
福大软工1816 · 第五次作业 - 结对作业2
分工情况
| 具体分工说明 | 分工 |
|---|---|
| 1. 编写爬虫爬取论文信息 | 叶一帆 |
| 2. 自定义输入输出文件 | 叶一帆 |
| 3. 加入权重的词频统计 | 林世杰 |
| 4. 新增词组词频统计功能 | 林世杰 |
| 5. 自定义词频统计输出 | 叶一帆 |
| 6. 多参数的混合使用 | 叶一帆 |
| 7. 附加题 | 叶一帆 |
| 8.性能分析与改进 | 叶一帆 |
| 9.单元测试 | 林世杰,叶一帆 |
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 0 | 0 |
| · Estimate | · 估计这个任务需要多少时间 | 630 | 640 |
| Development | 开发 | 0 | 0 |
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 100 |
| · Design Spec | · 生成设计文档 | 50 | 50 |
| · Design Review | · 设计复审 | 50 | 50 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 40 | 40 |
| · Coding | · 具体编码 | 100 | 100 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 50 | 50 |
| Reporting | 报告 | 0 | 0 |
| · Test Repor | · 测试报告 | 50 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 630 | 640 |
解题思路
-
爬虫部分(自己写的):
这里用到了Java的两个包,
httpclient和jsoup,本来是直接用jsoup解析,但是发现解析后的内容不全,有部分html源码没生成全就解析了,所以加了httpclient,先请求读取网页,然后用jsoup开始解析。整个爬虫流程:先找到标签的class为
ptitle的段,然后获取链接,但是这里的链接是相对地址,所以完整的链接需要自己拼接。这样就能拿到一个论文列表的url表。然后遍历每个链接,解析找标签的值为papertitle和abstract的文本,分别对应标题跟摘要。然后各种拼接字符串。大体流程:
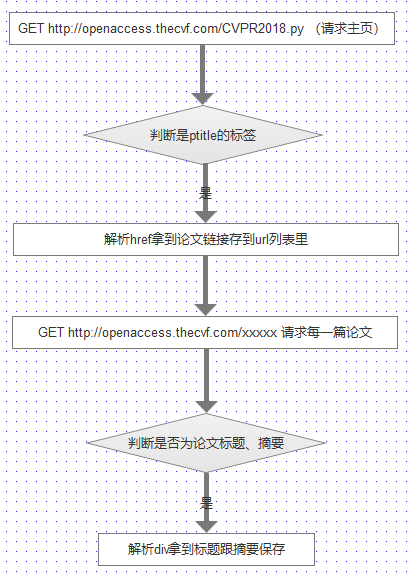
-
代码组织与内部实现设计
-
自定义输入输出文件:同上次作业,获取CLI上的参数,然后new一个File并且判断读写异常。
-
加入权重的词频统计:判断标题还是摘要,然后个数加1|10
-
新增词组词频统计功能:
用一个队列存给定词组长度的单词。
- 判断单词是否为合法单词:合法单词入队;队列全部清空。
- 如果队列长度达到给定长度,则存储到Map中。
- 队首出队一个,队尾继续入队。
- 循环①操作。
具体流程:

