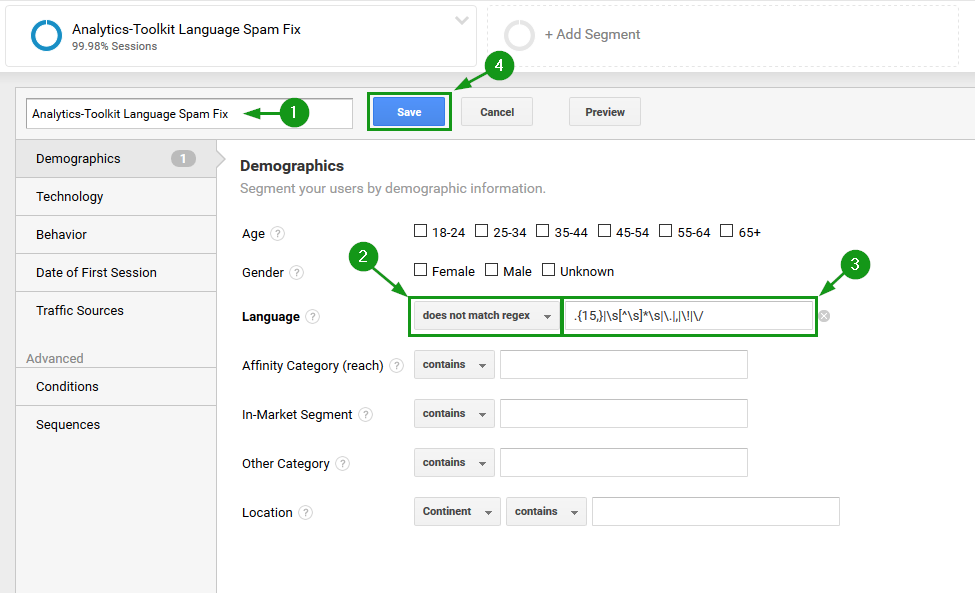
创建好了新的 segment 之后,就会看到过滤之后的全新报告。

下次再进入时,又会默认进入到 All Users 视图,这时可以在 All Users 里的 custom 里找到我们的自定义 segment,勾选即可。
如果经常需要查看这个 segment,推荐点击 shortcut 来新增快捷方式。
它会保存当前的 segment 和排序等,下一次可以直接从 Short 项目进入到这个快捷目录。
以上就是完整的过滤方法了,这样应该可以过滤掉大部分语言spam的攻击。GA提供的 filter 和 segment 的功能很强大,如果后续发现有新的垃圾信息,可以继续通过今天学习的方法来更新完善我们的过滤器。
参考资料: Language Spam – The Latest Google Analytics Spam Guide to Removing Referrer Spam in Google Analytics
相关推荐
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处,获取更多云计算技术干货,可请前往腾讯云技术社区
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~