-
自定义词频统计输出:把固定值全部写成变量的形式。
-
多参数的混合使用:获取CLI的各种参数判断,调用对应的模块或者做出对应的异常抛出
-
附加题设计与展示
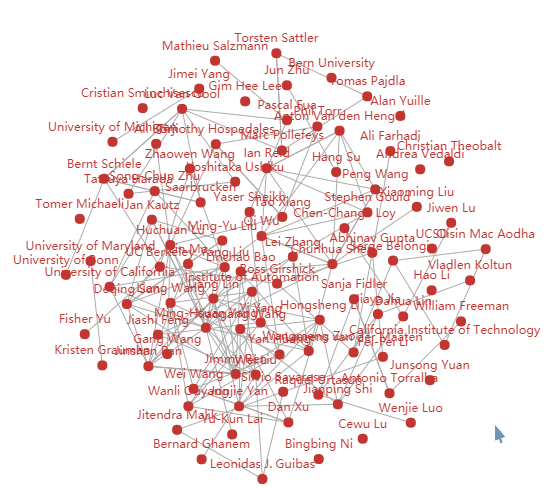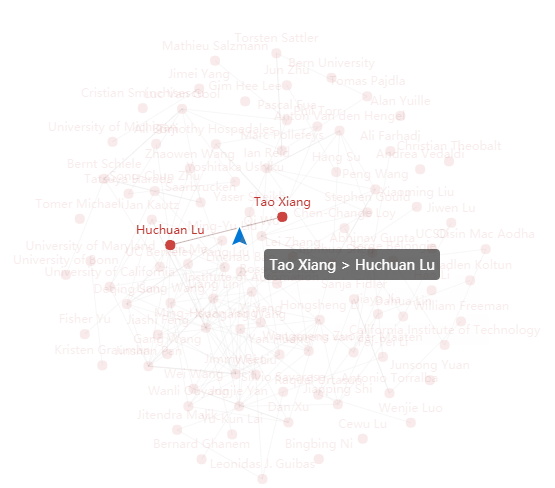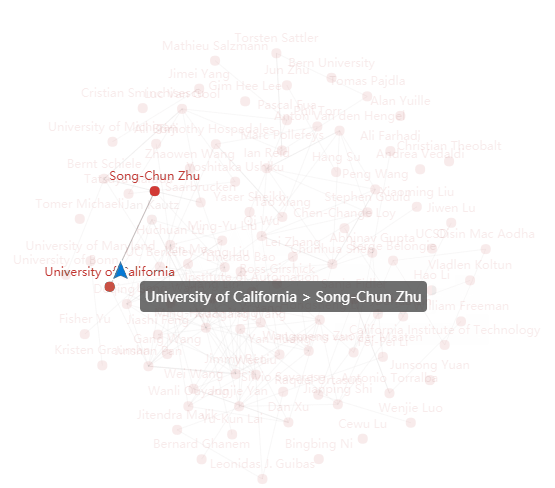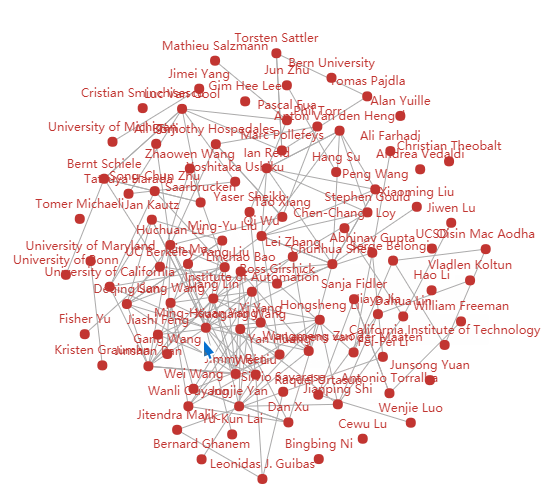
- 设计的创意独到之处:把全部已知的数据做一个分析+可视化处理。做到所见即所得,一眼就能看出这次论文的作者有多少,这次论文哪个类型的最多,这次活动最火的名词热词是什么,这次哪个地区的论文数量最多,又或者哪几个作者之间有关系。。
- 实现思路:先用java做各种数据处理和分析,然后输出
analy_result.txt,这个文本里包含一千多篇论文的类别、标题、摘要、作者以及作者来自、PDF链接。然后继续导出各种json文件,包含各种数据,由于时间问题,没用java做图形化。用pyecharts库快速生成图形化表格,对应文件cvpr数据可视化.html - 实现成果展示:文件在github,这里展示几个图。
由于全部作者的图太大这里就展示部分:

作者关系图
热词高频词组

不同类型的论文统计图

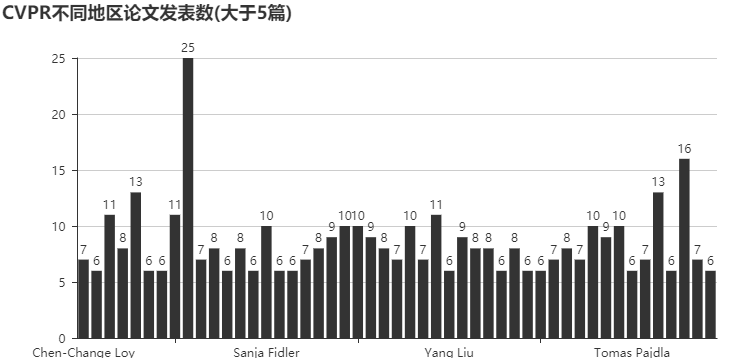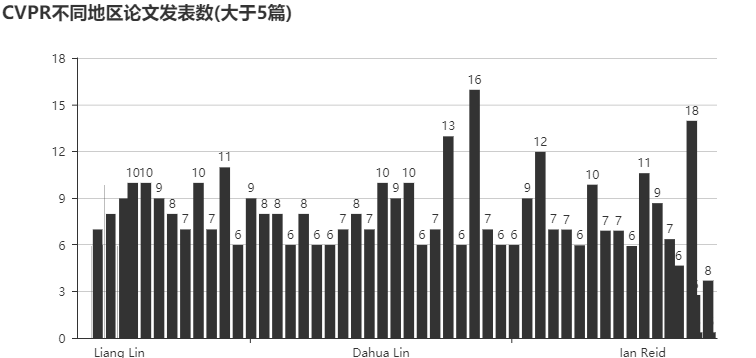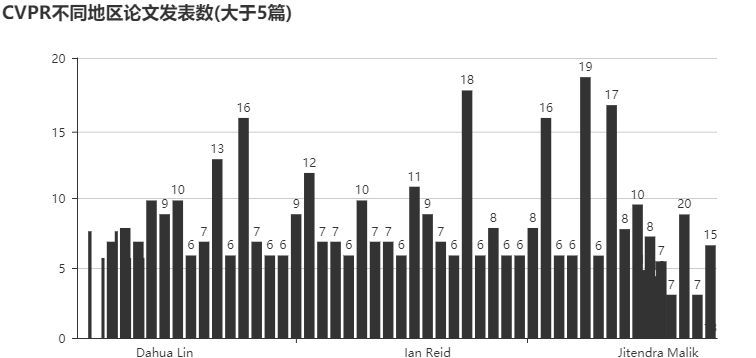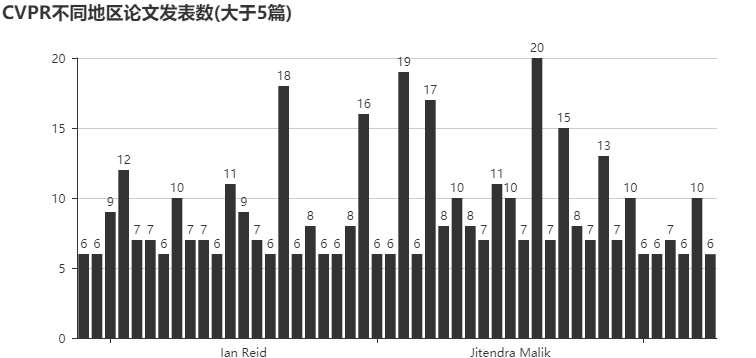
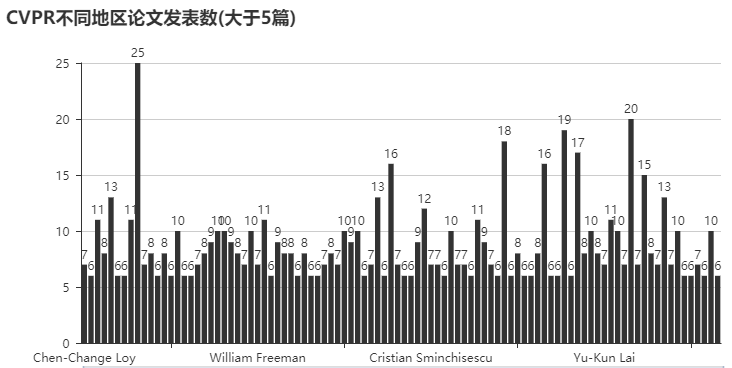
不同地区的论文发表数
关键代码展示
- 具有价值的代码片段
/*
* 统计词组
* 参数 字符串 ant:词组的单词数 ty权重类型
* ty 参数当ty==1 权重为10 ty==0 权重为1
*/
public void CountforPhrase(String ss,int ant,int ty){
ss = ss.toLowerCase();
ss = ss.replaceAll("\n","");
StringBuilder mid=new StringBuilder();//分隔符
StringBuilder wword=new StringBuilder();//单词拼接
Queue<String> que1=new LinkedList<String>();//用于存储词组单词
Queue<String> que2=new LinkedList<String>();//用于存储分隔符
String feng=",./;'[] \\<>?:\"{}|`~!@#$%^&*()_+-=";//分隔符集合
StringTokenizer words = new StringTokenizer(ss,feng,true); //分割文本成单词。
try {
while (words.hasMoreTokens()) {
String word =words.nextToken();
if (word.length() >= 4 && Character.isLetter(word.charAt(0)) && Character.isLetter(word.charAt(1)) && Character.isLetter(word.charAt(2)) && Character.isLetter(word.charAt(3))) { //判断单词前4个是否为字母
que2.offer(mid.toString());
mid.delete(0,mid.length());
que1.offer(word);
if(que1.size()>=ant){//达到词组单词数量
int cnt=0;
wword.delete(0,wword.length());
for(String w:que1){
wword.append(w);
cnt++;
if(que2.size()>cnt)
{
String tmp=((LinkedList<String>) que2).get(cnt);//取出中间的分隔符
wword.append(tmp);//拼接
}
}
//最后生成正确的wword 词组
// 进行统计操作
if(!phraseCount.containsKey(wword.toString()))
{
phraseCount.put(wword.toString(),new Integer( ty==1 ? 10:1 ));
}
else{
int count=phraseCount.get(wword.toString()) + (ty==1 ? 10:1);
phraseCount.put(wword.toString(),count);
}
que1.remove();
que2.remove();
}
}
else if(word.length()!=1){//不符合条件 将其前面的都删除
que1.clear();
que2.clear();
}else if(word.length()==1 && !(Character.isLetter(word.charAt(0)))){//判断是否为分隔符
mid.append(word);
}
}
}catch (Exception e){
System.out.println("词频统计报错:");
System.out.println(e.getMessage());
}
}
性能分析与改进
- 改进思路:目前没有改进,在写的过程中一边调优一边实现功能。
- 展示性能分析图和程序中消耗最大的函数:
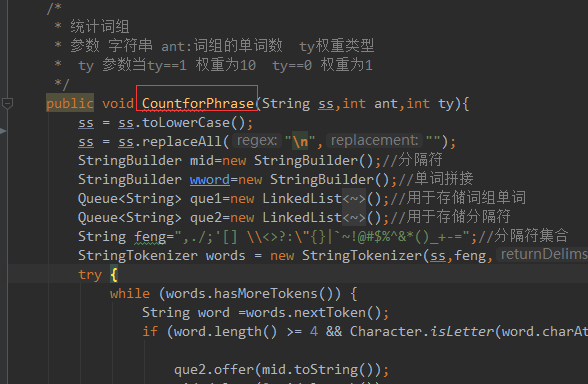
代码覆盖率的图:

覆盖率最高的函数——词组词频统计
性能分析图:

单元测试
- 展示出项目部分单元测试代码
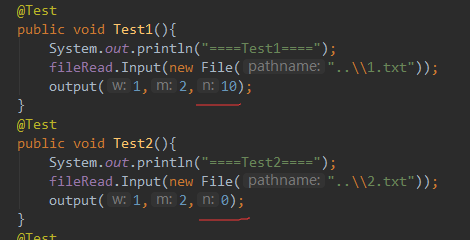
脏数据

1.txt&2.txt
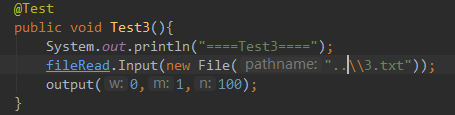
3.txt

读空文件

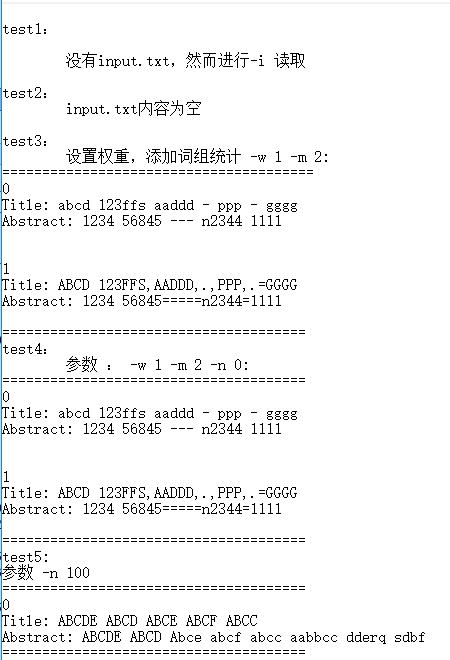
- 说明测试的函数
fileRead是文件读写类,负责读写。
output是临时提取出来的,跟写的格式一致。 - 构造测试数据的思路
Github的代码签入记录
- 合理的commit信息

遇到的代码模块异常或结对困难及解决方法
-
问题描述:
github的团队合作,结对代码的接口问题。对于github上面的团队交流不熟练,完成自己的功能之后就进行一次提交而已。
clone队友的github,之后不能进行项目编译。 -
做过哪些尝试:
接口问题:尝试过直接传入整个input文件,最后发现这样处理会使得分装变得比较没有效果。 -
是否解决:
解决了clone之后项目的编译问题,已经传参问题,将参数改成文件的每行字符串。 -
有何收获:
更加理解了java的基础知识,已经IEDA的环境配置问题。
学会简单的github团队项目更新,交互。
学会了字符串的各种处理。
评价你的队友
-
值得学习的地方
队友让我值得学习的地方有很多,解决问题的思考方式,对于问题的认真分析,快速自主学习的能力,解决问题的能力,快速查阅资料的能力。除此之外,队友对于一些技术方面的知识面比我广很多,熟练掌握了许多技能。人又帅,代码又写得好看。
-
需要改进的地方
我觉得我抱了一个超级厉害的大腿,在合作方面是十分愉快的,没有什么大问题。但是,所谓能力越强责任越大。这次作业是我第一次学习java并且用java进行编程,还是十分不熟练。然后队友就把大部分的工作给独立完成了,我会觉得队友承担的任务太重了,然而却没有和我抱怨,没有和我交流,没有分配足够多的工作给我。会让我觉得,队友更加倾向独立解决问题。
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 5 | 1000+ | 1000+ | 42 | 42 | acm训练,java基础语法学习,IDEA使用 |
| 6 | 300+ | 300+ | 5 | 5 | acm训练,java基础语法学习 ,github团队的使用 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号